
Cursus
Inzicht in Machine Learning
2 Hr
299.3K
Een voorspelling is maar zo goed als wat je erin stopt, dus het is de moeite waard om te beginnen bij de grondstoffen. Het model leert van twee live databronnen en zet die om in één nette featuretabel.
Alles is opgebouwd uit twee bronnen. API-Football levert het speelschema en wedstrijdstatistieken: wie tegen wie, wanneer, waar en hoe het eindigde. eloratings.net levert Elo-ratings voor elk nationaal team.
Een Elo-rating is één getal dat aangeeft hoe sterk een team is. Elk team staat ergens op die schaal, en na elke wedstrijd wordt de rating bijgewerkt: win van een sterkere tegenstander en je wint veel; verlies van een zwakkere en je zakt flink. Het idee komt uit het schaken en past goed op voetbal. Wil je de volledige intuïtie, dan loopt dit eerdere DataCamp-stuk erdoorheen in de context van het WK 2022.
Samen leveren de twee bronnen een Gold-dataset op van ongeveer 6.900 interlands sinds 2018 om van te leren.
Hier komt de eerste belangrijke ontwerpkeuze. In plaats van de uitkomst direct te voorspellen als winst, gelijk of verlies, voorspelt het model iets fijnmazigers: het aantal doelpunten dat elk team in een wedstrijd maakt. Doelpuntentellingen in voetbal volgen, bij benadering, een Poissonverdeling, de standaardmanier om te modelleren hoe vaak een relatief zeldzame gebeurtenis plaatsvindt in een vaste tijdsperiode.
Doelpunten in plaats van uitslagen voorspellen maakt alles wat volgt mogelijk. Zodra het model een plausibele score kan produceren voor elke matchup, kun je de vragen waar het iedereen om te doen is — wie overleeft de groep en wie tilt de beker — beantwoorden door die scorelijnen duizenden keren te simuleren.
Elke wedstrijd wordt beschreven door een kleine, zorgvuldig gekozen set features:
Elke feature is strikt lekvrij, wat betekent dat elke alleen informatie gebruikt die vóór de aftrap beschikbaar was. Dat klinkt vanzelfsprekend, maar het is een van de makkelijkste manieren om per ongeluk een model te bouwen dat in tests briljant oogt en in de praktijk instort.
Eén idee haalde het niet: ik had een set "speelstijl"-features gepland, gebouwd door teams te clusteren op basis van hun in-game statistieken, een stap met unsupervised learning. In de praktijk scheidden de teams zich niet in betekenisvolle groepen, dus in plaats van het model met ruis te voeden, heb ik het geschrapt. Negatieve resultaten zijn ook resultaten.
Omdat data doorlopend uit twee bronnen binnenkomt, moet het pad van ruwe bestanden naar modelklare features elke keer identiek zijn. Dat is wat een medallionarchitectuur biedt. Die organiseert data in drie lagen:
Elke laag voedt de volgende, zodat ik, wanneer iets vreemd lijkt, het stap voor stap kan terugtraceren in plaats van alles in één keer te moeten ontwarren. Om het hele pad reproduceerbaar te maken, gebruik ik DVC (Data Version Control). Telkens wanneer nieuwe uitslagen binnenkomen, bouwt één dvc repro Silver en Gold opnieuw op uit Bronze, voert een stap alleen opnieuw uit als de inputs zijn gewijzigd en versieert de resulterende datasets zodat elke eerdere staat exact kan worden teruggehaald.
Doelpunten voorspellen is een goed bestudeerd probleem en er is geen één evident hulpmiddel voor. Dus in plaats van vooraf één aanpak te kiezen, bouwde ik er tien en liet ik ze concurreren.
De tien modellen bestrijken vijf families plus een eenvoudige baseline. Je hoeft de interne werking van elk model niet te kennen; het punt is dat ze heel verschillende aannames maken over hoe doelpunten tot stand komen.
| Familie | Modellen | Het kernidee |
|---|---|---|
| Baseline | Poisson met gemiddeld tempo | Neemt aan dat elk team simpelweg een langetermijngemiddelde scoort en negeert alle features. Een ondergrens voor de anderen om te verslaan. |
| Statistisch | Bivariate Poisson, Negatieve binomiaal | Modelleer de twee doelpuntentellingen direct met kansverdelingen voor telgebeurtenissen. |
| Bayesiaans | Bayesiaanse Poisson (MCMC) | Hetzelfde telidee, maar dan met een volledig onzekerheidsbereik rond elke schatting. Veel zwaarder om te berekenen: grofweg 100 keer trager te fitten dan de rest. |
| Tijdreeks | SARIMAX | Behandelt de resultaten van een team als een sequentie in de tijd en projecteert die door. |
| Machine learning | Ridge, Random Forest, XGBoost | Leert patronen rechtstreeks uit de features zonder zich te binden aan een vaste vergelijking. |
| Deep learning | LSTM, 1D CNN | Neurale netwerken die op zoek gaan naar sequentiële en lokale patronen in de data. |
Met tien kandidaten was een winnaar met het blote oog kiezen onbegonnen werk. In plaats daarvan doorloopt elk model drie fases, en de code bepaalt of het door mag. Dit is wat codegebaseerde deployment betekent: modellen worden gepromoveerd van de ene omgeving naar de volgende door geautomatiseerde checks in plaats van handmatige afstemming, zodat de hele selectie reproduceerbaar en goed te auditen blijft.
Welke aanpak kwam als beste uit de bus? Hier is het volledige holdout-leaderboard, beoordeeld met RPS (lager is beter):
| Model | Holdout RPS |
|---|---|
| XGBoost | 0.18289 |
| Bayesiaanse Poisson | 0.18316 |
| Negatieve binomiaal | 0.18373 |
| Bivariate Poisson | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Poisson met gemiddeld tempo (baseline) | 0.22872 |
Vier dingen vallen op aan deze resultaten:
 Voor het live toernooi draai ik niet alle tien. Ik houd een kleinere selectie aan: de baseline met gemiddeld tempo als referentiepunt, plus de drie beste presteerders. XGBoost en Bayesiaanse Poisson pakken de bovenste twee plekken.
Voor het live toernooi draai ik niet alle tien. Ik houd een kleinere selectie aan: de baseline met gemiddeld tempo als referentiepunt, plus de drie beste presteerders. XGBoost en Bayesiaanse Poisson pakken de bovenste twee plekken.
De derde plek is feitelijk een gelijkspel: de Negatieve binomiaal en Bivariate Poisson eindigen binnen 0,0002 RPS van elkaar en wisselen van plek afhankelijk van de random seed, dus tussen twee statistisch niet te onderscheiden modellen koos ik voor de Bivariate Poisson, waarvan de formulering sterker verankerd is in de voetbalvoorspellingsliteratuur (Karlis en Ntzoufras, 2004).
Dat laat een selectie over van XGBoost (machine learning), Bivariate Poisson (klassieke statistiek) en Bayesiaanse Poisson (Bayesiaanse inferentie). In de volgende sectie staat hoe die modellen draaien, hertrainen en voorspellingen per wedstrijd omzetten in een toernooiverwachting.
Een model dat in een notebook leeft, is alleen nuttig zolang je ervoor zit. Om wedstrijden gedurende een toernooi van een maand te voorspellen, moet alles uit zichzelf draaien: nieuwe uitslagen ophalen, hertrainen, opnieuw simuleren en de verwachting verversen zonder dat iemand iets hoeft te doen. Dat is het werk van de pijplijn.
Het hele project draait als één geplande job op Google Cloud Run. Voor het toernooi wordt het één keer per dag wakker; vanaf de openingswedstrijd op 11 juni draait het elke twee uur. Elke run volgt dezelfde cyclus:
dvc repro de Silver- en Gold-lagen opnieuw op zodat de features actueel zijn.Omdat elke stap door code op schema wordt getriggerd, is er tijdens het toernooi geen handmatig knopgedruk. Nieuwe uitslag erin, vernieuwde verwachting eruit.
Hier fungeert het project ook als experiment. Tijdens het toernooi draaien de modellen parallel in twee modi, en het verschil ertussen is de vraag die ik met data wil beantwoorden: Maakt hertrainen terwijl het toernooi vordert de voorspellingen beter?
Beide naast elkaar laten lopen maakt het mogelijk ze achteraf op twee fronten te vergelijken: de ruwe voorspellende nauwkeurigheid en hoe snel de onzekerheid van elk model afneemt naarmate het veld uitdunt. Als per ronde wint, is regelmatig hertrainen de moeite waard; als bevroren zich staande houdt, is de extra machinekamer misschien niet nodig.
Eén wedstrijd voorspellen is één ding. Dat omzetten naar "wat is de kans dat elk team het toernooi wint" is waar de Monte Carlo-simulatie binnenkomt.
Eerst inferentie. In plaats van alleen de al bekende affiches te voorspellen, voorspelt het model elke mogelijke matchup tussen de 48 teams. Dat klinkt overdreven, maar in een toernooi kan elk team elk ander treffen in de knock-outs, dus er moet voor elke koppeling een voorspelling klaarstaan.
Vervolgens moeten de regels worden gecodeerd, en het format van 2026 maakt dat extra lastig. In de 12 groepen gaan de beste twee automatisch door, maar ook de acht beste nummers drie, en welke knock-outplek elk van die acht krijgt hangt af van uit welke groepen ze komen.
Er zijn 495 manieren om acht kwalificerende groepen uit twaalf te kiezen (twaalf boven acht), en elke combinatie levert een andere set affiches voor de ronde van 32 op. Er is geen nette formule voor; FIFA publiceert simpelweg een tabel. Dus heb ik (of beter gezegd mijn zeer capabele collega Cursor) alle 495 combinaties hardgecodeerd in een mapping, met de officiële tabel als bron.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Elke sleutel, zoals EFGHIJKL, geeft aan uit welke acht groepen de doorgeschoven nummers drie kwamen, en de waarden plaatsen elk van die teams (3E, 3F, enzovoort) in een specifiek wedstrijdnummer in de ronde van 32. Dat is één item; de volledige mapping herhaalt dit 495 keer, één per combinatie.
De drie gastlanden (de Verenigde Staten, Canada en Mexico) krijgen nog een extra behandeling. Als een gastland speelt in eigen land, past de simulatie voor die wedstrijd een thuisvoordeelcorrectie toe, terwijl de rest van het toernooi als neutraal terrein wordt behandeld.
Met de voorspellingen en de regels op hun plek draait de simulatie het hele toernooi 10.000 keer. In elke run volgt het deze procedure:
Over 10.000 gesimuleerde toernooien wordt het aandeel runs waarin een team de finale haalt, of de beker pakt, de kans voor dat team. Eén run is een gok; tienduizend runs is een voorspelling.
Elke run tot nu toe, in beide modi, wordt gelogd in MLflow (gehost op DagsHub). Experimenttracking betekent dat je de inputs, instellingen, resultaten en outputs van elke run systematisch vastlegt, zodat ze met elkaar vergeleken of exact gereproduceerd kunnen worden. Een paar zaken die het vastlegt zijn het noemen waard:
De getrainde modellen en de voorspellingsbestanden zelf (de toernooikansen, groepsstanden en wedstrijdvoorspellingen) worden opgeslagen als run-artifacts, en precies die bestanden leest het live dashboard. Daarmee is de cirkel rond: van ruwe uitslagen, via training en simulatie, naar de cijfers die je online ziet.
Het laatste onderdeel draait zodra wedstrijden zijn beslist. Als echte uitslagen binnenkomen, worden de daarvoor gemaakte voorspellingen gescoord en vergeleken met de eenvoudige baseline met gemiddeld tempo. Als de volledige modellen terrein verliezen ten opzichte van een model dat niets weet over de teams, is dat een waarschuwingssignaal voor drift: de patronen die vóór het toernooi zijn geleerd, sluiten mogelijk niet meer aan op wat er op het veld gebeurt.
Hierop letten is standaardpraktijk voor elk systeem dat live voorspellingen doet, en je kunt meer lezen over hoe dit wordt gedetecteerd in deze gids over datadrift en modeldrift.
Na al die machinekamer, hier is waar het om draait.
Op 10 juni 2026, de dag voor de openingswedstrijd, is het oordeel van het model aan de top duidelijk en daarachter dicht op elkaar. Spanje en Argentinië gaan aan de leiding, elk met ongeveer 16% kans om de beker te pakken. Dat de regerend wereldkampioen (Argentinië) en de regerend Europees kampioen (Spanje) bovenaan staan, is een geruststellende sanity check dat het model in de realiteit geworteld is.
Daarachter zit een compact jagend peloton: Frankrijk, Engeland, Brazilië en Colombia maken de meest waarschijnlijke winnaars compleet. Dit zijn live cijfers en ze bewegen zodra echte resultaten binnenkomen, dus beschouw ze als een momentopname van 10 juni en niet als een vaststaand orakel. Het dashboard toont altijd de huidige cijfers, met maximaal twee uur vertraging.
Daarover gesproken: elk getal in dit artikel komt uit een live Streamlit-app die automatisch bijwerkt terwijl de pijplijn draait. Je opent hem op wc2026-predictions.streamlit.app en kunt het toernooi volgen. Er zijn vier hoofdweergaven:
Eén eigenaardigheid om te noemen in de wedstrijdweergave: een paar teams verschijnen tegelijk op twee mogelijke plekken in de ronde van 32. Dat is geen bug. Het gebeurt wanneer een groep zo in balans is dat het model niet met vertrouwen kan zeggen welke kwalificatiepositie een team inneemt. In combinatie met de onzekerheid rond de beste derdes leiden de twee uitkomsten tot verschillende knock-outplekken. In het geval van Turkije leidde het er zelfs toe dat ze twee keer in de achtste finale stonden.
De volgende grafiek toont de laatste rondes (kwartfinales tot en met de finale) die het XGBoost-model projecteert vóór de aftrap van het toernooi:
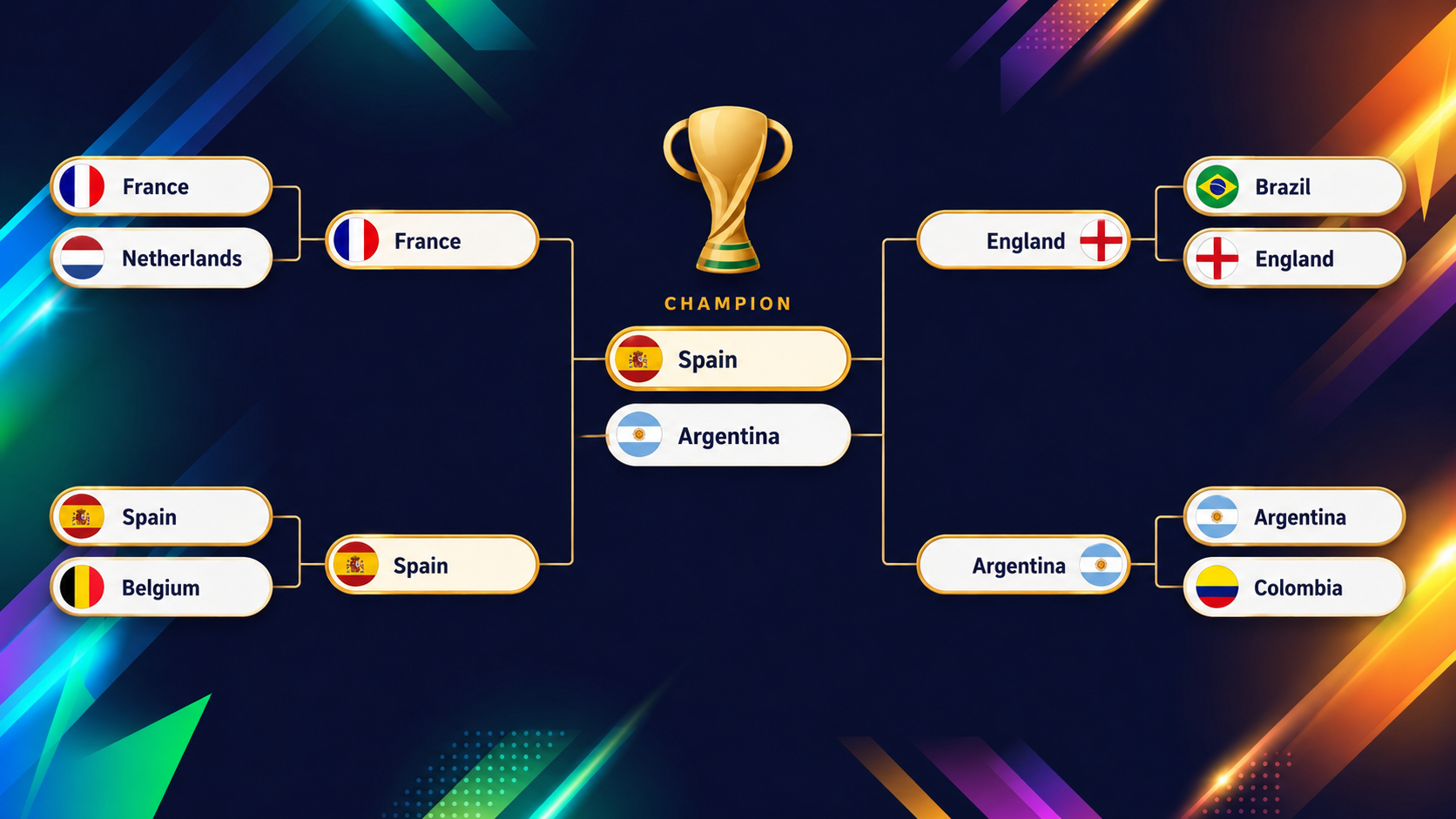
De lol van dit soort model zit in de teams die de oogtest tarten, en het duidelijkste voorbeeld zijn de Verenigde Staten. Als je op het dashboard naar het toernooioverzicht gaat, valt meteen op dat de VS er qua kleur uitspringt.
Als co-hosts voor eigen publiek verwacht je misschien een comfortabele start, maar het model is een stuk voorzichtiger: het geeft ze slechts zo’n 54,6% kans om de groep te overleven, de dertiende-laagste van het hele veld (bedenk dat twee derde van de teams doorgaat!), omdat hun groep met Australië, Paraguay en Turkije uitzonderlijk gelijkwaardig is.
Het interessante komt daarna. Als ze erdoorheen glippen, hangen de VS in elke volgende ronde rond grofweg een muntje-op. Stapel die muntjes op en ze komen uit op zo’n 2% kans om het hele toernooi te winnen, wat de dertiende-hoogste is van alle 48 teams.
Een ploeg die 13e van onder staat om uit de groep te komen en 13e van boven om alles te winnen, is zo’n beetje de perfecte definitie van een muntje-op team: nooit de favoriet, nooit kansloos.
Dit project was een hoop werk en bestrijkt veel meer dan in één artikel past. De repo bevat genoeg dat hier niet in paste: de volledige set kandidaatmodellen, de feature-engineering en de orkestratie die alles draaiende houdt, om maar wat te noemen.
Voor nu heeft het model zijn keuzes gemaakt, en het toernooi zal de rechter zijn. Of je nu voor de MLOps kwam of voor het voetbal, ik hoop dat je net zo geniet van het verloop als ik. Je kunt de live verwachting volgen terwijl de wedstrijden binnendruppelen en zien hoe goed de voorspellingen standhouden.
Wil je een paar van de genoemde concepten van dichterbij bekijken, dan raad ik onze cursus MLOps Concepts aan.
Topcursussen Machine Learning
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
