course
Înțelegerea Machine Learning-ului
2 oră
299.3K
O predicție este pe atât de bună pe cât sunt datele din spatele ei, așa că merită să începem cu materia primă. Modelul învață din două surse de date live și le transformă într-un singur tabel ordonat de caracteristici.
Totul e construit din două locuri. API-Football furnizează programările și statisticile pe meci: cine a jucat cu cine, când, unde și cum s-a terminat. eloratings.net furnizează ratinguri Elo pentru fiecare echipă națională.
Un rating Elo este un singur număr care surprinde cât de puternică este o echipă. Fiecare echipă se află undeva pe scară, iar după fiecare meci ratingul se actualizează: dacă bați o echipă mai puternică, câștigi mult; dacă pierzi cu una mai slabă, scazi brusc. Ideea vine din șah și se potrivește bine fotbalului. Dacă vrei intuiția completă, acest articol DataCamp mai vechi o explică în contextul Cupei Mondiale 2022.
Împreună, cele două surse oferă un set de date Gold de aproximativ 6.900 de meciuri internaționale din 2018 încoace din care să înveți.
Iată prima alegere de proiectare importantă. În loc să prezică direct rezultatul ca victorie, egal sau înfrângere, modelul prezice ceva mai granular: numărul de goluri marcate de fiecare echipă într-un meci. Numărul de goluri în fotbal urmează, cu o aproximare bună, o distribuție Poisson, modalitatea standard de a modela cât de des se întâmplă un eveniment relativ rar într-o fereastră de timp fixă.
Predict̂nd goluri mai degrabă decât rezultate face posibil tot ce urmează. Odată ce modelul poate produce un scor plauzibil pentru orice duel, întrebările care îi interesează pe toți — cine iese din grupă și cine ridică trofeul — pot fi răspunse prin simularea acelor scoruri de mii de ori.
Fiecare meci este descris de un set mic, ales cu grijă, de caracteristici:
Fiecare caracteristică este strict sigură din punctul de vedere al scurgerii de informații, adică folosește doar informații disponibile înainte de fluierul de start. Sună evident, dar este una dintre cele mai ușoare căi de a construi din greșeală un model care arată briliant în testare și se prăbușește în lumea reală.
O idee care nu a trecut filtrul: plănuisem un set de caracteristici de „stil de joc” construite prin clusterizarea echipelor din statisticile lor din meci, un pas de învățare nesupravegheată. În practică, echipele nu s-au separat în grupuri semnificative, așa că, în loc să bag modelului zgomot, am renunțat. Rezultatele negative sunt tot rezultate.
Cu date care sosesc din două surse în mod continuu, drumul de la fișiere brute la caracteristici gata de model trebuie să fie identic de fiecare dată. Asta oferă o arhitectură medallion. Ea organizează datele în trei straturi:
Fiecare strat îl alimentează pe următorul, așa că atunci când ceva pare în neregulă, pot urmări înapoi câte un pas, în loc să descurc totul odată. Pentru a face întregul traseu reproductibil, folosesc DVC (Data Version Control). Ori de câte ori intră rezultate noi, un singur dvc repro reconstruiește straturile Silver și Gold din Bronze, rerulând un pas doar dacă intrările lui s-au schimbat, și versiunează seturile de date rezultate astfel încât orice stare anterioară să poată fi recuperată exact.
Predicția golurilor este o problemă bine studiată și nu există un instrument evident unic pentru ea. Așa că, în loc să mă fixez din start pe o abordare, am construit zece și le-am lăsat să concureze.
Cele zece modele acoperă cinci familii plus un baseline simplu. Nu trebuie să știi mecanica internă a fiecăruia; ideea e că ele fac presupuneri foarte diferite despre cum apar golurile.
| Familie | Modele | Ideea de bază |
|---|---|---|
| Baseline | Poisson cu rată medie | Presupune că fiecare echipă marchează pur și simplu o medie pe termen lung, ignorând toate caracteristicile. Un prag pe care ceilalți trebuie să-l depășească. |
| Statistic | Poisson bivariată, Binomială negativă | Modelează direct cele două numere de goluri cu distribuții de probabilitate construite pentru numărarea evenimentelor. |
| Bayesian | Poisson bayesiană (MCMC) | Aceeași idee de numărare, dar returnează un interval complet de incertitudine în jurul fiecărei estimări. Mult mai solicitantă computațional: aproximativ de 100 de ori mai lent de ajustat decât restul. |
| Serii temporale | SARIMAX | Tratează rezultatele unei echipe ca o secvență în timp și proiectează acea secvență în viitor. |
| Machine learning | Ridge, Random Forest, XGBoost | Învăță modele direct din caracteristici fără a se angaja într-o ecuație fixă. |
| Deep learning | LSTM, CNN 1D | Rețele neuronale care caută tipare secvențiale și locale în date. |
Cu zece candidați, alegerea unui câștigător „la ochi” nu avea cum să funcționeze. În schimb, fiecare model trece prin trei etape, iar codul decide dacă merge mai departe. Asta înseamnă deployment bazat pe cod: modelele sunt promovate dintr-un mediu în altul prin verificări automate, nu prin reglaje manuale, astfel încât întreaga selecție rămâne reproductibilă și ușor de auditat.
Deci care abordare a ieșit pe primul loc? Iată clasamentul complet pe holdout, punctat prin RPS (mai mic e mai bun):
| Model | RPS pe holdout |
|---|---|
| XGBoost | 0.18289 |
| Poisson bayesian | 0.18316 |
| Binomial negativ | 0.18373 |
| Poisson bivariată | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| CNN 1D | 0.20916 |
| Poisson cu rată medie (baseline) | 0.22872 |
Patru lucruri ies în evidență din aceste rezultate:
 Pentru turneul live, nu rulez toate cele zece. Păstrez un lot mai mic: baseline-ul cu rată medie ca punct de referință, plus cei mai buni trei performeri. XGBoost și Poisson bayesiană ocupă clar primele două locuri.
Pentru turneul live, nu rulez toate cele zece. Păstrez un lot mai mic: baseline-ul cu rată medie ca punct de referință, plus cei mai buni trei performeri. XGBoost și Poisson bayesiană ocupă clar primele două locuri.
Locul trei este practic o egalitate: Binomialul negativ și Poisson bivariată termină la 0,0002 RPS unul de altul și își schimbă locurile în funcție de seed-ul aleator, așa că, între două modele statistic nedistincte, am ales Poisson bivariată, a cărei formulare are o bază mai solidă în literatura de predicție în fotbal (Karlis și Ntzoufras, 2004).
Asta lasă un lot cu XGBoost (machine learning), Poisson bivariată (statistică clasică) și Poisson bayesiană (inferință bayesiană). Secțiunea următoare acoperă cum rulează aceste modele, cum se reantrenează și cum transformă predicțiile la nivel de meci într-o prognoză pentru întregul turneu.
Un model care trăiește într-un notebook e util doar cât timp stai în fața lui. Ca să prezici meciuri pe durata unui turneu de o lună, totul trebuie să ruleze singur: să preia rezultate noi, să se reantreneze, să resimuleze și să reîmprospăteze prognoza fără ca cineva să-l atingă. Asta e treaba pipeline-ului.
Întregul proiect rulează ca un singur job programat pe Google Cloud Run. Înainte de turneu, se trezește o dată pe zi; din meciul de deschidere pe 11 iunie, rulează la fiecare două ore. Fiecare rulare urmează același ciclu:
dvc repro reconstruiește straturile Silver și Gold pentru ca caracteristicile să fie la zi.Pentru că fiecare pas e declanșat de cod pe un program, nu există apăsări manuale de butoane în timpul turneului. Rezultat nou intră, prognoză reîmprospătată iese.
Aici proiectul funcționează și ca un experiment. În timpul turneului, lotul rulează în două moduri paralele, iar diferența dintre ele e întrebarea la care sper să răspund din date: Face reantrenarea pe măsură ce se desfășoară turneul predicțiile mai bune?
Rularea ambelor în paralel îmi permite să le compar pe două fronturi după ce se termină: acuratețe predictivă brută și cât de repede se clarifică incertitudinea fiecăruia pe măsură ce se îngustează tabloul. Dacă „pe rundă” câștigă, reantrenarea regulată își justifică efortul; dacă „înghețat” se ține bine, s-ar putea ca mecanismul suplimentar să nu merite.
A prezice un singur meci e una. Să transformi asta în „care este șansa fiecărei echipe de a câștiga turneul” e locul în care intră simularea Monte Carlo.
Mai întâi, inferența. În loc să prezică doar meciurile pe care le știm deja, modelul prezice fiecare posibil duel între cele 48 de echipe. Sună excesiv, dar într-un turneu, orice echipă poate întâlni pe oricare alta în eliminatorii, așa că predicția trebuie să fie gata pentru fiecare pereche.
Apoi trebuie codificate regulile, iar formatul din 2026 face asta în mod special incomod. În cele 12 grupe, primele două avansează automat, dar și cele mai bune opt echipe de pe locul trei, iar în ce poziție din tabloul eliminatoriu ajunge fiecare dintre cele opt depinde de grupele din care provin.
Există 495 de moduri de a alege opt grupe calificate din douăsprezece (douăsprezece peste opt), iar fiecare produce un set diferit de meciuri pentru șaisprezecimi. Nu există o formulă curată pentru asta; FIFA publică pur și simplu un tabel. Așa că eu (sau, mai bine zis, colegul meu foarte capabil Cursor) am hardcodat toate cele 495 de combinații într-un mapping, folosind tabelul oficial ca sursă.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Fiecare cheie, precum EFGHIJKL, listează care opt grupe au furnizat echipele de pe locul trei care avansează, iar valorile plasează fiecare dintre acele echipe (3E, 3F și așa mai departe) într-un anumit meci numerotat din șaisprezecimi. Asta e o intrare; mappingul complet repetă asta de 495 de ori, câte o dată pentru fiecare combinație.
Cele trei țări gazdă (Statele Unite, Canada și Mexic) primesc o tratare suplimentară. Când o gazdă joacă un meci organizat în propria țară, simularea aplică un ajustaj de avantaj al terenului propriu pentru acel meci, în timp ce restul turneului este tratat ca teren neutru.
Cu predicțiile și regulile stabilite, simularea rulează întregul turneu de 10.000 de ori. În fiecare rulare, urmează această procedură:
Pe parcursul a 10.000 de turnee simulate, ponderea rulărilor în care o echipă ajunge în finală sau ridică trofeul devine probabilitatea acelei echipe. O rulare e o bănuială; zece mii de rulări sunt o prognoză.
Fiecare rulare descrisă până acum, în ambele moduri, este înregistrată în MLflow (găzduit pe DagsHub). Tracking-ul experimentului înseamnă înregistrarea sistematică a intrărilor, setărilor, rezultatelor și ieșirilor fiecărei rulări, astfel încât oricare dintre ele să poată fi comparată cu celelalte sau reprodusă exact. Câteva lucruri pe care le captează merită menționate:
Modelele antrenate și fișierele de predicții în sine (probabilitățile pentru turneu, clasamentele grupelor și prognozele pe meci) sunt stocate ca artefacte ale rulărilor, iar acele fișiere sunt exact ceea ce citește dashboard-ul live. Asta închide bucla: de la rezultate brute, prin antrenare și simulare, la cifrele pe care le poți vedea online.
Ultima piesă rulează după încheierea meciurilor. Pe măsură ce sosesc rezultatele reale, predicțiile făcute pentru ele sunt punctate și comparate cu baseline-ul simplu cu rată medie. Dacă modelele complete încep să piardă teren în fața unui model care nu știe nimic despre echipe, acesta e un semn de avertizare de drift: tiparele învățate înainte de turneu s-ar putea să nu mai corespundă cu ce se întâmplă pe teren.
Să urmărești asta e practică standard pentru orice sistem care face predicții live, iar poți citi mai multe despre cum este detectat în acest ghid despre data drift și model drift.
După toată această mașinărie, iată la ce folosește.
La 10 iunie 2026, cu o zi înainte de meciul de deschidere, verdictul modelului e clar în vârf și aglomerat imediat în spate. Spania și Argentina conduc plutonul, fiecare cu aproximativ 16% șanse să ridice trofeul. Faptul că actualele campioane mondiale (Argentina) și actualele campioane europene (Spania) ies în top e un control sănătos că modelul e ancorat în realitate.
În spatele lor se află un pluton urmăritor strâns: Franța, Anglia, Brazilia și Columbia completează cele mai probabile câștigătoare. Acestea sunt cifre live și se vor mișca în momentul în care apar rezultate reale, deci tratează-le ca o fotografie a zilei de 10 iunie, nu ca o profeție fixă. Dashboard-ul arată mereu cifrele curente, cu o întârziere maximă de două ore.
Apropo: fiecare număr din acest articol provine dintr-o aplicație Streamlit live care se actualizează automat pe măsură ce rulează pipeline-ul. O poți deschide la wc2026-predictions.streamlit.app și poți urmări turneul. Are patru vizualizări principale:
O particularitate de semnalat în vizualizarea pe meci: câteva echipe apar simultan în două posibile poziții din șaisprezecimi. Nu e un bug. Se întâmplă când o grupă e atât de echilibrată încât modelul nu poate spune cu încredere ce poziție de calificare va lua o echipă. Combinat cu incertitudinea „celui mai bun loc trei”, cele două rezultate duc la poziții diferite în eliminatorii. În cazul Turciei, a dus chiar la apariția lor de două ori în optimile de finală.
Graficul următor arată rundele finale (sferturi până la finală) pe care modelul XGBoost le proiectează înainte de startul turneului:
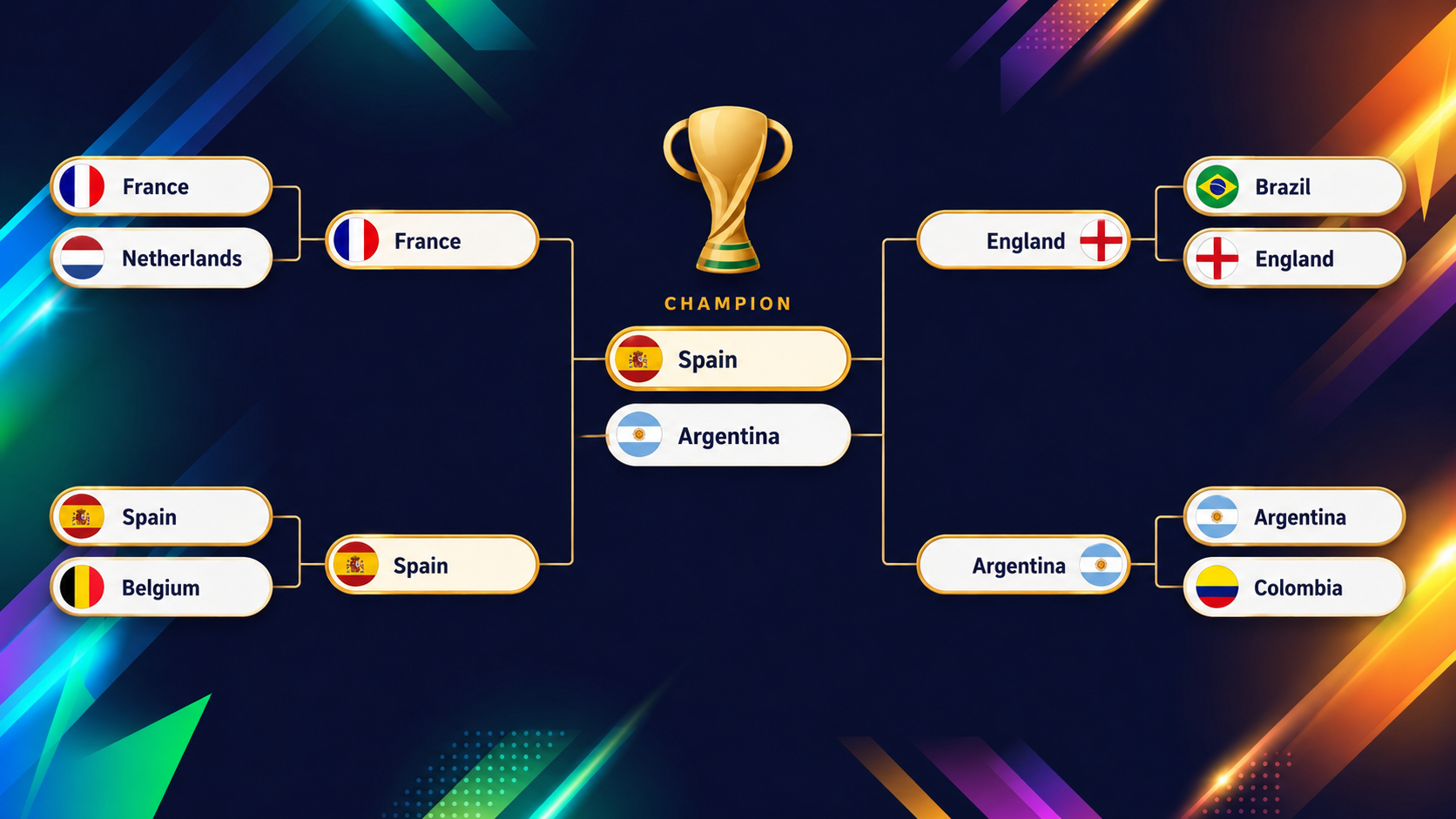
Farmecul unui astfel de model stă în echipele care sfidează testul vizual, iar cel mai clar exemplu sunt Statele Unite. Dacă intri la prezentarea generală a turneului pe dashboard, vei observa instantaneu că SUA ies în evidență prin culoare.
Ca co-gazde care joacă în fața propriilor fani, te-ai aștepta la un start confortabil, dar modelul e mult mai precaut: le dă doar aproximativ 54,6% șanse să iasă din grupă, al 13-lea cel mai mic procent din întregul lot (nu uita că două treimi din echipe se califică!), pentru că grupa lor cu Australia, Paraguay și Turcia e neobișnuit de echilibrată.
Partea interesantă vine apoi. După ce trec la limită, SUA plutesc apoi pe la aproximativ 50-50 în fiecare rundă care urmează. Dacă înșiri acele aruncări de monedă, ajung la cam 2% șanse să câștige întregul turneu, ceea ce e al 13-lea cel mai mare procent dintre toate cele 48 de echipe.
O echipă care e pe locul 13 de la coadă la ieșirea din grupe și pe locul 13 de la vârf la câștigarea trofeului e aproape definiția perfectă a unei „echipe aruncarea monedei”: niciodată favorită, niciodată scoasă din calcule.
Proiectul acesta a însemnat multă muncă și acoperă mult mai mult decât încap într-un singur articol. Repo-ul conține multe lucruri care nu au încăput aici: setul complet de modele candidate, ingineria de caracteristici și orhestrarea care ține totul în funcțiune, ca exemple.
Deocamdată, modelul și-a făcut alegerile, iar turneul va decide. Fie că ai venit pentru MLOps sau pentru fotbal, sper să-ți facă plăcere să-l urmărești desfășurându-se la fel de mult ca mie. Poți urmări prognoza live pe măsură ce intră meciurile și să vezi cât de bine rezistă predicțiile.
Dacă vrei să aprofundezi unele concepte menționate, îți recomand cursul nostru MLOps Concepts.
Top cursuri de Machine Learning
course
course
course