Courses
Understanding Machine Learning
2 ชม.
299.3K
คุณภาพของการทำนายดีได้เท่ากับสิ่งที่ใส่เข้าไป จึงควรเริ่มจากวัตถุดิบ โมเดลเรียนรู้จากแหล่งข้อมูลสดสองแหล่งและแปลงให้เป็นตารางฟีเจอร์ที่เป็นระเบียบเพียงชุดเดียว
ทุกอย่างเริ่มจากสองแหล่งนี้ API-Football จัดหาโปรแกรมแข่งและสถิติต่อแมตช์: ใครพบใคร เมื่อไหร่ ที่ไหน และจบอย่างไร ส่วน eloratings.net จัดอันดับ Elo ให้ทุกทีมชาติ
คะแนน Elo คือเลขเดียวที่สะท้อนความแข็งแกร่งของทีม ทุกทีมอยู่บนสเกลนี้ และหลังจบแต่ละนัด คะแนนจะอัปเดต: ชนะทีมที่แข็งกว่าได้มาก แพ้ทีมที่อ่อนกว่าก็ตกฮวบ ไอเดียมาจากหมากรุกและปรับใช้กับฟุตบอลได้ลงตัว หากอยากเข้าใจแบบเต็มๆ บทความ DataCamp ก่อนหน้านี้อธิบายในบริบทฟุตบอลโลก 2022
เมื่อนำมารวมกัน แหล่งข้อมูลทั้งสองให้ Gold dataset ราว 6,900 แมตช์ทีมชาติตั้งแต่ปี 2018 ให้เรียนรู้
นี่คือการออกแบบสำคัญข้อแรก แทนที่จะทำนายผลเป็น ชนะ เสมอ แพ้ โดยตรง โมเดลจะทำนายสิ่งที่ละเอียดกว่า: จำนวนประตูที่แต่ละทีมทำได้ในแมตช์หนึ่ง จำนวนประตูในฟุตบอลโดยประมาณตาม การกระจายแบบปัวซอง ซึ่งเป็นวิธีมาตรฐานในการจำลองเหตุการณ์ที่เกิดไม่บ่อยภายในช่วงเวลาคงที่
การทำนายประตูแทนผลการแข่งขันคือสิ่งที่ทำให้ทุกอย่างต่อจากนี้เป็นไปได้ เมื่อโมเดลให้สกอร์ไลน์สมเหตุสมผลได้สำหรับทุกคู่คำถามที่ทุกคนสนใจจริงๆ เช่น ใครจะผ่านรอบแบ่งกลุ่มและใครจะชูถ้วย แก้ได้ด้วยการจำลองสกอร์ไลน์เหล่านั้นเป็นพันๆ ครั้ง
แต่ละแมตช์อธิบายด้วยชุดฟีเจอร์เล็กๆ ที่คัดสรรมาอย่างตั้งใจ:
ทุกฟีเจอร์ป้องกันการรั่วไหลอย่างเคร่งครัด หมายถึงใช้เฉพาะข้อมูลที่มีอยู่ก่อนเขี่ยลูกเริ่มเกม ฟังดูชัดเจน แต่เป็นวิธีที่เผลอสร้างโมเดลที่ดูดีในเทสแต่พังในโลกจริงได้ง่ายมาก
อีกไอเดียที่ตัดออก: เดิมตั้งใจทำฟีเจอร์ "สไตล์การเล่น" ด้วยการจัดกลุ่มทีมจากสถิติในเกม เป็นขั้นตอน การเรียนรู้แบบไม่มีผู้สอน แต่ในทางปฏิบัติทีมไม่แยกเป็นกลุ่มที่มีความหมาย จึงเลือกไม่ป้อนสัญญาณรบกวนให้โมเดล ผลลบก็ยังเป็นผลลัพธ์
เมื่อข้อมูลไหลเข้าจากสองแหล่งอย่างต่อเนื่อง เส้นทางจากไฟล์ดิบไปถึงฟีเจอร์พร้อมเทรนต้องเหมือนเดิมทุกครั้ง ซึ่ง สถาปัตยกรรมเหรียญตรา ช่วยได้ โดยแบ่งข้อมูลเป็นสามชั้น:
แต่ละชั้นป้อนให้ชั้นถัดไป เมื่อมีอะไรแปลก สามารถไล่ย้อนทีละสเตจแทนการแก้ทุกอย่างพร้อมกัน เพื่อให้เส้นทางทั้งหมดทำซ้ำได้ ผมใช้ DVC (Data Version Control) ทุกครั้งที่มีผลสดเข้ามา คำสั่งเดียว dvc repro จะสร้าง Silver และ Gold จาก Bronze ใหม่ โดยรันเฉพาะสเตจที่อินพุตเปลี่ยน และเวอร์ชันชุดข้อมูลที่ได้เพื่อย้อนกลับสถานะก่อนหน้าได้เป๊ะ
การทำนายจำนวนประตูเป็นโจทย์ที่มีการศึกษาอย่างกว้างและไม่มีเครื่องมือเดียวที่ชัดเจน ดังนั้นแทนที่จะเลือกวิธีเดียวตั้งแต่แรก ผมสร้างไว้สิบโมเดลแล้วให้แข่งกัน
สิบโมเดลครอบคลุมห้าตระกูลพร้อมเบสไลน์ง่ายๆ ไม่จำเป็นต้องรู้กลไกภายใน จุดสำคัญคือแต่ละแบบตั้งสมมติฐานต่างกันมากว่าประตูเกิดขึ้นอย่างไร
| ตระกูล | โมเดล | แนวคิดหลัก |
|---|---|---|
| เบสไลน์ | Mean-rate Poisson | สมมติว่าทุกทีมยิงได้ตามค่าเฉลี่ยระยะยาวโดยรวม ไม่สนฟีเจอร์ เป็นฐานให้โมเดลอื่นต้องชนะให้ได้ |
| สถิติ | Bivariate Poisson, Negative Binomial | จำลองจำนวนประตูสองฝั่งโดยตรงด้วยการกระจายความน่าจะเป็นสำหรับเหตุการณ์นับจำนวน |
| เบย์esian | Bayesian Poisson (MCMC) | แนวคิดการนับแบบเดียวกัน แต่ให้ช่วงความไม่แน่นอนเต็มรอบค่าประมาณ คำนวณหนักกว่ามาก: ใช้เวลาฝึกสอนช้ากว่าประมาณ 100 เท่า |
| อนุกรมเวลา | SARIMAX | มองผลงานทีมเป็นลำดับตามเวลาและคาดการณ์ต่อไปข้างหน้า |
| แมชชีนเลิร์นนิง | Ridge, Random Forest, XGBoost | เรียนรู้แพทเทิร์นจากฟีเจอร์โดยไม่ผูกติดกับสมการตายตัว |
| ดีปเลิร์นนิง | LSTM, 1D CNN | โครงข่ายประสาทที่ค้นหาแพทเทิร์นเชิงลำดับและเชิงเฉพาะที่ในข้อมูล |
มีผู้สมัครสิบราย เลือกผู้ชนะด้วยสายตาย่อมไม่ได้ แต่ละโมเดลจึงผ่านสามสเตจ และให้โค้ดตัดสินว่าจะไปต่อหรือไม่ นี่คือความหมายของ code-based deployment: โมเดลถูกเลื่อนชั้นจากสภาพแวดล้อมหนึ่งไปอีกที่ด้วยการตรวจสอบอัตโนมัติแทนการจูนมือ ทำให้กระบวนการคัดเลือกทำซ้ำได้และตรวจสอบย้อนหลังง่าย
แล้ววิธีไหนชนะ? นี่คือกระดานผู้นำบนชุดทดสอบ วัดด้วย RPS (ยิ่งต่ำยิ่งดี):
| โมเดล | RPS ชุดทดสอบ |
|---|---|
| XGBoost | 0.18289 |
| Bayesian Poisson | 0.18316 |
| Negative Binomial | 0.18373 |
| Bivariate Poisson | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Mean-rate Poisson (เบสไลน์) | 0.22872 |
มีสี่ประเด็นที่โดดเด่นจากผลลัพธ์นี้:
 สำหรับทัวร์นาเมนต์สด ผมไม่รันทั้งสิบ จะเก็บรายชื่อเล็กลง: เบสไลน์แบบค่าเฉลี่ยเป็นจุดอ้างอิง บวกสามผู้ทำผลงานดีที่สุด XGBoost และ Bayesian Poisson ครองสองอันดับแรก
สำหรับทัวร์นาเมนต์สด ผมไม่รันทั้งสิบ จะเก็บรายชื่อเล็กลง: เบสไลน์แบบค่าเฉลี่ยเป็นจุดอ้างอิง บวกสามผู้ทำผลงานดีที่สุด XGBoost และ Bayesian Poisson ครองสองอันดับแรก
อันดับสามแทบเสมอกัน: Negative Binomial และ Bivariate Poisson ห่างกันเพียง 0.0002 RPS และสลับอันดับตาม seed แบบสุ่ม ระหว่างสองโมเดลที่แยกกันทางสถิติไม่ออก ผมเลือก Bivariate Poisson เพราะนิยามยืนบนฐานวรรณกรรมการทำนายฟุตบอลที่แข็งแรงกว่า (Karlis และ Ntzoufras, 2004)
รายชื่อสุดท้ายคือ XGBoost (แมชชีนเลิร์นนิง), Bivariate Poisson (สถิติเชิงคลาสสิก) และ Bayesian Poisson (อนุมานแบบเบย์) ส่วนถัดไปจะอธิบายว่าโมเดลเหล่านี้รัน ฝึกสอนใหม่ และแปลงการทำนายแมตช์เดี่ยวเป็นพยากรณ์ทั้งทัวร์นาเมนต์อย่างไร
โมเดลที่อยู่ในโน้ตบุ๊กมีประโยชน์แค่ตอนนั่งอยู่หน้ามัน เพื่อทำนายแมตช์ยาวตลอดเดือน ทั้งระบบต้องรันเอง: ดึงผลสด ฝึกสอนใหม่ จำลองใหม่ และรีเฟรชพยากรณ์โดยไม่ต้องให้ใครไปกดปุ่ม นั่นคือหน้าที่ของท่อส่งงาน
โปรเจกต์ทั้งหมดรันเป็นงานตามกำหนดการเพียงงานเดียวบน Google Cloud Run ก่อนทัวร์นาเมนต์จะปลุกวันละครั้ง ตั้งแต่นัดเปิดวันที่ 11 มิถุนายน จะรันทุกสองชั่วโมง ทุกครั้งทำตามวัฏจักรเดียวกัน:
dvc repro ครั้งเดียวจะสร้างชั้น Silver และ Gold ใหม่ให้ฟีเจอร์เป็นปัจจุบันเพราะทุกขั้นถูกทริกเกอร์ด้วยโค้ดตามตาราง จึงไม่ต้องกดปุ่มมือระหว่างทัวร์นาเมนต์ ผลใหม่เข้า พยากรณ์ใหม่ออก
ตรงนี้โปรเจกต์ทำหน้าที่เป็นการทดลองไปด้วย ระหว่างทัวร์นาเมนต์ รายชื่อโมเดลจะรันสองโหมดคู่ขนาน และความต่างระหว่างสองโหมดคือคำถามที่หวังให้ข้อมูลช่วยตอบ: การฝึกสอนใหม่ระหว่างรายการช่วยให้แม่นขึ้นหรือไม่?
การรันคู่กันช่วยให้เทียบได้สองมุมหลังจบ: ความแม่นยำ และความเร็วที่ความไม่แน่นอนลดลงเมื่อสนามแคบลง หากโหมดต่อรอบชนะ การฝึกใหม่เป็นประจำก็คุ้ม หากโหมดคงที่ไหว เครื่องไม้เครื่องมือเพิ่มเติมอาจไม่จำเป็น
การทำนายแมตช์เดียวเป็นอย่างหนึ่ง การแปลงให้เป็น "โอกาสคว้าแชมป์ของแต่ละทีม" คือจุดที่การจำลองมอนติคาร์โลเข้ามา
เริ่มจากการอนุมาน แทนที่จะทำนายเฉพาะโปรแกรมที่รู้แล้ว โมเดลจะทำนายทุกคู่ที่เป็นไปได้ของ 48 ทีม ฟังดูเกินจำเป็น แต่ในทัวร์นาเมนต์ ทีมใดก็อาจเจอทีมใดในรอบน็อกเอาต์ได้ จึงต้องพร้อมสำหรับทุกคู่
ต่อไปต้องเข้ารหัสกติกา ซึ่งฟอร์แมตปี 2026 ทำให้ยุ่งเป็นพิเศษ ใน 12 กลุ่ม สองทีมแรกเข้ารอบอัตโนมัติ และอันดับสามที่ดีที่สุด 8 ทีมก็เข้ารอบด้วย ตำแหน่งในรอบ 32 ทีมของทั้งแปดนั้นขึ้นกับว่ามาจากกลุ่มใด
มี 495 วิธีในการเลือกแปดกลุ่มจากสิบสองกลุ่ม (สิบสองเลือกแปด) และแต่ละแบบให้ผังกรอบ 32 ทีมต่างกัน ไม่มีสูตรสะอาดๆ FIFA แค่เผยแพร่ตาราง ดังนั้นผม (หรือพูดให้ถูกคือเพื่อนร่วมงานผู้เชี่ยวชาญ Cursor) จึงฮาร์ดโค้ดทั้ง 495 กรณีลงในแมปปิง โดยใช้ตารางทางการเป็นแหล่งอ้างอิง
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...แต่ละคีย์อย่าง EFGHIJKL ระบุว่ากลุ่มใดแปดกลุ่มที่ส่งทีมอันดับสามเข้ารอบ และค่าในนั้นจะจับคู่แต่ละทีม (3E, 3F เป็นต้น) เข้ากับหมายเลขแมตช์ในรอบ 32 ทีม นี่เป็นเพียงตัวอย่างเดียว แมปปิงเต็มทำซ้ำแบบนี้ 495 ครั้ง ตามทุกชุดความเป็นไปได้
สามเจ้าภาพ (สหรัฐฯ แคนาดา และเม็กซิโก) ต้องจัดการพิเศษหนึ่งอย่าง เมื่อเจ้าภาพลงสนามในประเทศของตน การจำลองจะใช้ตัวปรับแต่งความได้เปรียบเจ้าบ้านสำหรับแมตช์นั้น ส่วนที่เหลือถือเป็นสนามกลาง
เมื่อการทำนายและกติกาพร้อม การจำลองจะรันทัวร์นาเมนต์ทั้งหมด 10,000 ครั้ง ในแต่ละครั้งจะทำขั้นตอนดังนี้:
ตลอด 10,000 ทัวร์นาเมนต์จำลอง สัดส่วนครั้งที่ทีมหนึ่งๆ เข้าชิงหรือคว้าแชมป์จะกลายเป็นความน่าจะเป็นของทีมนั้น การจำลองครั้งเดียวคือการเดา สิบพันครั้งคือพยากรณ์
ทุกการรันทั้งสองโหมด ถูกบันทึกไว้ใน MLflow (โฮสต์บน DagsHub) การติดตามการทดลองหมายถึงการบันทึกอินพุต การตั้งค่า ผลลัพธ์ และเอาต์พุตของแต่ละรันอย่างเป็นระบบ เพื่อให้เปรียบเทียบกันได้หรือทำซ้ำได้เป๊ะ จุดที่น่าสังเกตบางอย่างได้แก่:
โมเดลที่ฝึกแล้วและไฟล์การทำนาย (ความน่าจะเป็นของทัวร์นาเมนต์ ตารางคะแนนกลุ่ม และพยากรณ์แมตช์) ถูกเก็บเป็นอาร์ติแฟกต์ของรัน และไฟล์เหล่านี้เองที่แดชบอร์ดสดอ่าน ปิดลูปตั้งแต่ผลดิบ ผ่านการฝึกและการจำลอง ไปจนถึงตัวเลขที่เห็นออนไลน์
ชิ้นส่วนสุดท้ายรันเมื่อแมตช์ตัดสิน เมื่อผลจริงเข้ามา จะให้คะแนนการทำนายที่ทำไว้และเปรียบเทียบกับเบสไลน์แบบค่าเฉลี่ย หากโมเดลเต็มเริ่มแพ้ให้กับโมเดลที่ไม่รู้อะไรเกี่ยวกับทีม นั่นคือสัญญาณเตือนการดริฟต์: แพทเทิร์นที่เรียนรู้ก่อนทัวร์นาเมนต์อาจไม่ตรงกับสิ่งที่เกิดขึ้นในสนามอีกต่อไป
การเฝ้าดูสิ่งนี้เป็นมาตรฐานสำหรับระบบพยากรณ์สดใดๆ และอ่านเพิ่มเติมได้จากคู่มือเรื่อง data drift และ model drift
หลังจากเครื่องไม้เครื่องมือทั้งหมด นี่คือสิ่งที่สร้างมาเพื่อมัน
ณ วันที่ 10 มิถุนายน 2026 วันก่อนเปิดสนาม คำตัดสินของโมเดลชัดเจนที่หัวตารางและแน่นขนัดถัดลงมา สเปนและอาร์เจนตินานำหน้าด้วยโอกาสชูถ้วยราว 16% เท่ากัน ที่แชมป์โลก (อาร์เจนตินา) และแชมป์ยุโรป (สเปน) ออกมานำ ถือเป็นเช็คความสมเหตุสมผลที่ดีว่าโมเดลยืนบนความจริง
ด้านหลังมีขบวนไล่ล่าที่สูสีกัน ฝรั่งเศส อังกฤษ บราซิล และโคลอมเบียคือผู้ท้าชิงแชมป์ที่น่าจะเป็นไปได้มากที่สุด ตัวเลขเหล่านี้เป็นแบบสดและจะขยับทันทีที่ผลจริงเริ่มมา จึงควรมองเป็นภาพวันที่ 10 มิถุนายน ไม่ใช่คำทำนายตายตัว แดชบอร์ดจะแสดงตัวเลขล่าสุดเสมอด้วยดีเลย์สูงสุดสองชั่วโมง
พูดถึงตรงนี้: ทุกตัวเลขในบทความนี้มาจากแอป Streamlit สดที่อัปเดตอัตโนมัติเมื่อท่อส่งงานรัน เปิดได้ที่ wc2026-predictions.streamlit.app เพื่อติดตามทัวร์นาเมนต์ มีสี่มุมมองหลัก:
ข้อสังเกตหนึ่งในมุมมองแมตช์: บางทีมอาจปรากฏในสองช่องรอบ 32 ทีมพร้อมกัน นั่นไม่ใช่บั๊ก เกิดเมื่อกลุ่มสูสีมากจนโมเดลบอกตำแหน่งเข้ารอบของทีมได้ไม่มั่นใจ พอรวมกับความไม่แน่นอนของอันดับสามที่ดีที่สุด ผลสองแบบนำไปสู่ช่องน็อกเอาต์ต่างกัน ในกรณีของตุรกี ถึงขั้นทำให้พวกเขาอยู่ในรอบ 16 ทีมสองครั้ง
กราฟิกต่อไปนี้แสดงรอบสุดท้าย (ตั้งแต่รอบก่อนรองชนะเลิศจนถึงนัดชิง) ที่โมเดล XGBoost คาดการณ์ก่อนเปิดทัวร์นาเมนต์:
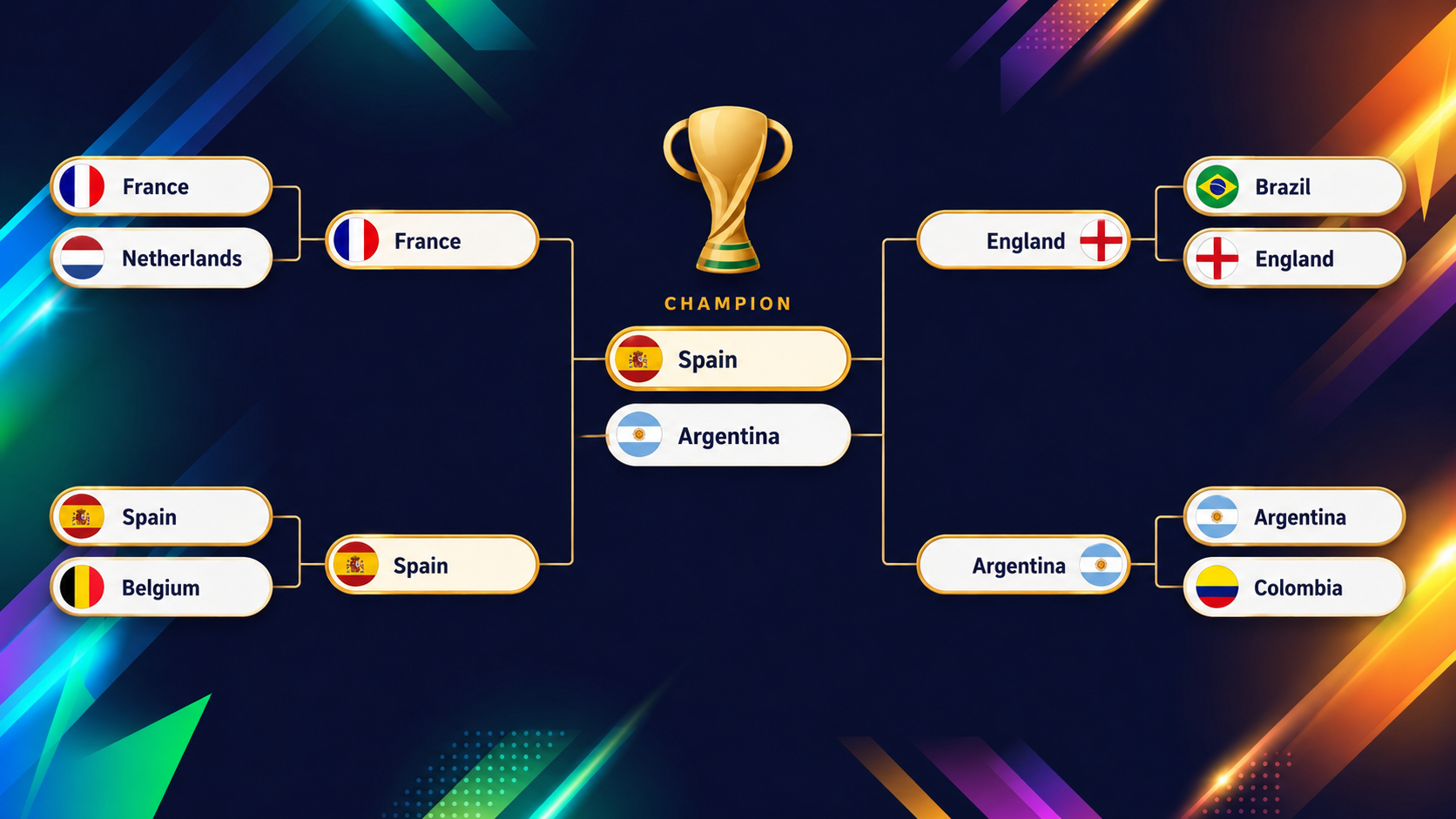
ความสนุกของโมเดลแบบนี้อยู่ที่ทีมที่สวนทางสายตา และตัวอย่างชัดที่สุดคือสหรัฐอเมริกา หากเปิดดูภาพรวมทัวร์นาเมนต์บนแดชบอร์ด จะเห็นชัดว่าสหรัฐฯ โดดเด่นด้วยสี
ในฐานะเจ้าภาพร่วม เล่นต่อหน้าแฟนบอลในบ้าน อาจคาดว่าออกสตาร์ตสบาย แต่โมเดลระมัดระวังกว่ามาก: ให้โอกาสผ่านรอบแบ่งกลุ่มเพียงราว 54.6% ซึ่งต่ำเป็นอันดับ 13 ของทั้งสนาม (จำไว้ว่าสองในสามของทีมจะเข้ารอบ!) เพราะกลุ่มที่มีออสเตรเลีย ปารากวัย และตุรกี สูสีกันผิดปกติ
ที่น่าสนใจคือหลังจากนั้น เมื่อลอดรอดมาได้ สหรัฐฯ จะอยู่ที่ระดับเหรียญโยนแทบทุกรอบที่ตามมา เมื่อนำโอกาสเหรียญโยนต่อเนื่องมาคูณกัน จะได้โอกาสคว้าแชมป์รวมราว 2% ซึ่งสูงเป็นอันดับ 13 จาก 48 ทีม
ทีมที่อยู่อันดับ 13 จากท้ายในการเข้ารอบแบ่งกลุ่ม และอันดับ 13 จากหัวในการคว้าแชมป์ น่าจะเป็นคำจำกัดความที่ลงตัวของ “ทีมเหรียญโยน”: ไม่เคยเป็นตัวเต็ง แต่อย่าเพิ่งนับว่าหมดลุ้น
โปรเจกต์นี้ใช้แรงไม่น้อย และครอบคลุมมากกว่าที่บทความเดียวจะใส่ได้ repo มีอีกมากที่ไม่ทันเล่า: ชุดผู้สมัครโมเดลเต็ม เทคนิคฟีเจอร์ และการจัดการที่ทำให้ทุกอย่างรันได้ต่อเนื่อง เป็นต้น
ตอนนี้โมเดลเลือกฝั่งแล้ว และสนามหญ้าจะเป็นผู้พิพากษา ไม่ว่ามาเพราะ MLOps หรือฟุตบอล หวังว่าจะสนุกไปกับการลุ้นเช่นเดียวกับผม ติดตาม พยากรณ์สด เมื่อผลการแข่งขันหลั่งไหลเข้ามา และดูว่าการทำนายจะยืนระยะได้แค่ไหน
หากอยากเจาะลึกแนวคิดที่กล่าวถึง แนะนำคอร์ส MLOps Concepts ของเรา
คอร์ส Machine Learning แนะนำ
Courses
Courses
Courses