
Cours
Comprendre le Machine Learning
2 h
299.3K
Une prédiction ne vaut que par ce qu'on y met. Autant commencer par la matière première. Le modèle apprend à partir de deux sources de données en direct et les transforme en une table de variables propre et unifiée.
Tout part de deux sources. API-Football fournit le calendrier et les statistiques par match : qui a joué contre qui, quand, où et avec quel score. eloratings.net fournit les classements Elo de chaque sélection nationale.
Un classement Elo est un nombre qui résume la force d'une équipe. Chaque équipe se situe sur l'échelle, et après chaque match, la note bouge : battre plus fort que soi rapporte beaucoup ; perdre contre plus faible coûte cher. Le concept vient des échecs et s'adapte très bien au football. Pour l'intuition complète, cet article DataCamp le détaille dans le contexte de la Coupe du monde 2022.
Ensemble, ces deux sources donnent un jeu de données Gold d'environ 6 900 matchs internationaux depuis 2018.
Voici un premier choix de conception important. Plutôt que de prédire directement l'issue (victoire, nul, défaite), le modèle prédit quelque chose de plus fin : le nombre de buts marqués par chaque équipe dans un match. Les buts au football suivent, à une bonne approximation, une loi de Poisson, la référence pour modéliser la survenue d'événements rares dans une fenêtre de temps fixe.
Prédire les buts plutôt que le résultat rend tout le reste possible. Une fois que le modèle sait générer un score plausible pour n'importe quelle affiche, on peut répondre aux vraies questions — qui sort des groupes, qui soulève le trophée — en simulant ces scores des milliers de fois.
Chaque match est décrit par un petit ensemble de variables soigneusement choisies :
Toutes les variables sont étanches à toute fuite d'information : elles n'utilisent que ce qui est disponible avant le coup d'envoi. Cela semble évident, mais c'est l'un des meilleurs moyens, sinon, de construire un modèle brillant en test et friable en production.
Une idée écartée : j'avais prévu des variables de « style de jeu » via un apprentissage non supervisé en regroupant les équipes selon leurs statistiques en match. En pratique, les groupes n'étaient pas parlants. Plutôt que d'injecter du bruit, je les ai retirées. Un résultat négatif reste un résultat.
Avec des données arrivant en continu de deux sources, le chemin des fichiers bruts aux variables prêt-à-modéliser doit être identique à chaque exécution. C'est ce que fournit une architecture médaillon. Elle organise les données en trois couches :
Chaque couche alimente la suivante, ce qui permet de remonter pas à pas en cas d'anomalie, plutôt que de tout démêler d'un bloc. Pour rendre tout le processus reproductible, j'utilise DVC (Data Version Control). À chaque nouveaux résultats, une simple commande dvc repro reconstruit Silver et Gold depuis Bronze, ne relançant une étape que si ses entrées ont changé, et versionne les datasets pour pouvoir revenir exactement à tout état antérieur.
La prédiction de buts est bien étudiée et il n'existe pas d'outil unique évident. Plutôt que de choisir d'emblée, j'en ai construit dix et les ai laissés se départager.
Les dix modèles couvrent cinq familles, plus un simple point de référence. Pas besoin d'en connaître les entrailles : ils reposent sur des hypothèses très différentes sur la façon dont les buts surviennent.
| Famille | Modèles | Idée de base |
|---|---|---|
| Référence | Poisson à taux moyen | Suppose que chaque équipe marque simplement sa moyenne de long terme, en ignorant toutes les variables. Le plancher à dépasser. |
| Statistique | Poisson bivarié, Binomiale négative | Modélise directement les deux comptes de buts avec des lois de probabilité adaptées aux événements comptables. |
| Bayésien | Poisson bayésien (MCMC) | Même idée de comptage, mais renvoie une incertitude complète autour de chaque estimation. Bien plus coûteux en calcul : environ 100 fois plus lent à ajuster que les autres. |
| Séries temporelles | SARIMAX | Considère les résultats d'une équipe comme une séquence dans le temps et projette cette séquence. |
| Apprentissage automatique | Ridge, Random forest, XGBoost | Apprend les motifs directement à partir des variables sans imposer d'équation fixe. |
| Deep learning | LSTM, CNN 1D | Réseaux neuronaux qui détectent des motifs séquentiels et locaux dans les données. |
Avec dix candidats, impossible de choisir au jugé. Chaque modèle passe donc par trois étapes, et le code décide s'il progresse. C'est ce qu'on entend par déploiement piloté par le code : les modèles sont promus d'un environnement au suivant via des contrôles automatisés plutôt que par des ajustements manuels, ce qui rend la sélection reproductible et facile à auditer.
Alors, quelle approche sort du lot ? Voici le classement complet sur le jeu de réserve, au RPS (plus bas est mieux) :
| Modèle | RPS holdout |
|---|---|
| XGBoost | 0.18289 |
| Poisson bayésien | 0.18316 |
| Binomiale négative | 0.18373 |
| Poisson bivarié | 0.18389 |
| Random forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| CNN 1D | 0.20916 |
| Poisson à taux moyen (référence) | 0.22872 |
Quatre points marquants se dégagent :
 Pour le direct, je ne lance pas les dix modèles. Je garde une sélection réduite : la baseline à taux moyen comme point de repère, plus les trois meilleurs. XGBoost et Poisson bayésien occupent les deux premières places.
Pour le direct, je ne lance pas les dix modèles. Je garde une sélection réduite : la baseline à taux moyen comme point de repère, plus les trois meilleurs. XGBoost et Poisson bayésien occupent les deux premières places.
La troisième place est un quasi ex æquo : la Binomiale négative et le Poisson bivarié sont à 0,0002 de RPS l'un de l'autre et échangent selon la graine aléatoire. Entre deux modèles statistiquement indiscernables, j'ai retenu le Poisson bivarié, mieux établi dans la littérature de prédiction footballistique (Karlis et Ntzoufras, 2004).
La sélection finale retient XGBoost (apprentissage automatique), Poisson bivarié (statistiques classiques) et Poisson bayésien (inférence bayésienne). La suite explique comment ces modèles tournent, se réentraînent et transforment des prédictions de matchs en prévisions de tournoi.
Un modèle coincé dans un notebook n'est utile que quand vous êtes devant. Pour couvrir un mois de compétition, tout doit tourner en autonomie : récupérer, réentraîner, resimuler, actualiser — sans intervention humaine. C'est le rôle du pipeline.
L'ensemble tourne comme une tâche planifiée sur Google Cloud Run. Avant le tournoi, une exécution quotidienne ; dès le match d'ouverture le 11 juin, toutes les deux heures. À chaque cycle :
dvc repro reconstruit les couches Silver et Gold pour remettre les variables à jour.Parce que tout est déclenché par du code à horaires fixes, personne n'a de bouton à presser pendant le tournoi. Nouveau résultat en entrée, prévision rafraîchie en sortie.
Le projet sert aussi d'expérience contrôlée. Pendant le tournoi, deux modes tournent en parallèle. L'objectif est de répondre empiriquement à la question : réentraîner au fil de l'eau améliore-t-il les prédictions ?
Les faire tourner côte à côte permet de les comparer, après coup, sur deux axes : la précision brute et la vitesse à laquelle l'incertitude se réduit à mesure que le champ se resserre. Si le mode « par tour » gagne, le réentraînement régulier se justifie ; si le mode figé tient la route, l'appareil supplémentaire n'est peut-être pas nécessaire.
Prédire un match est une chose. En déduire « quelles sont les chances de chaque équipe de gagner le tournoi » requiert la simulation Monte Carlo.
D'abord, l'inférence. Plutôt que de prédire seulement les affiches déjà connues, le modèle évalue tous les duels possibles entre les 48 équipes. Cela peut paraître excessif, mais en tournoi, n'importe quelle équipe peut affronter n'importe quelle autre en phase finale : il faut donc une prédiction prête pour chaque paire.
Ensuite, il faut encoder les règles — et le format 2026 n'aide pas. Dans les 12 groupes, les deux premiers avancent automatiquement, tout comme les huit meilleurs troisièmes, et l'emplacement de ces huit-là dans le tableau des 32e dépend des groupes d'où ils proviennent.
Il y a 495 manières de choisir huit groupes qualifiés sur douze (douze parmi huit), et chacune produit une configuration différente des 32e. Il n'y a pas de formule élégante ; la FIFA publie simplement un tableau. J'ai donc (ou plutôt mon collègue Cursor) codé en dur les 495 combinaisons en m'appuyant sur le tableau officiel.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Chaque clé, comme EFGHIJKL, liste les groupes dont les troisièmes se sont qualifiés, et les valeurs positionnent chacune de ces équipes (3E, 3F, etc.) dans un numéro de match précis des 32e. Une entrée parmi 495.
Les trois pays hôtes (États-Unis, Canada et Mexique) nécessitent un traitement spécifique. Lorsqu'un hôte joue dans son pays, la simulation applique un avantage terrain pour ce match, le reste du tournoi étant traité comme terrain neutre.
Munie des prédictions et des règles, la simulation déroule 10 000 éditions du tournoi. À chaque itération :
Sur 10 000 tournois simulés, la part d'itérations où une équipe atteint la finale ou soulève le trophée devient sa probabilité. Une itération est une hypothèse ; dix mille donnent une prévision.
Chaque exécution, dans les deux modes, est journalisée dans MLflow (hébergé sur DagsHub). Le suivi d'expériences consiste à enregistrer systématiquement les entrées, paramètres, résultats et sorties, pour pouvoir comparer et reproduire à l'identique. Quelques éléments notables :
Les modèles entraînés et les fichiers de prédiction (probabilités du tournoi, classements de groupes, prévisions de matchs) sont stockés comme artefacts, et ce sont exactement ces fichiers que lit le tableau de bord en direct. La boucle est bouclée : des résultats bruts, jusqu'à la simulation, aux chiffres visibles en ligne.
Dernière brique, une fois les matchs terminés. À mesure que les résultats réels arrivent, les prédictions correspondantes sont scorées et comparées à la baseline à taux moyen. Si les modèles complets cèdent du terrain face à un modèle qui ignore tout des équipes, c'est un signal d'alarme : les motifs appris avant le tournoi ne collent peut-être plus à ce qui se passe sur le terrain.
C'est une pratique standard pour tout système de prédictions live. Pour en savoir plus : data drift et model drift.
Après toute cette machinerie, voici l'essentiel.
Au 10 juin 2026, veille du match d'ouverture, le verdict du modèle est net en tête, et serré juste derrière. L'Espagne et l'Argentine mènent, chacune avec environ 16 % de chances de soulever le trophée. Voir les champions du monde en titre (Argentine) et les champions d'Europe (Espagne) en tête est un bon test de réalité.
Derrière, un peloton très compact : France, Angleterre, Brésil et Colombie complètent les prétendants. Ces chiffres évoluent dès que les résultats tombent : considérez-les comme un instantané au 10 juin, pas une prophétie figée. Le tableau de bord affiche en permanence les valeurs actuelles, avec au plus deux heures de décalage.
Justement : tous les chiffres cités proviennent d'une application Streamlit qui s'actualise automatiquement au rythme du pipeline. Vous pouvez la consulter sur wc2026-predictions.streamlit.app pendant tout le tournoi. Quatre vues principales :
Un point à noter dans la vue matchs : certaines équipes apparaissent en deux emplacements possibles des 32e en même temps. Ce n'est pas un bug. Cela arrive quand un groupe est si équilibré que le modèle ne peut pas trancher le rang de qualification. Combiné à l'incertitude des meilleurs troisièmes, les deux issues mènent à des positions différentes dans le tableau. Dans le cas de la Turquie, cela les a même placés deux fois en huitièmes.
Le graphique suivant montre les dernières phases (quarts jusqu'à la finale) projetées par le modèle XGBoost avant le coup d'envoi :
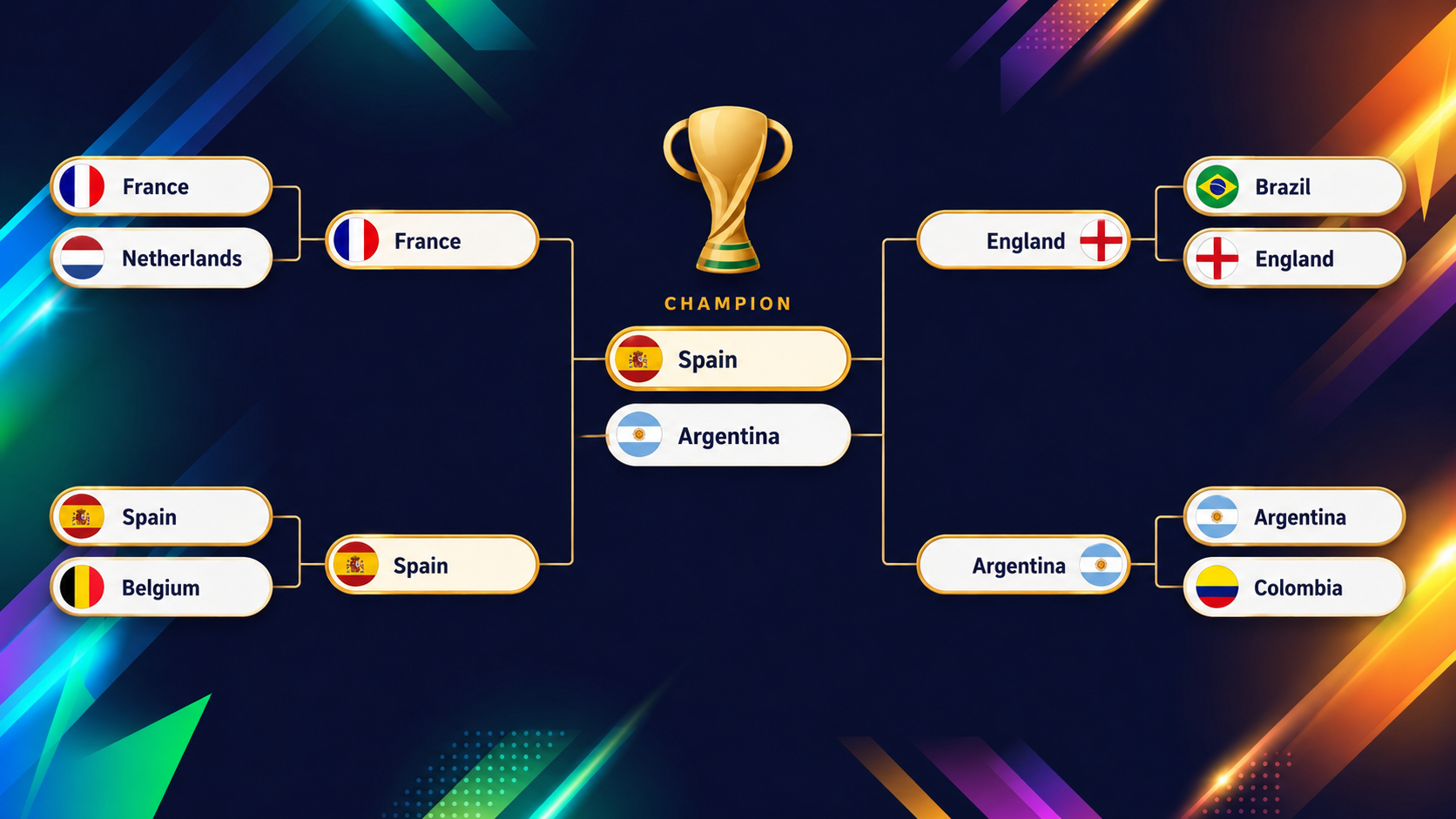
L'intérêt d'un tel modèle, ce sont les équipes qui contredisent l'intuition visuelle, et l'exemple le plus net est celui des États-Unis. Sur la vue d'ensemble, leur couleur saute aux yeux.
En tant que coorganisateurs, on pourrait attendre un départ serein, mais le modèle est plus prudent : il ne leur accorde qu'environ 54,6 % de chances de sortir des groupes, le 13e plus faible total du plateau (alors que deux équipes sur trois y parviennent), car leur groupe avec l'Australie, le Paraguay et la Turquie est particulièrement homogène.
L'intéressant, c'est la suite. Une fois sortis, les USA naviguent autour d'un pile ou face à chaque tour. Empilez ces lancers, et on arrive à ~2 % de chances de remporter le tournoi, 13e total le plus élevé sur 48 équipes.
Être 13e en partant du bas pour sortir des groupes et 13e en partant du haut pour tout gagner, c'est presque la définition parfaite d'une équipe « pile ou face » : jamais favorite, jamais condamnée.
Ce projet a demandé beaucoup de travail et couvre bien plus que ce qu'un article peut contenir. Le repo regorge d'éléments non abordés ici : l'ensemble des modèles candidats, l'ingénierie des variables, et l'orchestration qui fait tout tourner, pour n'en citer que quelques-uns.
Pour l'heure, le modèle a fait ses choix, et le terrain tranchera. Que vous soyez venu pour le MLOps ou pour le foot, j'espère que vous prendrez autant de plaisir que moi à suivre le déroulé. Vous pouvez consulter la prévision en direct au fil des matchs et voir comment tiennent les prédictions.
Si vous souhaitez creuser certaines notions évoquées, je vous recommande notre cours MLOps Concepts.
Les meilleurs cours de machine learning
Cours
Cours
Cours
blog
Lynn Heidmann
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Matt Crabtree
14 min
Tutoriel
Tutoriel
Matt Crabtree

