course
Introduktion till maskininlärning
2 timmar
299.3K
En prognos blir aldrig bättre än vad som matas in i den, så det är värt att börja med råvarorna. Modellen lär sig av två livedatakällor och förvandlar dem till en enda, prydlig feature-tabell.
Allt byggs från två håll. API-Football tillhandahåller spelscheman och matchstatistik: vilka som möttes, när, var och hur det slutade. eloratings.net tillhandahåller Elo-ratingar för varje landslag.
En Elo-rating är ett enda tal som fångar hur starkt ett lag är. Varje lag finns någonstans på skalan och efter varje match uppdateras ratingen: slå ett starkare lag och du tjänar mycket; förlora mot ett svagare och du tappar rejält. Idén kommer från schack och passar snyggt för fotboll. Vill du ha hela intuitionen går denna tidigare DataCamp-artikel igenom den i kontexten av VM 2022.
Tillsammans ger de två källorna ett Gold-dataset med ungefär 6 900 landskamper sedan 2018 att lära av.
Här är det första viktiga designvalet. I stället för att förutsäga utfall direkt som vinst, oavgjort eller förlust förutspår modellen något mer finmaskigt: hur många mål varje lag gör i en match. Målantal i fotboll följer, med god approximation, en Poisson-fördelning, standardmetoden för att modellera hur ofta en relativt sällsynt händelse inträffar under ett fast tidsfönster.
Att förutsäga mål snarare än resultat är det som gör allt senare möjligt. När modellen kan ge en plausibel målrad för vilken matchning som helst kan de frågor alla egentligen bryr sig om – vilka som tar sig ur gruppen och vem som lyfter bucklan – besvaras genom att simulera dessa målrader tusentals gånger.
Varje match beskrivs av en liten, noggrant vald uppsättning features:
Varje feature är strikt läckagesäker, vilket betyder att var och en endast använder information som fanns tillgänglig före avspark. Det låter självklart, men det är ett av de lättaste sätten att av misstag bygga en modell som ser briljant ut i test och faller isär i verkligheten.
En idé som inte kom med: jag planerade en uppsättning "spelsstils"-features byggda genom att klustra lag utifrån deras in-game-statistik, ett steg i osuperviserat lärande. I praktiken separerade sig inte lagen i meningsfulla grupper, så i stället för att mata modellen med brus strök jag det. Negativa resultat är också resultat.
När data anländer från två källor löpande måste vägen från råfiler till modellklara features vara identisk varje gång. Det är vad en medaljongsarkitektur ger. Den organiserar data i tre lager:
Varje lager matar nästa, så när något ser fel ut kan jag spåra tillbaka ett steg i taget i stället för att reda ut allt på en gång. För att göra hela kedjan reproducerbar använder jag DVC (Data Version Control). När färska resultat kommer in räcker ett dvc repro för att bygga om Silver och Gold från Bronze, köra om ett steg bara om dess indata ändrats och versionshantera de resulterande dataseten så att vilket tidigare tillstånd som helst kan återställas exakt.
Att förutsäga mål är ett välstuderat problem och det finns inget självklart verktyg. Så i stället för att låsa mig vid ett angreppssätt från början byggde jag tio och lät dem tävla.
De tio modellerna spänner över fem familjer plus en enkel baslinje. Du behöver inte känna till varje modells inre; poängen är att de gör mycket olika antaganden om hur mål uppstår.
| Familj | Modeller | Kärnidén |
|---|---|---|
| Baslinje | Poisson med medelhastighet | Antar att varje lag helt enkelt gör ett övergripande långsiktigt snitt, och ignorerar alla features. En lägstanivå för de andra att slå. |
| Statistisk | Bivariat Poisson, Negativ binomial | Modellerar de två målantalens fördelningar direkt med sannolikhetsfördelningar gjorda för räknehändelser. |
| Bayesiansk | Bayesiansk Poisson (MCMC) | Samma räkningsidé, men returnerar ett fullt osäkerhetsintervall kring varje uppskattning. Betydligt tyngre att beräkna: ungefär 100 gånger långsammare att anpassa än de övriga. |
| Tidsserier | SARIMAX | Behandlar ett lags resultat som en sekvens över tid och projicerar sekvensen framåt. |
| Maskininlärning | Ridge, Random Forest, XGBoost | Lär mönster direkt från features utan att låsa sig vid en fast ekvation. |
| Djupinlärning | LSTM, 1D CNN | Neuronnät som letar efter sekventiella och lokala mönster i datan. |
Med tio kandidater var det aldrig aktuellt att välja en vinnare på känn. I stället passerar varje modell tre steg, och koden avgör om den går vidare. Det är detta som avses med kodbaserad driftsättning: modeller flyttas från en miljö till nästa via automatiska kontroller i stället för manuell justering, så att hela urvalet förblir reproducerbart och lätt att granska.
Så vilken metod toppade? Här är hela holdout-tabellen, bedömd med RPS (lägre är bättre):
| Modell | Holdout RPS |
|---|---|
| XGBoost | 0.18289 |
| Bayesiansk Poisson | 0.18316 |
| Negativ binomial | 0.18373 |
| Bivariat Poisson | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Poisson med medelhastighet (baslinje) | 0.22872 |
Fyra saker sticker ut från dessa resultat:
 Inför live-turneringen kör jag inte alla tio. Jag behåller en mindre trupp: baslinjen med medelhastighet som referenspunkt, plus de tre bästa. XGBoost och Bayesiansk Poisson tar de två topplatserna.
Inför live-turneringen kör jag inte alla tio. Jag behåller en mindre trupp: baslinjen med medelhastighet som referenspunkt, plus de tre bästa. XGBoost och Bayesiansk Poisson tar de två topplatserna.
Tredjeplatsen är i praktiken oavgjord: Negativ binomial och Bivariat Poisson hamnar inom 0,0002 RPS från varandra och byter plats beroende på slumpfrö, så mellan två statistiskt oskiljbara modeller valde jag Bivariat Poisson, vars formulering har starkare fotfäste i fotbollsprognoslitteraturen (Karlis och Ntzoufras, 2004).
Det lämnar en trupp bestående av XGBoost (maskininlärning), Bivariat Poisson (klassisk statistik) och Bayesiansk Poisson (bayesiansk inferens). Nästa avsnitt täcker hur dessa modeller körs, tränas om och förvandlar matchprognoser till en fullständig turneringsprognos.
En modell som lever i en notebook är bara användbar medan du sitter framför den. För att förutspå matcher under en månadslång turnering måste allt rulla av sig självt: hämta nya resultat, träna om, simulera på nytt och uppdatera prognosen utan handpåläggning. Det är pipelinens jobb.
Hela projektet körs som ett enda schemalagt jobb på Google Cloud Run. Före turneringen vaknar den en gång om dagen; från öppningsmatchen den 11 juni körs den varannan timme. Varje körning följer samma cykel:
dvc repro bygger om Silver- och Gold-lagren så att features är aktuella.Eftersom varje steg triggas av kod enligt schema finns ingen manuell knapptryckning under turneringen. Nya resultat in, uppdaterad prognos ut.
Här fungerar projektet också som ett experiment. Under turneringen körs truppen i två parallella lägen, och skillnaden mellan dem är frågan jag hoppas besvara med data: Blir prognoserna bättre om man tränar om allteftersom turneringen fortskrider?
Att köra båda sida vid sida låter mig jämföra dem på två fronter när allt är över: rå prediktiv noggrannhet och hur snabbt var och ens osäkerhet minskar när fältet smalnar. Om per omgång vinner är regelbunden omträning mödan värd; om fruset håller jämna steg kanske den extra mekaniken inte är värd besväret.
Att förutsäga en enskild match är en sak. Att omvandla det till ”hur stor chans har varje lag att vinna turneringen” är där Monte Carlo-simuleringen kommer in.
Först inferens. I stället för att bara förutsäga de matcher vi redan känner till förutspår modellen varje möjlig matchning bland de 48 lagen. Det låter överdrivet, men i en turnering kan vilket lag som helst möta vilket annat i slutspelet, så en prognos måste vara redo för varje parning.
Sedan måste reglerna kodas, och 2026 års format gör det särskilt besvärligt. I de 12 grupperna går topp två automatiskt vidare, men det gör också de åtta bästa treorna, och vilken slutspelsplats var och en av dessa åtta hamnar på beror på vilka grupper de kom ifrån.
Det finns 495 sätt att välja åtta kvalificerande grupper av tolv (tolv över åtta), och vart och ett ger en annan uppsättning 32-delsfinaler. Det finns ingen elegant formel för det; FIFA publicerar helt enkelt en tabell. Så jag (eller snarare min mycket kapabla kollega Cursor) hårdkodade alla 495 kombinationer i en mapping, med den officiella tabellen som källa.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Varje nyckel, som EFGHIJKL, listar vilka åtta grupper som levererade de vidaregående treorna, och värdena placerar vart och ett av dessa lag (3E, 3F osv.) i en specifik 32-delsfinal med matchnummer. Det är en post; hela mappen upprepar detta 495 gånger, en gång per kombination.
De tre värdnationerna (USA, Kanada och Mexiko) får en extra hantering. När en värd spelar en match i sitt eget land tillämpas en hemmaplansjustering i simuleringen för den matchen, medan resten av turneringen betraktas som neutral plan.
Med prognoserna och reglerna på plats kör simuleringen hela turneringen 10 000 gånger. I varje körning följer den denna procedur:
Över 10 000 simulerade turneringar blir andelen körningar där ett lag når final eller lyfter bucklan lagets sannolikhet. En körning är en gissning; tiotusen körningar är en prognos.
Varje körning som hittills beskrivits, i båda lägena, loggas till MLflow (hostat på DagsHub). Experimentspårning innebär att systematiskt registrera indata, inställningar, resultat och utdata från varje körning, så att vilken som helst kan jämföras mot de andra eller reproduceras exakt. Några saker som fångas är värda att lyfta:
De tränade modellerna och själva prognosfilerna (turneringssannolikheter, gruppställningar och matchprognoser) lagras som körningsartefakter, och det är exakt dessa filer som den live-instrumentpanelen läser. Det sluter loopen: från råa resultat, genom träning och simulering, till siffrorna du kan se online.
Den sista delen körs när matcher är avgjorda. När riktiga resultat anländer poängsätts de prognoser som gjordes för dem och jämförs med den enkla baslinjen med medelhastighet. Om fullmodellerna börjar tappa mark mot en modell som inte vet något om lagen är det en varningssignal om drift: mönstren som lärdes före turneringen kanske inte längre matchar vad som händer på planen.
Att bevaka detta är standardpraxis för alla system som gör liveprognoser, och du kan läsa mer om hur detekteringen går till i denna guide till datadrift och modelldrift.
Efter all denna maskineri – här är vad det är till för.
Per den 10 juni 2026, dagen före öppningsmatchen, är modellens dom tydlig i toppen och tät strax bakom. Spanien och Argentina leder fältet, båda med ungefär 16 % chans att lyfta bucklan. Att de regerande världsmästarna (Argentina) och de regerande Europamästarna (Spanien) hamnar överst är en betryggande rimlighetskontroll på att modellen är förankrad i verkligheten.
Bakom dem finns en tät jagande klunga: Frankrike, England, Brasilien och Colombia kompletterar de troligaste vinnarna. Detta är live-siffror och de rör sig så snart riktiga resultat börjar trilla in, så betrakta dem som en ögonblicksbild från den 10 juni snarare än en fast profetia. Instrumentpanelen visar alltid de aktuella siffrorna, med högst två timmars fördröjning.
På tal om det: Varenda siffra i den här artikeln kommer från en live-Streamlit-app som uppdateras automatiskt när pipelinen körs. Du kan öppna den på wc2026-predictions.streamlit.app och följa turneringen. Den har fyra huvudvyer:
En egenhet värd att flagga i matchvyn: ett par lag dyker upp i två möjliga 32-delsfinalplatser samtidigt. Det är inte ett fel. Det händer när en grupp är så jämn att modellen inte kan avgöra med säkerhet vilken kvalificeringsposition ett lag tar. Kombinerat med osäkerheten kring bästa treor leder de två utfallen till olika slutspelsplatser. För Turkiet ledde det till och med till att de var med två gånger i åttondelsfinal.
Följande grafik visar de avslutande rundorna (kvartsfinal till final) som XGBoost-modellen projicerar före turneringsstart:
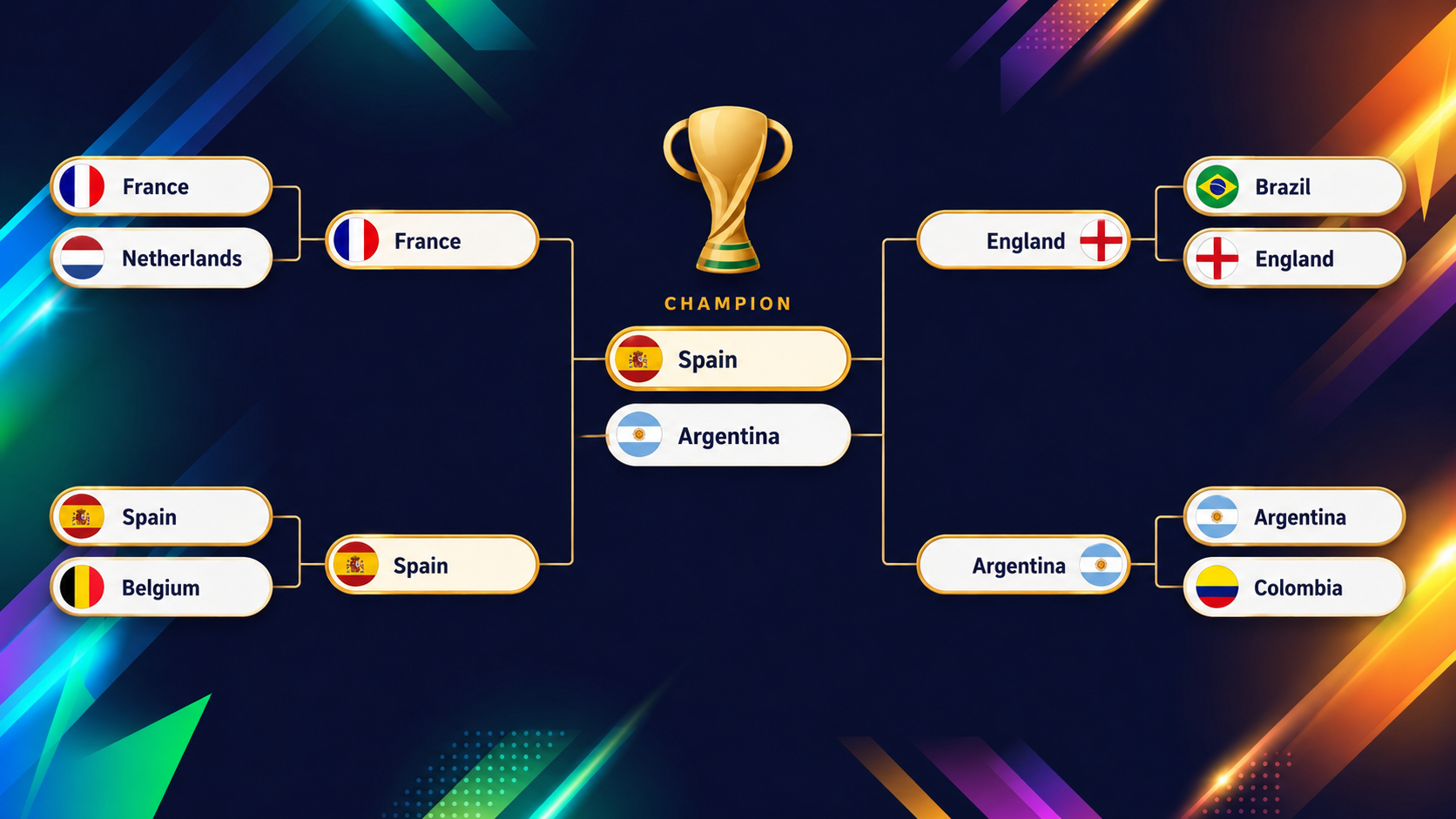
Det roliga med en sådan här modell ligger i lagen som trotsar ögonmåttet, och det tydligaste exemplet är USA. Går du till turneringsöversikten på instrumentpanelen märker du direkt att USA sticker ut i färg.
Som medvärdar inför hemmapublik kan du kanske vänta dig en bekväm start, men modellen är betydligt mer försiktig: den ger dem bara omkring 54,6 % chans att ta sig ur gruppen, den 13:e lägsta i hela fältet (kom ihåg att två tredjedelar av lagen kvalificerar sig!), eftersom deras grupp med Australien, Paraguay och Turkiet är ovanligt jämn.
Det intressanta kommer sedan. Har de krånglat sig vidare ligger USA sedan på ungefär slantsingling i varje följande omgång. Staplar du dessa slantsinglingar hamnar de på cirka 2 % chans att vinna hela turneringen, vilket är den 13:e högsta av alla 48 lag.
Ett lag som rankas 13:e från botten att ta sig ur gruppen och 13:e från toppen att vinna allt är så nära en perfekt definition av ett slantsinglingslag du kan komma: aldrig favorit, aldrig uträknat.
Det här projektet var mycket arbete och täcker långt mer än vad en artikel rymmer. Repon innehåller mycket som inte fick plats här: hela uppsättningen kandidatmodeller, feature engineering och orkestreringen som håller allt rullande är några exempel.
För nu har modellen gjort sina val, och turneringen blir domare. Oavsett om du kom för MLOps eller fotbollen hoppas jag att du tycker det är lika roligt att följa det som jag. Du kan följa live-prognosen när matcherna spelas och se hur väl förutsägelserna står sig.
Vill du titta närmare på några av begreppen jag nämnt rekommenderar jag vår kurs MLOps Concepts.
Toppkurser i maskininlärning
course
course
course