Tracks
พื้นฐานของ AI Agent
6 ชม.
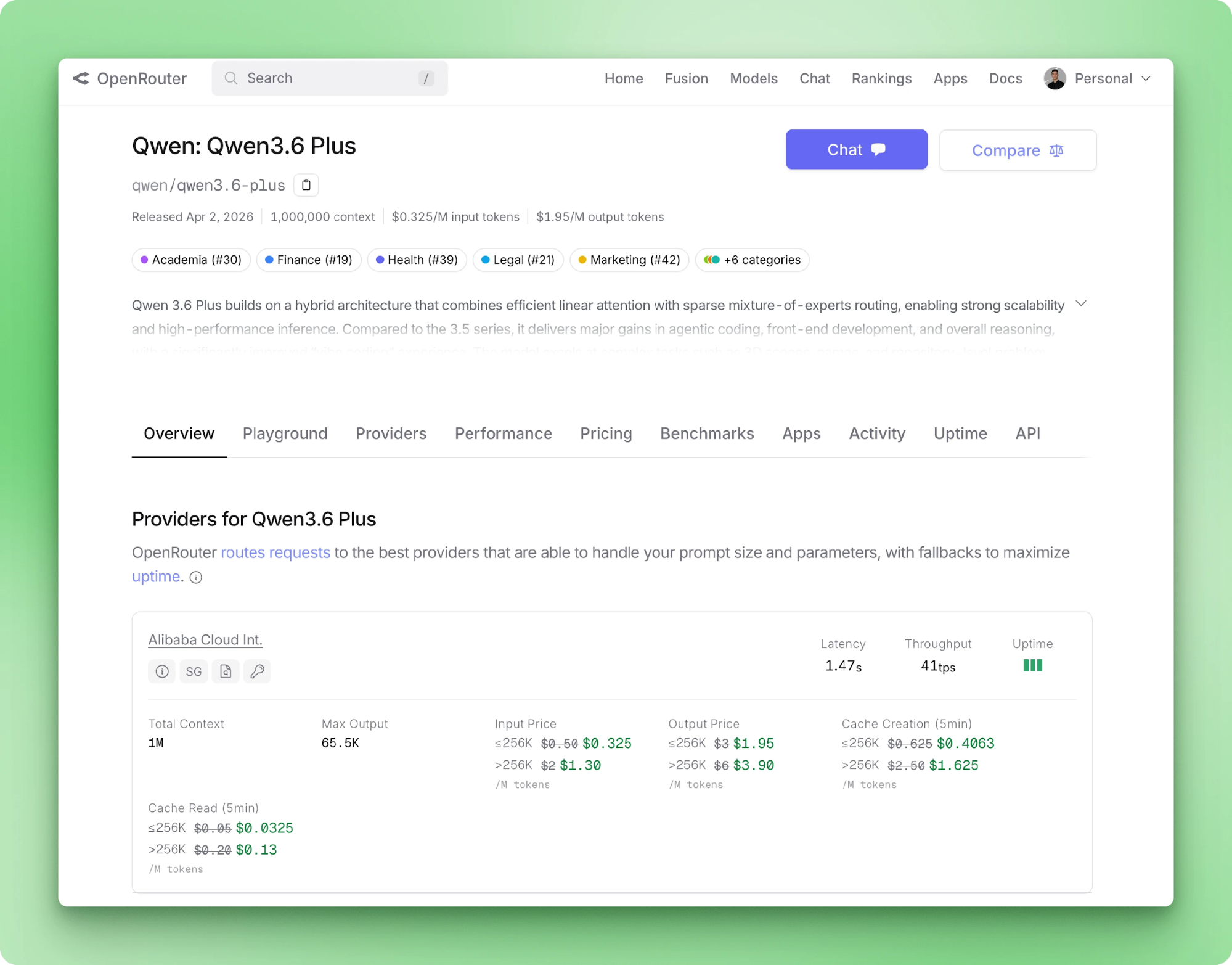
Alibaba เปิดตัว Qwen 3.6 Plus ในเดือนเมษายน 2026 สเปกโดยย่อ: SWE-bench Verified ที่ 78.8 หน้าต่างบริบท 1M โทเค็นเป็นค่าเริ่มต้น อินพุตมัลติโหมดแบบเนทีฟ และมีโหมด reasoning ตลอดเวลา สำหรับนักพัฒนา Python ประเด็นที่น่าสนใจไม่ใช่ตารางเบนช์มาร์ก แต่คือโมเดลนี้ให้บริการผ่าน API เท่านั้น และใช้งานร่วมกับแพ็กเกจ OpenAI มาตรฐานได้ เพียงสลับ base URL
ในบทเรียนนี้ เราจะใช้ 3 ความสามารถหลักของรุ่นนี้ในโปรเจกต์เดียว: chain-of-thought reasoning, การเรียกใช้เครื่องมือเพื่อสร้างเอาต์พุตแบบมีโครงสร้าง และวิชันสำหรับใบแจ้งหนี้ที่สแกน ผลลัพธ์คือไปป์ไลน์ประมวลผลใบแจ้งหนี้ขนาดเล็กที่อ่านไฟล์ PDF และ JPG แสดงกระบวนการคิด และคืนค่า JSON ที่ตรวจสอบแล้วสำหรับบันทึกเป็น CSV
ต้องใช้ Python 3.10 ขึ้นไป และคุ้นเคยกับการเรียก API ไม่ต้องใช้ GPU ไม่ต้องดาวน์โหลดโมเดล ไม่ต้องโฮสต์เอง เราจะเข้าถึง Qwen 3.6 Plus ผ่าน OpenRouter จึงสมัครใช้งานได้ด้วยฟอร์มเดียว และ OpenAI SDK ใช้งานได้เหมือนเดิม
ขอแนะนำให้ดูบทเรียนเรื่อง การปรับจูน Qwen 3.6 ซึ่งเป็นเวอร์ชัน open-weights ล่าสุดของ Qwen หากสนใจโมเดลคู่แข่ง ลองอ่านคู่มือของเราเกี่ยวกับ DeepSeek v4, GPT-5.5 ของ OpenAI และ Claude Opus 4.7 ของ Anthropic
Qwen 3.6 Plus เป็นโมเดลเรือธงของ Alibaba ประจำเมษายน 2026 แกนกลางเป็นสถาปัตยกรรมผสมระหว่าง linear-attention และ sparse mixture-of-experts เปิดโหมด reasoning เป็นค่าเริ่มต้น และรองรับข้อความ รูปภาพ และวิดีโอผ่าน API เดียวกัน
การเรียกใช้ฟังก์ชันทำตามโปรโตคอล tool-call ของ OpenAI Alibaba วางตำแหน่งรุ่นนี้ว่า “สู่เอเจนต์โลกจริง” หมายถึงโมเดลเดียวที่รับมืออินพุตหลากหลาย ต้องใช้เหตุผล อ่านภาพ และเรียกฟังก์ชันในขั้นตอนเดียว
ระดับ Plus เป็นโมเดลปิด ไม่สามารถดาวน์โหลดเช็กพอยต์มารันบนฮาร์ดแวร์ของตนเองได้ (ตัวโมเดลใหญ่เกินสำหรับฮาร์ดแวร์ผู้ใช้ทั่วไปอยู่แล้ว) Alibaba เผยแพร่รุ่นโอเพ่นซอร์ส Qwen/Qwen3.6-35B-A3B ที่มีบริบทเริ่มต้น 262K แต่เป็นผลิตภัณฑ์คนละตัว สำหรับบทเรียนนี้ เราใช้ API แบบโฮสต์
Qwen 3.6 Plus รับอินพุตได้สูงสุด 1M โทเค็น และคืนเอาต์พุตได้สูงสุด 65,536 โทเค็นต่อคำขอ อินพุตรองรับข้อความ รูปภาพ และวิดีโอ การเรียกใช้เครื่องมือเป็นแบบเนทีฟผ่านสคีมาของ OpenAI หน้า โมเดลของ OpenRouter แสดงราคา เวลาแฝง และปริมาณงานของแบ็กเอนด์ที่มีการเราต์
Chain-of-thought ทำงานเป็นค่าเริ่มต้นทุกคำขอ และสตรีมเนื้อหา reasoning แยกฟิลด์ออกจากคำตอบ มีพารามิเตอร์ใหม่ใน 3.6 Plus ที่ผูกลิงก์ร่องรอย reasoning ก่อนหน้าไว้กับข้อความข้ามรอบการสนทนา
Alibaba แนะนำสำหรับลูปเอเจนต์ที่รอบถัดไปได้ประโยชน์จากห่วงโซ่ความคิดในรอบก่อน สำหรับงานดึงข้อมูลครั้งเดียวอย่างของเรา การเก็บร่องรอยไว้เปลืองโทเค็น จึงปิดไว้
เบนช์มาร์ก 3 ตัวที่สำคัญสำหรับบทเรียนนี้:
สองข้อแรกคือเหตุผลที่ใบแจ้งหนี้สแกนเป็นเป้าหมายที่เหมาะสม ข้อที่สามคือเหตุผลที่คาดได้ว่าโมเดลจะทำตามโปรโตคอลการเรียกใช้เครื่องมือโดยไม่ต้องปรับพรอมป์ตมาก
การขยับเวอร์ชันจาก 3.5 Plus เป็น 3.6 Plus เพิ่มคะแนนในหลายเบนช์มาร์กเล็กน้อย การเขียนโค้ดและ reasoning ดีขึ้นไม่กี่คะแนน การเปลี่ยนที่ใหญ่กว่าคือ reasoning จากเดิมที่เป็นตัวเลือกกลายเป็นค่าเริ่มต้น OCR และการระบุตำแหน่งวัตถุ ดีขึ้นมากที่สุด
|
ความสามารถ |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
โหมด Reasoning |
เปิดเป็นค่าเริ่มต้น (ปิดได้ด้วย |
CoT เปิดตลอดเวลา |
|
หน้าต่างบริบท |
สูงสุด 1M โทเค็น |
1M โทเค็น (ค่าเริ่มต้น) |
|
มัลติโหมด |
วิชัน-ภาษาแบบเนทีฟ |
เนทีฟ + OCR และการระบุตำแหน่งวัตถุที่ดีขึ้น |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
Reasoning ข้ามรอบ |
— |
|
หากกำลังรัน 3.5 Plus ในโปรดักชัน การอัปเกรดหมายถึงการนำพารามิเตอร์ preserve_thinking มาใช้ และรับทราบว่าโทเค็น reasoning จะถูกคิดค่าบริการทุกคำขอ จุดเด่นหลักอยู่ที่ลูปเอเจนต์และวิชันเอกสาร ซึ่งเป็นสิ่งที่บทเรียนนี้ใช้
เข้าถึงโมเดลได้สองทาง ทางการคือ Alibaba Cloud Model Studio ซึ่งจะให้ปลายทางโดยตรงที่ https://dashscope-intl.aliyuncs.com/compatible-mode/v1 อีกทางคือ OpenRouter ที่เราต์ไป Alibaba ผ่านเลเยอร์การเรียกเก็บเงินรวมและขั้นตอนสมัครที่ง่ายกว่า
บทเรียนนี้เลือกใช้ OpenRouter เพราะสร้างคีย์ได้เร็วและมีข้อยกเว้นปลายทางน้อยกว่า หากต้องการทางตรง เปลี่ยนสองบรรทัดแล้วทำต่อได้เลย
Alibaba Cloud Model Studio ใช้งานได้พอๆ กับ OpenRouter สำหรับบทเรียนนี้ สิ่งที่เปลี่ยนมีเพียง base URL และชื่อ environment variable
สมัครที่ openrouter.ai ด้วยบัญชี Google หรือ GitHub ชั้นฟรีใช้ได้โดยไม่ต้องผูกบัตร ซึ่งเพียงพอสำหรับทำบทเรียนนี้จนจบ หากภายหลังจะรันปริมาณงานมากขึ้น เติมเครดิตเพื่อได้ระดับ throughput สูงขึ้นและยกเพดานอัตราต่อโมเดล
เมื่อล็อกอินแล้ว ไปที่ openrouter.ai/settings/keys และสร้างคีย์ ตั้งชื่อเช่น qwen-tutorial เพื่อจะได้เพิกถอนภายหลังได้ง่าย
คัดลอกค่า key ตอนนี้ เพราะ OpenRouter จะแสดงเพียงครั้งเดียว จากนั้นบันทึกไว้ในไฟล์ .env ที่ root ของโปรเจกต์:
OPENROUTER_API_KEY=sk-or-v1-...เราจะโหลดด้วย python-dotenv ในส่วนถัดไป หากต้องการใช้ Alibaba Cloud โดยตรง ให้รับคีย์จาก modelstudio.console.alibabacloud.com แล้วใส่ไปที่ DASHSCOPE_API_KEY แทน
ติดตั้งแพ็กเกจสองตัวที่ต้องใช้สำหรับการทดสอบครั้งแรก:
pip install openai python-dotenvแพ็กเกจ openai คือ SDK เดียวกับที่ใช้กับปลายทางของ OpenAI ทั้ง OpenRouter และ Alibaba Cloud Model Studio รองรับ OpenAI Chat Completions API ดังนั้นโค้ดฝั่งไคลเอนต์จึงไม่ต้องเปลี่ยน
สร้างไฟล์ชื่อ hello.py และตรวจสอบการเชื่อมต่อ:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)เมื่อรัน python hello.py จะพิมพ์คำตอบสั้นๆ ความหน่วงโทเค็นแรกบนชั้นฟรีอาจใช้เวลาสองสามวินาที เนื่องจากโมเดลกำลังก่อร่างรอย reasoning ก่อนสร้างคำตอบที่มองเห็นได้
โปรเจกต์ตัวอย่างนี้คือไปป์ไลน์ประมวลผลใบแจ้งหนี้ รองรับสองรูปแบบ: PDF แบบข้อความ และ JPG ที่สแกน ใบแจ้งหนี้แต่ละใบจะรันผ่าน Qwen 3.6 Plus โดยเปิด reasoning และฟิลด์ที่ดึงมาได้จะถูกส่งกลับผ่านการเรียกเครื่องมือ แต่ละใบผ่าน 4 ขั้นตอน:
ถอดรหัสอินพุต (เข้ารหัสภาพแบบ base64 หรือแปลงแต่ละหน้าของ PDF เป็นภาพก่อน)
สตรีมรอย reasoning กลับจากโมเดล
แปลงการเรียกเครื่องมือเป็น JSON แบบมีโครงสร้าง
เขียนหนึ่งแถวไปยัง results.csv
โค้ดทั้งหมดในส่วนนี้มีอยู่ที่ bextuychiev/qwen-invoice-pipeline-tutorial โคลนมาเพื่อตามไปพร้อมกัน หรือใช้เป็นข้อมูลอ้างอิงระหว่างสร้างเวอร์ชันของตนเอง
สร้างไดเรกทอรี invoice-pipeline/ และจัดโครงสร้างดังนี้:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtการแยกระหว่าง client.py กับตัวประมวลผล ช่วยให้การตั้งค่า OpenRouter อยู่ในไฟล์เดียว หากภายหลังสลับไป Alibaba Cloud ก็จะแก้เฉพาะ client.py ได้เลย
client.py ครอบ OpenAI client ด้วย base URL และรหัสโมเดลที่ถูกต้อง:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example อยู่ข้างๆ เพื่อให้ผู้ที่โคลน repo รู้ว่าต้องกรอกอะไรบ้าง:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1repo คู่กันนี้มีตัวอย่างใบแจ้งหนี้หกรายการจากสามแหล่ง:
ใบแจ้งหนี้ของบริษัทจริงมักไม่สามารถเผยแพร่ต่อสาธารณะได้เพราะมี PII จึงใช้ชุดนี้แทน ยอดรวมตามจริงระบุไว้ใน README ของ repo สำหรับตรวจสอบผลลัพธ์
หากเคยใช้ Qwen 3.5, CoT เป็นตัวเลือกต่อคำขอ: enable_thinking=True ภายใน extra_body บน 3.6 Plus reasoning จะทำงานโดยอัตโนมัติ และพารามิเตอร์นี้มีไว้เพื่อปิดเป็นหลัก โทเค็น reasoning จะถูกคิดค่าบริการเสมอเมื่อเปิดคิด ทำให้ “เปิดตลอดเวลา” เป็นเรื่องต้นทุน ไม่ใช่ฟีเจอร์ฟรี
เมื่อสตรีมคำตอบ delta.reasoning_content จะมาก่อน แล้วจึงตามด้วย delta.content (หรือ delta.tool_calls ในกรณีของเรา)
ตัวอย่างเรียกขั้นต่ำที่ดึงข้อมูลจากใบแจ้งหนี้และพิมพ์รอย reasoning ระหว่างสตรีมมีดังนี้:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)เราอ่านไบต์ของ JPG จากดิสก์ เข้ารหัส base64 และห่อด้วย URI แบบ data: รูปแบบนี้ทำให้โปรโตคอล content-block ของ OpenAI รับภาพแบบ inline ได้โดยไม่ต้องมี URL โฮสต์ บล็อก image_url รับ URI ได้โดยตรง และโมเดลมองเห็นใบแจ้งหนี้เหมือนส่งลิงก์ภาพ
extra_body={"enable_thinking": True} ส่งต่อแฟล็ก enable_thinking ไปยัง Qwen เนื่องจาก OpenAI SDK ไม่รู้จักพารามิเตอร์นี้ จึงใช้ extra_body เพื่อส่งออปชันเฉพาะผู้ให้บริการ
เมื่อรันกับ invoice_04.jpg คำตอบที่สตรีมกลับมาจะเป็นสรุปสั้นๆ:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51สั้นตามที่ขอไว้: พรอมป์ต system บอกให้ “สรุป” เท่านั้น เมื่องานซับซ้อนขึ้น (รายการสินค้า หมวดหมู่ ฟิลด์แบบมีโครงสร้าง) รอย reasoning จะยาวขึ้น เราจะเห็นในส่วนถัดไปที่ใช้โมเดลเดียวกันกับภาพเดิม แต่ใช้เวลาส่วนใหญ่ไปกับการคิดก่อนตอบ
การเติม /no_think ท้ายพรอมป์ตผู้ใช้งานเป็น สวิตช์แบบซอฟต์ เพื่อปิด CoT สำหรับคำขอนั้นๆ ใช้ช่วยดีบักเมื่ออยากได้คำตอบเร็วแบบไม่คิด
Reasoning ช่วยให้อ่านกระบวนการได้ แต่เอาต์พุตยังเป็นข้อความอิสระภายในรอย reasoning หากต้องการ JSON แบบมีโครงสร้างที่พาร์สได้ทุกครั้ง เรากำหนดเครื่องมือเดียวคือ extract_invoice และตั้งค่า tool_choice="auto" พร้อมพรอมป์ต system ที่สั่งให้โมเดลเรียกเครื่องมือนี้ทุกครั้ง
สคีมาใน tools.py อธิบาย 6 ฟิลด์ โครงร่างภายนอกทำตามรูปแบบมาตรฐานของฟังก์ชันเครื่องมือใน OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}ทั้งหกฟิลด์อยู่ภายใน parameters.properties ฟิลด์สเกลาร์ (vendor, date, total, tax) ใช้ชนิดของ JSON Schema ปกติ category ใช้ enum เพื่อให้โมเดลเลือกจาก 4 ค่าที่กำหนด แทนการสร้างป้ายกำกับเอง ส่วน line_items เป็นฟิลด์แบบมีโครงสร้าง เป็นอาเรย์ของอ็อบเจ็กต์ โดยแต่ละอ็อบเจ็กต์มีรายการ required ของตนเอง:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},สคีมามีระดับของ required สองชั้น รายการภายนอกระบุว่าฟิลด์ระดับบนใดต้องมีในทุกผลลัพธ์ รายการต่อรายการระบุว่าฟิลด์ย่อยใดต้องมีในแต่ละบรรทัดของรายการสินค้า สคีมาฉบับเต็มอยู่ใน tools.py ใน repo คู่กัน
อาร์กิวเมนต์จะถูกส่งกลับเป็นสตริงรูปแบบ JSON ภายใน tool_calls[0].function.arguments ไม่ใช่อ็อบเจ็กต์ที่พาร์สแล้ว จึงต้องเรียก json.loads เอง เมื่อสตรีม อาร์กิวเมนต์จะมาถึงเป็นลำดับของเดลตาที่ต้องต่อเข้าด้วยกันก่อนพาร์ส
ข้อควรระวัง: ปลายทาง Qwen 3.6 Plus ของ OpenRouter ไม่รองรับการบังคับเรียกเครื่องมือ หากลองใช้ tool_choice={"type": "function", "function": {"name": "extract_invoice"}} คำขอจะคืนข้อผิดพลาดว่า:
No endpoints found that support the provided 'tool_choice' valueวิธีแก้ปฏิบัติได้คือใช้ tool_choice="auto" และพึ่งพาพรอมป์ต system:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""กับใบแจ้งหนี้ตัวอย่างทั้งหกรายการใน repo คู่กัน พรอมป์ตนี้ทำให้เกิดการเรียกเครื่องมือทุกครั้ง โค้ดโปรดักชันยังควรป้องกันกรณียกเว้น: ตรวจ finish_reason ตรวจว่า tool_calls ถูกเติมข้อมูล และลองใหม่ด้วยคำสั่งที่คมขึ้นหากไม่ใช่ เอกสาร ของ Qwen เรื่อง function-calling ก็กล่าวเช่นกัน ว่าการสร้างการเรียกเครื่องมือไม่การันตี โค้ดโปรดักชันต้องมีแผนสำรอง
ผลข้างเคียงอย่างหนึ่ง: เมื่อพรอมป์ตขอข้อมูลแบบมีโครงสร้าง delta.reasoning_content จะยาวขึ้นมาก โมเดลจะพาร์สตารางทีละแถว ถกเรื่องสัญกรณ์ทศนิยมยุโรปใน invoice_04.jpg และตรวจสอบยอดรวมรายการกับยอดรวมสุดท้าย โทเค็น reasoning อาจมากกว่าโทเค็นคำตอบ 10 เท่าหรือมากกว่านั้นบนพรอมป์ตแบบนี้
นี่คือค่าใช้จ่ายของ CoT แบบเปิดตลอดเวลาในการดึงข้อมูลเชิงโครงสร้าง จึงทำให้ preserve_thinking คุ้มค่าเฉพาะลูปเอเจนต์หลายรอบที่รอบถัดไปจะอ่านรอย reasoning เรากำลังดึงแบบครั้งเดียว จึงสตรีมรอยไปยังเทอร์มินัลแล้วทิ้ง
สำหรับ JPG โฟลว์มี 3 ขั้นตอน:
อ่านไบต์ภาพจากดิสก์
เข้ารหัสแบบ Base64
ใส่ผลลัพธ์ลงในบล็อก image_url ด้วย URI แบบ data:
PDF ต้องเพิ่มอีกขั้น เนื่องจากช่องทางวิชันของ Qwen รับภาพแทนไฟล์ PDF โดยตรง ให้แปลงแต่ละหน้าเป็นภาพของ PIL ด้วย pdf2image แล้วส่งแต่ละหน้าเป็นรายการบล็อกภาพในข้อความเดียวกัน
ทั้งสองเส้นทางใช้การเรียกโมเดลเดียวกัน จึงวางการเรียกไว้ใน processors/image.py และ processors/pdf.py จะเรียกใช้งานต่อ เริ่มจากการอิมพอร์ต (SYSTEM_PROMPT จากด้านบนอยู่ในโมดูลเดียวกัน):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveตัวเข้ารหัสจะแปลงพาธ JPG เป็น URI แบบ data: ตามที่ API ต้องการ:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"ตัวช่วยใช้งานร่วม _call_with_images จะสร้างอาร์เรย์ user-content (ข้อความ + รูปภาพหนึ่งภาพหรือมากกว่า) และส่งคำขอแบบสตรีม จากสตรีมนี้จะรวบรวมสองส่วน: รอย reasoning และอาร์กิวเมนต์ของการเรียกเครื่องมือ เริ่มตั้งค่าคำขอก่อน:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)จากนั้นลูปสตรีมจะแยกเดลตาของ reasoning ออกจากเดลตาของอาร์กิวเมนต์การเรียกเครื่องมือ:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}จุดเข้าใช้งานสาธารณะสำหรับ JPG เป็นฟังก์ชันสั้นๆ ที่ใช้ตัวช่วยเหล่านั้น:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)ตัวประมวลผล PDF ใช้ซ้ำ _call_with_images และเพิ่มเฉพาะการแปลงหน้าสู่ภาพ:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image ต้องติดตั้ง poppler ติดตั้งได้ดังนี้:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsสำหรับ PDF หลายหน้า ให้ส่งทุกหน้าเป็นบล็อกภาพของตัวเองในข้อความเดียวกัน Qwen จะอ่านรวมกันและสร้างผลลัพธ์เดียว ซึ่งเหมาะกับใบแจ้งหนี้ที่ยอดรวมอยู่หน้าที่ 2
ความละเอียด 150 DPI ทำให้ข้อความบนใบแจ้งหนี้อ่านได้ชัด โดยไม่เพิ่มน้ำหนักเพย์โหลดมากไป การตั้งสูงกว่านี้ทำให้คำขอใหญ่ขึ้นโดยไม่เพิ่มความแม่นยำจากการทดสอบกับชุดตัวอย่าง เอกสาร วิชันของ Alibaba ครอบคลุมรูปแบบที่รองรับและขีดจำกัดสูงสุด
main.py เดินไฟล์ใน sample_invoices/ จัดเส้นทางตามนามสกุล ไฟล์ เรียกตัวประมวลผลที่เหมาะสม และเขียนผลรวมเป็น CSV เริ่มจากอิมพอร์ตและค่าคงที่:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}ลูปหลักจะวนไฟล์ในโฟลเดอร์ตัวอย่างตามลำดับ จัดเส้นทางตามนามสกุล และแปลงผลลัพธ์แต่ละรายการให้เป็นแถวที่เขียนลง CSV ได้ง่าย:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})สุดท้าย เขียนแถวลงดิสก์และแสดงจำนวนรายการ:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()เมื่อรัน python main.py จะไล่ประมวลผลตัวอย่างทั้งหกตามลำดับ แต่ละใบจะแสดงชื่อไฟล์ จากนั้นรอย reasoning แล้วตามด้วย JSON ที่ดึงได้ ก่อนขยับไปไฟล์ถัดไป
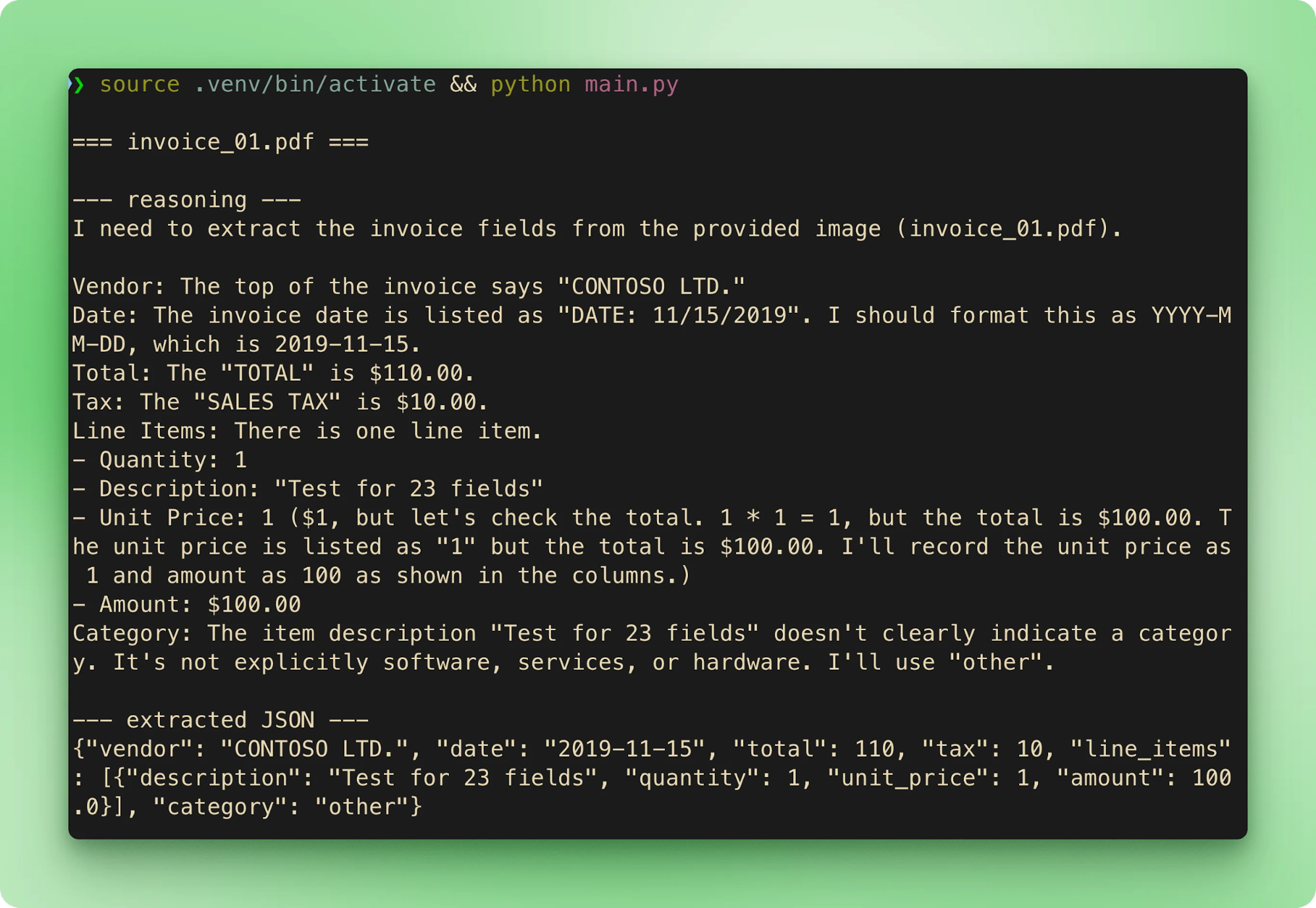
results.csv รวมผลลัพธ์การดึงข้อมูลเป็น หนึ่งแถวต่อใบแจ้งหนี้:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
ยอดรวมตรงกับค่าจริงทั้งหกไฟล์ เวลาแฝงบนชั้นฟรีอยู่ที่ 15–40 วินาทีต่อใบแจ้งหนี้ ส่วนใหญ่ใช้ไปกับช่วง reasoning ก่อนเริ่มสตรีมการเรียกเครื่องมือ
มีไม่กี่รูปแบบที่ทำให้ต่างกันระหว่างไปป์ไลน์ที่ทำงานได้ครั้งเดียว กับไปป์ไลน์ที่ทำงานได้จริงกับใบแจ้งหนี้หลากหลาย
เก็บความลับไว้นอกโค้ด รูปแบบ .env และ python-dotenv ที่เราใช้มาตลอดเป็นมาตรฐานพื้นฐาน เพิ่ม .env ไปยัง .gitignore ก่อนคอมมิตครั้งแรก เพื่อให้คีย์ไม่เข้าสู่ repo
จัดการ rate limit ด้วย exponential backoff OpenRouter บังคับใช้ลิมิตต่อผู้ให้บริการด้วย HTTP 429 ไลบรารี tenacity ให้การใช้งานแบบ decorator และ แพทเทิร์นจาก OpenAI cookbook สำหรับ wait_random_exponential ใช้ได้โดยไม่ต้องแก้
สตรีมเมื่อคาดว่าคำตอบจะยาว CoT แบบเปิดตลอดเวลาเพิ่มความยาวเอาต์พุตโดยค่าเริ่มต้น การเรียกแบบไม่สตรีมทำให้ต้องรอทั้งบล็อก reasoning ก่อนเห็นอะไร สตรีมจะให้ฟีดแบ็กเร็ว ทำให้ UI ตอบสนอง และยกเลิกคำขอที่ดูผิดทางได้
ใช้ preserve_thinking เฉพาะเมื่อรอบถัดไปจะอ่าน reasoning ก่อนหน้า สำหรับตัวดึงข้อมูลครั้งเดียวอย่างไปป์ไลน์นี้ ถือว่าเปลืองโทเค็น สำหรับลูปเอเจนต์หลายรอบ (ห่วงโซ่การเรียกเครื่องมือ งานวางแผน เวิร์กโฟลว์ดีบัก) พารามิเตอร์นี้ออกแบบมาเพื่อบริบทข้ามรอบ เอกสาร deep thinking ของ Alibaba ยังครอบคลุม thinking_budget ซึ่งเป็นเพดานโทเค็น reasoning ต่อคำขอ
คำตอบบนชั้นฟรีอาจถูกบันทึกเพื่อเทรน ชั้นฟรีของ OpenRouter อาจเราต์ผ่านผู้ให้บริการที่เก็บพรอมป์ตไว้ จึงไม่เหมาะกับใบแจ้งหนี้ที่มี PII ชื่อ ลูกค้า หรือรายละเอียดการชำระเงิน ย้ายไปชั้นชำระเงินของ OpenRouter (หรือตรงไป Alibaba Cloud แบบชำระเงิน) ก่อนส่งข้อมูลจริงผ่านไปป์ไลน์
ระดับ Plus ไม่รองรับโฮสต์เอง การดีพลอยที่ต้องแยกเครือข่ายหรือ on-prem ใช้ API แบบโฮสต์ไม่ได้ รุ่นโอเพ่นซอร์ส Qwen3.6-35B-A3B เป็นอีกทางเลือกที่ควรพิจารณาสำหรับกรณีนั้น
เวลาโทเค็นแรกอาจช้าเมื่อเริ่ม reasoning ตั้งเวลา timeout กว้างๆ 30 ถึง 60 วินาทีถือว่าเหมาะสำหรับอินพุตภาพ ตรวจให้แน่ใจว่าลอจิกการลองใหม่แยกแยะ read timeout ออกจาก 429
เอาต์พุตไม่เป็นดีเทอร์มินิสติกแม้เปิด CoT ตลอดเวลา จากการทดสอบกับตัวอย่างของ repo คู่กัน invoice_01.pdf มักดึงได้ $610.00 แต่มีอย่างน้อยหนึ่งครั้งที่พลิกเป็น $110.00 ด้วยอินพุตที่เหมือนกัน รอย reasoning ไปถึงคำตอบที่ถูกทั้งสองครั้ง แต่ค่าอาร์กิวเมนต์ของการเรียกเครื่องมือต่างกัน วิธีบรรเทา: ตั้ง temperature ต่ำ (0.1 ถึง 0.2 สำหรับงานดึงข้อมูลล้วน) และตรวจเทียบกับค่าจริงหรือทำรอบที่สองเมื่อต้องการความแม่นยำสูงพอจะยอมจ่ายค่าเรียกเพิ่ม
จากตรงนี้ การห่อไปป์ไลน์ด้วยเฟรมเวิร์กเอเจนต์เป็นเพียงก้าวเล็กๆ ลูปการเรียกเครื่องมือ ตัวพาร์เซอร์แบบสตรีม และตัวเขียน CSV คือพรีมิทีฟเดียวกับที่เฟรมเวิร์กเอเจนต์ประสานงานข้ามหลายรอบ DataCamp มีคอร์ส Developing LLM Applications with LangChain ที่อธิบายแพทเทิร์นเหล่านี้ร่วมกับหน่วยความจำ สถานะ และการเราต์หลายเครื่องมือ
คอร์ส Agentic AI
Tracks
Tracks
Courses