
Leerpad
Basisprincipes van AI-agenten
6 Hr
Alibaba bracht Qwen 3.6 Plus uit in april 2026. De specs: SWE-bench Verified op 78,8, standaard een contextvenster van 1M tokens, native multimodale input en always-on reasoning. Voor een Python-developer is het interessante niet de benchmarktabel, maar dat het model alleen via API werkt en gewoon met het OpenAI-pakket samenwerkt door de base-URL te wisselen.
In deze tutorial gebruiken we drie hoofdfeatures in één project: chain-of-thought reasoning, tool-calling voor gestructureerde output en vision op gescande facturen. Het resultaat is een kleine factuurpipeline die PDF’s en JPG’s leest, zijn redenering toont en gevalideerde JSON terugstuurt die je naar een CSV kunt schrijven.
Je hebt Python 3.10 of nieuwer nodig en bekendheid met het maken van API-calls. Geen GPU, geen modeldownloads, geen self-hosting. We benaderen Qwen 3.6 Plus via OpenRouter, zodat aanmelden één formulier is en de OpenAI SDK ongewijzigd werkt.
Ik raad je ook aan onze tutorial over Fine-tuning van Qwen 3.6 te bekijken, de nieuwste open-weights-versie van Qwen. Als je geïnteresseerd bent in concurrerende modellen, lees dan zeker onze gidsen over DeepSeek v4, OpenAI’s GPT-5.5 en Anthropic’s Claude Opus 4.7.
Qwen 3.6 Plus is Alibaba’s vlaggenschipmodel van april 2026. De backbone is een hybride van lineaire aandacht plus sparse mixture-of-experts, redenering draait standaard en tekst, afbeeldingen en video gaan allemaal via dezelfde API.
Function calling gebruikt het OpenAI tool-call-protocol. Alibaba positioneert de release als “towards real-world agents”, oftewel één model voor rommelige input die in één stap redenering, beeldlezing en een functiecall nodig heeft.
De Plus-laag heeft gesloten gewichten. Je kunt de checkpoint niet downloaden en op eigen hardware draaien (het model is sowieso te groot voor consumentenhardware). Alibaba publiceert wel een open-sourcevariant Qwen/Qwen3.6-35B-A3B met standaard 262K context, maar dat is een apart product. Voor deze tutorial gebruiken we de gehoste API.
Qwen 3.6 Plus neemt tot 1M inputtokens en geeft tot 65.536 outputtokens per call. Inputmodaliteiten zijn tekst, afbeelding en video. Tool-calling is native via het OpenAI-schema. De modelpagina van OpenRouter toont prijzen, providerlatentie en throughput voor de geroute backends.
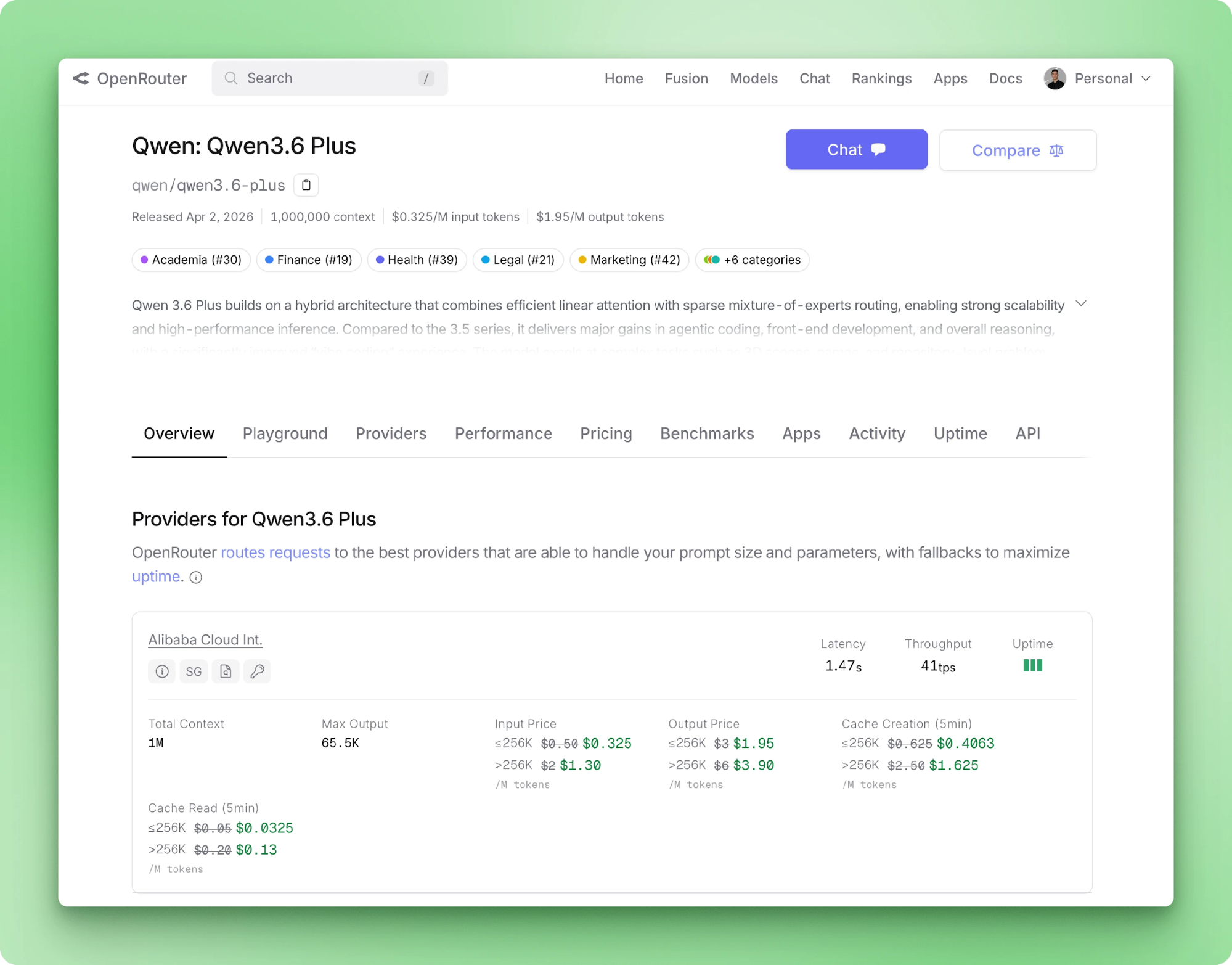
Chain-of-thought draait standaard bij elke call, en de redeneringscontent streamt terug op een apart veld naast het antwoord. Een nieuwe 3.6 Plus-parameter houdt eerdere reasoning-traces gekoppeld aan berichten over meerdere beurten.
Alibaba raadt dit aan voor agentloops waarin latere beurten baat hebben bij eerdere chains of thought. Voor one-shot-extractie zoals de onze is het bewaren van de trace verspilling van tokens, dus we schakelen het uit.
Drie benchmarkcijfers zijn relevant voor deze tutorial:
De eerste twee zijn waarom gescande facturen een logische use case zijn. De derde is waarom we mogen verwachten dat het model een tool-callprotocol volgt zonder zware prompt engineering.
De sprong van 3.5 Plus naar 3.6 Plus is op de meeste metrics klein. Codeer- en redeneerbenchmarks winnen enkele punten. De grotere verschuiving is dat reasoning verandert van een schakeloptie naar de standaard. OCR en objectlokalisatie verbeteren het meest.
|
Vermogen |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Reasoning-modus |
Standaard aan (kan worden uitgeschakeld met |
Altijd-aan CoT |
|
Contextvenster |
Tot 1M tokens |
1M tokens (standaard) |
|
Multimodaal |
Native vision-language |
Native + verbeterde OCR, objectlokalisatie |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Reasoning-over-beurten |
— |
|
Als je 3.5 Plus al in productie draaide, betekent de upgrade dat je de nieuwe preserve_thinking-parameter adopteert en noteert dat thinking nu bij elke call wordt gefactureerd. De belangrijkste winst zit in agentloops en documentvision, precies wat deze tutorial gebruikt.
Je kunt het model op twee manieren benaderen. De officiële is Alibaba Cloud Model Studio, die je een directe endpoint geeft op https://dashscope-intl.aliyuncs.com/compatible-mode/v1. De andere is OpenRouter, dat naar Alibaba routeert achter een uniforme billinglaag en een eenvoudiger onboarding.
De tutorial gebruikt OpenRouter omdat het aanmaken van een key sneller gaat en er minder endpoint-eigenaardigheden zijn. Wil je de directe route, wijzig dan twee regels en ga verder.
Alibaba Cloud Model Studio werkt net zo goed als OpenRouter voor deze tutorial. Alleen de base-URL en de naam van de omgevingsvariabele veranderen.
Meld je aan op openrouter.ai met een Google- of GitHub-account. De gratis laag is beschikbaar zonder creditcard en volstaat om deze tutorial van begin tot eind te volgen. Als je later grotere volumes wilt draaien, levert het toevoegen van tegoed een hogere throughput en vervalt de rate cap per model.
Zodra je bent ingelogd, ga je naar openrouter.ai/settings/keys en maak je een sleutel aan. Geef ’m een label zoals qwen-tutorial zodat je ’m later kunt intrekken.
Kopieer de sleutel nu, want OpenRouter toont ’m maar één keer. Sla ’m daarna op in een .env-bestand in de root van je project:
OPENROUTER_API_KEY=sk-or-v1-...We laden ’m met python-dotenv in de volgende sectie. Als je liever direct Alibaba Cloud gebruikt, komt de sleutel van modelstudio.console.alibabacloud.com en gaat in DASHSCOPE_API_KEY in plaats daarvan.
Installeer de twee pakketten die we nodig hebben voor de eerste verificatiecall:
pip install openai python-dotenvHet openai-pakket is dezelfde SDK die je met OpenAI’s endpoint zou gebruiken. Zowel OpenRouter als Alibaba Cloud Model Studio implementeren de OpenAI Chat Completions API, dus de clientcode hoeft niet te veranderen.
Maak een bestand hello.py en verifieer de verbinding:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Het draaien van python hello.py zou een kort antwoord moeten printen. De first-token-latency op de gratis laag kan een paar seconden duren omdat het model eerst een reasoning-trace opbouwt voordat het het zichtbare antwoord genereert.
Het voorbeeldproject is een factuurverwerkingspipeline. Hij accepteert twee formaten: tekst-PDF’s en gescande JPG’s. Elke factuur gaat door Qwen 3.6 Plus met reasoning aan, en de geëxtraheerde velden komen terug via een tool-call. Elke factuur doorloopt vier stappen:
Decodeer de input (base64-encodeer de afbeelding, of converteer elke PDF-pagina eerst naar een afbeelding)
Stream de reasoning-trace terug vanuit het model
Parse de tool-call naar gestructureerde JSON
Schrijf een rij naar results.csv
Alle code voor deze sectie staat in bextuychiev/qwen-invoice-pipeline-tutorial. Clone ’m om mee te volgen, of gebruik ’m als referentie terwijl je je eigen versie bouwt.
Maak een invoice-pipeline/-map en structureer die zo:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtDe splitsing tussen client.py en de processors houdt de OpenRouter-configuratie in één bestand. Als je later naar Alibaba Cloud wisselt, bewerk je client.py en verder niets.
client.py wikkelt de OpenAI-client met de juiste base-URL en het model-ID:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example staat erbij zodat iedereen die de repo clonet weet wat in te vullen:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1De bijbehorende repo bevat zes voorbeeldfacturen uit drie bronnen:
Echte bedrijfsfacturen zijn vanwege PII niet publiek herdistribueerbaar, dus gebruiken we deze. Ground-truth-totalen staan in de README van de repo als je de pipeline ertegen wilt checken.
Als je Qwen 3.5 hebt gebruikt, was CoT een toggle per call: enable_thinking=True binnen extra_body. Op 3.6 Plus draait reasoning standaard en bestaat de parameter vooral om het uit te zetten. Reasoning-tokens worden altijd gefactureerd wanneer thinking actief is, wat “altijd-aan” tot een kostenbeslissing maakt in plaats van een gratis feature.
Als je een reactie streamt, komt delta.reasoning_content eerst binnen, gevolgd door delta.content (of delta.tool_calls, in ons geval).
Een minimale call die een factuur extraheert en de reasoning-trace print terwijl die streamt, ziet er zo uit:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)We lezen de JPG-bytes van schijf, base64-encoden ze en wikkelen het resultaat in een data:-URI. Dat formaat laat het OpenAI content-block-protocol inline afbeeldingen accepteren zonder gehoste URL. Het image_url-blok neemt de URI direct, en het model ziet de factuur alsof je een link had doorgegeven.
extra_body={"enable_thinking": True} geeft de enable_thinking-vlag door aan Qwen. De OpenAI SDK kent de parameter niet, dus extra_body is de manier om provider-specifieke opties mee te geven.
Als je dit draait op invoice_04.jpg, komt het gestreamde antwoord terug als een korte samenvatting:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Kort is wat we vroegen: de systeemprompt zei “summarize” en niets meer. Als de taak groeit (regelniveaus, categorieën, gestructureerde velden), groeit de reasoning-trace mee. Dat zien we in de volgende sectie, waar hetzelfde model op dezelfde afbeelding het grootste deel van zijn outputbudget aan denken besteedt voordat het antwoordt.
Door /no_think aan het userprompt toe te voegen, schakel je CoT voor die call zacht uit. Handig tijdens debuggen voor een snellere, niet-denkende response.
Reasoning maakt de extractie leesbaar, maar de output is nog steeds vrije tekst binnen een reasoning-trace. Om elke keer gestructureerde, parsebare JSON terug te krijgen, definiëren we één tool, extract_invoice, en zetten tool_choice="auto" met een systeemprompt die het model instrueert om de tool altijd aan te roepen.
Het schema in tools.py beschrijft zes velden. De buitenste vorm volgt het standaard OpenAI function-tool-formaat:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}De zes velden staan binnen parameters.properties. Scalaire velden (vendor, date, total, tax) gebruiken gewone JSON Schema-typen. category gebruikt een enum zodat het model kiest uit een vaste set van vier waarden in plaats van labels te verzinnen. line_items is het ene gestructureerde veld, een array van objecten, elk met een eigen required-lijst:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Het schema heeft twee niveaus van required. De buitenste lijst markeert welke toplevel-velden in elke extractie moeten voorkomen. De per-item-lijst markeert welke subvelden op elk regelniveau moeten staan. Het volledige schema staat in tools.py in de bijbehorende repo.
De argumenten komen terug als een JSON-geformatteerde string binnen tool_calls[0].function.arguments, niet als een geparse object, dus je roept zelf json.loads erop aan. Bij streamen komen de argumenten als een reeks delta’s die je concateneert voordat je ze parseert.
Eén valkuil: de Qwen 3.6 Plus-endpoint van OpenRouter ondersteunt geen geforceerde tool-calls. Als je probeert met tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, geeft het verzoek een fout:
No endpoints found that support the provided 'tool_choice' valueDe praktische oplossing is tool_choice="auto" en vertrouwen op de systeemprompt:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Over alle zes voorbeeldfacturen in de bijbehorende repo levert deze prompt elke keer een tool-call op. Productiecode moet nog steeds tegen de uitzonderingscase beveiligen: check finish_reason, verifieer of tool_calls gevuld is, en probeer opnieuw met een scherpere instructie als dat niet zo is. Qwen’s eigen function-calling-docs melden hetzelfde. Tool-callgeneratie is niet gegarandeerd, en productiecode heeft een fallback nodig.
Een neveneffect: zodra de prompt om gestructureerde velden vraagt, vult delta.reasoning_content zich met een lange trace. Het model parseert de tabel rij voor rij, discussieert over Europese decimale notatie op invoice_04.jpg, en kruist regelniveau-bedragen met het totaal. Reasoning-tokens kunnen op dit soort prompt 10x of meer talrijker zijn dan antwoordtokens.
Dat is de kostenkant van always-on CoT bij gestructureerde extractie, en daarom loont preserve_thinking alleen bij multi-turn agentloops waar een latere beurt de trace leest. Wij doen one-shot-extractie, dus de trace streamt naar de terminal en we gooien ’m weg.
Voor JPG’s is de flow drie stappen:
Lees de afbeeldingsbytes van schijf
Base64-encodeer ze
Plaats het resultaat in een image_url-contentblok met een data:-URI
PDF’s hebben één extra stap omdat Qwen’s vision-pad afbeeldingen accepteert en niet direct PDF-bestanden. Converteer elke pagina naar een PIL-afbeelding met pdf2image, en stuur de pagina’s dan als een lijst met image-contentblokken in hetzelfde bericht.
Beide paden delen dezelfde modelcall, dus de call leeft in processors/image.py en processors/pdf.py delegeert daarheen. Begin met de imports (de SYSTEM_PROMPT hierboven staat in dezelfde module):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveDe encoder zet een JPG-pad om naar de data:-URI die de API verwacht:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"De gedeelde helper _call_with_images bouwt de user-content-array (tekst + één of meer afbeeldingen) en stuurt het streamingverzoek. Uit de stream verzamelt hij twee dingen: de reasoning-trace en de tool-call-argumenten. Eerst de request-setup:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Daarna splitst de streamloop reasoning-delta’s van tool-call-argument-delta’s:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}De publieke entrypoint voor JPG’s is een oneliner die die helpers gebruikt:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)De PDF-processor hergebruikt _call_with_images en voegt alleen de conversie van pagina naar afbeelding toe:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image vereist poppler. Installeer dat met:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsVoor meerpaginapdf’s stuur je elke pagina als eigen imageblok in hetzelfde bericht. Qwen leest ze samen en produceert één extractie, wat je wilt bij een factuur waarvan de totalen op pagina 2 staan.
150 DPI houdt factuurtekst leesbaar zonder de payload op te blazen. Hoger gaan maakt het verzoek groter zonder de nauwkeurigheid te verbeteren in tests op deze samples. Alibaba’s vision-documentatie dekt ondersteunde formaten en bovengrenzen.
main.py loopt door sample_invoices/, routeert elk bestand op extensie, roept de juiste processor aan en schrijft de gecombineerde resultaten naar een CSV. Eerst imports en constanten:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}De hoofdloop itereert de samples-map in gesorteerde volgorde, routeert op bestandsextensie en vlakt elke extractie af naar een CSV-vriendelijke rij:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Tot slot schrijf je de rijen naar schijf en log je de telling:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
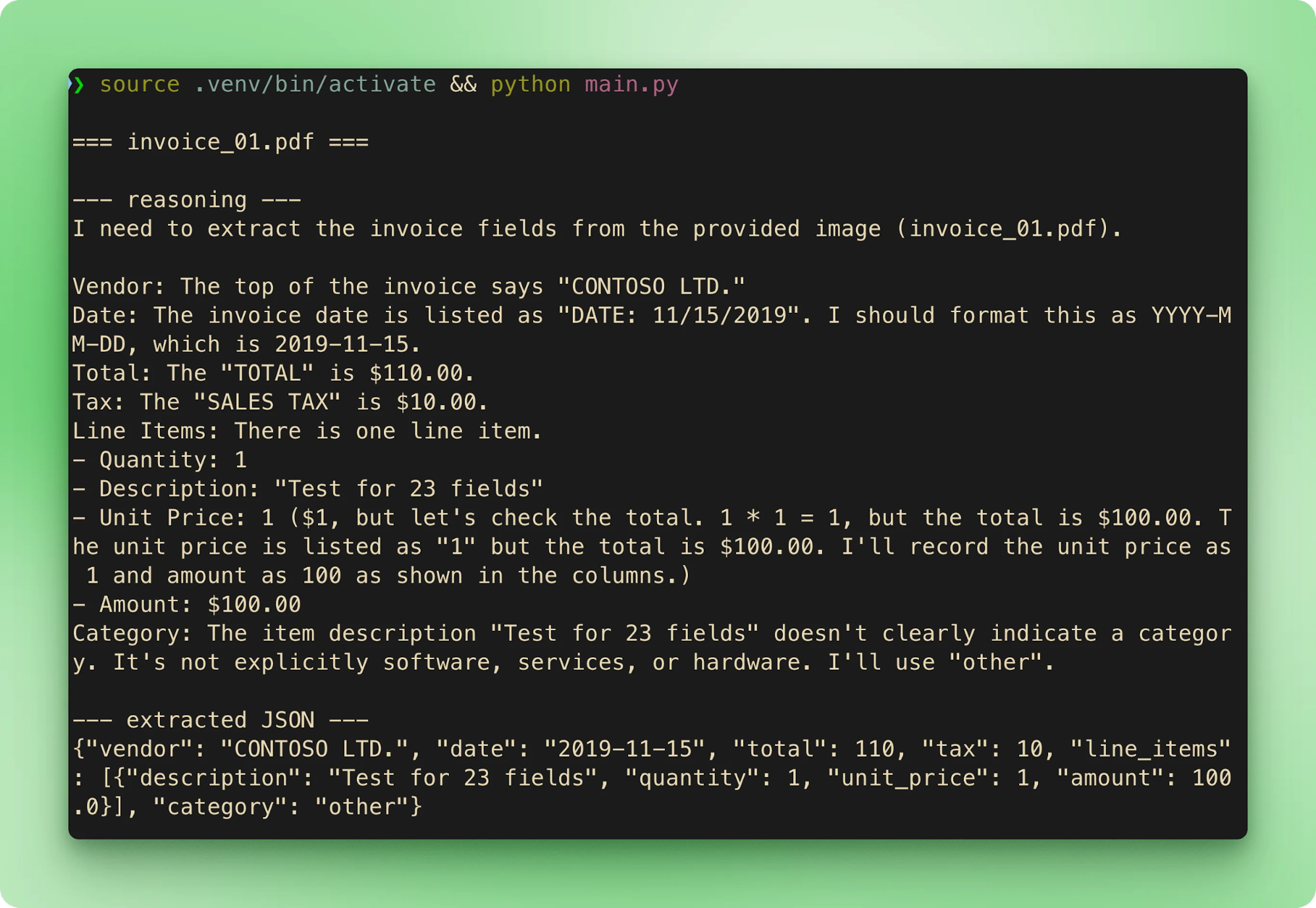
main()Het draaien van python main.py loopt de zes samples in volgorde door. Elke factuur streamt zijn bestandsnaam, dan de reasoning-trace en vervolgens de geëxtraheerde JSON, voor hij naar de volgende gaat:
results.csv aggregeert elke extractie tot één rij per factuur:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Totalen komen overeen met de ground truth op alle zes. Latentie op de gratis laag ligt op 15 tot 40 seconden per factuur. Het meeste daarvan is de reasoning-fase voordat de tool-call begint te streamen.
Een paar patronen maken het verschil tussen een pipeline die één keer werkt en een die op echte facturen blijft werken.
Houd secrets uit je code. Het .env- en python-dotenv-patroon dat we overal gebruiken is de basis. Voeg .env toe aan je .gitignore vóór de eerste commit zodat de sleutel de repo nooit bereikt.
Ga rate limits te lijf met exponentiële backoff. OpenRouter hanteert per-providerlimieten met HTTP 429-responses. De tenacity-bibliotheek geeft je een decorator-gebaseerde implementatie, en het OpenAI cookbook-patroon voor wait_random_exponential werkt ongewijzigd.
Stream wanneer responses lang zullen zijn. Always-on CoT blaast de responslengte standaard op. Niet-streamende calls betekenen wachten op het volledige reasoningblok vóór je iets ziet. Streamen geeft vroege feedback, houdt de UI responsief en laat je een verzoek afbreken dat duidelijk de verkeerde kant op gaat.
Gebruik preserve_thinking alleen wanneer latere beurten eerdere reasoning lezen. Voor one-shot-extractors zoals deze pipeline zijn het verspilde tokens. Voor multi-turn agentloops (tool-calling-ketens, planningtaken, debugworkflows) bestaat de parameter juist voor die cross-turn context. Alibaba’s deep thinking-documentatie behandelt ook thinking_budget, een harde limiet op reasoning-tokens per call.
Responses op de gratis laag kunnen voor training worden gelogd. De gratis laag van OpenRouter routeert via providers die prompts kunnen bewaren. Dat maakt ’m ongeschikt voor facturen met echte PII, klantnamen of betalingsgegevens. Stap over op een betaalde OpenRouter-laag (of direct naar Alibaba Cloud met een betaald account) voordat er echte data door de pipeline gaat.
Geen self-hosting op de Plus-laag. Deployments die air-gapping of on-prem vereisen, kunnen de gehoste API niet gebruiken. De open-sourcevariant Qwen3.6-35B-A3B is een apart alternatief om te overwegen voor die gevallen.
Time-to-first-token kan traag zijn wanneer reasoning start. Stel time-outs royaal in; 30 tot 60 seconden is redelijk voor beeldinput. Zorg dat je retrylogica read time-outs apart van 429’s afhandelt.
Output is niet deterministisch, zelfs met always-on CoT. In tests op de samples van de bijbehorende repo werd invoice_01.pdf meestal als $610,00 geëxtraheerd. Bij minstens één herhaalrun met identieke input flipte het naar $110,00. De reasoning-trace kwam beide keren tot het juiste antwoord, maar het uiteindelijke tool-call-argument verschilde. Twee mitigaties: zet temperature laag (0,1–0,2 voor pure extractie) en valideer tegen ground truth of gebruik een tweede pass wanneer nauwkeurigheid belangrijk genoeg is om de extra call te rechtvaardigen.
Vanaf hier is het inpakken van de pipeline in een agentframework een kleine stap. De tool-call-loop, de streamingparser en de CSV-writer zijn dezelfde bouwstenen die een agentframework over meerdere beurten orkestreert. DataCamp’s cursus Developing LLM Applications with LangChain doorloopt die patronen met geheugen, state en multi-toolrouting.
Agentic AI-cursussen
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
