course
Understanding Machine Learning
2 घंटा
299.3K
कोई भी भविष्यवाणी उतनी ही अच्छी होती है जितना अच्छा डेटा उसमें जाता है, इसलिए कच्चे मटीरियल से शुरू करना उचित है। मॉडल दो लाइव डेटा स्रोतों से सीखता है और उन्हें एक एकल, व्यवस्थित फीचर टेबल में बदल देता है।
सब कुछ दो जगहों से बनता है। API-Football फिक्स्चर और प्रति-मैच आंकड़े देता है: किसने किससे कब, कहां खेला, और परिणाम क्या रहा। eloratings.net हर राष्ट्रीय टीम की Elo रेटिंग देता है।
Elo रेटिंग एक एकल संख्या है जो बताती है कि कोई टीम कितनी मजबूत है। हर टीम इस पैमाने पर कहीं न कहीं बैठती है, और हर मैच के बाद रेटिंग अपडेट होती है: किसी मजबूत टीम को हराएं, तो बहुत अंक मिलते हैं; किसी कमजोर से हारें, तो तेज़ी से गिरते हैं। यह विचार शतरंज से आया है और फुटबॉल पर अच्छी तरह लागू होता है। अगर आप पूरी समझ चाहते हैं, तो DataCamp का यह पुराना लेख 2022 विश्व कप के संदर्भ में इसे समझाता है।
साथ मिलकर, ये दो स्रोत 2018 से अब तक के लगभग 6,900 अंतरराष्ट्रीय मैचों का एक Gold डेटासेट देते हैं, जिससे मॉडल सीखता है।
यह पहली महत्वपूर्ण डिज़ाइन पसंद है। परिणाम को सीधे जीत, ड्रा, या हार के रूप में भविष्यवाणी करने के बजाय, मॉडल कुछ अधिक सूक्ष्म चीज़ भविष्यवाणी करता है: एक मैच में प्रत्येक टीम द्वारा किए गए गोलों की संख्या। फुटबॉल में गोल काउंट्स मोटे तौर पर पॉइसन वितरण का पालन करते हैं—एक मानक तरीका जिससे किसी तय समय-खिड़की में दुर्लभ घटना कितनी बार होती है, इसे मॉडल किया जाता है।
नतीजों के बजाय गोलों की भविष्यवाणी करना ही आगे की सारी चीज़ें संभव बनाता है। एक बार जब मॉडल किसी भी मुकाबले के लिए एक संभावित स्कोरलाइन दे सकता है, तब वही प्रश्न जिनमें सबकी दिलचस्पी है—कौन ग्रुप से निकलेगा और कौन ट्रॉफी उठाएगा—उन स्कोरलाइनों को हज़ारों बार सिमुलेट करके जवाब दिए जा सकते हैं।
हर मैच को एक छोटे, सावधानी से चुने गए फीचर सेट से वर्णित किया जाता है:
हर फीचर सख्ती से लीक-सेफ है, यानी प्रत्येक फीचर केवल वही जानकारी उपयोग करता है जो किकऑफ से पहले उपलब्ध थी। यह सुनने में सामान्य लगता है, पर यही वह आसान तरीका है जिससे अनजाने में ऐसा मॉडल बन सकता है जो टेस्टिंग में शानदार दिखे और वास्तविक दुनिया में बिखर जाए।
एक विचार जो शामिल नहीं हुआ: मैंने इन-गेम सांख्यिकी से टीमों को क्लस्टर करके "प्लेइंग स्टाइल" फीचर्स का सेट बनाने की योजना बनाई थी—एक अनसुपरवाइज़्ड लर्निंग स्टेप। व्यवहार में, टीमें अर्थपूर्ण समूहों में अलग नहीं हो पाईं, तो मॉडल में शोर डालने के बजाय मैंने इसे हटा दिया। नकारात्मक नतीजे भी नतीजे ही होते हैं।
दो स्रोतों से लगातार डेटा आते रहने पर, कच्ची फाइलों से मॉडल-तैयार फीचर्स तक का रास्ता हर बार एक जैसा होना चाहिए। यही मेडलियन आर्किटेक्चर देता है। यह डेटा को तीन लेयरों में संगठित करता है:
हर लेयर अगली को फीड करती है, इसलिए जब कुछ गड़बड़ दिखे, तो मैं एक-एक चरण पीछे जाकर ट्रेस कर सकता हूं, सबकुछ एक साथ सुलझाने की बजाय। पूरे रास्ते को पुनरुत्पादक बनाने के लिए, मैं DVC (Data Version Control) का उपयोग करता हूं। जब भी ताज़ा नतीजे आते हैं, एक dvc repro Bronze से Silver और Gold को फिर से बनाता है, किसी स्टेप को तभी चलाता है जब उसके इनपुट बदले हों, और तैयार हुए डेटासेट्स को वर्ज़न करता है ताकि पहले की किसी भी स्थिति को ठीक-ठीक रिकवर किया जा सके।
गोल्स की भविष्यवाणी एक अच्छी तरह अध्ययन किया गया समस्या है, और इसके लिए कोई एक स्पष्ट टूल नहीं है। इसलिए एक ही तरीके पर पहले से कमिट करने के बजाय, मैंने दस बनाए और उन्हें मुकाबला करने दिया।
ये दस मॉडल पांच परिवारों और एक सरल बेसलाइन में फैले हैं। आपको हर एक के भीतर के कामकाज जानने की ज़रूरत नहीं; बात यह है कि वे गोल्स बनने के तरीके के बारे में बहुत अलग मान्यताएं रखते हैं।
| परिवार | मॉडल | मुख्य विचार |
|---|---|---|
| बेसलाइन | मीन-रेट पॉइसन | मानता है कि हर टीम बस अपनी दीर्घकालिक औसत दर से स्कोर करती है, सभी फीचर्स को नजरअंदाज करते हुए। बाकी सबके हराने के लिए एक फर्श। |
| सांख्यिकीय | बाइवेरिएट पॉइसन, नेगेटिव बाइनोमियल | दोनों गोल काउंट्स को सीधे उन प्रायिकता वितरणों से मॉडल करना जो काउंटिंग इवेंट्स के लिए बने हैं। |
| बेयेसियन | बेयेसियन पॉइसन (MCMC) | वही काउंटिंग विचार, लेकिन यह हर अनुमान के आसपास अनिश्चितता की पूरी रेंज देता है। गणना में कहीं अधिक मांग: बाकी की तुलना में फिट करने में लगभग 100 गुना धीमा। |
| टाइम सीरीज़ | SARIMAX | किसी टीम के नतीजों को समय के साथ एक अनुक्रम की तरह मानता है और उस अनुक्रम को आगे प्रोजेक्ट करता है। |
| मशीन लर्निंग | रिज, रैंडम फॉरेस्ट, XGBoost | किसी तय समीकरण पर कमिट किए बिना सीधे फीचर्स से पैटर्न सीखना। |
| डीप लर्निंग | LSTM, 1D CNN | न्यूरल नेटवर्क जो डेटा में सीक्वेंशियल और लोकल पैटर्न ढूंढ़ते हैं। |
दस उम्मीदवारों के साथ, आंख से विजेता चुनना संभव नहीं था। इसके बजाय, हर मॉडल तीन चरणों से गुजरता है, और कोड तय करता है कि वह आगे बढ़ेगा या नहीं। इसे ही कोड-आधारित डिप्लॉयमेंट कहते हैं: मॉडल्स को एक वातावरण से अगले में मैनुअल ट्यूनिंग की बजाय स्वचालित जांचों से प्रोमोट किया जाता है, ताकि पूरी सेलेक्शन पुनरुत्पादक और ऑडिट में आसान रहे।
तो कौन-सा तरीका शीर्ष पर आया? यहां पूरा होल्डआउट लीडरबोर्ड है, RPS से स्कोर किया गया (कम बेहतर):
| मॉडल | होल्डआउट RPS |
|---|---|
| XGBoost | 0.18289 |
| बेयेसियन पॉइसन | 0.18316 |
| नेगेटिव बाइनोमियल | 0.18373 |
| बाइवेरिएट पॉइसन | 0.18389 |
| रैंडम फॉरेस्ट | 0.18392 |
| SARIMAX | 0.18583 |
| रिज | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| मीन-रेट पॉइसन (बेसलाइन) | 0.22872 |
इन नतीजों से चार बातें उभरती हैं:
 लाइव टूर्नामेंट के लिए, मैं सभी दस नहीं चलाता। मैं एक छोटा रोस्टर रखता हूं: संदर्भ बिंदु के रूप में मीन-रेट बेसलाइन, और साथ में तीन सर्वश्रेष्ठ परफॉर्मर। XGBoost और बेयेसियन पॉइसन स्पष्ट तौर पर शीर्ष दो स्थान लेते हैं।
लाइव टूर्नामेंट के लिए, मैं सभी दस नहीं चलाता। मैं एक छोटा रोस्टर रखता हूं: संदर्भ बिंदु के रूप में मीन-रेट बेसलाइन, और साथ में तीन सर्वश्रेष्ठ परफॉर्मर। XGBoost और बेयेसियन पॉइसन स्पष्ट तौर पर शीर्ष दो स्थान लेते हैं।
तीसरा स्थान व्यावहारिक रूप से टाई है: नेगेटिव बाइनोमियल और बाइवेरिएट पॉइसन एक-दूसरे से 0.0002 RPS के भीतर खत्म करते हैं और रैंडम सीड पर निर्भर होकर स्थान बदलते हैं, तो दो सांख्यिकीय रूप से अभेद्य मॉडलों में, मैंने बाइवेरिएट पॉइसन को चुना, जिसकी फॉर्म्युलेशन फुटबॉल-प्रेडिक्शन साहित्य (Karlis और Ntzoufras, 2004) में मजबूत आधार रखती है।
इससे एक रोस्टर बनता है—XGBoost (मशीन लर्निंग), बाइवेरिएट पॉइसन (क्लासिकल स्टैटिस्टिक्स), और बेयेसियन पॉइसन (बेयेसियन इंफेरेंस)। अगला सेक्शन बताता है कि ये मॉडल कैसे चलते हैं, रीट्रेन होते हैं, और सिंगल-मैच भविष्यवाणियों को पूरे टूर्नामेंट के फोरकास्ट में कैसे बदलते हैं।
जो मॉडल नोटबुक में रहता है, वह तभी उपयोगी है जब आप उसके सामने बैठे हों। एक महीने लंबे टूर्नामेंट के दौरान मैचों की भविष्यवाणी करने के लिए, पूरी चीज़ खुद चलनी चाहिए: नए नतीजे खींचना, रीट्रेन करना, दोबारा सिमुलेट करना, और बिना किसी के छुए फोरकास्ट को रिफ्रेश करना। यही पाइपलाइन का काम है।
पूरा प्रोजेक्ट एक एकल शेड्यूल जॉब के रूप में Google Cloud Run पर चलता है। टूर्नामेंट से पहले, यह रोज़ एक बार जागता है; 11 जून को उद्घाटन मैच से, यह हर दूसरे घंटे चलता है। हर रन यही चक्र फॉलो करता है:
dvc repro Silver और Gold लेयरों को फिर से बनाता है ताकि फीचर्स अपडेटेड रहें।क्योंकि हर स्टेप शेड्यूल पर कोड द्वारा ट्रिगर होता है, टूर्नामेंट के दौरान कोई मैनुअल बटन दबाना नहीं पड़ता। नया नतीजा अंदर, ताज़ा फोरकास्ट बाहर।
यहीं से प्रोजेक्ट एक प्रयोग भी बन जाता है। टूर्नामेंट के दौरान, रोस्टर दो समानांतर मोड में चलता है, और उनके बीच का फर्क वह प्रश्न है जिसका उत्तर मैं डेटा से चाहता हूं: क्या टूर्नामेंट चलते-चलते रीट्रेन करना भविष्यवाणियों को बेहतर बनाता है?
दोनों को साथ-साथ चलाना मुझे टूर्नामेंट खत्म होने पर दो मोर्चों पर तुलना करने देता है: कच्ची भविष्यसूचक सटीकता, और फील्ड सिमटने के साथ हर एक की अनिश्चितता कितनी तेजी से घटती है। अगर प्रति-राउंड जीतता है, तो नियमित रीट्रेनिंग अपनी उपयोगिता दिखाती है; अगर फ्रोजन टिकता है, तो अतिरिक्त मशीनरी शायद उतनी सार्थक न हो।
एक मैच की भविष्यवाणी एक बात है। इसे "हर टीम के टूर्नामेंट जीतने की कितनी संभावना है" में बदलना वहीं है जहां मोंटे कार्लो सिमुलेशन काम आता है।
पहले, इंफेरेंस। केवल वे फिक्स्चर जिनका हमें पहले से पता है, उनकी बजाय, मॉडल 48 टीमों के बीच हर संभव मुकाबले की भविष्यवाणी करता है। यह अतिशयोक्ति लग सकती है, लेकिन टूर्नामेंट में कोई भी टीम नॉकआउट में किसी भी अन्य से मिल सकती है, इसलिए हर पेयरिंग के लिए भविष्यवाणी तैयार होनी चाहिए।
अगला, नियमों को एन्कोड करना पड़ता है, और 2026 का फॉर्मेट इसे खास तौर पर पेचीदा बनाता है। 12 ग्रुप्स में, शीर्ष दो स्वतः आगे बढ़ते हैं, लेकिन सर्वश्रेष्ठ तीसरे स्थान पर रहने वाली आठ टीमें भी, और उन आठ में से कौन-सी किस नॉकआउट स्लॉट में जाएगी यह इस पर निर्भर करता है कि वे किन समूहों से आई हैं।
बारह में से आठ क्वालिफाइंग ग्रुप्स चुनने के 495 तरीके हैं (ट्वेल्व चूज़ एट), और हर एक राउंड-ऑफ-32 पेयरिंग्स का अलग सेट बनाता है। इसका कोई साफ सूत्र नहीं; FIFA बस एक टेबल प्रकाशित करता है। तो मैंने (या यूं कहें मेरे अत्यंत सक्षम सहकर्मी Cursor ने) आधिकारिक टेबल को स्रोत मानकर सभी 495 कॉम्बिनेशन को एक मैपिंग में हार्डकोड किया।
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...हर कुंजी, जैसे EFGHIJKL, बताती है कि कौन-से आठ समूहों ने तीसरे स्थान पर रहते हुए आगे बढ़ने वाली टीमें दीं, और वैल्यूज़ उन टीमों (3E, 3F, आदि) को किसी विशेष राउंड-ऑफ-32 मैच नंबर में स्लॉट करती हैं। यह एक एंट्री है; पूरी मैपिंग इसे 495 बार दोहराती है, हर कॉम्बिनेशन पर एक।
तीन मेज़बान देशों (संयुक्त राज्य अमेरिका, कनाडा, और मेक्सिको) के लिए एक अतिरिक्त हैंडलिंग है। जब कोई होस्ट अपने ही देश में आयोजित मैच खेलता है, तो सिमुलेशन उस फिक्स्चर पर होम-एडवांटेज समायोजन लागू करता है, जबकि टूर्नामेंट का बाकी हिस्सा न्यूट्रल ग्राउंड माना जाता है।
भविष्यवाणियां और नियम तय होने के बाद, सिमुलेशन पूरा टूर्नामेंट 10,000 बार चलाता है। हर रन में यह प्रक्रिया फॉलो होती है:
10,000 सिमुलेटेड टूर्नामेंट्स में, जितने अंश में कोई टीम फाइनल तक पहुंचती है या ट्रॉफी उठाती है, वही उसकी संभावना बन जाती है। एक रन एक अनुमान है; दस हजार रन एक फोरकास्ट।
अब तक वर्णित हर रन—दोनों मोड में—MLflow (जो DagsHub पर होस्टेड है) में लॉग होता है। एक्सपेरिमेंट ट्रैकिंग का मतलब है हर रन के इनपुट्स, सेटिंग्स, नतीजे और आउटपुट को व्यवस्थित रूप से रिकॉर्ड करना, ताकि किसी भी रन की ठीक-ठीक तुलना या पुनरुत्पादन किया जा सके। कुछ खास चीजें जो यह कैप्चर करता है, उल्लेखनीय हैं:
ट्रेंड मॉडल्स और स्वयं प्रेडिक्शन फाइलें (टूर्नामेंट संभावनाएं, ग्रुप स्टैंडिंग्स, और मैच फोरकास्ट) रन आर्टिफैक्ट्स के रूप में स्टोर होती हैं, और यही फाइलें लाइव डैशबोर्ड पढ़ता है। इस तरह लूप पूरा होता है: कच्चे नतीजों से, ट्रेनिंग और सिमुलेशन होते हुए, उन संख्याओं तक जिन्हें आप ऑनलाइन देख सकते हैं।
आखिरी हिस्सा मैचों के निपटने के बाद चलता है। जैसे-जैसे वास्तविक नतीजे आते हैं, उनके लिए की गई भविष्यवाणियों को स्कोर किया जाता है और सरल मीन-रेट बेसलाइन से तुलना की जाती है। अगर फुल मॉडल्स ऐसी मॉडल से भी पीछे रहने लगें जो टीमों के बारे में कुछ नहीं जानता, तो यह ड्रिफ्ट का चेतावनी संकेत है: टूर्नामेंट से पहले सीखे गए पैटर्न अब मैदान पर हो रही चीजों से मेल नहीं खाते होंगे।
लाइव भविष्यवाणियां करने वाली किसी भी प्रणाली के लिए इस पर निगरानी रखना मानक प्रैक्टिस है, और आप डेटा ड्रिफ्ट और मॉडल ड्रिफ्ट पर इस गाइड में जान सकते हैं कि इसे कैसे पहचाना जाता है।
इतनी सारी मशीनरी के बाद, यही उसका मकसद है।
10 जून, 2026 तक, उद्घाटन मैच से एक दिन पहले, मॉडल का फैसला शीर्ष पर स्पष्ट और उसके पीछे भीड़भाड़ वाला है। स्पेन और अर्जेंटीना फील्ड का नेतृत्व करते हैं, प्रत्येक के ट्रॉफी उठाने की संभावना लगभग 16% है। कि मौजूदा विश्व चैंपियन (अर्जेंटीना) और मौजूदा यूरोपीय चैंपियन (स्पेन) शीर्ष पर आते हैं, यह एक आश्वस्त करने वाला स sanity check है कि मॉडल वास्तविकता पर टिका है।
उनके पीछे कड़ा पीछा करने वाला समूह है: फ्रांस, इंग्लैंड, ब्राज़ील और कोलंबिया सबसे संभावित विजेताओं में शामिल हैं। ये लाइव आंकड़े हैं, और वास्तविक नतीजे आते ही बदलेंगे, इसलिए इन्हें 10 जून का स्नैपशॉट मानें, न कि पक्की भविष्यवाणी। डैशबोर्ड हमेशा मौजूदा नंबर दिखाता है, अधिकतम दो घंटे की देरी के साथ।
यही बात उठी: इस लेख की हर संख्या एक लाइव Streamlit ऐप से आती है जो पाइपलाइन के चलते ही अपने-आप अपडेट होती है। आप इसे wc2026-predictions.streamlit.app पर खोल सकते हैं और टूर्नामेंट भर फॉलो कर सकते हैं। इसमें चार मुख्य दृश्य हैं:
मैच व्यू में एक खास बात नोट करने लायक है: कुछ टीमें एक साथ राउंड-ऑफ-32 के दो संभावित स्लॉट्स में दिखाई देती हैं। यह बग नहीं है। ऐसा तब होता है जब कोई ग्रुप इतना संतुलित हो कि मॉडल भरोसे के साथ नहीं बता पाए कि टीम कौन-सी क्वालिफाइंग पोज़िशन लेगी। सर्वश्रेष्ठ-तीसरे की अनिश्चितता के साथ मिलकर, ये दो परिणाम अलग-अलग नॉकआउट स्लॉट्स की ओर ले जाते हैं। तुर्की के मामले में, यह उन्हें राउंड ऑफ 16 में दो बार ले गया।
नीचे दिया गया ग्राफिक XGBoost मॉडल द्वारा टूर्नामेंट शुरू होने से पहले प्रोजेक्ट किए गए अंतिम राउंड्स (क्वार्टरफाइनल से फाइनल तक) दिखाता है:
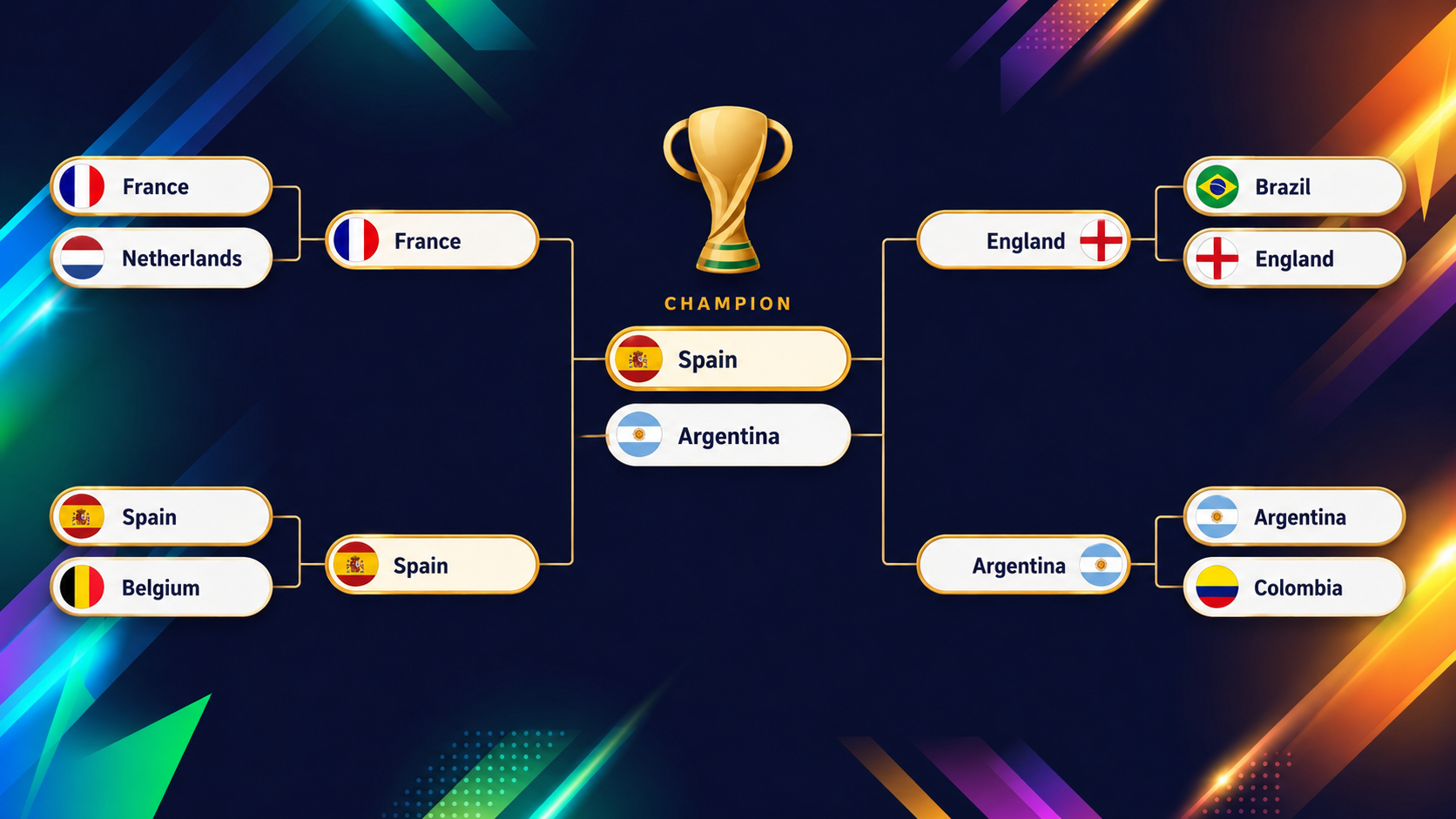
ऐसे मॉडल का मजा उन टीमों में है जो आंखों की कसौटी को चुनौती देती हैं, और सबसे स्पष्ट उदाहरण संयुक्त राज्य है। अगर आप डैशबोर्ड पर टूर्नामेंट ओवरव्यू में जाएं, तो आप तुरंत देखेंगे कि US रंग में अलग दिखता है।
को-होस्ट्स के रूप में घरेलू भीड़ों के सामने खेलते हुए आप आरामदायक शुरुआत की उम्मीद कर सकते हैं, लेकिन मॉडल कहीं ज्यादा सतर्क है: वह उन्हें अपने ग्रुप से निकलने की केवल लगभग 54.6% संभावना देता है, जो पूरे फील्ड में 13वां सबसे कम है (याद रखें कि दो-तिहाई टीमें क्वालिफाई करती हैं!), क्योंकि उनका ग्रुप ऑस्ट्रेलिया, पराग्वे और तुर्किये के साथ असाधारण रूप से संतुलित है।
दिलचस्प हिस्सा उसके बाद आता है। किसी तरह निकलने के बाद, US फिर हर अगले राउंड में लगभग सिक्का उछाल जैसी स्थिति में मंडराता है। उन सिक्का उछालों को जोड़ने पर उनके पूरे टूर्नामेंट जीतने की संभावना लगभग 2% पर आती है, जो 48 टीमों में 13वां सबसे ऊंचा है।
जो टीम अपने ग्रुप से निकलने में नीचे से 13वीं और खिताब जीतने में ऊपर से 13वीं रैंक करे, वह व्यावहारिक रूप से कॉइन-फ्लिप टीम की परफेक्ट परिभाषा है: कभी स्पष्ट फेवरेट नहीं, कभी पूरी तरह बाहर नहीं।
यह प्रोजेक्ट काफी काम का था, और यह एक लेख से कहीं अधिक चीजों को कवर करता है। रिपो में बहुत-सी चीजें हैं जो यहां नहीं समा सकीं: उम्मीदवार मॉडलों का पूरा सेट, फीचर इंजीनियरिंग, और वह ऑर्केस्ट्रेशन जो सब कुछ चलाए रखता है—कुछ उदाहरण हैं।
फिलहाल, मॉडल ने अपनी पसंद बता दी है, और फैसला टूर्नामेंट करेगा। आप MLOps के लिए आए हों या फुटबॉल के लिए, मुझे उम्मीद है कि आप इसे unfolding होते देखना उतना ही एन्जॉय करेंगे जितना मैं करूंगा। आप मैचों के आते ही लाइव फोरकास्ट फॉलो कर सकते हैं और देख सकते हैं कि भविष्यवाणियां कितनी टिकती हैं।
अगर आप बताए गए कुछ कॉन्सेप्ट्स को करीब से देखना चाहते हैं, तो मैं हमारा MLOps Concepts कोर्स लेने की सलाह देता हूं।
शीर्ष मशीन लर्निंग कोर्स
course
course
course