
Lernpfad
KI-Agent-Grundlagen
6 Std.
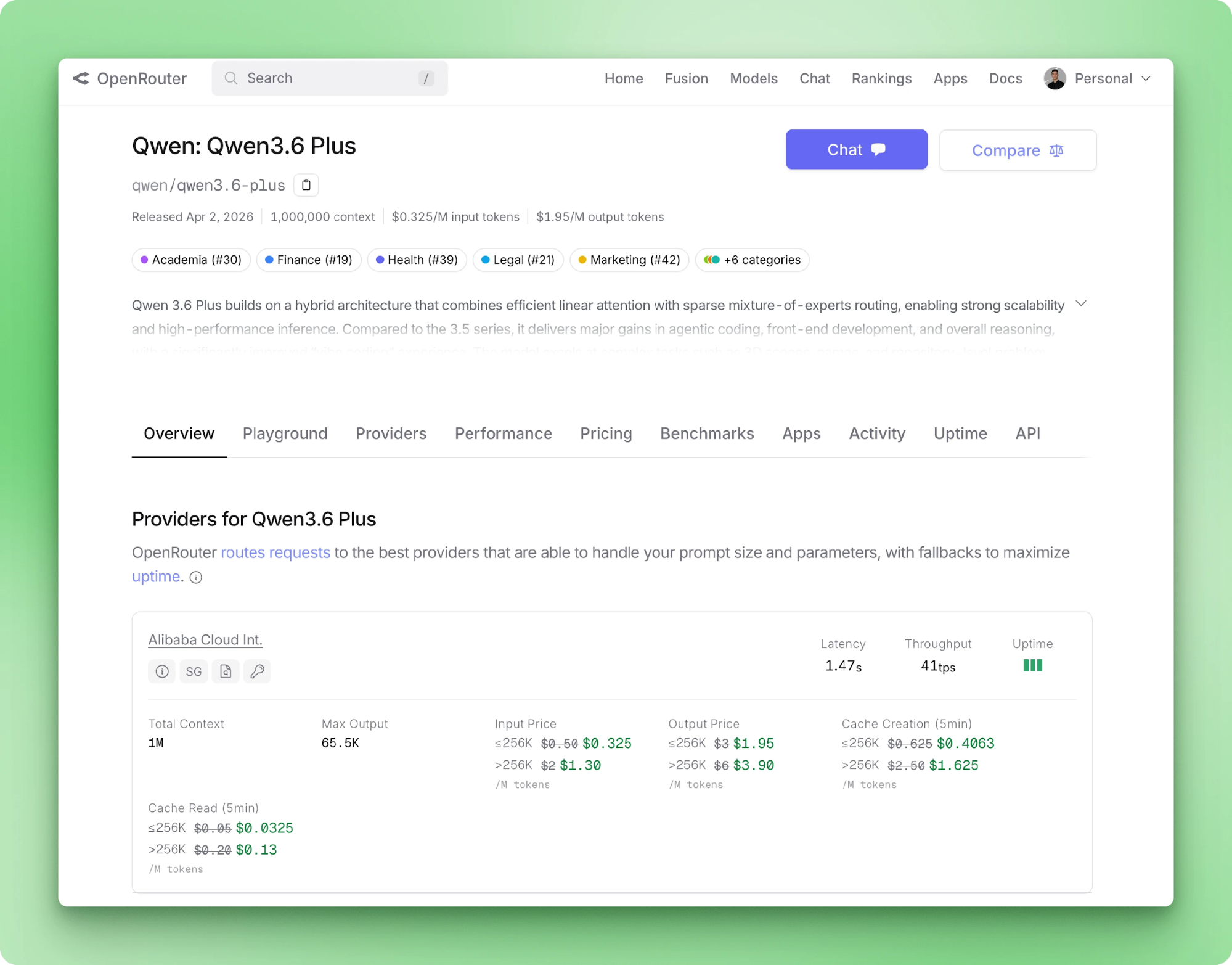
Alibaba hat Qwen 3.6 Plus im April 2026 ausgeliefert. Die wichtigsten Daten: SWE-bench Verified mit 78,8, ein Kontextfenster von 1 Mio. Tokens standardmäßig, native multimodale Eingaben und dauerhaft aktives Reasoning. Für Python-Entwickler ist nicht die Benchmark-Tabelle spannend, sondern dass das Modell nur per API verfügbar ist und mit dem OpenAI-Paket funktioniert, wenn du nur die Base-URL austauschst.
In diesem Tutorial nutzen wir drei Kernfeatures in einem Projekt: Chain-of-Thought-Reasoning, Tool-Aufrufe für strukturierten Output und Vision für gescannte Rechnungen. Das Ergebnis ist eine kleine Rechnungsverarbeitungs-Pipeline, die PDFs und JPGs liest, ihr Denken zeigt und validiertes JSON zurückgibt, das du in eine CSV schreiben kannst.
Du brauchst Python 3.10 oder neuer und etwas Erfahrung mit API-Calls. Keine GPU, keine Modelldownloads, kein Self-Hosting. Wir greifen über OpenRouter auf Qwen 3.6 Plus zu, dadurch ist die Registrierung in einem Schritt erledigt und das OpenAI SDK läuft unverändert.
Ich empfehle dir außerdem unser Tutorial zu Fine-Tuning Qwen 3.6, der neuesten Open-Weights-Version von Qwen. Wenn dich Wettbewerbsmodelle interessieren, lies auch unsere Guides zu DeepSeek v4, OpenAI’s GPT-5.5 und Anthropic’s Claude Opus 4.7.
Qwen 3.6 Plus ist Alibabas Flaggschiffmodell vom April 2026. Das Rückgrat ist eine Hybrid-Architektur aus Linear-Attention und Sparse Mixture-of-Experts, Reasoning läuft standardmäßig, und Text, Bilder sowie Videos gehen alle durch dieselbe API.
Function Calling nutzt das OpenAI-Tool-Call-Protokoll. Alibaba positioniert den Release als „auf dem Weg zu realen Agenten“ – also ein Modell für unordentliche Eingaben, die in einem Schritt Reasoning, Bilderkennung und einen Funktionsaufruf brauchen.
Die Plus-Stufe sind Closed Weights. Du kannst den Checkpoint nicht herunterladen und lokal ausführen (das Modell ist ohnehin zu groß für Consumer-Hardware). Alibaba veröffentlicht eine Open-Source-Variante Qwen/Qwen3.6-35B-A3B mit 262K Kontext standardmäßig, aber das ist ein separates Produkt. Für dieses Tutorial nutzen wir die gehostete API.
Qwen 3.6 Plus nimmt bis zu 1 Mio. Input-Tokens und gibt bis zu 65.536 Output-Tokens pro Call zurück. Eingabemodalitäten sind Text, Bild und Video. Tool-Aufrufe sind nativ über das OpenAI-Schema. Auf der Modellseite von OpenRouter findest du Preise, Latenz und Durchsatz für die gerouteten Backends.
Chain-of-Thought läuft standardmäßig bei jedem Call, und der Reasoning-Content wird getrennt vom Antworttext gestreamt. Ein neuer 3.6-Plus-Parameter hält frühere Reasoning-Traces über mehrere Turns an Nachrichten angehängt.
Alibaba empfiehlt das für Agent-Loops, bei denen spätere Turns von früheren Gedankengängen profitieren. Für One-Shot-Extraktion wie bei uns verschwenden diese Traces Tokens, daher schalten wir es ab.
Drei Benchmarks sind für dieses Tutorial wichtig:
Die ersten beiden sind der Grund, warum gescannte Rechnungen ein sinnvolles Ziel sind. Der dritte erklärt, warum wir erwarten können, dass das Modell ein Tool-Call-Protokoll ohne viel Prompt-Engineering befolgt.
Der Versionssprung von 3.5 Plus auf 3.6 Plus ist in vielen Metriken klein. Coding- und Reasoning-Benchmarks gewinnen ein paar Punkte. Die größere Änderung: Reasoning ist nicht mehr optional, sondern Standard. OCR und Objekterkennung haben sich am stärksten verbessert.
|
Fähigkeit |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Reasoning-Modus |
Standardmäßig an (abschaltbar mit |
Immer aktives CoT |
|
Kontextfenster |
Bis zu 1 Mio. Tokens |
1 Mio. Tokens (Standard) |
|
Multimodal |
Native Vision-Language |
Nativ + verbesserte OCR, Objekterkennung |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Reasoning über Turns |
— |
|
Wenn du 3.5 Plus bereits in Produktion laufen hast, bedeutet das Upgrade, den neuen preserve_thinking-Parameter zu übernehmen und zu beachten, dass Thinking jetzt bei jedem Call berechnet und abgerechnet wird. Die größten Zugewinne liegen in Agent-Loops und Dokumentenvision, genau das nutzen wir hier.
Du kannst auf zwei Arten auf das Modell zugreifen. Offiziell über das Alibaba Cloud Model Studio, das dir einen direkten Endpunkt unter https://dashscope-intl.aliyuncs.com/compatible-mode/v1 gibt. Alternativ OpenRouter, das zu Alibaba hinter einer einheitlichen Abrechnungsebene routet und die Anmeldung vereinfacht.
Wir nutzen OpenRouter, weil die Schlüsselerstellung schneller geht und es weniger Endpunkt-Besonderheiten gibt. Wenn du den direkten Weg willst, änderst du zwei Zeilen und machst weiter.
Alibaba Cloud Model Studio funktioniert für dieses Tutorial genauso gut wie OpenRouter. Es ändern sich nur die Base-URL und der Name der Umgebungsvariable.
Melde dich auf openrouter.ai mit einem Google- oder GitHub-Konto an. Die kostenlose Stufe ist ohne Kreditkarte verfügbar und reicht, um dieses Tutorial komplett durchzugehen. Wenn du später größere Volumina planst, bringen Guthaben eine höhere Durchsatzstufe und entfernen das modellbezogene Ratellimit.
Sobald du angemeldet bist, gehe zu openrouter.ai/settings/keys und erstelle einen Schlüssel. Vergib einen Namen wie qwen-tutorial, damit du ihn später wieder entziehen kannst.
Kopiere den Schlüssel jetzt, denn OpenRouter zeigt ihn nur einmal an. Speichere ihn dann in einer .env-Datei im Projektwurzelverzeichnis:
OPENROUTER_API_KEY=sk-or-v1-...Wir laden ihn im nächsten Schritt mit python-dotenv. Wenn du lieber direkt Alibaba Cloud nutzen willst, kommt der Schlüssel von modelstudio.console.alibabacloud.com und geht in DASHSCOPE_API_KEY.
Installiere die zwei Pakete für den ersten Test-Call:
pip install openai python-dotenvDas openai-Paket ist dasselbe SDK, das du auch mit dem OpenAI-Endpunkt verwenden würdest. Sowohl OpenRouter als auch Alibaba Cloud Model Studio implementieren die OpenAI Chat Completions API, daher muss der Client-Code nicht angepasst werden.
Erstelle eine Datei namens hello.py und prüfe die Verbindung:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Der Aufruf python hello.py sollte eine kurze Antwort ausgeben. Die First-Token-Latenz kann in der kostenlosen Stufe ein paar Sekunden dauern, weil das Modell zunächst einen Reasoning-Trace aufbaut, bevor es die sichtbare Antwort generiert.
Das Beispielprojekt ist eine Rechnungsverarbeitungs-Pipeline. Sie akzeptiert zwei Formate: Text-PDFs und gescannte JPGs. Jede Rechnung läuft mit aktiviertem Reasoning durch Qwen 3.6 Plus, und die extrahierten Felder kommen über einen Tool-Call zurück. Jede Rechnung durchläuft vier Phasen:
Eingabe decodieren (Bild base64-codieren oder jede PDF-Seite zuerst in ein Bild umwandeln)
Den Reasoning-Trace vom Modell streamen
Den Tool-Call in strukturiertes JSON parsen
Eine Zeile in results.csv schreiben
Der gesamte Code für diesen Abschnitt liegt in bextuychiev/qwen-invoice-pipeline-tutorial. Klone das Repo, um mitzugehen, oder nutze es als Referenz, während du deine eigene Version baust.
Lege ein Verzeichnis invoice-pipeline/ an und strukturiere es so:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtDie Trennung zwischen client.py und den Prozessoren hält die OpenRouter-Konfiguration in einer Datei. Wenn du später zu Alibaba Cloud wechselst, änderst du nur client.py und sonst nichts.
client.py kapselt den OpenAI-Client mit der richtigen Base-URL und der Modell-ID:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example liegt daneben, damit alle, die das Repo klonen, wissen, was sie eintragen müssen:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Das Begleit-Repo enthält sechs Beispielrechnungen aus drei Quellen:
Echte Firmenrechnungen sind wegen PII nicht öffentlich weiterverteilbar, daher nutzen wir diese. Die Ground-Truth-Summen sind im Repo-README gelistet, falls du die Pipeline dagegen prüfen willst.
Wenn du Qwen 3.5 genutzt hast, war CoT ein Toggle pro Call: enable_thinking=True innerhalb von extra_body. In 3.6 Plus läuft Reasoning standardmäßig, und der Parameter dient vor allem zum Abschalten. Reasoning-Tokens werden immer berechnet und abgerechnet, wenn Thinking aktiv ist – „always-on“ ist also eine Kostenentscheidung, kein Gratis-Feature.
Beim Streaming kommt delta.reasoning_content zuerst, dann folgt delta.content (oder bei uns delta.tool_calls).
Ein Minimalaufruf, der eine Rechnung extrahiert und den Reasoning-Trace beim Streamen ausgibt, sieht so aus:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Wir lesen die JPG-Bytes von der Platte, codieren sie in Base64 und packen das Ergebnis in eine data:-URI. Dieses Format erlaubt es dem OpenAI-Content-Block-Protokoll, Inline-Bilder ohne gehostete URL zu akzeptieren. Der image_url-Block nimmt die URI direkt, und das Modell sieht die Rechnung, als hättest du einen Link übergeben.
extra_body={"enable_thinking": True} leitet das enable_thinking-Flag an Qwen durch. Das OpenAI SDK kennt den Parameter nicht, daher ist extra_body der Weg für anbieterspezifische Optionen.
Beim Lauf auf invoice_04.jpg kommt die gestreamte Antwort als kurze Zusammenfassung zurück:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Kurz ist, was wir angefragt haben: Der System-Prompt sagte „summarize“ und nicht mehr. Wenn die Aufgabe wächst (Positionen, Kategorien, strukturierte Felder), wächst auch der Reasoning-Trace. Das sehen wir im nächsten Abschnitt: Dasselbe Modell auf demselben Bild verbringt dann den Großteil seines Output-Budgets mit Denken, bevor es antwortet.
Wenn du /no_think an den User-Prompt anhängst, ist das ein weicher Schalter, der CoT für diesen Call deaktiviert. Praktisch beim Debuggen, wenn du eine schnellere Antwort ohne Thinking willst.
Reasoning macht die Extraktion nachvollziehbar, aber der Output bleibt Freitext innerhalb eines Reasoning-Traces. Um jedes Mal strukturiertes, parsebares JSON zu bekommen, definieren wir ein Tool, extract_invoice, und setzen tool_choice="auto" mit einem System-Prompt, der das Modell anweist, das Tool immer aufzurufen.
Das Schema in tools.py beschreibt sechs Felder. Die äußere Form folgt dem Standardformat für OpenAI Function-Tools:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Die sechs Felder liegen unter parameters.properties. Skalare Felder (vendor, date, total, tax) nutzen einfache JSON-Schema-Typen. category verwendet ein enum, damit das Modell aus vier festen Werten wählt statt Labels zu erfinden. line_items ist das strukturierte Feld: ein Array von Objekten, jedes mit eigener required-Liste:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Das Schema hat zwei Ebenen von required. Die äußere Liste markiert, welche Top-Level-Felder in jeder Extraktion erscheinen müssen. Die Pro-Item-Liste markiert, welche Unterfelder in jeder Position vorhanden sein müssen. Das vollständige Schema liegt in tools.py im Begleit-Repo.
Die Argumente kommen als JSON-formatierter String in tool_calls[0].function.arguments zurück, nicht als geparstes Objekt, also musst du sie selbst mit json.loads parsen. Beim Streaming kommen die Argumente als Folge von Deltas, die du vor dem Parsen zusammenfügst.
Ein Stolperstein: Der Qwen-3.6-Plus-Endpunkt von OpenRouter unterstützt keine erzwungenen Tool-Calls. Wenn du tool_choice={"type": "function", "function": {"name": "extract_invoice"}} versuchst, kommt ein Fehler:
No endpoints found that support the provided 'tool_choice' valuePraktische Lösung: tool_choice="auto" nutzen und dich auf den System-Prompt verlassen:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Über alle sechs Beispielrechnungen im Begleit-Repo hinweg liefert dieser Prompt jedes Mal einen Tool-Call. Produktionscode sollte trotzdem den Ausnahmefall abfedern: finish_reason prüfen, verifizieren, dass tool_calls befüllt ist, und bei Bedarf mit schärferer Anweisung erneut versuchen. In Qwens eigenen Function-Calling-Dokumenten steht dasselbe: Tool-Calls sind nicht garantiert, und Produktionscode braucht einen Fallback.
Ein Nebeneffekt: Sobald der Prompt strukturierte Felder anfordert, füllt sich delta.reasoning_content mit einem langen Trace. Das Modell parst die Tabelle Zeile für Zeile, diskutiert europäische Dezimalnotation bei invoice_04.jpg und gleicht Positionssummen mit der Gesamtsumme ab. Reasoning-Tokens können bei solchen Prompts das Antwortbudget um den Faktor 10 oder mehr übersteigen.
Das ist der Preis von Always-on-CoT bei strukturierter Extraktion – und der Grund, warum preserve_thinking nur in Multi-Turn-Agent-Loops zahlt, wo ein späterer Turn den Trace liest. Wir machen One-Shot-Extraktion, also streamen wir den Trace ins Terminal und verwerfen ihn.
Für JPGs ist der Ablauf dreistufig:
Bildbytes von der Platte lesen
Base64-codieren
Das Ergebnis in einen image_url-Content-Block mit einer data:-URI setzen
PDFs brauchen einen zusätzlichen Schritt, da Qwens Vision-Pfad Bilder statt PDF-Dateien direkt akzeptiert. Wandle jede Seite mit pdf2image in ein PIL-Bild, und sende die Seiten als Liste von Bild-Content-Blöcken in derselben Nachricht.
Beide Pfade teilen sich denselben Modellaufruf, daher lebt der Call in processors/image.py und processors/pdf.py delegiert dorthin. Beginn mit den Imports (der oben genannte SYSTEM_PROMPT steht im selben Modul):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveDer Encoder macht aus einem JPG-Pfad die data:-URI, die die API erwartet:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Der gemeinsame Helper _call_with_images baut das User-Content-Array (Text + ein oder mehrere Bilder) und sendet den Streaming-Request. Aus dem Stream sammelt er zwei Dinge: den Reasoning-Trace und die Tool-Call-Argumente. Zuerst das Request-Setup:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Dann trennt die Stream-Schleife Reasoning-Deltas von Tool-Call-Argument-Deltas:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Der öffentliche Einstiegspunkt für JPGs ist ein Einzeiler, der diese Helper nutzt:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Der PDF-Prozessor wiederverwendet _call_with_images und ergänzt nur die Seiten-zu-Bild-Konvertierung:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image benötigt poppler. Installiere es mit:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsBei mehrseitigen PDFs schickst du jede Seite als eigenen Bildblock in derselben Nachricht. Qwen liest sie zusammen und produziert eine Extraktion – genau richtig für Rechnungen, bei denen die Summen auf Seite 2 stehen.
150 DPI halten den Rechnungstext gut lesbar, ohne die Nutzlast aufzublähen. Höher zu gehen macht die Anfrage größer, ohne in unseren Tests die Genauigkeit zu verbessern. Alibabas Vision-Dokumentation deckt unterstützte Formate und Obergrenzen ab.
main.py läuft durch sample_invoices/, routet jede Datei per Extension, ruft den passenden Prozessor auf und schreibt die kombinierten Ergebnisse in eine CSV. Zuerst Imports und Konstanten:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Die Hauptschleife iteriert das Musterverzeichnis sortiert, routet nach Dateiendung und faltet jede Extraktion in eine CSV-freundliche Zeile:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Zum Schluss die Zeilen auf die Platte schreiben und die Anzahl loggen:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Der Aufruf python main.py läuft die sechs Beispiele der Reihe nach. Jede Rechnung streamt zuerst den Dateinamen, dann den Reasoning-Trace und dann das extrahierte JSON, bevor die nächste dran ist:
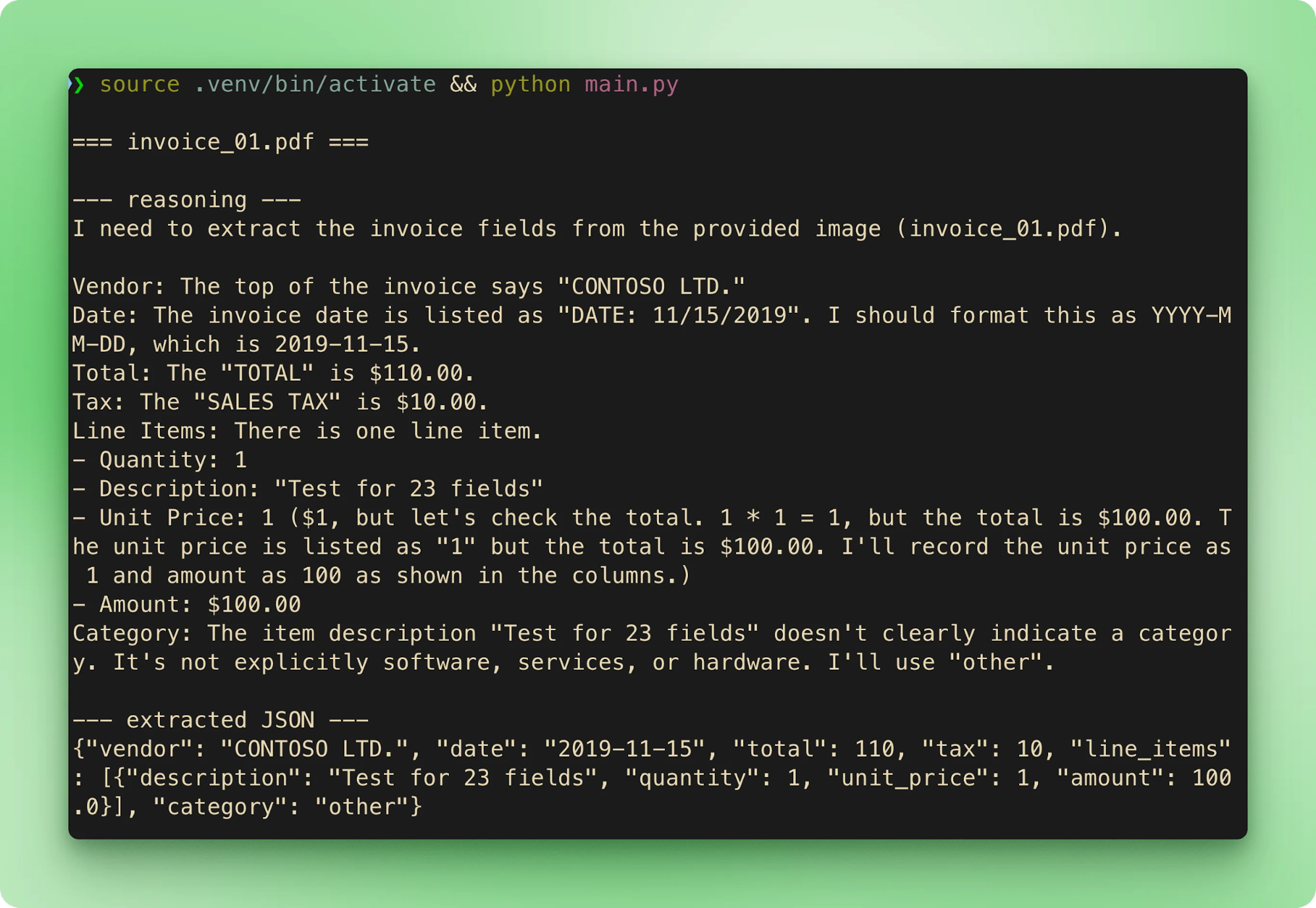
results.csv fasst jede Extraktion in einer Zeile pro Rechnung zusammen:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Die Summen stimmen bei allen sechs mit der Ground Truth überein. Die Latenz in der kostenlosen Stufe liegt bei 15 bis 40 Sekunden pro Rechnung. Der Großteil entfällt auf die Reasoning-Phase, bevor der Tool-Call zu streamen beginnt.
Ein paar Muster entscheiden darüber, ob eine Pipeline einmal funktioniert oder dauerhaft mit echten Rechnungen läuft.
Secrets nicht im Code halten. Das Muster mit .env und python-dotenv ist die Basis. Füge .env vor dem ersten Commit zu .gitignore hinzu, damit der Schlüssel nie im Repo landet.
Ratellimits mit exponentiellem Backoff behandeln. OpenRouter erzwingt providerbasierte Limits mit HTTP-429-Antworten. Die Bibliothek tenacity liefert eine dekoratorbasierte Implementierung, und das OpenAI-Cookbook-Muster für wait_random_exponential funktioniert unverändert.
Streamen, wenn Antworten lang werden. Always-on-CoT bläht Antworten standardmäßig auf. Nicht-streamende Calls bedeuten Warten auf den gesamten Reasoning-Block, bevor du etwas siehst. Streaming gibt frühes Feedback, hält die UI responsiv und lässt dich einen offensichtlich schief laufenden Request abbrechen.
preserve_thinking nur nutzen, wenn spätere Turns früheres Reasoning lesen. Für One-Shot-Extraktoren wie diese Pipeline sind das vergeudete Tokens. Für Multi-Turn-Agent-Loops (Tool-Calling-Ketten, Planung, Debugging-Workflows) existiert der Parameter für diesen Cross-Turn-Kontext. Alibabas Deep-Thinking-Dokumentation deckt außerdem thinking_budget ab, ein hartes Limit für Reasoning-Tokens pro Call.
Antworten der kostenlosen Stufe können für Training geloggt werden. Die Free-Tier-Routen von OpenRouter können über Provider laufen, die Prompts speichern. Damit ist sie ungeeignet für Rechnungen mit echten personenbezogenen Daten, Kundennamen oder Zahlungsdetails. Wechsle vor Echtdatenläufen auf eine bezahlte OpenRouter-Stufe (oder direkt zu Alibaba Cloud mit bezahltem Konto).
Kein Self-Hosting in der Plus-Stufe. Deployments mit Air-Gapping oder On-Prem können die gehostete API nicht verwenden. Die Open-Source-Variante Qwen3.6-35B-A3B ist für solche Fälle eine separate Option.
Time-to-first-token kann bei startendem Reasoning langsam sein. Setze Timeouts großzügig, 30 bis 60 Sekunden sind für Bildeingaben sinnvoll. Stelle sicher, dass dein Retry-Handling Read-Timeouts separat von 429ern behandelt.
Output ist nicht deterministisch, selbst mit Always-on-CoT. In Tests gegen die Beispiele des Begleit-Repos wurde invoice_01.pdf meist mit 610,00 $ extrahiert, aber mindestens einmal mit identischem Input auf 110,00 $ gedreht. Der Reasoning-Trace kam beide Male zur richtigen Antwort, aber das finale Tool-Call-Argument unterschied sich. Zwei Gegenmaßnahmen: temperature niedrig setzen (0,1 bis 0,2 für reine Extraktion) und gegen Ground Truth validieren oder bei hoher Genauigkeitsanforderung einen zweiten Durchlauf anhängen.
Von hier ist es nur ein kleiner Schritt, die Pipeline in ein Agenten-Framework zu packen. Die Tool-Call-Schleife, der Streaming-Parser und der CSV-Writer sind genau die Bausteine, die ein Agenten-Framework über mehrere Turns orchestriert. Der DataCamp-Kurs Developing LLM Applications with LangChain führt diese Muster mit Speicher, State und Multi-Tool-Routing durch.
Agentic AI-Kurse
Lernpfad
Lernpfad
Kurs
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
Tutorial
Derrick Mwiti