
Courses
Tìm hiểu Machine Learning
2 giờ
299.3K
Một dự đoán chỉ tốt tương xứng với dữ liệu đầu vào, nên đáng để bắt đầu từ nguyên liệu thô. Mô hình học từ hai nguồn dữ liệu trực tiếp và biến chúng thành một bảng đặc trưng gọn gàng, nhất quán.
Mọi thứ được xây dựng từ hai nơi. API-Football cung cấp lịch thi đấu và thống kê theo trận: ai gặp ai, khi nào, ở đâu, và kết quả ra sao. eloratings.net cung cấp điểm Elo cho mọi đội tuyển quốc gia.
Điểm Elo là một con số đơn lẻ phản ánh sức mạnh của một đội. Mỗi đội nằm đâu đó trên thang điểm, và sau mỗi trận, điểm số được cập nhật: thắng đội mạnh hơn, bạn được cộng nhiều; thua đội yếu hơn, bạn bị trừ mạnh. Ý tưởng đến từ cờ vua và thích nghi rất gọn với bóng đá. Nếu muốn直 quan đầy đủ, bài viết DataCamp trước này diễn giải trong bối cảnh World Cup 2022.
Kết hợp lại, hai nguồn tạo thành bộ dữ liệu Gold khoảng 6.900 trận quốc tế từ năm 2018 để học.
Đây là lựa chọn thiết kế quan trọng đầu tiên. Thay vì dự đoán trực tiếp kết quả thắng, hòa, thua, mô hình dự đoán chi tiết hơn: số bàn mỗi đội ghi trong một trận. Số bàn trong bóng đá, xấp xỉ tốt, tuân theo phân phối Poisson, cách chuẩn để mô hình hóa tần suất một sự kiện tương đối hiếm xảy ra trong một khoảng thời gian cố định.
Dự đoán số bàn thay vì kết quả là điều khiến mọi thứ về sau khả thi. Khi mô hình có thể tạo ra một tỉ số hợp lý cho bất kỳ cặp đấu nào, những câu hỏi mà mọi người thực sự quan tâm—ai vượt qua vòng bảng và ai nâng cúp—có thể được trả lời bằng cách mô phỏng các tỉ số đó hàng nghìn lần.
Mỗi trận được mô tả bởi một bộ đặc trưng nhỏ nhưng chọn lọc kỹ:
Mọi đặc trưng đều tuyệt đối an toàn với rò rỉ dữ liệu, nghĩa là chỉ dùng thông tin có trước giờ bóng lăn. Nghe có vẻ hiển nhiên, nhưng đây là một trong những cách dễ nhất để vô tình xây một mô hình trông xuất sắc khi thử nghiệm nhưng sụp đổ ngoài thực tế.
Một ý tưởng bị loại: tôi định xây bộ đặc trưng "phong cách chơi" bằng cách gom cụm đội dựa trên thống kê trong trận, một bước học không giám sát. Thực tế, các đội không tách thành nhóm có ý nghĩa, nên thay vì đưa nhiễu vào mô hình, tôi loại bỏ. Kết quả âm vẫn là kết quả.
Với dữ liệu đến từ hai nguồn theo cuộn thời gian, con đường từ tệp thô đến đặc trưng sẵn sàng cho mô hình phải giống hệt nhau mỗi lần. Đó là điều kiến trúc huân chương mang lại. Nó tổ chức dữ liệu thành ba lớp:
Mỗi lớp cấp dữ liệu cho lớp sau, nên khi có gì đó trục trặc, tôi có thể lần ngược từng bước thay vì gỡ cả mớ cùng lúc. Để toàn bộ đường đi có thể tái lập, tôi dùng DVC (Data Version Control). Mỗi khi có kết quả mới, một lệnh dvc repro sẽ dựng lại Silver và Gold từ Bronze, chỉ chạy lại bước có đầu vào thay đổi, và quản lý phiên bản các bộ dữ liệu kết quả để bất kỳ trạng thái trước đó đều có thể khôi phục y nguyên.
Dự đoán số bàn là một bài toán đã được nghiên cứu kỹ, và không có công cụ duy nhất rõ ràng. Vì vậy thay vì chốt một cách tiếp cận từ đầu, tôi xây mười mô hình và để chúng cạnh tranh.
Mười mô hình trải rộng trên năm họ cộng một đường cơ sở đơn giản. Bạn không cần biết nội tại từng mô hình; điểm mấu chốt là chúng đưa ra những giả định rất khác nhau về cách bàn thắng xuất hiện.
| Họ | Mô hình | Ý tưởng cốt lõi |
|---|---|---|
| Đường cơ sở | Poisson tốc độ trung bình | Giả định mỗi đội chỉ ghi một mức trung bình dài hạn, bỏ qua mọi đặc trưng. Nền tảng để các mô hình khác vượt qua. |
| Thống kê | Poisson song biến, Nhị thức âm | Mô hình hóa trực tiếp hai số bàn bằng các phân phối xác suất thiết kế cho đếm sự kiện. |
| Bayes | Poisson Bayes (MCMC) | Cùng ý tưởng đếm, nhưng trả về toàn bộ khoảng bất định quanh mỗi ước lượng. Nặng tính toán hơn nhiều: huấn luyện chậm hơn khoảng 100 lần so với phần còn lại. |
| Chuỗi thời gian | SARIMAX | Xem kết quả của một đội như dãy theo thời gian và ngoại suy dãy đó. |
| Machine learning | Ridge, Random Forest, XGBoost | Học mẫu trực tiếp từ đặc trưng mà không ràng buộc vào một phương trình cố định. |
| Deep learning | LSTM, CNN 1D | Mạng nơ-ron săn tìm các mẫu tuần tự và cục bộ trong dữ liệu. |
Với mười ứng viên, chọn bằng mắt là bất khả thi. Thay vào đó, mỗi mô hình đi qua ba giai đoạn, và mã quyết định có được đi tiếp hay không. Đây là triển khai dựa trên mã: mô hình được thăng cấp từ môi trường này sang môi trường khác bằng kiểm tra tự động thay vì chỉnh tay, giúp toàn bộ quy trình chọn lọc có thể tái lập và dễ kiểm toán.
Vậy cách tiếp cận nào dẫn đầu? Đây là bảng xếp hạng đầy đủ trên tập giữ lại, chấm bằng RPS (càng thấp càng tốt):
| Mô hình | RPS giữ lại |
|---|---|
| XGBoost | 0.18289 |
| Poisson Bayes | 0.18316 |
| Nhị thức âm | 0.18373 |
| Poisson song biến | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| CNN 1D | 0.20916 |
| Poisson tốc độ trung bình (đường cơ sở) | 0.22872 |
Bốn điều nổi bật từ kết quả này:
 Với giải đấu trực tiếp, tôi không chạy cả mười mô hình. Tôi giữ một danh sách rút gọn: baseline tốc độ trung bình làm mốc tham chiếu, cộng với ba mô hình hiệu năng tốt nhất. XGBoost và Poisson Bayes chiếm hai vị trí dẫn đầu tuyệt đối.
Với giải đấu trực tiếp, tôi không chạy cả mười mô hình. Tôi giữ một danh sách rút gọn: baseline tốc độ trung bình làm mốc tham chiếu, cộng với ba mô hình hiệu năng tốt nhất. XGBoost và Poisson Bayes chiếm hai vị trí dẫn đầu tuyệt đối.
Vị trí thứ ba coi như hòa: Nhị thức âm và Poisson song biến chỉ hơn kém nhau 0,0002 RPS và hoán đổi thứ hạng tùy hạt giống ngẫu nhiên, nên giữa hai mô hình không phân biệt được về thống kê, tôi chọn Poisson song biến, có công thức đặt nền tảng vững hơn trong văn liệu dự đoán bóng đá (Karlis và Ntzoufras, 2004).
Danh sách cuối cùng gồm XGBoost (machine learning), Poisson song biến (thống kê cổ điển), và Poisson Bayes (suy luận Bayes). Phần tiếp theo trình bày cách những mô hình này chạy, huấn luyện lại, và biến dự đoán từng trận thành dự báo cho cả giải.
Một mô hình sống trong notebook chỉ hữu ích khi bạn đang ngồi trước nó. Để dự đoán trong suốt giải kéo dài một tháng, mọi thứ phải tự chạy: lấy kết quả mới, huấn luyện lại, mô phỏng lại, và làm mới dự báo mà không ai phải chạm tay. Đó là nhiệm vụ của pipeline.
Toàn bộ dự án chạy như một job theo lịch trên Google Cloud Run. Trước giải, nó chạy mỗi ngày một lần; từ trận khai mạc 11/6, nó chạy mỗi hai giờ. Mỗi lần chạy theo chu trình giống nhau:
dvc repro dựng lại lớp Silver và Gold để đặc trưng được cập nhật.Vì mọi bước đều do mã kích hoạt theo lịch, không có thao tác thủ công nào trong suốt giải. Kết quả mới vào, dự báo cập nhật ra.
Đây là nơi dự án đồng thời là một thí nghiệm. Trong giải, danh sách mô hình chạy song song hai chế độ, và khác biệt giữa chúng là câu hỏi tôi muốn dữ liệu trả lời: Huấn luyện lại khi giải diễn ra có làm dự đoán tốt hơn không?
Chạy song song cho phép tôi so sánh sau khi giải kết thúc ở hai mặt: độ chính xác dự báo thuần, và tốc độ mà bất định của mỗi chế độ được thu hẹp khi số đội giảm. Nếu theo vòng thắng, việc huấn luyện lại thường xuyên là xứng đáng; nếu đóng băng vẫn trụ vững, máy móc bổ sung có thể không đáng công.
Dự đoán một trận là một chuyện. Biến điều đó thành "xác suất vô địch của mỗi đội" là lúc mô phỏng Monte Carlo phát huy tác dụng.
Đầu tiên là suy luận. Thay vì chỉ dự đoán các cặp đã biết, mô hình dự đoán mọi cặp đấu có thể có giữa 48 đội. Nghe có vẻ quá tay, nhưng trong một giải đấu, bất kỳ đội nào cũng có thể chạm bất kỳ đội nào ở knock-out, nên cần sẵn dự đoán cho mọi cặp.
Tiếp theo là mã hóa luật chơi, và thể thức 2026 khiến phần này đặc biệt rắc rối. Ở 12 bảng, hai đội đầu đi tiếp tự động, nhưng còn có tám đội thứ ba tốt nhất, và ô knock-out mỗi đội thứ ba được xếp vào phụ thuộc vào họ đến từ bảng nào.
Có 495 cách chọn tám bảng có đội thứ ba đi tiếp trong mười hai bảng (mười hai chọn tám), và mỗi cách tạo ra một bộ cặp đấu vòng 32 đội khác nhau. Không có công thức gọn; FIFA chỉ công bố một bảng. Vì vậy tôi (chính xác là đồng nghiệp rất cừ của tôi Cursor) đã hardcode cả 495 tổ hợp vào một bảng ánh xạ, dùng bảng chính thức làm nguồn.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Mỗi khóa, như EFGHIJKL, liệt kê tám bảng có đội thứ ba đi tiếp, và các giá trị đưa từng đội đó (3E, 3F, v.v.) vào một trận cụ thể ở vòng 32 đội. Đó là một mục; bảng đầy đủ lặp lại 495 lần, mỗi lần cho một tổ hợp.
Ba nước chủ nhà (Hoa Kỳ, Canada, Mexico) được xử lý thêm một bước. Khi chủ nhà đá trận tổ chức trên lãnh thổ mình, mô phỏng áp dụng điều chỉnh lợi thế sân nhà cho trận đó, còn phần còn lại của giải coi như sân trung lập.
Khi có dự đoán và luật chơi, mô phỏng chạy cả giải 10.000 lần. Mỗi lượt, nó làm như sau:
Qua 10.000 giải mô phỏng, tỷ lệ số lần một đội vào chung kết hay nâng cúp trở thành xác suất của đội đó. Một lượt mô phỏng là phỏng đoán; mười nghìn lượt là dự báo.
Mỗi lần chạy như mô tả ở trên, trong cả hai chế độ, đều được ghi vào MLflow (host trên DagsHub). Theo dõi thí nghiệm nghĩa là ghi có hệ thống đầu vào, thiết lập, kết quả, và đầu ra của từng lần chạy, để có thể so sánh hoặc tái lập y nguyên. Một vài điểm đáng lưu ý:
Các mô hình đã huấn luyện và chính tệp dự đoán (xác suất giải, xếp hạng bảng, và dự báo trận) được lưu dạng artifact của lần chạy, và đó chính là các tệp mà dashboard trực tiếp đọc. Vòng lặp khép kín: từ kết quả thô, qua huấn luyện và mô phỏng, đến các con số bạn thấy online.
Mảnh ghép cuối chạy khi các trận kết thúc. Khi có kết quả thực, các dự đoán tương ứng được chấm điểm và so sánh với baseline tốc độ trung bình đơn giản. Nếu các mô hình đầy đủ bắt đầu thua một mô hình chẳng biết gì về đội bóng, đó là tín hiệu cảnh báo trôi lệch: các mẫu học được trước giải có thể không còn khớp với những gì diễn ra trên sân.
Theo dõi điều này là thực hành chuẩn cho mọi hệ thống dự báo trực tiếp, và bạn có thể đọc thêm về cách phát hiện trong hướng dẫn về data drift và model drift.
Sau tất cả máy móc, đây là điều chúng ta muốn biết.
Tính đến ngày 10/6/2026, trước trận khai mạc một ngày, phán quyết của mô hình ở nhóm đầu khá rõ ràng và nhóm bám đuổi thì sít sao. Tây Ban Nha và Argentina dẫn đầu, mỗi đội khoảng 16% cơ hội nâng cúp. Việc đương kim vô địch thế giới (Argentina) và đương kim vô địch châu Âu (Tây Ban Nha) đứng trên cùng là một kiểm tra tỉnh táo đáng tin rằng mô hình bám sát thực tế.
Ngay sau họ là nhóm bám đuổi chặt chẽ: Pháp, Anh, Brazil, và Colombia hoàn thiện danh sách ứng viên vô địch dễ xảy ra nhất. Đây là các con số trực tiếp và sẽ thay đổi ngay khi có kết quả thực, nên hãy coi như ảnh chụp ngày 10/6 chứ không phải lời tiên tri cố định. Dashboard luôn hiển thị số liệu hiện tại, trễ tối đa hai giờ.
Nói đến đây: Mọi con số trong bài đều đến từ ứng dụng Streamlit trực tiếp được cập nhật tự động khi pipeline chạy. Bạn có thể mở wc2026-predictions.streamlit.app và theo dõi suốt giải. Ứng dụng có bốn chế độ xem chính:
Một điểm lạ đáng lưu ý ở chế độ xem trận: một vài đội xuất hiện đồng thời ở hai ô vòng 32 đội. Đó không phải lỗi. Nó xảy ra khi một bảng cân bằng đến mức mô hình không thể chắc chắn vị trí đi tiếp của một đội. Kết hợp bất định của đội thứ ba xuất sắc, hai kết cục dẫn đến hai ô knock-out khác nhau. Trường hợp Thổ Nhĩ Kỳ thậm chí dẫn đến việc họ xuất hiện hai lần ở vòng 16 đội.
Hình sau cho thấy các vòng cuối (tứ kết đến chung kết) mà mô hình XGBoost dự phóng trước khi giải khởi tranh:
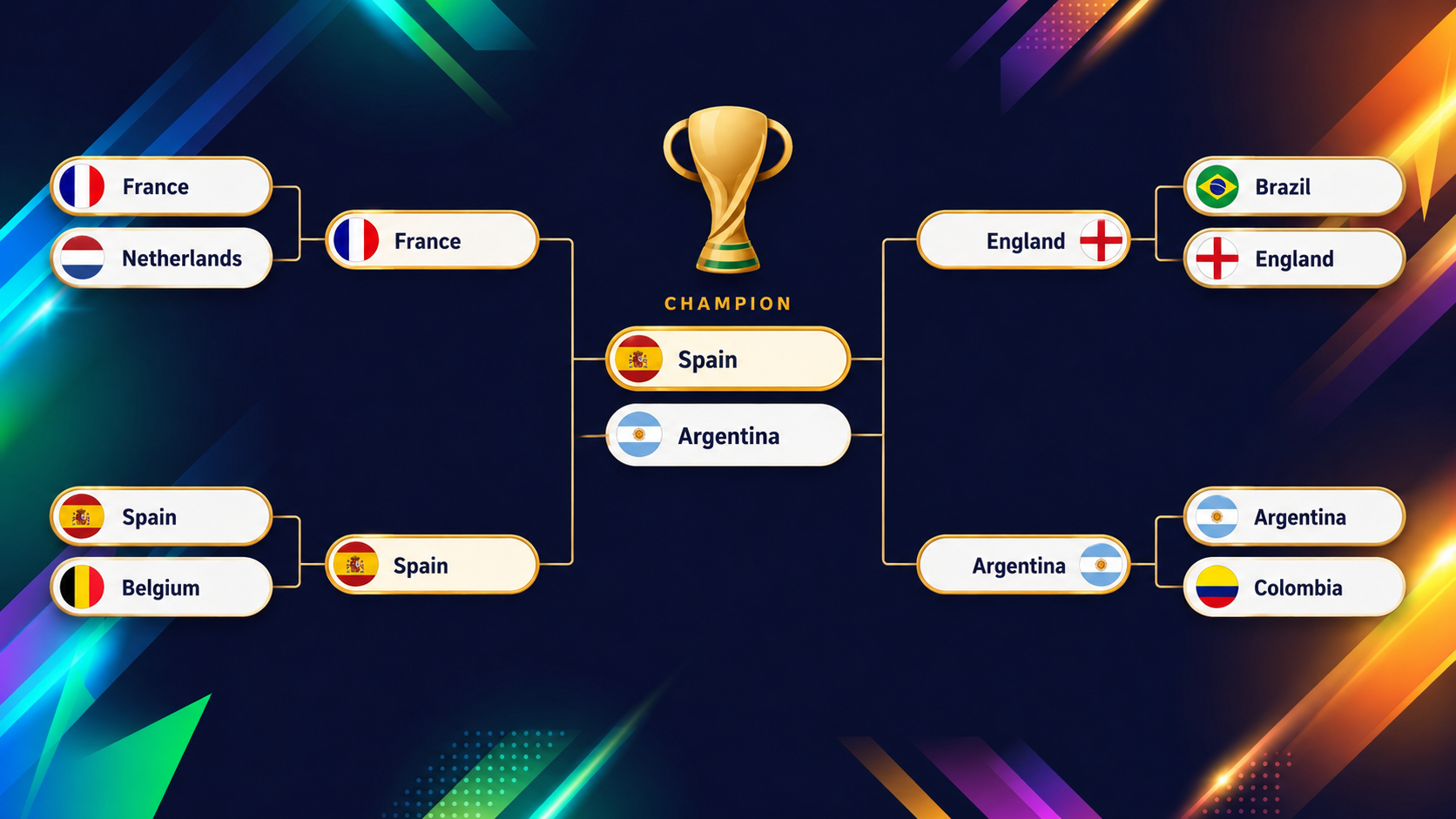
Điều thú vị của một mô hình như thế này nằm ở những đội trái với cảm nhận mắt thường, và ví dụ rõ nhất là Hoa Kỳ. Nếu bạn mở tổng quan giải trên dashboard, bạn sẽ lập tức thấy Mỹ nổi bật về màu sắc.
Với lợi thế đồng chủ nhà đá trước khán giả nhà, bạn có thể kỳ vọng khởi đầu dễ chịu, nhưng mô hình thận trọng hơn nhiều: chỉ khoảng 54,6% cơ hội vượt qua vòng bảng, thấp thứ 13 toàn giải (nhớ rằng hai phần ba số đội đi tiếp!), vì bảng của họ với Australia, Paraguay, và Thổ Nhĩ Kỳ cân bằng bất thường.
Phần thú vị là sau đó. Nếu vượt qua khe cửa hẹp, Mỹ sau đó gần như tung đồng xu ở mọi vòng tiếp theo. Chồng các “cú tung xu” đó lại, họ có khoảng 2% cơ hội vô địch cả giải, xếp thứ 13 trong 48 đội.
Một đội xếp hạng 13 từ dưới lên về khả năng qua vòng bảng và 13 từ trên xuống về khả năng vô địch chính là định nghĩa hoàn hảo của đội tung đồng xu: chẳng bao giờ là cửa trên, nhưng cũng chẳng bao giờ hết cửa.
Dự án này tốn rất nhiều công sức, và nó bao trùm nhiều nội dung hơn một bài viết có thể chứa. Repo có nhiều thứ không đưa vào đây: toàn bộ tập mô hình ứng viên, kỹ thuật đặc trưng, và phần điều phối giúp mọi thứ chạy trơn tru chỉ là vài ví dụ.
Hiện tại, mô hình đã đưa ra lựa chọn, và giải đấu sẽ là quan tòa. Dù bạn đến vì MLOps hay vì bóng đá, tôi hy vọng bạn sẽ tận hưởng quá trình diễn ra như tôi. Bạn có thể theo dõi dự báo trực tiếp khi các trận đổ về và xem dự đoán bền vững đến đâu.
Nếu muốn xem kỹ hơn một số khái niệm tôi nhắc tới, bạn có thể học khóa MLOps Concepts của chúng tôi.
Các khóa học Machine Learning hàng đầu
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút