tracks
AI 에이전트 기초
6
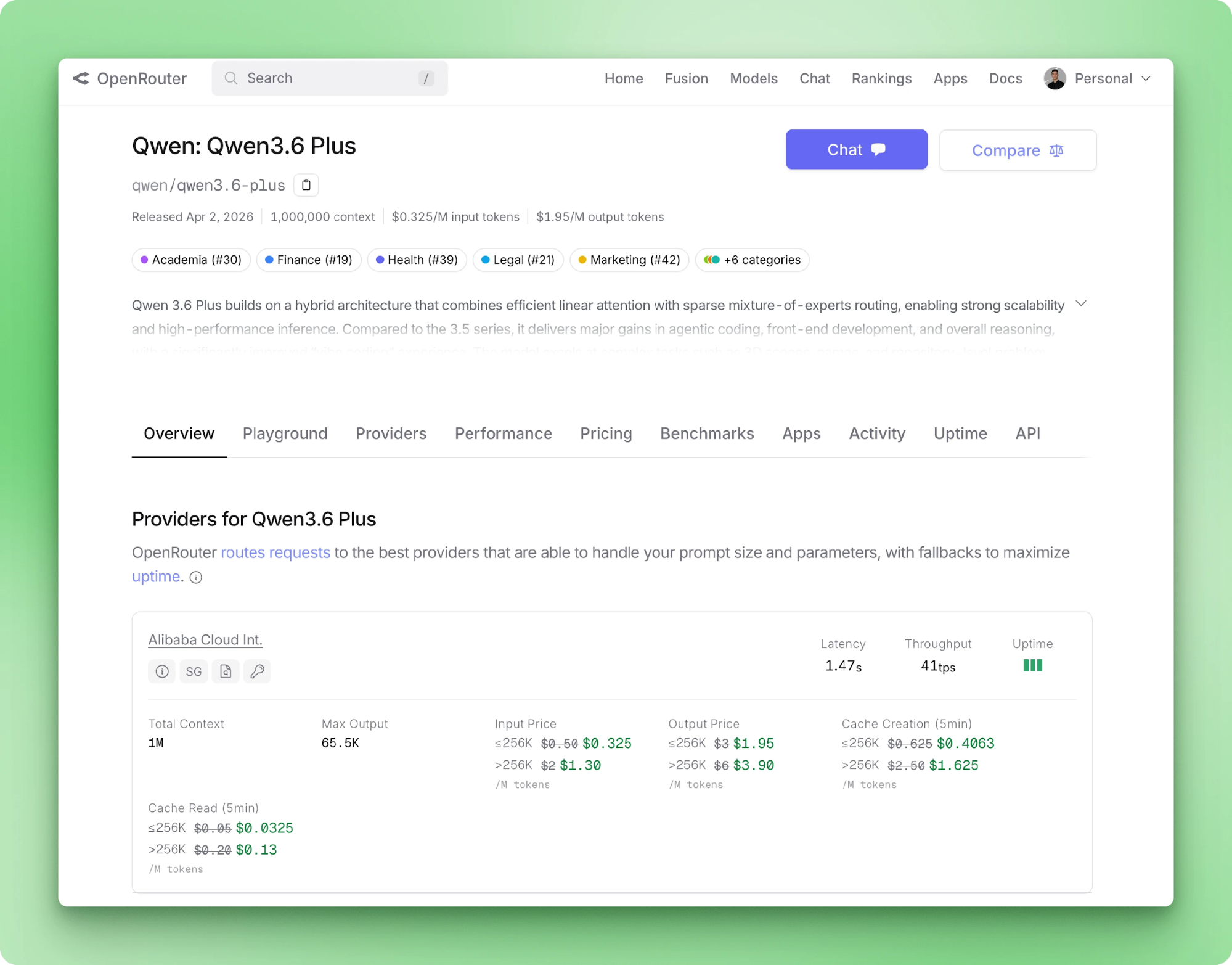
Alibaba는 2026년 4월 Qwen 3.6 Plus를 출시했습니다. 사양은 다음과 같습니다: SWE-bench Verified 78.8, 기본 1M 토큰 컨텍스트 윈도우, 네이티브 멀티모달 입력, 항상 활성화된 추론. Python 개발자에게 흥미로운 점은 벤치마크 표가 아닙니다. 이 모델이 API 전용이며 기본 URL만 바꾸면 일반 OpenAI 패키지로 동작한다는 사실입니다.
이 튜토리얼에서는 세 가지 주요 기능을 하나의 프로젝트에서 사용합니다: 사고 사슬(chain-of-thought) 추론, 구조화된 출력을 위한 도구 호출, 그리고 스캔된 인보이스에 대한 비전. 결과물은 PDF와 JPG를 읽고, 추론 과정을 보여주며, CSV로 기록할 수 있는 검증된 JSON을 반환하는 작은 인보이스 처리 파이프라인입니다.
Python 3.10 이상과 API 호출에 대한 기본적인 이해가 필요합니다. GPU도, 모델 다운로드도, 셀프 호스팅도 필요 없습니다. 우리는 OpenRouter를 통해 Qwen 3.6 Plus에 접근할 것이므로, 회원가입은 한 번이면 되고 OpenAI SDK는 변경 없이 동작합니다.
또한 최신 오픈 웨이트 버전인 Qwen 3.6 미세 조정 튜토리얼도 함께 보시길 강력히 권장합니다. 경쟁 모델에 관심이 있다면 DeepSeek v4, OpenAI의 GPT-5.5, Anthropic의 Claude Opus 4.7 가이드를 꼭 읽어보세요.
Qwen 3.6 Plus는 Alibaba의 2026년 4월 플래그십 모델입니다. 백본은 하이브리드 선형 어텐션 + 스파스 Mixture-of-Experts이며, 추론이 기본으로 실행되고, 텍스트·이미지·비디오가 모두 동일한 API를 통해 들어옵니다.
함수 호출은 OpenAI 도구 호출 프로토콜을 사용합니다. Alibaba는 이 릴리스를 “현실 세계의 에이전트를 향해”로 포지셔닝하며, 즉 한 번에 추론, 이미지 읽기, 함수 호출이 모두 필요한 난잡한 입력을 처리하는 단일 모델을 의미합니다.
Plus 티어는 폐쇄형 웨이트입니다. 체크포인트를 다운로드해 자체 하드웨어에서 실행할 수 없습니다(어차피 소비자 하드웨어에서 실행하기에는 모델이 너무 큽니다). Alibaba는 262K 기본 컨텍스트를 갖춘 오픈 소스 Qwen/Qwen3.6-35B-A3B 변형을 공개하지만, 이는 별개의 제품입니다. 이 튜토리얼에서는 호스팅된 API를 사용합니다.
Qwen 3.6 Plus는 최대 100만 입력 토큰과 호출당 최대 65,536 출력 토큰을 처리합니다. 입력 모달리티로 텍스트, 이미지, 비디오를 지원합니다. 도구 호출은 OpenAI 스키마를 통해 네이티브로 제공됩니다. OpenRouter의 모델 페이지에는 라우팅 백엔드의 가격, 제공자 지연 시간, 처리량이 나와 있습니다.
체인 오브 소트(사고 사슬)는 모든 호출에서 기본으로 실행되며, 추론 내용은 답변과 분리된 필드로 스트리밍됩니다. 새로운 3.6 Plus 파라미터는 이전 추론 흔적을 턴 간 메시지에 유지합니다.
Alibaba는 이후 턴이 이전 사고 사슬의 이점을 얻는 에이전트 루프에서 사용을 권장합니다. 우리처럼 원샷 추출에서는 흔적을 보존하면 토큰이 낭비되므로 비활성화합니다.
이 튜토리얼에서 중요한 벤치마크는 세 가지입니다:
앞의 두 가지는 스캔된 인보이스가 합리적인 타겟인 이유입니다. 세 번째는 무거운 프롬프트 엔지니어링 없이도 모델이 도구 호출 프로토콜을 따를 것으로 기대할 수 있는 이유입니다.
3.5 Plus에서 3.6 Plus로의 버전 점프는 대부분의 지표에서 작습니다. 코딩과 추론 벤치마크가 몇 점 상승했습니다. 더 큰 변화는 추론이 토글형 옵션에서 기본값으로 바뀌었다는 점입니다. OCR과 객체 위치 지정이 가장 크게 개선되었습니다.
|
기능 |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
추론 모드 |
기본 활성( |
항상 활성 CoT |
|
컨텍스트 윈도우 |
최대 1M 토큰 |
1M 토큰(기본) |
|
멀티모달 |
네이티브 비전-언어 |
네이티브 + 개선된 OCR, 객체 위치 지정 |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
턴 간 추론 |
— |
|
프로덕션에서 3.5 Plus를 사용해 왔다면, 업그레이드는 새로운 preserve_thinking 파라미터를 채택하고 이제 모든 호출에서 추론이 과금된다는 점을 인지하는 것을 의미합니다. 주요 이득은 에이전트 루프와 문서 비전에서 나타나며, 이 튜토리얼도 이를 활용합니다.
모델에 접근하는 방법은 두 가지입니다. 공식 경로는 Alibaba Cloud Model Studio로, 직접 엔드포인트 https://dashscope-intl.aliyuncs.com/compatible-mode/v1를 제공합니다. 다른 방법은 OpenRouter로, 단일 결제 레이어 뒤에서 Alibaba로 라우팅하며 가입 절차가 더 간단합니다.
튜토리얼에서는 키 생성이 더 빠르고 엔드포인트 특이점이 적기 때문에 OpenRouter를 사용합니다. 직접 경로를 원한다면 두 줄만 바꾸고 계속 진행하면 됩니다.
Alibaba Cloud Model Studio도 이 튜토리얼에서는 OpenRouter만큼 잘 동작합니다. 달라지는 것은 기본 URL과 환경 변수 이름뿐입니다.
Google 또는 GitHub 계정으로 openrouter.ai에 가입하세요. 무료 티어는 신용카드 없이 사용할 수 있으며, 이 튜토리얼을 처음부터 끝까지 따라오는 데 충분합니다. 나중에 더 큰 볼륨을 실행할 계획이라면 크레딧을 추가해 더 높은 처리량 티어를 얻고 모델별 속도 제한을 해제할 수 있습니다.
로그인한 후 openrouter.ai/settings/keys로 이동해 키를 생성하세요. 나중에 회수할 수 있도록 qwen-tutorial 같이 라벨링합니다.
OpenRouter는 키 값을 한 번만 보여주므로 지금 복사하세요. 그런 다음 프로젝트 루트의 .env 파일에 저장합니다:
OPENROUTER_API_KEY=sk-or-v1-...다음 섹션에서 python-dotenv로 로드하겠습니다. Alibaba Cloud를 직접 사용하려면 키는 modelstudio.console.alibabacloud.com에서 발급받고 다음 변수 DASHSCOPE_API_KEY에 넣으면 됩니다.
첫 확인 호출에 필요한 두 패키지를 설치하세요:
pip install openai python-dotenvopenai 패키지는 OpenAI 엔드포인트에서 사용하던 것과 같은 SDK입니다. OpenRouter와 Alibaba Cloud Model Studio는 모두 OpenAI Chat Completions API를 구현하므로, 클라이언트 코드를 바꿀 필요가 없습니다.
hello.py 파일을 만들고 연결을 확인하세요:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)python hello.py를 실행하면 짧은 답변이 출력되어야 합니다. 무료 티어에서 첫 토큰 지연은 몇 초 걸릴 수 있는데, 이는 모델이 보이는 답변을 생성하기 전에 추론 흔적을 구축하기 때문입니다.
샘플 프로젝트는 인보이스 처리 파이프라인입니다. 텍스트 PDF와 스캔된 JPG 두 가지 형식을 받습니다. 각 인보이스는 추론을 켠 상태로 Qwen 3.6 Plus를 거치며, 추출된 필드는 도구 호출로 반환됩니다. 모든 인보이스는 네 단계를 거칩니다:
입력 디코드(이미지는 base64 인코딩, PDF는 각 페이지를 먼저 이미지로 변환)
모델에서 추론 흔적을 스트리밍으로 수신
도구 호출을 구조화된 JSON으로 파싱
results.csv에 행 기록
이 섹션의 모든 코드는 bextuychiev/qwen-invoice-pipeline-tutorial에 있습니다. 클론해서 따라 하거나, 직접 구현할 때 참고로 사용하세요.
invoice-pipeline/ 디렉토리를 만들고 다음과 같이 구성하세요:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtclient.py와 프로세서 간 분리는 OpenRouter 설정을 한 파일에 모읍니다. 이후 Alibaba Cloud로 바꾸더라도 client.py만 수정하면 됩니다.
client.py는 OpenAI 클라이언트를 올바른 기본 URL과 모델 ID로 래핑합니다:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example는 저장소를 클론하는 이가 무엇을 채워야 하는지 알 수 있도록 함께 둡니다:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1동반 저장소에는 세 가지 출처에서 가져온 샘플 인보이스 여섯 개가 포함되어 있습니다:
실제 회사 인보이스는 PII 때문에 공개 재배포가 불가하므로 이들을 사용합니다. 파이프라인을 대조해보고 싶다면 저장소 README에 기준 합계가 기재되어 있습니다.
Qwen 3.5를 사용해 보셨다면, CoT는 호출 단위 토글이었습니다: enable_thinking=True 를 extra_body 안에서 설정. 3.6 Plus에서는 추론이 기본으로 실행되며, 파라미터는 주로 끄기 위해 존재합니다. 추론이 활성화되면 추론 토큰은 항상 과금되며, “항상 켜짐”은 무료 기능이 아니라 비용 의사결정이 됩니다.
응답을 스트리밍할 때 delta.reasoning_content가 먼저 도착하고, 그다음에 delta.content(또는 우리의 경우 delta.tool_calls)가 이어집니다.
인보이스를 추출하고 스트리밍되는 추론 흔적을 출력하는 최소 호출은 다음과 같습니다:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)디스크에서 JPG 바이트를 읽어 base64로 인코딩하고, 결과를 data: URI로 감쌉니다. 이 형식은 OpenAI 콘텐츠 블록 프로토콜이 호스트된 URL 없이 인라인 이미지를 허용하게 해줍니다. image_url 블록은 URI를 직접 받고, 모델은 링크를 전달한 것처럼 인보이스를 인식합니다.
extra_body={"enable_thinking": True}는 enable_thinking 플래그를 Qwen으로 전달합니다. OpenAI SDK는 이 파라미터를 알지 못하므로 extra_body가 제공자별 옵션을 전달하는 방식입니다.
invoice_04.jpg에 대해 실행하면 스트리밍된 답변은 짧은 요약으로 돌아옵니다:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51짧게 나온 이유는 우리가 그렇게 요청했기 때문입니다. 시스템 프롬프트에는 “요약”만 있었죠. 작업이 커지면(라인 아이템, 카테고리, 구조화된 필드) 추론 흔적도 함께 커집니다. 다음 섹션에서는 같은 모델이 같은 이미지에서 답변하기 전 출력 예산 대부분을 생각하는 데 쓰는 모습을 보게 됩니다.
/no_think를 사용자 프롬프트에 덧붙이면 해당 호출에서 CoT를 비활성화하는 소프트 스위치가 됩니다. 디버깅 중 더 빠른 비추론 응답이 필요할 때 유용합니다.
추론은 추출 과정을 읽기 쉽게 해 주지만, 출력은 여전히 추론 흔적 안의 자유 형식 텍스트입니다. 매번 구조화되어 파싱 가능한 JSON을 받으려면 하나의 도구 extract_invoice를 정의하고, 시스템 프롬프트로 항상 도구를 호출하도록 지시하면서 tool_choice="auto"를 설정합니다.
tools.py의 스키마는 여섯 개 필드를 설명합니다. 외부 형태는 표준 OpenAI 함수-도구 형식을 따릅니다:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}여섯 개 필드는 parameters.properties 내부에 위치합니다. 스칼라 필드(vendor, date, total, tax)는 일반 JSON 스키마 타입을 사용합니다. category는 enum을 사용하여 모델이 라벨을 만들어내지 않고 네 가지 고정 값 중에서 선택하게 합니다. line_items는 유일한 구조화된 필드로, 객체 배열이며 각 객체는 자체 required 목록을 갖습니다:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},스키마에는 두 수준의 required가 있습니다. 바깥 목록은 모든 추출에서 반드시 나타나야 하는 최상위 필드를 표시합니다. 항목별 목록은 각 라인 아이템마다 반드시 있어야 하는 하위 필드를 표시합니다. 전체 스키마는 동반 저장소의 tools.py에 있습니다.
인자는 tool_calls[0].function.arguments 내부의 JSON 형식 문자열로 반환되며, 파싱된 객체가 아니므로 직접 json.loads를 호출해야 합니다. 스트리밍 시에는 인자가 델타 시퀀스로 도착하므로 파싱 전에 이어붙입니다.
유의할 점: OpenRouter의 Qwen 3.6 Plus 엔드포인트는 강제 도구 호출을 지원하지 않습니다. tool_choice={"type": "function", "function": {"name": "extract_invoice"}}를 시도하면 요청이 다음 오류로 반환됩니다:
No endpoints found that support the provided 'tool_choice' value실용적인 해결책은 tool_choice="auto"를 사용하고 시스템 프롬프트에 의존하는 것입니다:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""동반 저장소의 여섯 개 샘플 인보이스 전체에서 이 프롬프트는 매번 도구 호출을 유도했습니다. 프로덕션 코드는 예외 케이스에 대비해야 합니다. finish_reason을 확인하고, tool_calls가 채워졌는지 검증하며, 그렇지 않다면 더 명확한 지시로 재시도하세요. Qwen의 함수 호출 문서도 같은 점을 언급합니다. 도구 호출 생성은 보장되지 않으며, 프로덕션 코드는 폴백이 필요합니다.
부수 효과 하나: 프롬프트가 구조화된 필드를 요구하면 delta.reasoning_content가 긴 흔적으로 채워집니다. 모델은 표를 행 단위로 파싱하고, invoice_04.jpg의 유럽식 소수점 표기를 검토하며, 라인 아이템 금액을 합계와 대조합니다. 이 종류의 프롬프트에서는 추론 토큰이 답변 토큰보다 10배 이상 많을 수 있습니다.
이는 구조화된 추출에서 항상 켜진 CoT의 비용이며, preserve_thinking이 다중 턴 에이전트 루프에서 나중 턴이 흔적을 읽을 때만 효과적인 이유입니다. 우리는 원샷 추출을 하므로 흔적은 터미널로 스트리밍되고 폐기됩니다.
JPG의 경우 흐름은 세 단계입니다:
디스크에서 이미지 바이트 읽기
base64로 인코딩
data: URI와 함께 image_url 콘텐츠 블록에 넣기
PDF는 Qwen의 비전 경로가 PDF 파일을 직접이 아니라 이미지로 받기 때문에 하나의 추가 단계가 필요합니다. 각 페이지를 pdf2image로 PIL 이미지로 변환한 다음, 동일한 메시지 안에서 페이지들을 이미지 콘텐츠 블록 목록으로 전송하세요.
두 경로는 동일한 모델 호출을 공유하므로 호출은 processors/image.py에 있고 processors/pdf.py가 이를 위임합니다. 먼저 임포트부터 시작합니다(위의 SYSTEM_PROMPT는 같은 모듈에 있습니다):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined above인코더는 JPG 경로를 API가 기대하는 data: URI로 변환합니다:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"공유 헬퍼 _call_with_images는 사용자 콘텐츠 배열(텍스트 + 하나 이상의 이미지)을 구성하고 스트리밍 요청을 보냅니다. 스트림에서 두 가지 데이터를 수집합니다: 추론 흔적과 도구 호출 인자. 먼저 요청 설정입니다:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)그 다음 스트림 루프는 추론 델타와 도구 호출 인자 델타를 분리합니다:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}JPG용 공개 엔트리 포인트는 이 헬퍼들을 사용하는 한 줄짜리입니다:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)PDF 프로세서는 _call_with_images를 재사용하며 페이지-이미지 변환만 추가합니다:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image는 poppler 설치가 필요합니다. 다음으로 설치하세요:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utils다중 페이지 PDF의 경우, 각 페이지를 동일한 메시지 내의 개별 이미지 블록으로 보내세요. Qwen은 이를 함께 읽고 하나의 추출 결과를 생성하며, 이는 합계가 2페이지에 있는 인보이스에서 원하는 동작입니다.
150 DPI는 인보이스 텍스트를 가독성 있게 유지하면서 페이로드를 불필요하게 키우지 않습니다. 이 샘플들에 대한 테스트에서 더 높여도 정확도는 개선되지 않고 요청만 커졌습니다. Alibaba의 비전 문서에 지원 형식과 상한이 나와 있습니다.
main.py는 sample_invoices/를 순회하면서 각 파일을 확장자로 라우팅하고, 올바른 프로세서를 호출해 결합 결과를 CSV로 기록합니다. 먼저 임포트와 상수입니다:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}메인 루프는 샘플 디렉토리를 정렬된 순서로 순회하고, 파일 확장자로 라우팅하며, 각 추출을 CSV 친화적인 행으로 평탄화합니다:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})마지막으로, 행을 디스크에 기록하고 개수를 로그합니다:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()python main.py를 실행하면 여섯 개 샘플이 순서대로 처리됩니다. 각 인보이스는 파일명을 스트리밍한 뒤, 추론 흔적, 추출된 JSON을 순서대로 보여주고 다음 항목으로 넘어갑니다:
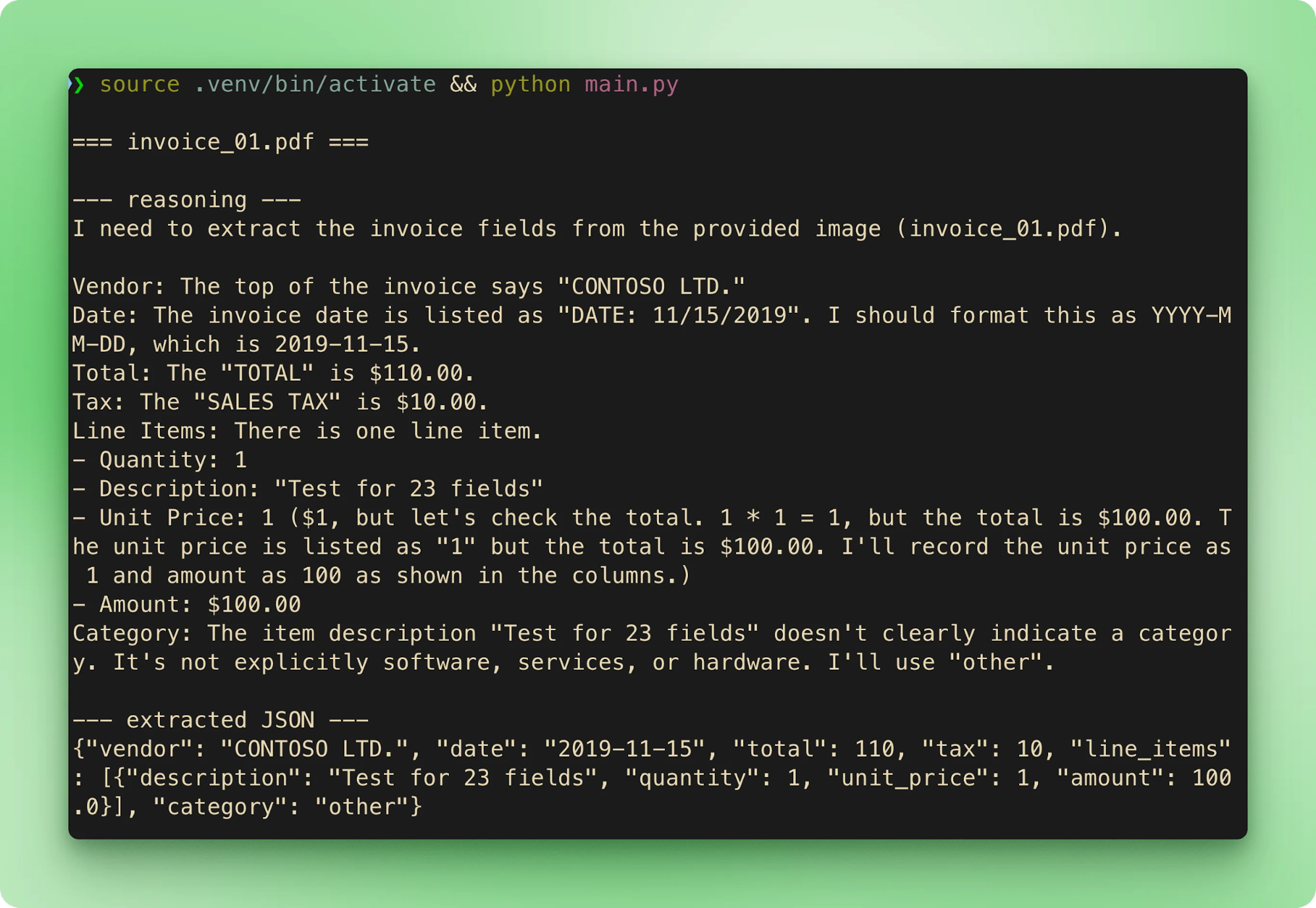
results.csv는 각 추출을 인보이스당 한 행으로 집계합니다:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
합계는 여섯 개 모두 기준값과 일치합니다. 무료 티어의 지연 시간은 인보이스당 15~40초입니다. 대부분의 시간은 도구 호출이 스트리밍되기 전에 진행되는 추론 단계입니다.
몇 가지 패턴은 한 번만 동작하는 파이프라인과 실제 인보이스에서도 계속 동작하는 파이프라인을 가릅니다.
시크릿을 코드 밖에 보관하세요. 우리가 내내 사용한 .env와 python-dotenv 패턴은 기본입니다. 첫 커밋 전에 .gitignore에 .env를 추가해 키가 저장소에 올라가지 않게 하세요.
지수 백오프로 레이트 리밋을 처리하세요. OpenRouter는 HTTP 429 응답으로 제공자별 제한을 적용합니다. tenacity 라이브러리는 데코레이터 기반 구현을 제공하며, OpenAI 쿡북 패턴의 wait_random_exponential은 변경 없이 동작합니다.
응답이 길어질 때는 스트리밍을 사용하세요. 항상 켜진 CoT는 기본적으로 응답 길이를 늘립니다. 비스트리밍 호출은 전체 추론 블록을 기다려야만 합니다. 스트리밍은 초기 피드백을 제공하고, UI를 반응성 있게 유지하며, 명백히 잘못 가는 요청을 중단할 수 있게 해줍니다.
이전 추론을 이후 턴에서 읽을 때만 preserve_thinking을 사용하세요. 이 파이프라인처럼 원샷 추출기에는 토큰 낭비입니다. 다중 턴 에이전트 루프(도구 호출 체인, 계획 작업, 디버깅 워크플로)에서는 턴 간 컨텍스트를 위해 존재합니다. Alibaba의 딥 싱킹 문서에는 호출당 추론 토큰 상한인 thinking_budget도 나와 있습니다.
무료 티어 응답은 학습을 위해 로그될 수 있습니다. OpenRouter의 무료 티어는 프롬프트를 보관할 수 있는 제공자를 경유합니다. 실제 PII, 고객 이름, 결제 정보가 포함된 인보이스에는 부적합합니다. 실제 데이터를 파이프라인에 태우기 전 유료 OpenRouter 티어(또는 유료 계정으로 Alibaba Cloud 직접 경로)로 전환하세요.
Plus 티어는 셀프 호스팅이 불가합니다. 에어갭 또는 온프렘 배포가 필요한 경우 호스팅 API를 사용할 수 없습니다. 오픈 소스 Qwen3.6-35B-A3B 변형은 이러한 경우 고려할 만한 별도 옵션입니다.
추론이 시작될 때 첫 토큰까지 시간이 길 수 있습니다. 타임아웃은 넉넉히 설정하세요. 이미지 입력의 경우 30~60초가 합리적입니다. 재시도 로직이 429와는 별도로 읽기 타임아웃을 처리하도록 하세요.
항상 켜진 CoT에서도 출력은 결정적이지 않습니다. 동반 저장소 샘플 테스트에서 invoice_01.pdf는 대부분 $610.00으로 추출되지만, 동일 입력 재실행에서 $110.00으로 바뀐 경우도 있었습니다. 두 번 모두 추론 흔적은 올바른 답에 도달했지만, 최종 도구 호출 인자는 달랐습니다. 두 가지 완화책: temperature를 낮게 설정(순수 추출에는 0.1~0.2)하고, 기준값 검증 또는 정확도가 중요한 경우 두 번째 패스를 사용하세요.
여기서부터 파이프라인을 에이전트 프레임워크로 감싸는 일은 작은 단계입니다. 도구 호출 루프, 스트리밍 파서, CSV 라이터는 에이전트 프레임워크가 다중 턴 전반에서 오케스트레이션하는 동일한 기본 요소입니다. DataCamp의 Developing LLM Applications with LangChain 코스는 메모리, 상태, 멀티 툴 라우팅과 함께 이러한 패턴을 다룹니다.
에이전틱 AI 강좌
tracks
tracks
courses