Courses
機械学習を理解する
2時間
299.3K
予測の良し悪しは入力に依存する。まずは材料から見ていこう。モデルは2つのライブデータソースから学習し、それらを単一の整然データ(tidy)な特徴量テーブルへと変換する。
基盤は2つのソースからなる。API-Footballは対戦カードと試合ごとの統計、つまり対戦相手・日時・開催地・結果を提供する。eloratings.netは各国代表のEloレーティングを提供する。
Eloレーティングは、チームの強さを1つの数値で表すものだ。各チームはスケール上のどこかに位置し、試合ごとに更新される。格上に勝てば大きく加点、格下に負ければ大きく減点。元はチェスの発想で、サッカーにも上手く適用できる。直感をより深く知りたいなら、DataCampの過去記事が2022年大会の文脈で丁寧に解説している。
この2つを組み合わせると、2018年以降の代表戦約6,900試合分のGoldデータセットが得られ、学習に使える。
ここが最初の重要な設計判断だ。勝ち・引き分け・負けを直接当てるのではなく、より粒度の細かい「各チームがその試合で挙げる得点数」を予測する。サッカーの得点数は、おおむねポアソン分布に従う。一定時間内に比較的まれな事象が起こる回数を扱う標準的なモデルだ。
結果ではなく得点を予測するからこそ、後の工程が可能になる。任意の対戦で妥当なスコアラインを出せるようになれば、グループ突破や優勝といった皆が関心を寄せる問いに対し、そのスコアラインを何千回もシミュレートして答えを出せる。
各試合は、厳選した少数の特徴量で記述される。
すべての特徴量は厳密にリーケージを防いでいる。つまり、キックオフ前に利用可能だった情報のみを使う。これは当然に聞こえるが、検証では優秀でも実運用で崩れる「見かけ倒しモデル」を作ってしまう最もありがちな落とし穴の1つだ。
採用を見送ったアイデアもある。「プレースタイル」特徴量を、試合中のスタッツから各国をクラスタリングして作る教師なし学習を計画していた。しかし、実際には有意なグループ分けが得られず、ノイズを入れるくらいならと削除した。否定的な結果もまた成果だ。
2つのソースから継続的にデータが流入する以上、生データからモデル用特徴量に至る経路は毎回同一でなければならない。そこでメダリオンアーキテクチャを用いる。データを3層に整理するやり方だ。
各層は次の層を支えるため、異常があれば一段ずつ遡って原因を突き止められる。一連の経路を再現可能にするため、DVC(Data Version Control)を使う。新しい結果が入ったら、dvc repro1回でBronzeからSilverとGoldを再構築し、入力が変わったステップだけを再実行する。同時に出来上がったデータセットにバージョンを付け、過去の任意の状態を正確に復元できる。
得点予測は研究が進んだ課題で、明白な唯一解はない。そこで1つに絞らず、10モデルを構築して競わせた。
10モデルは5つの系統と単純なベースラインから成る。内部構造を理解する必要はない。重要なのは、得点が生まれる仕組みに対して、それぞれが大きく異なる仮定を置くという点だ。
| 系統 | モデル | 中核となる考え方 |
|---|---|---|
| ベースライン | 平均率ポアソン | 全チームが長期平均の得点率で得点すると仮定し、特徴量を無視。ほかのモデルが超えるべき下限。 |
| 統計モデル | 二変量ポアソン、負の二項 | 2チームの得点回数を、計数データ向けの確率分布で直接モデル化。 |
| ベイズ | ベイズ・ポアソン(MCMC) | 同様に計数を扱うが、推定値の不確実性をフルな分布で返す。計算負荷は桁違いで、学習は他より約100倍遅い。 |
| 時系列 | SARIMAX | チームの結果を時系列として扱い、その系列を先へ外挿。 |
| 機械学習 | Ridge、ランダムフォレスト、XGBoost | 固定の数式に縛られず、特徴量からパターンを直接学習。 |
| ディープラーニング | LSTM、1D CNN | 時系列や局所パターンを捉えるニューラルネット。 |
10候補から目視で勝者を選ぶのは不可能だ。各モデルは3段階を通過し、先へ進めるかはコードが判断する。これがコードベースのデプロイの意味だ。手作業の微調整ではなく自動チェックで環境を昇格させるため、選定の再現性と監査性が保たれる。
最終的に頂点に立ったのはどの手法か。RPS(低いほど良い)で評価したホールドアウトのリーダーボードは次の通り。
| モデル | ホールドアウトRPS |
|---|---|
| XGBoost | 0.18289 |
| ベイズ・ポアソン | 0.18316 |
| 負の二項 | 0.18373 |
| 二変量ポアソン | 0.18389 |
| ランダムフォレスト | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| 平均率ポアソン(ベースライン) | 0.22872 |
ここから見えてくるのは4点。
 ライブ運用では10モデルすべては走らせない。参照用の平均率ベースラインと、上位3モデルに絞る。XGBoostとベイズ・ポアソンが上位2枠を確保。
ライブ運用では10モデルすべては走らせない。参照用の平均率ベースラインと、上位3モデルに絞る。XGBoostとベイズ・ポアソンが上位2枠を確保。
3位は実質引き分け。負の二項と二変量ポアソンは0.0002 RPS差以内で、乱数シード次第で順位が入れ替わる。統計的に同等な2モデルのうち、フットボール予測の文献で定式化の足場がより強い(二変量ポアソン:Karlis & Ntzoufras, 2004)方を採用した。
最終ロスターは、XGBoost(機械学習)、二変量ポアソン(古典統計)、ベイズ・ポアソン(ベイズ推論)。次節では、これらがどのように動き、再学習し、単一試合の予測を大会全体の予測へと変換するかを説明する。
ノートブック内のモデルは、目の前に座っている間だけ有用だ。1か月にわたるトーナメントの試合を予測するには、すべてが自律的に動く必要がある。新しい結果の取得、再学習、再シミュレーション、予測の更新まで、手を触れずに回す。それがパイプラインの役割だ。
プロジェクト全体はGoogle Cloud Run上の単一スケジュールジョブとして動作する。大会前は1日1回、6月11日の開幕以後は2時間おきに起動。各実行は同じサイクルに従う。
dvc repro1回で特徴量が最新になるようSilverとGoldを再構築。各ステップはスケジュールに従ってコードで起動されるため、大会中に手動操作は不要だ。新しい結果が入れば、更新済みの予測が出る。
このプロジェクトは同時に実験でもある。大会中、ロスターは2つの並行モードで走る。違いは「大会の進行に合わせた再学習は精度向上に寄与するか」という問いに対する答えだ。
両者を並走させることで、大会後に2点で比較できる。純粋な予測精度と、フィールドが絞られるにつれて不確実性がどれだけ早く収束するか。ラウンドごとが勝てば定期的な再学習の価値が証明され、固定が健闘すれば追加の仕掛けは不要かもしれない。
単一試合の予測と、「優勝確率はいくつか」を結びつけるのがモンテカルロシミュレーションだ。
まずは推論。確定している対戦だけでなく、出場48チームのあらゆる組み合わせを予測する。過剰に聞こえるが、ノックアウトではどの組み合わせも起こり得るため、すべてのペアに予測が必要だ。
次にルールの符号化。2026年方式は特に厄介だ。12グループの各上位2チームが自動的に進むほか、3位のうち上位8チームも進出する。そして、その8チームがどの決勝トーナメント枠に入るかは、どのグループから来たかに左右される。
12グループから8つを選ぶ組み合わせは495通り(12C8)。そのたびにラウンド32の組み合わせが異なる。きれいな公式はなく、FIFAは単に表を公表している。そこで私(正確には有能な同僚のCursor)は、公式表を元に495通りすべてをマッピングとしてハードコードした。
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...EFGHIJKLのようなキーは、3位通過チームを輩出した8つのグループを表し、値はそれぞれのチーム(3E、3Fなど)をラウンド32の特定の試合番号へ割り当てる。これは1件分で、完全版は495通りすべてについて同様の対応が並ぶ。
開催3か国(アメリカ、カナダ、メキシコ)には追加処理がある。自国開催の試合では、そのカードに限ってホームアドバンテージを適用し、それ以外は中立地として扱う。
予測とルールが揃えば、シミュレーションは大会全体を1万回走らせる。各回で以下を実行する。
1万回の大会で、あるチームが決勝進出・優勝を果たした割合が、そのチームの確率となる。1回の走行は推測、1万回の走行は予測だ。
ここまでのすべての実行(両モード)は、MLflow(DagsHub上でホスト)に記録される。実験管理とは、各実行の入力・設定・結果・出力を体系的に記録し、相互比較や完全再現を可能にすることだ。注目すべき点をいくつか挙げる。
学習済みモデルや予測ファイル(大会確率、グループ順位、試合予測)は実行アーティファクトとして保存され、ライブダッシュボードはまさにそれらを読み込む。これでループが閉じる。生の結果から、学習・シミュレーションを経て、オンラインで見られる数値まで。
最後のピースは、試合が確定した後に動く。実際の結果が届くたび、その試合に対して事前に出していた予測を採点し、単純な平均率ベースラインと比較する。もしフルモデルが、チーム情報を何も持たないモデルに劣り始めたら、それはドリフトの警告だ。大会前に学んだパターンが、ピッチ上の現実に合わなくなってきた可能性がある。
ライブ予測を行うあらゆるシステムでの標準的な実務であり、検知の詳細はデータドリフトとモデルドリフトのガイドで解説している。
ここまでの仕組みは、すべてこのためにある。
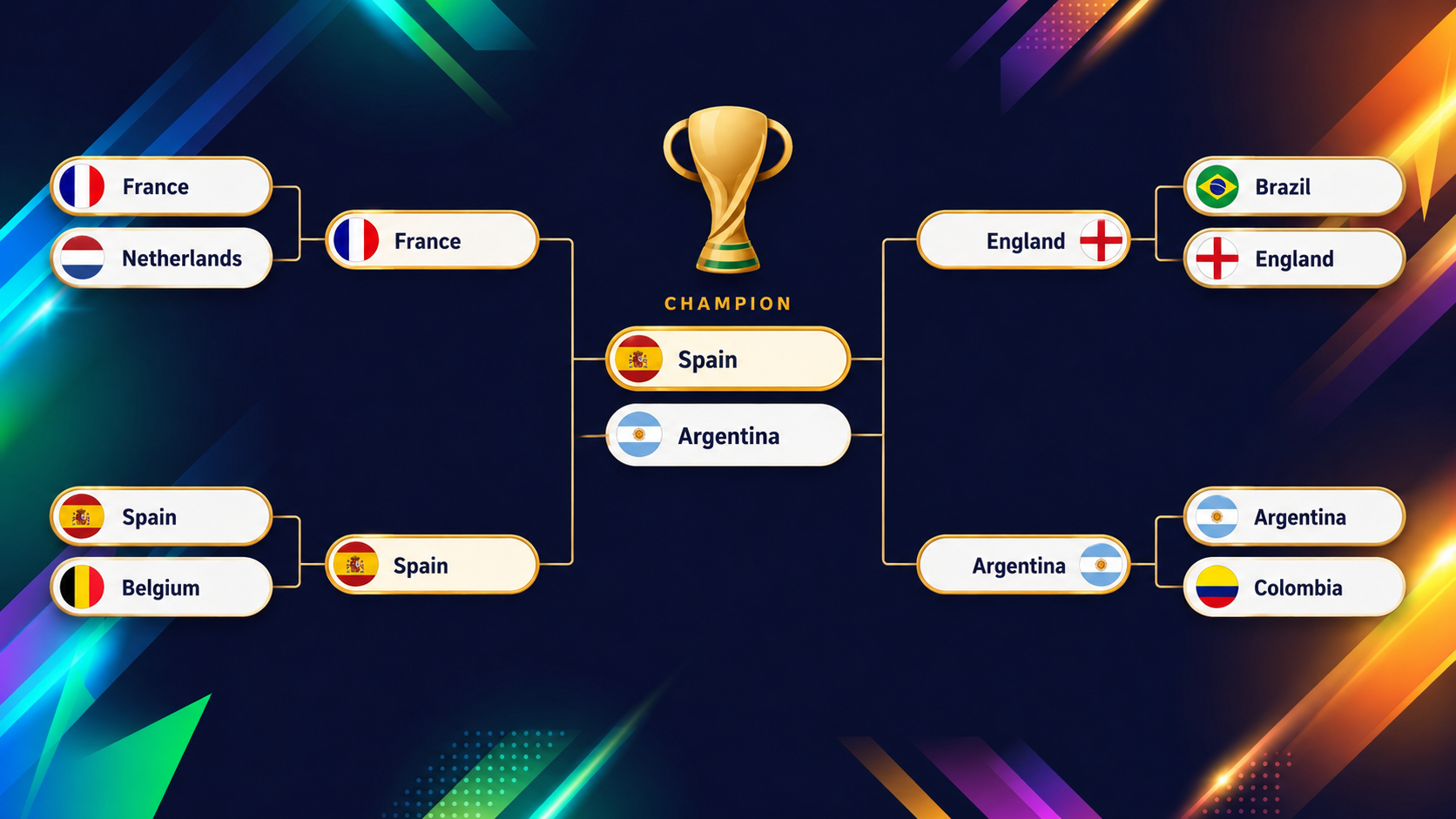
開幕前日の2026年6月10日時点で、最上位2強は明確だが、その直後は混戦だ。スペインとアルゼンチンがともに約16%でトップ。現役の世界王者(アルゼンチン)と欧州王者(スペイン)が頂点に来るのは、モデルが現実と整合しているという健全性チェックでもある。
その後方には、フランス、イングランド、ブラジル、コロンビアが続く。これらはライブな数値で、実際の結果が出た瞬間に動く。固定的な予言ではなく、6月10日時点のスナップショットとして扱ってほしい。ダッシュボードは常に最新値を表示し、遅延は最大でも2時間だ。
念のため:この記事の数値はすべて、パイプラインの実行に合わせて自動更新されるStreamlitアプリから来ている。wc2026-predictions.streamlit.appで開いて大会を追いかけられる。主なビューは4つ。
試合ビューの注意点を1つ。ラウンド32で同じチームが2つのスロットに同時に現れることがある。これはバグではない。グループが均衡しすぎて、モデルがそのチームの通過順位を自信を持って判別できない場合に起きる。ベスト3位の不確実性と合わさって、2通りのノックアウト枠に分岐する。トルコのケースでは、ラウンド16に2回現れることさえあった。
以下の図は、開幕前にXGBoostモデルが描いた最終ラウンド(準々決勝〜決勝)の投影だ。
こうしたモデルの醍醐味は、目測と食い違うチームだ。最もわかりやすい例がアメリカ。ダッシュボードの大会概要を見ると、色で一目瞭然だ。
開催国の1つとして地の利もあり、楽な滑り出しを期待するかもしれない。だがモデルはずっと慎重だ。グループ突破確率は約54.6%と見積もり、全48チーム中で下から13番目(3チームに2チームが突破する方式なのに!)。オーストラリア、パラグアイ、トルコと同居するグループが異常に拮抗しているためだ。
面白いのはその先。辛くも突破した後は、毎ラウンドおよそコインフリップの勝負が続く。そのコインフリップを積み重ねると、最終的な優勝確率は約2%となり、これは全48チーム中で上から13番目。
グループ突破確率が下から13番目で、優勝確率が上から13番目。まさに「コインフリップの代表」だ。常に本命ではないが、常にチャンスがある。
このプロジェクトは多くの労力を要し、1本の記事に収まりきらない範囲をカバーしている。リポジトリには、ここで触れなかった内容も多い。候補モデル一式、特徴量エンジニアリング、そして全体を動かすオーケストレーションなどだ。
現時点でモデルは予想を出し、あとは大会が審判となる。MLOps目当てでもサッカー目当てでも、過程を私と同じくらい楽しんでもらえれば嬉しい。ライブ予測で、試合の進行に合わせて数値の行方と予測の当たり具合を追ってみてほしい。
本文で触れた概念を深掘りしたい方には、MLOps Conceptsコースをおすすめする。
人気の機械学習コース
Courses
Courses
Courses