
Kursus
Memahami Machine Learning
2 Hr
299.3K
Sebuah prediksi hanya sebaik masukan yang digunakan, jadi ada baiknya mulai dari bahan bakunya. Model belajar dari dua sumber data live dan mengubahnya menjadi satu tabel fitur yang rapi.
Semuanya dibangun dari dua tempat. API-Football menyediakan jadwal dan statistik per pertandingan: siapa melawan siapa, kapan, di mana, dan bagaimana hasilnya. eloratings.net menyediakan rating Elo untuk setiap tim nasional.
Rating Elo adalah satu angka yang menangkap seberapa kuat sebuah tim. Setiap tim berada di suatu titik pada skala, dan setelah setiap pertandingan, rating diperbarui: kalahkan lawan yang lebih kuat, Anda mendapat banyak; kalah dari lawan yang lebih lemah, Anda turun tajam. Idenya berasal dari catur dan pas diterapkan ke sepak bola. Jika Anda ingin memahami sepenuhnya, artikel DataCamp sebelumnya ini membahasnya dalam konteks Piala Dunia 2022.
Bersama-sama, dua sumber tersebut memberikan dataset Gold sekitar 6.900 pertandingan internasional sejak 2018 untuk dipelajari.
Inilah pilihan desain penting pertama. Alih-alih memprediksi hasil langsung sebagai menang, seri, atau kalah, model memprediksi sesuatu yang lebih rinci: jumlah gol yang dicetak masing-masing tim dalam satu pertandingan. Jumlah gol dalam sepak bola, dengan pendekatan yang cukup baik, mengikuti distribusi Poisson, cara standar untuk memodelkan seberapa sering suatu kejadian yang relatif jarang terjadi dalam jangka waktu tetap.
Memprediksi gol alih-alih hasil adalah yang membuat semuanya berikutnya menjadi mungkin. Setelah model dapat menghasilkan skor yang masuk akal untuk pasangan mana pun, pertanyaan yang sebenarnya dipedulikan semua orang—siapa yang lolos dari grup dan siapa yang mengangkat trofi—bisa dijawab dengan mensimulasikan skor tersebut ribuan kali.
Setiap pertandingan dideskripsikan oleh sekumpulan fitur kecil yang dipilih dengan cermat:
Setiap fitur benar-benar aman dari kebocoran, artinya masing-masing hanya menggunakan informasi yang tersedia sebelum kick-off. Kedengarannya jelas, tetapi ini adalah salah satu cara termudah untuk tanpa sengaja membangun model yang terlihat brilian saat pengujian dan runtuh di dunia nyata.
Satu ide yang tidak lolos seleksi: saya berencana membuat serangkaian fitur "gaya bermain" yang dibangun dengan mengelompokkan tim dari statistik dalam pertandingan, sebuah langkah pembelajaran tanpa supervisi. Dalam praktiknya, tim-tim tersebut tidak terpisah menjadi kelompok yang bermakna, jadi daripada memberi model noise, saya menghapusnya. Hasil negatif tetaplah hasil.
Dengan data datang dari dua sumber secara bergulir, jalur dari file mentah ke fitur siap model harus identik setiap saat. Itulah yang disediakan oleh arsitektur medali. Ia mengorganisasi data ke dalam tiga lapisan:
Setiap lapisan mengalir ke berikutnya, jadi ketika sesuatu terlihat janggal, saya dapat menelusurinya kembali satu tahap demi tahap alih-alih mengurai semuanya sekaligus. Untuk membuat seluruh jalur dapat direproduksi, saya menggunakan DVC (Data Version Control). Setiap kali hasil baru masuk, satu dvc repro membangun ulang Silver dan Gold dari Bronze, menjalankan ulang sebuah langkah hanya jika inputnya berubah, dan memberi versi pada dataset yang dihasilkan sehingga kondisi sebelumnya dapat dipulihkan persis.
Memprediksi gol adalah masalah yang telah banyak dikaji, dan tidak ada satu alat yang jelas unggul untuk itu. Jadi alih-alih berkomitmen pada satu pendekatan sejak awal, saya membangun sepuluh dan membiarkan mereka bersaing.
Sepuluh model mencakup lima keluarga ditambah baseline sederhana. Anda tidak perlu mengetahui internal masing-masing; intinya adalah mereka membuat asumsi yang sangat berbeda tentang bagaimana gol tercipta.
| Keluarga | Model | Gagasan inti |
|---|---|---|
| Baseline | Poisson laju-rata | Mengasumsikan setiap tim sekadar mencetak rata-rata jangka panjang keseluruhan, mengabaikan semua fitur. Patokan yang harus dilampaui model lain. |
| Statistik | Poisson bivariat, Binomial Negatif | Memodelkan dua jumlah gol secara langsung dengan distribusi probabilitas yang dibuat untuk menghitung kejadian. |
| Bayesian | Poisson Bayesian (MCMC) | Gagasan menghitung yang sama, tetapi mengembalikan rentang ketidakpastian penuh di sekitar setiap estimasi. Jauh lebih menuntut komputasi: sekitar 100 kali lebih lambat untuk dilatih daripada yang lain. |
| Deret waktu | SARIMAX | Menganggap hasil tim sebagai urutan dari waktu ke waktu dan memproyeksikan urutan itu ke depan. |
| Pembelajaran mesin | Ridge, Random Forest, XGBoost | Mempelajari pola langsung dari fitur tanpa berkomitmen pada persamaan tetap. |
| Pembelajaran mendalam | LSTM, 1D CNN | Jaringan saraf yang mencari pola berurutan dan lokal dalam data. |
Dengan sepuluh kandidat, memilih pemenang dengan pandangan mata jelas tidak akan berhasil. Sebagai gantinya, setiap model melewati tiga tahap, dan kode yang memutuskan apakah ia melaju. Inilah yang dimaksud dengan deployment berbasis kode: model dipromosikan dari satu lingkungan ke lingkungan berikutnya oleh pemeriksaan otomatis alih-alih penyetelan manual, sehingga seluruh seleksi tetap dapat direproduksi dan mudah diaudit.
Jadi pendekatan mana yang keluar sebagai pemenang? Berikut papan peringkat holdout lengkap, dinilai dengan RPS (lebih rendah lebih baik):
| Model | RPS Holdout |
|---|---|
| XGBoost | 0.18289 |
| Poisson Bayesian | 0.18316 |
| Binomial Negatif | 0.18373 |
| Poisson Bivariat | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Poisson laju-rata (baseline) | 0.22872 |
Ada empat hal yang menonjol dari hasil ini:
 Untuk turnamen live, saya tidak menjalankan semua sepuluh. Saya mempertahankan daftar kecil: baseline laju-rata sebagai titik referensi, plus tiga performer terbaik. XGBoost dan Poisson Bayesian menempati dua posisi teratas.
Untuk turnamen live, saya tidak menjalankan semua sepuluh. Saya mempertahankan daftar kecil: baseline laju-rata sebagai titik referensi, plus tiga performer terbaik. XGBoost dan Poisson Bayesian menempati dua posisi teratas.
Posisi ketiga pada dasarnya seri: Binomial Negatif dan Poisson Bivariat finis dalam selisih 0,0002 RPS dan saling bertukar tempat tergantung benih acak, jadi di antara dua model yang secara statistik tak terbedakan, saya memilih Poisson Bivariat, yang rumusannya memiliki pijakan lebih kuat dalam literatur prediksi sepak bola (Karlis dan Ntzoufras, 2004).
Itu menyisakan daftar XGBoost (pembelajaran mesin), Poisson Bivariat (statistik klasik), dan Poisson Bayesian (inferensi Bayesian). Bagian berikut membahas bagaimana model-model tersebut dijalankan, dilatih ulang, dan mengubah prediksi pertandingan tunggal menjadi ramalan turnamen lengkap.
Model yang hidup di notebook hanya berguna saat Anda duduk di depannya. Untuk memprediksi pertandingan sepanjang turnamen sebulan penuh, semuanya harus berjalan sendiri: menarik hasil baru, berlatih ulang, mensimulasikan ulang, dan menyegarkan ramalan tanpa ada yang menyentuhnya. Itulah tugas pipeline.
Seluruh proyek berjalan sebagai satu job terjadwal di Google Cloud Run. Sebelum turnamen, ia bangun sekali sehari; mulai laga pembuka pada 11 Juni, ia berjalan setiap dua jam. Setiap run mengikuti siklus yang sama:
dvc repro membangun ulang lapisan Silver dan Gold agar fitur mutakhir.Karena setiap langkah dipicu oleh kode pada jadwal, tidak ada penekanan tombol manual selama turnamen. Hasil baru masuk, ramalan segar keluar.
Di sinilah proyek ini berperan ganda sebagai eksperimen. Selama turnamen, daftar model berjalan dalam dua mode paralel, dan perbedaannya adalah pertanyaan yang saya harap bisa dijawab dari data: Apakah melatih ulang seiring turnamen berlangsung membuat prediksi menjadi lebih baik?
Menjalankan keduanya berdampingan memungkinkan saya membandingkannya di dua sisi setelah selesai: akurasi prediksi mentah, dan seberapa cepat ketidakpastian masing-masing menyusut seiring menyempitnya peserta. Jika per-putaran menang, pelatihan ulang rutin terbukti berguna; jika beku mampu bersaing, mesin tambahan itu mungkin tidak sepadan.
Memprediksi satu pertandingan adalah satu hal. Mengubahnya menjadi "berapa peluang setiap tim menjuarai turnamen" adalah ranah simulasi Monte Carlo.
Pertama, inferensi. Alih-alih hanya memprediksi jadwal yang sudah kita ketahui, model memprediksi setiap kemungkinan pasangan di antara 48 tim. Kedengarannya berlebihan, tetapi di turnamen, tim mana pun bisa bertemu tim mana pun di fase gugur, jadi prediksi harus siap untuk setiap pasangan.
Berikutnya, aturannya harus dikodekan, dan format 2026 membuatnya sangat rumit. Di 12 grup, dua teratas lolos otomatis, tetapi begitu pula delapan tim peringkat ketiga terbaik, dan slot fase gugur mana yang ditempati masing-masing delapan tim itu bergantung pada dari grup mana mereka berasal.
Ada 495 cara untuk memilih delapan grup yang meloloskan peringkat ketiga dari dua belas (dua belas pilih delapan), dan masing-masing menghasilkan susunan pasangan 32 besar yang berbeda. Tidak ada rumus bersih untuk ini; FIFA hanya menerbitkan tabel. Jadi saya (atau tepatnya rekan saya yang sangat andal Cursor) meng-hardcode semua 495 kombinasi ke dalam sebuah pemetaan, menggunakan tabel resmi sebagai sumber.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Setiap kunci, seperti EFGHIJKL, mencantumkan grup mana yang memasok tim peringkat ketiga yang lolos, dan nilainya menempatkan masing-masing tim tersebut (3E, 3F, dan seterusnya) ke nomor pertandingan 32 besar tertentu. Itu satu entri; pemetaan lengkap mengulanginya 495 kali, sekali per kombinasi.
Tiga negara tuan rumah (Amerika Serikat, Kanada, dan Meksiko) mendapat perlakuan tambahan. Ketika tuan rumah memainkan pertandingan yang digelar di negaranya sendiri, simulasi menerapkan penyesuaian keunggulan kandang untuk laga tersebut, sementara sisa turnamen diperlakukan sebagai tempat netral.
Dengan prediksi dan aturan yang siap, simulasi menjalankan seluruh turnamen 10.000 kali. Pada setiap run, prosedurnya sebagai berikut:
Di seluruh 10.000 turnamen simulasi, porsi run di mana sebuah tim mencapai final, atau mengangkat trofi, menjadi probabilitas tim tersebut. Satu run adalah tebakan; sepuluh ribu run adalah ramalan.
Setiap run yang dijelaskan sejauh ini, di kedua mode, dicatat ke MLflow (di-host di DagsHub). Pelacakan eksperimen berarti mencatat secara sistematis input, pengaturan, hasil, dan output dari setiap run, sehingga semuanya bisa dibandingkan satu sama lain atau direproduksi persis. Beberapa hal yang ditangkapnya patut disorot:
Model terlatih dan file prediksi itu sendiri (probabilitas turnamen, klasemen grup, dan ramalan pertandingan) disimpan sebagai artefak run, dan file-file itulah yang dibaca oleh dashboard live. Itu menutup lingkaran: dari hasil mentah, melalui pelatihan dan simulasi, hingga angka yang dapat Anda lihat secara online.
Bagian terakhir berjalan setelah pertandingan tuntas. Saat hasil nyata tiba, prediksi yang dibuat untuknya diberi skor dan dibandingkan dengan baseline laju-rata sederhana. Jika model lengkap mulai tertinggal dari model yang tidak tahu apa-apa tentang tim, itu adalah tanda peringatan drift: pola yang dipelajari sebelum turnamen mungkin tidak lagi cocok dengan apa yang terjadi di lapangan.
Mengawasi hal ini adalah praktik standar untuk sistem apa pun yang membuat prediksi live, dan Anda dapat membaca lebih lanjut tentang cara mendeteksinya dalam panduan data drift dan model drift.
Setelah semua mesin itu, inilah tujuannya.
Per 10 Juni 2026, sehari sebelum laga pembuka, putusan model jelas di puncak dan padat tepat di belakangnya. Spanyol dan Argentina memimpin, masing-masing dengan sekitar 16% peluang mengangkat trofi. Fakta bahwa juara dunia bertahan (Argentina) dan juara Eropa bertahan (Spanyol) berada di puncak adalah pemeriksaan kewarasan yang meyakinkan bahwa model berpijak pada realitas.
Di belakang mereka ada kelompok pengejar yang rapat: Prancis, Inggris, Brasil, dan Kolombia melengkapi kandidat pemenang paling mungkin. Ini adalah angka live, dan akan bergerak begitu hasil nyata mulai datang, jadi perlakukan sebagai cuplikan 10 Juni, bukan ramalan tetap. Dashboard selalu menampilkan angka terkini, dengan jeda maksimal dua jam.
Ngomong-ngomong: Setiap angka dalam artikel ini berasal dari aplikasi Streamlit live yang memperbarui otomatis seiring pipeline berjalan. Anda dapat membukanya di wc2026-predictions.streamlit.app dan mengikutinya sepanjang turnamen. Ada empat tampilan utama:
Satu keunikan yang perlu dicatat di tampilan pertandingan: beberapa tim muncul di dua kemungkinan slot 32 besar sekaligus. Itu bukan bug. Ini terjadi ketika sebuah grup begitu berimbang sehingga model tidak dapat dengan yakin menentukan posisi kualifikasi yang akan diambil sebuah tim. Dikombinasikan dengan ketidakpastian peringkat ketiga terbaik, dua hasil itu mengarah ke slot fase gugur yang berbeda. Dalam kasus Turki, ini bahkan membuat mereka dua kali berada di babak 16 besar.
Grafik berikut menunjukkan babak akhir (perempat final hingga final) yang diproyeksikan model XGBoost sebelum kick-off turnamen:
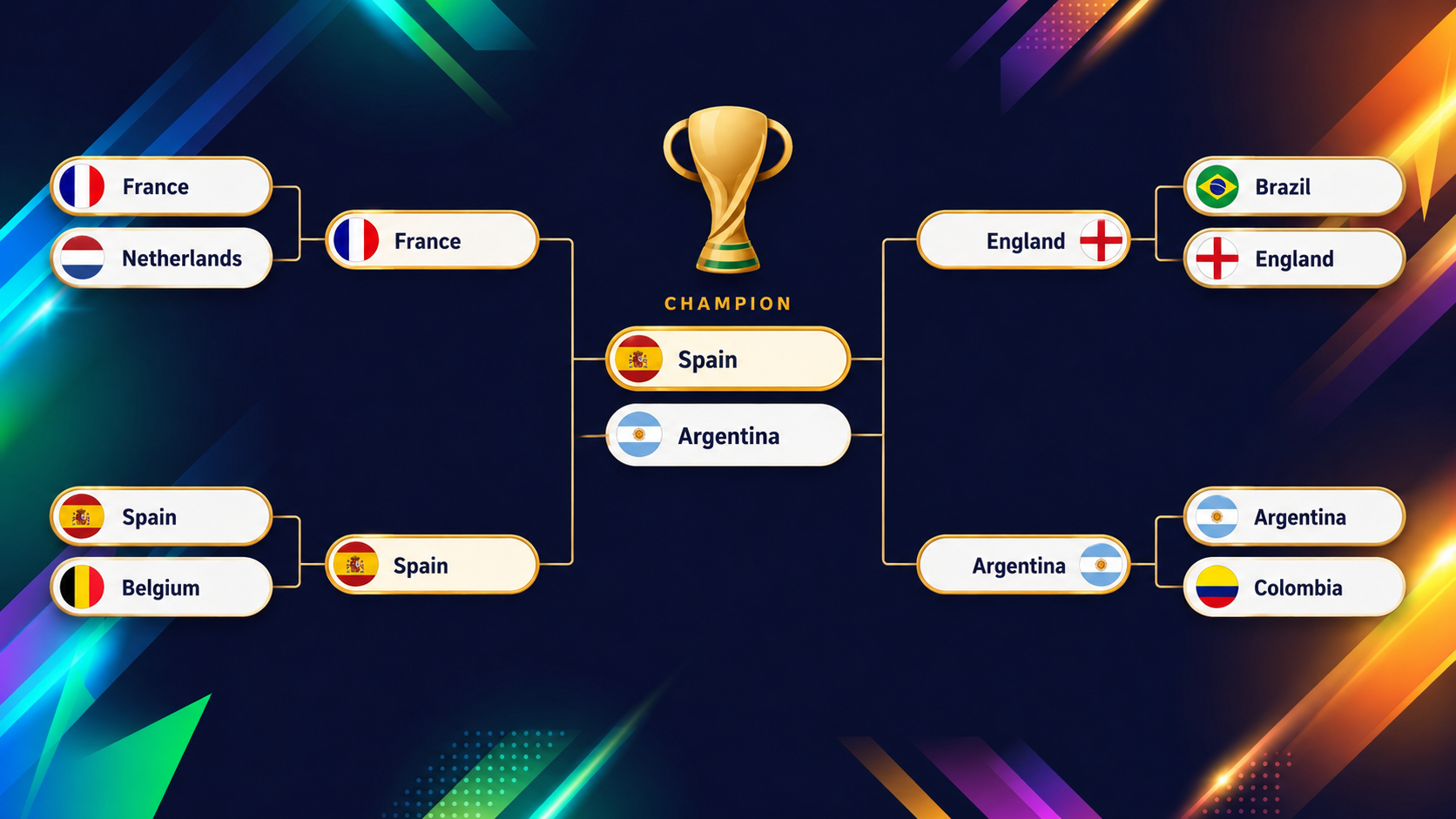
Serunya model seperti ini ada pada tim-tim yang menantang penilaian kasatmata, dan contoh paling jelas adalah Amerika Serikat. Jika Anda membuka gambaran turnamen di dashboard, Anda akan langsung melihat AS menonjol warnanya.
Sebagai tuan rumah bersama yang bermain di depan pendukung sendiri, Anda mungkin mengharapkan start yang nyaman, tetapi model jauh lebih berhati-hati: model hanya memberi mereka sekitar 54,6% peluang lolos dari grup, ke-13 terendah di seluruh peserta (ingat bahwa dua pertiga tim lolos!), karena grup mereka dengan Australia, Paraguay, dan Turki sangat berimbang.
Bagian menariknya adalah apa yang terjadi selanjutnya. Setelah lolos dengan susah payah, AS kemudian berada di sekitar lempar koin di setiap babak berikutnya. Menumpuk lemparan koin itu menghasilkan sekitar 2% peluang menjuarai seluruh turnamen, yang merupakan ke-13 tertinggi dari semua 48 tim.
Tim yang berada di peringkat ke-13 dari bawah untuk lolos grup dan ke-13 dari atas untuk menjuarai turnamen adalah definisi sempurna tim lempar koin: tidak pernah favorit, tidak pernah benar-benar tersisih.
Proyek ini memakan banyak pekerjaan, dan mencakup jauh lebih banyak hal daripada yang bisa dimuat dalam satu artikel. Repo berisi banyak hal yang tidak masuk di sini: seluruh set kandidat model, rekayasa fitur, dan orkestrasi yang menjaga semuanya tetap berjalan adalah beberapa contohnya.
Untuk saat ini, model telah membuat pilihannya, dan turnamen akan menjadi hakim. Apakah Anda datang untuk MLOps atau sepak bolanya, saya harap Anda menikmati menyaksikannya bergulir sama seperti saya. Anda dapat mengikuti ramalan live seiring pertandingan bergulir dan melihat seberapa baik prediksinya bertahan.
Jika Anda ingin melihat lebih dekat beberapa konsep yang saya sebutkan, saya sarankan mengambil kursus MLOps Concepts kami.
Kursus Machine Learning Teratas
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
