
Cursus
Principes fondamentaux des agents IA
6 h
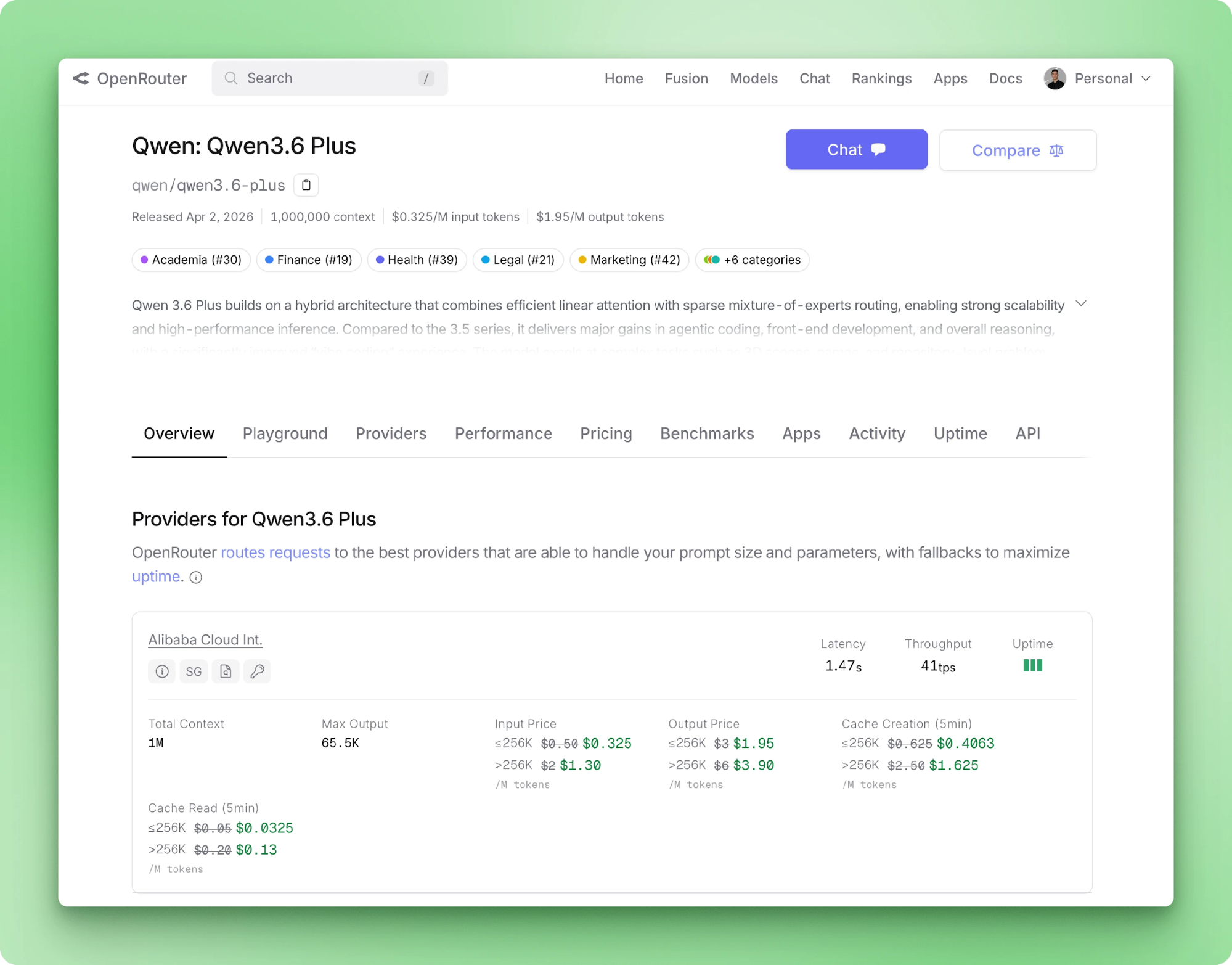
Alibaba a lancé Qwen 3.6 Plus en avril 2026. Sur la fiche technique : SWE-bench Verified à 78,8, une fenêtre de contexte de 1 million de tokens par défaut, des entrées multimodales natives et un raisonnement toujours activé. Pour un développeur Python, l’intérêt ne se résume pas au tableau des benchmarks : le modèle est accessible uniquement via API et fonctionne avec le package OpenAI standard en remplaçant simplement l’URL de base.
Dans ce tutoriel, nous allons utiliser trois de ses fonctionnalités clés dans un même projet : le raisonnement « chain-of-thought », l’appel d’outils pour un retour structuré et la vision sur des factures scannées. À l’arrivée : une petite chaîne de traitement de factures qui lit des PDF et des JPG, expose son raisonnement et renvoie un JSON validé que vous pouvez écrire dans un CSV.
Vous avez besoin de Python 3.10 ou plus récent et d’être à l’aise avec les appels d’API. Pas de GPU, pas de téléchargement de modèle, pas d’auto‑hébergement. Nous accéderons à Qwen 3.6 Plus via OpenRouter, ce qui réduit l’inscription à un seul formulaire, tout en conservant le SDK OpenAI inchangé.
Je vous recommande vivement notre tutoriel sur le fine-tuning de Qwen 3.6, la dernière version open-weights de Qwen. Si vous vous intéressez aux modèles concurrents, consultez aussi nos guides sur DeepSeek v4, le GPT‑5.5 d’OpenAI, et le Claude Opus 4.7 d’Anthropic.
Qwen 3.6 Plus est le modèle phare d’Alibaba en avril 2026. L’architecture repose sur une attention linéaire hybride avec mixture-of-experts clairsemée, le raisonnement est activé par défaut et texte, images et vidéo passent par la même API.
L’appel de fonctions suit le protocole d’outils OpenAI. Alibaba positionne cette version « vers des agents en conditions réelles », c’est‑à‑dire un seul modèle pour des entrées hétérogènes nécessitant raisonnement, lecture d’images et appel de fonction en une étape.
L’édition Plus est à poids fermés. Vous ne pouvez pas télécharger le checkpoint ni l’exécuter sur votre propre matériel (le modèle est de toute façon trop volumineux pour du matériel grand public). Alibaba publie une variante open source Qwen/Qwen3.6-35B-A3B avec un contexte par défaut de 262 K, mais c’est un produit distinct. Pour ce tutoriel, nous utilisons l’API hébergée.
Qwen 3.6 Plus accepte jusqu’à 1 million de tokens en entrée et renvoie jusqu’à 65 536 tokens en sortie par appel. Les modalités d’entrée incluent texte, image et vidéo. L’appel d’outils est natif via le schéma OpenAI. La page modèle d’OpenRouter liste les tarifs, la latence des fournisseurs et le débit des backends routés.
Le chain-of-thought s’exécute par défaut à chaque appel et le contenu de raisonnement est diffusé dans un champ séparé de la réponse. Un nouveau paramètre 3.6 Plus conserve les traces de raisonnement précédentes attachées aux messages sur plusieurs tours.
Alibaba le recommande pour les boucles d’agents où les tours suivants bénéficient des chaînes de pensée antérieures. Pour une extraction en un seul coup comme la nôtre, conserver la trace gaspille des tokens, donc nous la désactivons.
Trois scores de benchmark comptent pour ce tutoriel :
Les deux premiers expliquent pourquoi des factures scannées sont une cible pertinente. Le troisième laisse attendre que le modèle suive un protocole d’appel d’outil sans ingénierie de prompt lourde.
Le saut de version de 3.5 Plus à 3.6 Plus est modeste sur la plupart des métriques. Le code et le raisonnement gagnent quelques points. Le changement majeur : le raisonnement passe d’un interrupteur à l’état par défaut. L’OCR et la localisation d’objets sont ceux qui s’améliorent le plus.
|
Capacité |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Mode raisonnement |
Activé par défaut (désactivation possible avec |
CoT toujours activé |
|
Fenêtre de contexte |
Jusqu’à 1 M de tokens |
1 M de tokens (par défaut) |
|
Multimodal |
Vision-langage native |
Natif + OCR amélioré, localisation d’objets |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Raisonnement sur plusieurs tours |
— |
Paramètre |
Si vous exécutez 3.5 Plus en production, la mise à niveau implique d’adopter le nouveau paramètre preserve_thinking et de noter que le raisonnement est désormais facturé à chaque appel. Les gains principaux concernent les boucles d’agents et la vision documentaire, ce que nous exploitons ici.
Vous pouvez accéder au modèle de deux façons. La voie officielle est Alibaba Cloud Model Studio, qui vous fournit un endpoint direct à https://dashscope-intl.aliyuncs.com/compatible-mode/v1. L’autre est OpenRouter, qui route vers Alibaba derrière une couche de facturation unifiée et une inscription simplifiée.
Nous utilisons OpenRouter car la création de clés est plus rapide et il y a moins de particularités côté endpoint. Si vous préférez la voie directe, changez deux lignes et continuez.
Alibaba Cloud Model Studio fonctionne aussi bien qu’OpenRouter pour ce tutoriel. Seules l’URL de base et le nom de la variable d’environnement changent.
Inscrivez-vous sur openrouter.ai avec un compte Google ou GitHub. L’offre gratuite est accessible sans carte bancaire et suffit pour suivre ce tutoriel de bout en bout. Si vous prévoyez des volumes plus importants ensuite, ajouter du crédit vous donne une couche de débit supérieure et supprime la limite de taux par modèle.
Une fois connecté·e, allez sur openrouter.ai/settings/keys et créez une clé. Donnez‑lui un nom comme qwen-tutorial pour pouvoir la révoquer plus tard.
Copiez la valeur de la clé maintenant, car OpenRouter ne l’affiche qu’une seule fois. Puis enregistrez‑la dans un fichier .env à la racine de votre projet :
OPENROUTER_API_KEY=sk-or-v1-...Nous la chargerons avec python-dotenv dans la section suivante. Si vous préférez utiliser directement Alibaba Cloud, la clé provient de modelstudio.console.alibabacloud.com et s’enregistre dans DASHSCOPE_API_KEY à la place.
Installez les deux packages nécessaires pour le premier appel de vérification :
pip install openai python-dotenvLe package openai est le même SDK que celui utilisé avec l’endpoint d’OpenAI. OpenRouter comme Alibaba Cloud Model Studio implémentent l’API Chat Completions d’OpenAI, donc aucun changement côté client.
Créez un fichier hello.py et vérifiez la connexion :
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)L’exécution de python hello.py doit afficher une courte réponse. La latence du premier token sur l’offre gratuite peut prendre quelques secondes, le modèle construisant une trace de raisonnement avant de générer la réponse visible.
Le projet d’exemple est une chaîne de traitement de factures. Elle accepte deux formats : PDF texte et JPG scannés. Chaque facture passe dans Qwen 3.6 Plus avec raisonnement activé, et les champs extraits reviennent via un appel d’outil. Chaque facture suit quatre étapes :
Décoder l’entrée (encoder l’image en base64, ou convertir chaque page PDF en image avant)
Diffuser la trace de raisonnement renvoyée par le modèle
Parser l’appel d’outil en JSON structuré
Écrire une ligne dans results.csv
Tout le code de cette section se trouve dans bextuychiev/qwen-invoice-pipeline-tutorial. Clonez‑le pour suivre pas à pas, ou servez‑vous en comme référence pour bâtir votre propre version.
Créez un répertoire invoice-pipeline/ et structurez‑le ainsi :
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtLa séparation entre client.py et les processeurs garde la configuration OpenRouter dans un seul fichier. Si vous passez plus tard à Alibaba Cloud, vous n’éditez que client.py.
client.py encapsule le client OpenAI avec la bonne URL de base et l’ID du modèle :
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example accompagne le dépôt pour indiquer quoi renseigner :
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Le dépôt compagnon propose six factures d’exemple issues de trois sources :
Les factures d’entreprises réelles ne sont pas redistribuables publiquement à cause des données personnelles, d’où ces échantillons. Les totaux de référence sont indiqués dans le README du dépôt si vous souhaitez comparer la chaîne avec le « ground truth ».
Si vous avez utilisé Qwen 3.5, le CoT était un interrupteur par appel : enable_thinking=True dans extra_body. En 3.6 Plus, le raisonnement s’exécute par défaut et le paramètre sert surtout à le couper. Les tokens de raisonnement sont toujours facturés quand la pensée est active, ce qui en fait un choix de coût, pas une fonctionnalité « gratuite ».
En diffusion (« streaming »), delta.reasoning_content arrive en premier, puis delta.content suit (ou delta.tool_calls, dans notre cas).
Un appel minimal qui extrait une facture et affiche la trace de raisonnement au fil de l’eau ressemble à ceci :
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Nous lisons les octets du JPG depuis le disque, les encodons en base64 et encapsulons le résultat dans une URI data:. Ce format permet au protocole de blocs de contenu OpenAI d’accepter des images inline sans URL hébergée. Le bloc image_url prend l’URI directement et le modèle voit la facture comme si vous aviez passé un lien.
extra_body={"enable_thinking": True} transmet le drapeau enable_thinking à Qwen. Le SDK OpenAI ne connaît pas ce paramètre, donc extra_body est la façon de passer des options spécifiques au fournisseur.
Exécuté sur invoice_04.jpg, la réponse diffusée revient sous forme d’un bref résumé :
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Bref, car c’est ce que nous avons demandé : le prompt système disait « summarize » et rien de plus. Quand la tâche s’étoffe (lignes, catégories, champs structurés), la trace de raisonnement grandit avec. Nous le verrons dans la section suivante, où le même modèle sur la même image passe l’essentiel de son budget à réfléchir avant de répondre.
Ajouter /no_think au prompt utilisateur est un commutateur souple qui désactive le CoT pour cet appel. Pratique en débogage pour une réponse plus rapide sans raisonnement.
Le raisonnement rend l’extraction lisible, mais la sortie reste du texte libre à l’intérieur d’une trace. Pour obtenir un JSON structuré et analysable à chaque fois, nous définissons un outil, extract_invoice, et nous définissons tool_choice="auto" avec un prompt système qui impose toujours l’appel à l’outil.
Le schéma dans tools.py décrit six champs. La structure externe suit le format standard des outils de type fonction d’OpenAI :
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Les six champs résident dans parameters.properties. Les champs scalaires (vendor, date, total, tax) utilisent des types JSON Schema simples. category utilise un enum pour que le modèle choisisse parmi quatre valeurs fixes plutôt qu’inventer des libellés. line_items est le champ structuré : un tableau d’objets, chacun avec sa propre liste required :
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Le schéma comporte deux niveaux de required. La liste externe marque les champs de premier niveau obligatoires pour chaque extraction. La liste par élément impose les sous‑champs requis sur chaque ligne. Le schéma complet se trouve dans tools.py dans le dépôt compagnon.
Les arguments reviennent sous forme de chaîne JSON dans tool_calls[0].function.arguments, pas d’objet parsé : vous devez appeler json.loads vous‑même. En streaming, les arguments arrivent en une séquence de deltas à concaténer avant parsing.
Un piège : l’endpoint Qwen 3.6 Plus d’OpenRouter ne prend pas en charge l’appel d’outil forcé. Si vous tentez tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, la requête retourne une erreur :
No endpoints found that support the provided 'tool_choice' valueLa solution pragmatique consiste à utiliser tool_choice="auto" et à s’appuyer sur le prompt système :
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Sur les six factures d’exemple du dépôt compagnon, ce prompt déclenche un appel d’outil à chaque fois. En production, prévoyez tout de même le cas d’exception : vérifiez finish_reason, assurez‑vous que tool_calls est renseigné et relancez avec une instruction plus directe si besoin. La doc d’appel de fonctions de Qwen (lien) dit la même chose. La génération d’appels d’outils n’est pas garantie ; un repli est nécessaire en production.
Effet de bord : dès que le prompt exige des champs structurés, delta.reasoning_content se remplit d’une longue trace. Le modèle parcourt le tableau ligne par ligne, débat de la notation décimale européenne sur invoice_04.jpg et recoupe les montants des lignes avec le total. Les tokens de raisonnement peuvent dépasser les tokens de réponse d’un facteur 10 ou plus sur ce type de prompt.
C’est le coût du CoT toujours activé sur l’extraction structurée, d’où l’intérêt de preserve_thinking uniquement pour des boucles multi‑tours où un tour ultérieur lit la trace. Ici, nous faisons du « one‑shot » : la trace défile au terminal et nous la jetons.
Pour les JPG, le flux est en trois étapes :
Lire les octets de l’image depuis le disque
Les encoder en base64
Insérer le résultat dans un bloc image_url avec une URI data:
Les PDF nécessitent une étape supplémentaire, car le chemin vision de Qwen accepte des images plutôt que des fichiers PDF. Convertissez chaque page en image PIL avec pdf2image, puis envoyez les pages sous forme de liste de blocs image dans le même message.
Les deux chemins partagent le même appel modèle ; l’appel vit dans processors/image.py et processors/pdf.py y délègue. Commencez par les imports (le SYSTEM_PROMPT ci‑dessus vit dans le même module) :
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveL’encodeur transforme un chemin JPG en URI data: attendue par l’API :
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Le helper partagé _call_with_images construit le tableau de contenu utilisateur (texte + une ou plusieurs images) et envoie la requête en streaming. Il recueille deux éléments depuis le flux : la trace de raisonnement et les arguments de l’appel d’outil. La configuration de la requête d’abord :
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Ensuite, la boucle de streaming sépare les deltas de raisonnement des deltas d’arguments d’appel d’outil :
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Le point d’entrée public pour les JPG tient en une ligne qui utilise ces helpers :
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Le processeur PDF réutilise _call_with_images et n’ajoute que la conversion page → image :
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image nécessite l’installation de poppler. Installez‑le avec :
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsPour les PDF multi‑pages, envoyez chaque page comme son propre bloc image dans le même message. Qwen les lit ensemble et produit une seule extraction, ce qui est idéal quand les totaux sont en page 2.
150 DPI gardent le texte lisible sans gonfler la charge utile. Aller au‑delà augmente la taille de la requête sans améliorer la précision sur nos échantillons. La documentation vision d’Alibaba détaille les formats pris en charge et les limites supérieures.
main.py parcourt sample_invoices/, route chaque fichier par extension, appelle le bon processeur et écrit le tout dans un CSV. Imports et constantes :
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}La boucle principale itère le répertoire des échantillons dans l’ordre trié, route par extension et aplatit chaque extraction en une ligne compatible CSV :
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Enfin, écrivez les lignes sur disque et journalisez le nombre :
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()L’exécution de python main.py parcourt les six échantillons dans l’ordre. Chaque facture diffuse son nom de fichier, puis la trace de raisonnement, puis le JSON extrait, avant de passer à la suivante :
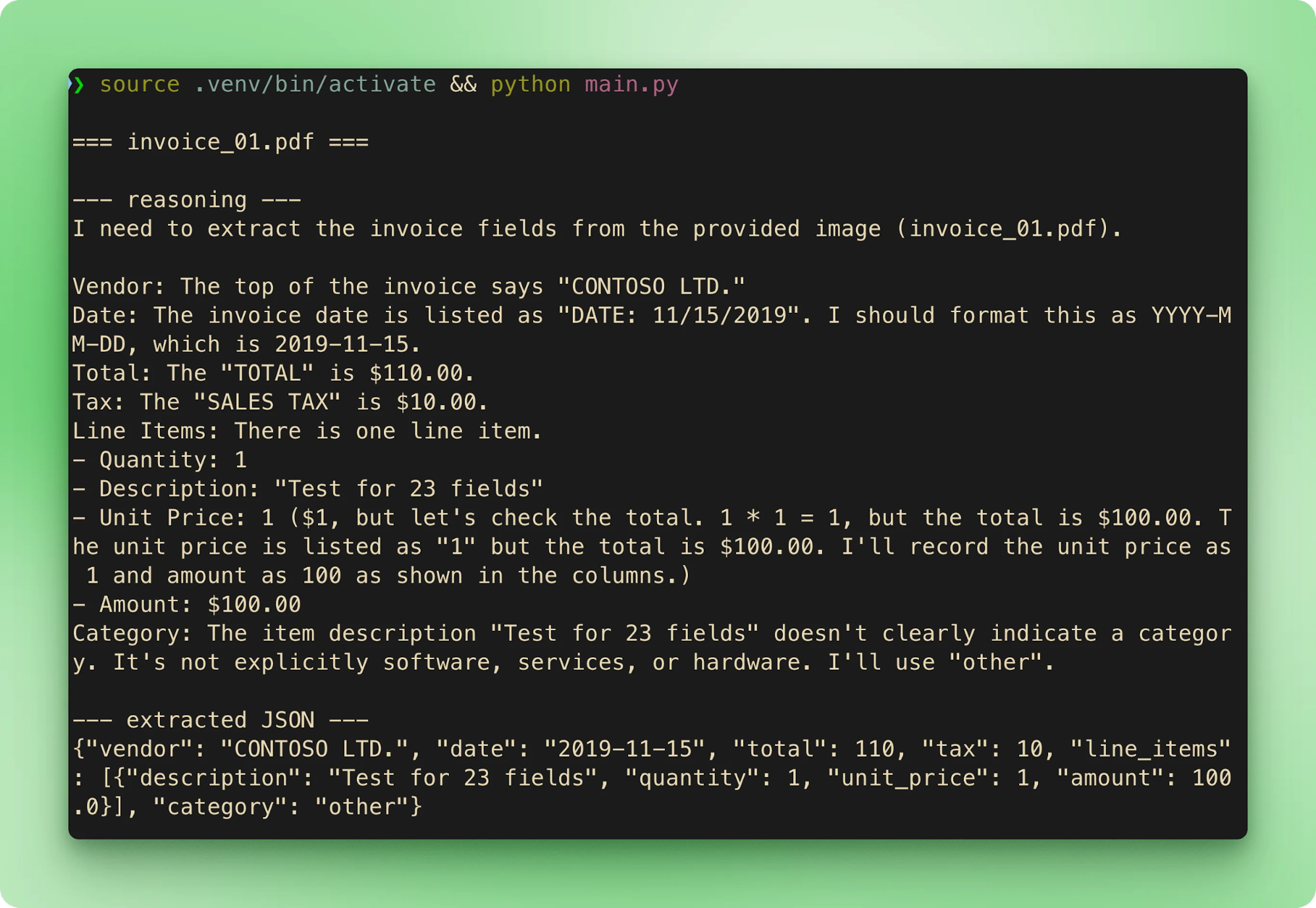
results.csv agrège chaque extraction en une ligne par facture :
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Les totaux correspondent au ground truth sur les six. La latence sur l’offre gratuite varie de 15 à 40 secondes par facture. La majeure partie correspond à la phase de raisonnement avant le début du streaming de l’appel d’outil.
Quelques schémas font la différence entre une chaîne qui marche une fois et une qui reste robuste sur de vraies factures.
Gardez les secrets hors du code. Le duo .env + python-dotenv que nous utilisons est le minimum. Ajoutez .env à votre .gitignore avant le premier commit pour que la clé n’arrive jamais dans le dépôt.
Gérez le rate limiting avec backoff exponentiel. OpenRouter applique des limites par fournisseur avec des réponses HTTP 429. La librairie tenacity fournit une implémentation à base de décorateurs, et le schéma du cookbook OpenAI pour wait_random_exponential fonctionne tel quel.
Utilisez le streaming pour les réponses longues. Le CoT toujours activé allonge par défaut les réponses. Sans streaming, vous attendez tout le bloc de raisonnement avant de voir quoi que ce soit. Le streaming donne un retour précoce, garde l’UI réactive et permet d’interrompre une requête qui part visiblement de travers.
N’utilisez preserve_thinking que si des tours ultérieurs lisent le raisonnement antérieur. Pour une extraction en un coup comme ici, ce sont des tokens perdus. Pour des boucles d’agents multi‑tours (chaînes d’outils, planification, débogage), le paramètre sert précisément à ce contexte inter‑tours. La documentation deep thinking d’Alibaba couvre aussi thinking_budget, un plafond dur sur les tokens de raisonnement par appel.
Les réponses du palier gratuit peuvent être journalisées pour l’entraînement. Le palier gratuit d’OpenRouter route via des fournisseurs qui peuvent conserver les prompts. Évitez‑le pour des factures avec PII, noms de clients ou données de paiement. Passez à une offre payante OpenRouter (ou directement Alibaba Cloud payant) avant d’y faire transiter des données réelles.
Pas d’auto‑hébergement sur l’édition Plus. Les déploiements nécessitant de l’isolation réseau ou on‑prem ne peuvent pas utiliser l’API hébergée. La variante open source Qwen3.6-35B-A3B est une autre option à considérer dans ces cas.
Le temps jusqu’au premier token peut être long quand le raisonnement démarre. Fixez des timeouts généreux, 30 à 60 secondes sont raisonnables pour une entrée image. Assurez‑vous que votre logique de retry traite séparément les timeouts de lecture et les 429.
La sortie n’est pas déterministe même avec CoT toujours activé. Dans nos tests sur les échantillons du dépôt compagnon, invoice_01.pdf s’extrait à $610,00 la plupart du temps, mais est passé à $110,00 au moins une fois avec des entrées identiques. La trace de raisonnement convergeait correctement dans les deux cas, mais l’argument final de l’appel d’outil différait. Deux parades : temperature faible (0,1 à 0,2 pour de l’extraction pure) et validation par vérité terrain ou seconde passe quand la précision le justifie.
À partir d’ici, encapsuler la chaîne dans un framework d’agents est une petite étape. La boucle d’appel d’outils, le parseur en streaming et l’écriture CSV sont les mêmes briques qu’un framework d’agents orchestre sur plusieurs tours. Le cours de DataCamp Developing LLM Applications with LangChain parcourt ces schémas avec mémoire, état et routage multi‑outils.
Cours sur les IA agentiques
Cursus
Cursus
Cours
Tutoriel
DataCamp Team
Tutoriel
Moez Ali
Tutoriel
Laiba Siddiqui
Tutoriel
Satyabrata Pal
Tutoriel
Sejal Jaiswal
