
Curso
Understanding Machine Learning
2 h
299.3K
Una predicción solo es tan buena como lo que entra en ella, así que merece la pena empezar por la materia prima. El modelo aprende de dos fuentes de datos en vivo y las convierte en una única tabla ordenada de variables.
Todo se construye a partir de dos sitios. API-Football aporta el calendario y las estadísticas por partido: quién jugó contra quién, cuándo, dónde y cómo terminó. eloratings.net aporta las valoraciones Elo de cada selección nacional.
Una valoración Elo es un único número que refleja la fuerza de un equipo. Cada equipo se sitúa en algún punto de la escala y, tras cada partido, la valoración se actualiza: si ganas a un rival más fuerte, subes mucho; si pierdes con uno más débil, bajas en picado. La idea viene del ajedrez y encaja muy bien con el fútbol. Si quieres la intuición completa, este artículo anterior de DataCamp lo explica en el contexto del Mundial 2022.
Juntas, las dos fuentes dan un dataset Gold de unas 6.900 selecciones internacionales desde 2018 con el que aprender.
Aquí llega la primera decisión de diseño importante. En lugar de predecir directamente el resultado como victoria, empate o derrota, el modelo predice algo más granular: el número de goles que marca cada equipo en un partido. Los conteos de goles en fútbol siguen, con bastante aproximación, una distribución de Poisson, la forma estándar de modelar cuántas veces ocurre un evento relativamente raro en una ventana de tiempo fija.
Predecir goles en lugar de resultados es lo que permite todo lo que viene después. Una vez que el modelo puede producir un marcador plausible para cualquier duelo, las preguntas que realmente interesan —quién sale del grupo y quién levanta el trofeo— pueden responderse simulando esos marcadores miles de veces.
Cada partido se describe con un conjunto pequeño y muy seleccionado de variables:
Cada variable es estrictamente segura frente a fugas de información: solo usa datos disponibles antes del inicio del partido. Suena obvio, pero es una de las formas más fáciles de construir por accidente un modelo que parece brillante en pruebas y se cae en el mundo real.
Una idea que se quedó fuera: había planeado un conjunto de variables de "estilo de juego" construidas agrupando equipos a partir de sus estadísticas en juego, un paso de aprendizaje no supervisado. En la práctica, los equipos no se separaban en grupos con sentido, así que, en lugar de meter ruido al modelo, lo descarté. Los resultados negativos también cuentan.
Con datos que llegan de dos fuentes de forma continua, el camino desde los ficheros en bruto hasta las variables listas para el modelo debe ser idéntico cada vez. Eso es lo que aporta una arquitectura medallón. Organiza los datos en tres capas:
Cada capa alimenta a la siguiente, así que cuando algo no cuadra puedo rastrearlo hacia atrás paso a paso en lugar de deshacerlo todo de golpe. Para hacer reproducible todo el recorrido, utilizo DVC (Data Version Control). Cuando entran resultados nuevos, un único dvc repro reconstruye Silver y Gold desde Bronze, rehaciendo solo los pasos cuyos inputs han cambiado, y versiona los datasets resultantes para poder recuperar exactamente cualquier estado anterior.
Predecir goles es un problema muy estudiado y no hay una herramienta única y obvia. Así que, en lugar de casarme con un enfoque de antemano, construí diez y los dejé competir.
Los diez modelos cubren cinco familias más una línea base sencilla. No necesitas conocer las tripas de cada uno; la idea es que parten de supuestos muy distintos sobre cómo se generan los goles.
| Familia | Modelos | La idea central |
|---|---|---|
| Línea base | Poisson de tasa media | Asume que cada equipo simplemente anota un promedio global a largo plazo, ignorando todas las variables. Un suelo que los demás deben superar. |
| Estadísticos | Poisson bivariante, binomial negativa | Modelan directamente los dos conteos de goles con distribuciones diseñadas para eventos contables. |
| Bayesianos | Poisson bayesiano (MCMC) | La misma idea de conteo, pero devuelve un rango completo de incertidumbre en torno a cada estimación. Mucho más costoso de calcular: aproximadamente 100 veces más lento de ajustar que el resto. |
| Series temporales | SARIMAX | Trata los resultados de un equipo como una secuencia en el tiempo y proyecta esa secuencia hacia delante. |
| Machine learning | Ridge, Random Forest, XGBoost | Aprenden patrones directamente de las variables sin imponer una ecuación fija. |
| Deep learning | LSTM, CNN 1D | Redes neuronales que buscan patrones secuenciales y locales en los datos. |
Con diez candidatas, elegir a ojo era inviable. En su lugar, cada modelo pasa por tres etapas, y el código decide si avanza. A esto nos referimos con despliegue basado en código: los modelos se promocionan de un entorno a otro mediante comprobaciones automáticas en lugar de ajustes manuales, de modo que toda la selección se mantiene reproducible y fácil de auditar.
Entonces, ¿qué enfoque salió vencedor? Este es el ranking completo del holdout, medido por RPS (cuanto más bajo, mejor):
| Modelo | RPS en holdout |
|---|---|
| XGBoost | 0.18289 |
| Poisson bayesiano | 0.18316 |
| Binomial negativa | 0.18373 |
| Poisson bivariante | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| CNN 1D | 0.20916 |
| Poisson de tasa media (línea base) | 0.22872 |
De estos resultados destacan cuatro cosas:
 Para el torneo en directo no ejecuto los diez. Mantengo una lista reducida: la línea base de tasa media como punto de referencia, más los tres mejores. XGBoost y Poisson bayesiano ocupan los dos primeros puestos con claridad.
Para el torneo en directo no ejecuto los diez. Mantengo una lista reducida: la línea base de tasa media como punto de referencia, más los tres mejores. XGBoost y Poisson bayesiano ocupan los dos primeros puestos con claridad.
El tercer lugar es prácticamente un empate: la binomial negativa y la Poisson bivariante quedan a 0,0002 de RPS una de otra y se intercambian según la semilla aleatoria, así que, entre dos modelos estadísticamente indistinguibles, me quedé con la Poisson bivariante, cuya formulación tiene más respaldo en la literatura de predicción futbolística (Karlis y Ntzoufras, 2004).
Así queda un plantel con XGBoost (machine learning), Poisson bivariante (estadística clásica) y Poisson bayesiano (inferencia bayesiana). En la siguiente sección verás cómo se ejecutan, se reentrenan y convierten predicciones de un solo partido en un pronóstico de todo el torneo.
Un modelo que vive en un notebook solo es útil mientras estás delante. Para predecir partidos durante un mes de torneo, todo debe funcionar solo: traer resultados nuevos, reentrenar, re-simular y refrescar el pronóstico sin que nadie lo toque. Ese es el trabajo de la canalización.
Todo el proyecto se ejecuta como un único job programado en Google Cloud Run. Antes del torneo, se despierta una vez al día; desde el partido inaugural del 11 de junio, corre cada dos horas. Cada ejecución sigue el mismo ciclo:
dvc repro reconstruye las capas Silver y Gold para que las variables estén al día.Como cada paso lo dispara código en un calendario, no hay que pulsar botones manualmente durante el torneo. Entran resultados nuevos, sale el pronóstico actualizado.
Aquí es donde el proyecto hace también de experimento. Durante el torneo, el plantel corre en dos modos en paralelo, y la diferencia entre ellos es la pregunta que quiero responder con los datos: ¿reentrenar a medida que avanza el torneo mejora las predicciones?
Ejecutar ambos en paralelo me permite compararlos en dos frentes cuando acabe: precisión predictiva bruta y la velocidad a la que se resuelve la incertidumbre de cada uno a medida que se estrecha el cuadro. Si gana el modo por ronda, el reentrenamiento regular se justifica; si el congelado se mantiene, quizá no compense la maquinaria extra.
Predecir un solo partido es una cosa. Convertirlo en "cuál es la probabilidad de que cada equipo gane el torneo" es donde entra la simulación de Monte Carlo.
Primero, la inferencia. En lugar de predecir solo los partidos ya conocidos, el modelo predice todos los posibles duelos entre las 48 selecciones. Suena excesivo, pero en un torneo cualquier equipo puede encontrarse con cualquier otro en las eliminatorias, así que hay que tener una predicción lista para cada emparejamiento.
Después, hay que codificar las reglas, y el formato de 2026 lo complica especialmente. En los 12 grupos, pasan automáticamente las dos primeras, pero también las ocho mejores terceras, y en qué plaza del cuadro cae cada una de esas ocho depende de qué grupos procedan.
Hay 495 formas de elegir ocho grupos que aportan terceras de doce (doce sobre ocho), y cada una produce un set distinto de emparejamientos en dieciseisavos. No hay una fórmula limpia: la FIFA simplemente publica una tabla. Así que yo (o mejor dicho, mi muy capaz colega Cursor) codifiqué a mano las 495 combinaciones en un mapeo, usando la tabla oficial como fuente.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Cada clave, como EFGHIJKL, enumera qué ocho grupos aportaron las terceras clasificadas, y los valores colocan a cada uno de esos equipos (3E, 3F, etc.) en un número de partido concreto de dieciseisavos. Ese es un caso; el mapeo completo lo repite 495 veces, una por combinación.
Las tres anfitrionas (Estados Unidos, Canadá y México) requieren un tratamiento adicional. Cuando una anfitriona juega un partido disputado en su país, la simulación aplica un ajuste por ventaja de local para ese encuentro, mientras que el resto del torneo se trata como campo neutral.
Con las predicciones y las reglas listas, la simulación ejecuta el torneo completo 10.000 veces. En cada ejecución, sigue este procedimiento:
A lo largo de 10.000 torneos simulados, la proporción de veces que un equipo llega a la final o levanta el trofeo se convierte en su probabilidad. Una ejecución es una conjetura; diez mil son un pronóstico.
Cada ejecución descrita hasta ahora, en ambos modos, se registra en MLflow (alojado en DagsHub). El seguimiento de experimentos significa registrar de forma sistemática los inputs, la configuración, los resultados y las salidas de cada ejecución, para poder compararlas o reproducirlas exactamente. Vale la pena destacar algunas de las cosas que captura:
Los modelos entrenados y los propios ficheros de predicción (las probabilidades del torneo, las clasificaciones de grupos y los pronósticos de partidos) se guardan como artefactos de ejecución, y esos ficheros son exactamente lo que lee el dashboard en vivo. Así se cierra el círculo: de los resultados en bruto, pasando por entrenamiento y simulación, a los números que ves online.
La última pieza se ejecuta cuando se cierran los partidos. A medida que llegan los resultados reales, se puntúan las predicciones hechas para ellos y se comparan con la sencilla línea base de tasa media. Si los modelos completos empiezan a perder terreno frente a un modelo que no sabe nada de los equipos, es una señal de alerta de drift: los patrones aprendidos antes del torneo pueden no corresponderse ya con lo que sucede en el campo.
Vigilar esto es práctica habitual en cualquier sistema con predicciones en vivo, y puedes leer más sobre cómo se detecta en esta guía sobre data drift y model drift.
Después de toda esta maquinaria, aquí tienes para qué sirve.
A 10 de junio de 2026, víspera del partido inaugural, el veredicto del modelo es claro en la cima y apretado justo detrás. España y Argentina lideran el grupo, cada una con alrededor de un 16% de opciones de levantar el trofeo. Que salgan arriba las vigentes campeonas del mundo (Argentina) y de Europa (España) es una buena señal de que el modelo pisa tierra.
Tras ellas llega un grupo perseguidor muy igualado: Francia, Inglaterra, Brasil y Colombia completan el bloque de candidatas más probables. Son cifras en vivo y se moverán en cuanto empiecen a llegar resultados reales, así que tómalas como una foto del 10 de junio, no como una profecía fija. El dashboard muestra siempre los números actuales, con un retraso máximo de dos horas.
Hablando de eso: todos los números de este artículo salen de una app de Streamlit en vivo que se actualiza automáticamente a medida que corre la canalización. Puedes abrirla en wc2026-predictions.streamlit.app y seguir el torneo. Tiene cuatro vistas principales:
Un detalle a tener en cuenta en la vista de partidos: un par de equipos aparecen a la vez en dos posibles plazas de dieciseisavos. No es un bug. Ocurre cuando un grupo está tan igualado que el modelo no puede determinar con confianza qué puesto clasificatorio ocupará un equipo. Combinado con la incertidumbre de mejores terceras, los dos desenlaces llevan a plazas distintas en el cuadro. En el caso de Turquía, incluso llevó a que apareciera dos veces en octavos.
El siguiente gráfico muestra las rondas finales (de cuartos a la final) que el modelo XGBoost proyecta antes del inicio del torneo:
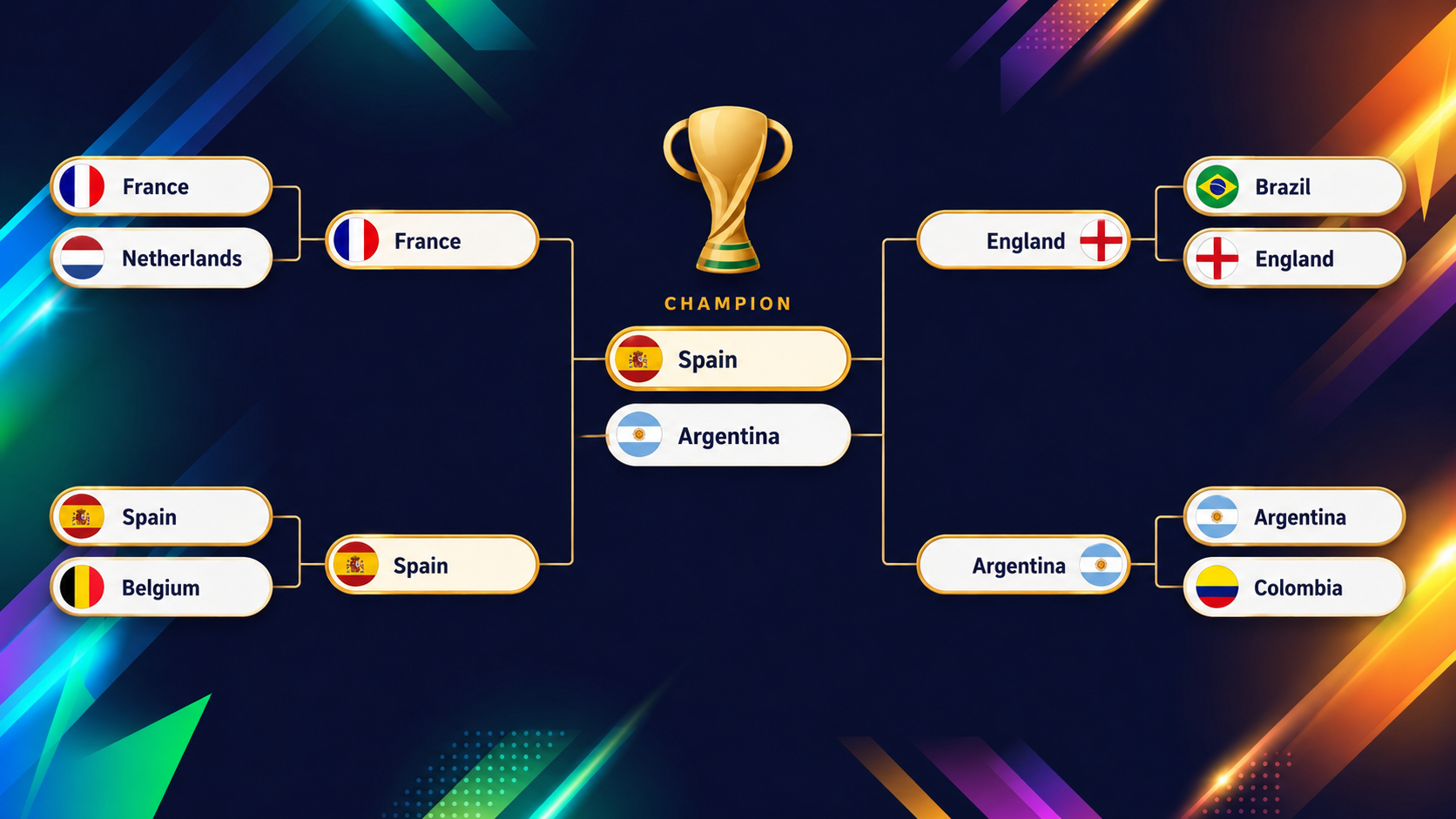
La gracia de un modelo así está en los equipos que desafían la prueba del ojo, y el ejemplo más claro son los Estados Unidos. Si vas a la visión general del torneo en el dashboard, verás enseguida que EE. UU. destaca por color.
Como coanfitriones ante su afición, podrías esperar un inicio cómodo, pero el modelo es mucho más cauto: les da solo alrededor de un 54,6% de opciones de salir del grupo, la 13.ª más baja de todo el cuadro (¡recuerda que pasan dos tercios!), porque su grupo con Australia, Paraguay y Turquía está inusualmente igualado.
Lo interesante viene después. Si pasan por los pelos, EE. UU. ronda prácticamente el cara o cruz en cada ronda siguiente. Al encadenar esos lances, aterrizan en torno a un 2% de probabilidad de ganar el torneo, la 13.ª más alta de las 48 selecciones.
Un equipo que es 13.º por la cola para salir del grupo y 13.º por arriba para ganarlo todo es casi la definición perfecta de equipo moneda al aire: nunca favorito, nunca descartado.
Este proyecto ha sido mucho trabajo y abarca mucho más de lo que cabe en un artículo. En el repo hay de todo lo que no entró aquí: el conjunto completo de modelos candidatos, la ingeniería de variables y la orquestación que mantiene todo en marcha, por ejemplo.
Por ahora, el modelo ha hecho sus apuestas y el torneo será el juez. Hayas venido por MLOps o por el fútbol, espero que disfrutes viéndolo desarrollarse tanto como yo. Puedes seguir el pronóstico en vivo a medida que entren los partidos y comprobar lo bien que aguantan las predicciones.
Si quieres profundizar en algunos de los conceptos que he mencionado, te recomiendo nuestro curso MLOps Concepts.
Los mejores cursos de machine learning
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Natassha Selvaraj
15 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
7 min
blog
Javier Canales Luna
8 min
Tutorial
Josep Ferrer


