
Program
Dasar-Dasar Agen Kecerdasan Buatan
6 Hr
Alibaba merilis Qwen 3.6 Plus pada April 2026. Spesifikasinya: SWE-bench Verified 78,8, jendela konteks 1 juta token secara default, input multimodal native, dan penalaran selalu aktif. Bagi pengembang Python, yang menarik bukan tabel benchmarknya, melainkan bahwa model ini hanya tersedia lewat API dan dapat digunakan dengan paket OpenAI biasa hanya dengan mengganti base URL.
Dalam tutorial ini, kita akan menggunakan tiga fitur utamanya sekaligus: penalaran chain-of-thought, pemanggilan tool untuk output terstruktur, dan visi pada faktur hasil pemindaian. Hasilnya adalah pipeline pemrosesan faktur kecil yang membaca PDF dan JPG, menampilkan proses penalarannya, dan mengembalikan JSON tervalidasi yang bisa Anda tulis ke CSV.
Anda memerlukan Python 3.10 atau lebih baru dan familiar dengan membuat panggilan API. Tidak perlu GPU, tidak perlu mengunduh model, tidak perlu self-hosting. Kita akan mengakses Qwen 3.6 Plus melalui OpenRouter, sehingga pendaftaran cukup sekali, dan OpenAI SDK dapat digunakan tanpa perubahan.
Saya sangat menyarankan Anda juga melihat tutorial kami tentang Fine-Tuning Qwen 3.6, versi bobot-terbuka terbaru dari Qwen. Jika Anda tertarik pada model pesaing, pastikan membaca panduan kami tentang DeepSeek v4, GPT-5.5 dari OpenAI, dan Claude Opus 4.7 dari Anthropic.
Qwen 3.6 Plus adalah model flagship Alibaba pada April 2026. Tulang punggungnya adalah gabungan linear-attention dan sparse mixture-of-experts, penalaran berjalan secara default, dan teks, gambar, serta video melewati API yang sama.
Function calling menggunakan protokol tool-call OpenAI. Alibaba memposisikan rilis ini sebagai "menuju agen dunia nyata," artinya satu model untuk input berantakan yang membutuhkan penalaran, pembacaan gambar, dan pemanggilan fungsi dalam satu langkah.
Tingkat Plus adalah bobot tertutup. Anda tidak bisa mengunduh checkpoint dan menjalankannya di perangkat sendiri (modelnya terlalu besar untuk hardware konsumen). Alibaba memublikasikan varian open-source Qwen/Qwen3.6-35B-A3B dengan konteks default 262K, tetapi itu produk terpisah. Untuk tutorial ini, kita menggunakan API yang di-host.
Qwen 3.6 Plus menerima hingga 1 juta token input dan mengembalikan hingga 65.536 token output per panggilan. Modality input mencakup teks, gambar, dan video. Pemanggilan tool bersifat native melalui skema OpenAI. Halaman model OpenRouter mencantumkan harga, latensi penyedia, dan throughput untuk backend yang dirutekan.
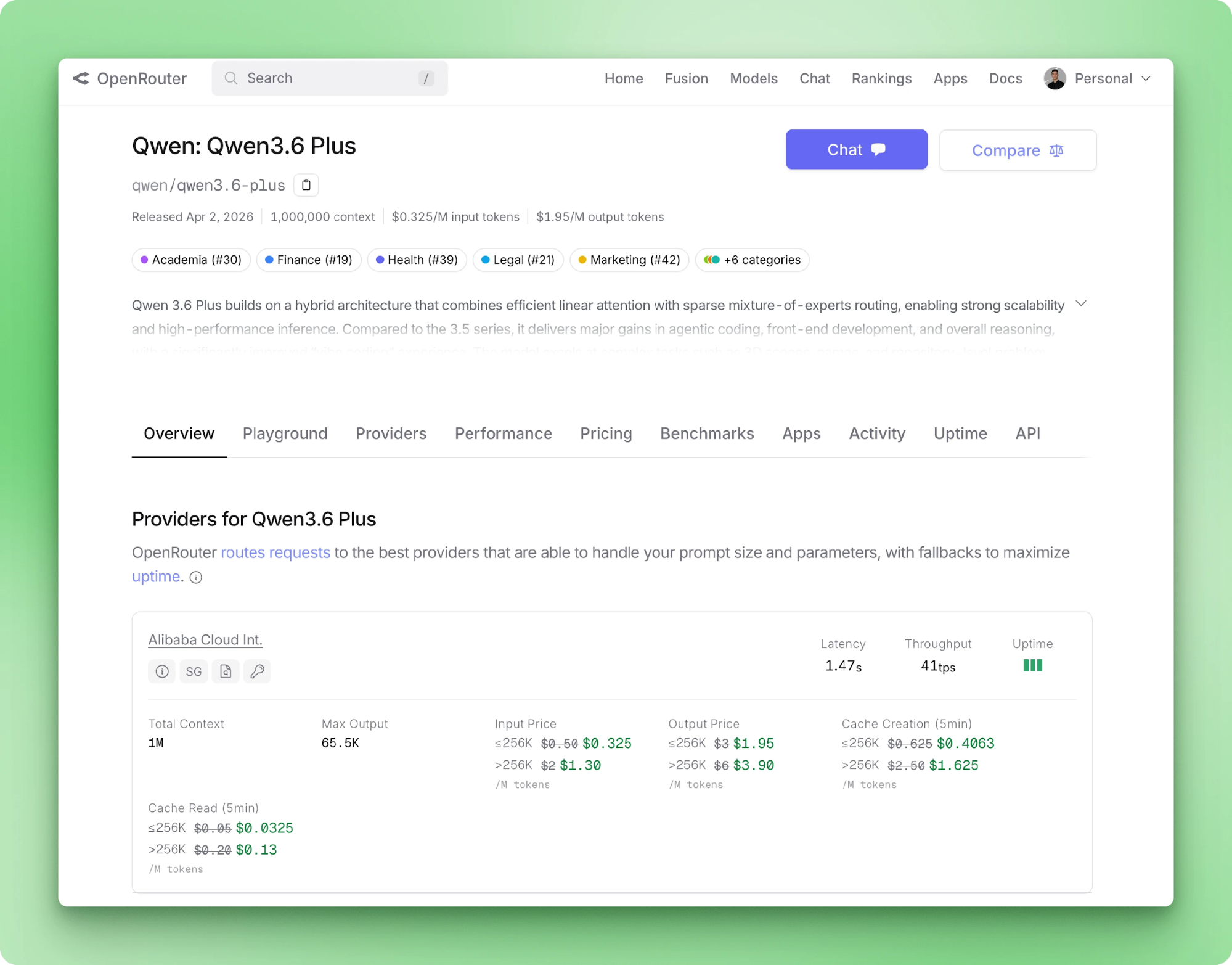
Chain-of-thought berjalan secara default pada setiap panggilan, dan konten penalaran mengalir kembali pada field terpisah dari jawaban. Parameter baru 3.6 Plus menjaga jejak penalaran sebelumnya tetap terlampir pada pesan lintas giliran.
Alibaba merekomendasikannya untuk loop agen di mana giliran berikutnya diuntungkan oleh chain-of-thought sebelumnya. Untuk ekstraksi satu kali seperti milik kita, mempertahankan jejak hanya memboroskan token, jadi kita menonaktifkannya.
Tiga skor benchmark yang relevan untuk tutorial ini:
Dua yang pertama adalah alasan mengapa faktur hasil pemindaian menjadi target yang masuk akal. Yang ketiga menjelaskan mengapa kita dapat berharap model mengikuti protokol tool-call tanpa prompt engineering berat.
Lompatan versi dari 3.5 Plus ke 3.6 Plus kecil pada sebagian besar metrik. Benchmark coding dan penalaran naik beberapa poin. Perubahan lebih besar adalah penalaran beralih dari sakelar menjadi default. OCR dan pelokalan objek yang paling meningkat.
|
Kemampuan |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Mode penalaran |
Aktif secara default (bisa dinonaktifkan dengan |
CoT selalu aktif |
|
Jendela konteks |
Hingga 1 juta token |
1 juta token (default) |
|
Multimodal |
Vision-language native |
Native + OCR dan pelokalan objek meningkat |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Penalaran lintas giliran |
— |
|
Jika Anda telah menjalankan 3.5 Plus di produksi, peningkatan ini berarti mengadopsi preserve_thinking yang baru dan mencatat bahwa penalaran kini ditagihkan pada setiap panggilan. Keuntungan utama ada pada loop agen dan visi dokumen, yang menjadi fokus tutorial ini.
Anda bisa mengakses model dengan dua cara. Cara resmi adalah Alibaba Cloud Model Studio, yang memberikan endpoint langsung di https://dashscope-intl.aliyuncs.com/compatible-mode/v1. Opsi lain adalah OpenRouter, yang merutekan ke Alibaba di belakang lapisan penagihan terpadu dan proses pendaftaran yang lebih sederhana.
Tutorial ini menggunakan OpenRouter karena alur pembuatan key lebih cepat dan quirks endpoint lebih sedikit. Jika Anda ingin jalur langsung, ubah dua baris dan lanjutkan.
Alibaba Cloud Model Studio sama baiknya dengan OpenRouter untuk tutorial ini. Satu-satunya yang berubah adalah base URL dan nama variabel lingkungan.
Daftar di openrouter.ai dengan akun Google atau GitHub. Paket gratis tersedia tanpa kartu kredit, cukup untuk mengikuti tutorial ini dari awal hingga akhir. Jika Anda berencana menjalankan volume lebih besar nanti, menambahkan kredit memberi Anda tier throughput lebih tinggi dan menghapus batas laju per model.
Setelah masuk, buka openrouter.ai/settings/keys dan buat key. Beri label seperti qwen-tutorial agar mudah dicabut nanti.
Salin nilai key sekarang, karena OpenRouter hanya menampilkannya sekali. Lalu simpan di file .env di root proyek Anda:
OPENROUTER_API_KEY=sk-or-v1-...Kita akan memuatnya dengan python-dotenv di bagian berikutnya. Jika Anda lebih suka menggunakan Alibaba Cloud langsung, key berasal dari modelstudio.console.alibabacloud.com dan disimpan di DASHSCOPE_API_KEY sebagai gantinya.
Instal dua paket yang kita perlukan untuk panggilan verifikasi pertama:
pip install openai python-dotenvPaket openai adalah SDK yang sama yang akan Anda gunakan dengan endpoint OpenAI. Baik OpenRouter maupun Alibaba Cloud Model Studio mengimplementasikan OpenAI Chat Completions API, sehingga kode klien tidak perlu diubah.
Buat file bernama hello.py dan verifikasi koneksi:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Menjalankan python hello.py akan mencetak balasan singkat. Latensi token pertama di paket gratis bisa memakan beberapa detik karena model membangun jejak penalaran sebelum menghasilkan jawaban yang terlihat.
Proyek contoh ini adalah pipeline pemrosesan faktur. Ia menerima dua format: PDF teks dan JPG hasil pemindaian. Setiap faktur dijalankan melalui Qwen 3.6 Plus dengan penalaran aktif, dan field yang diekstrak dikembalikan melalui pemanggilan tool. Setiap faktur melewati empat tahap:
Dekode input (base64-encode gambar, atau konversi setiap halaman PDF menjadi gambar terlebih dahulu)
Stream jejak penalaran dari model
Parse pemanggilan tool menjadi JSON terstruktur
Tulis satu baris ke results.csv
Seluruh kode untuk bagian ini ada di bextuychiev/qwen-invoice-pipeline-tutorial. Clone untuk mengikuti langkah, atau gunakan sebagai referensi saat Anda membangun versi Anda sendiri.
Buat direktori invoice-pipeline/ dan atur strukturnya seperti ini:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtPemisahan antara client.py dan processor menjaga konfigurasi OpenRouter dalam satu file. Jika nantinya Anda beralih ke Alibaba Cloud, cukup mengedit client.py dan tidak ada yang lain.
client.py membungkus klien OpenAI dengan base URL yang benar dan ID model:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example diletakkan berdampingan agar siapa pun yang meng-clone repo tahu apa yang perlu diisi:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Repo pendamping menyertakan enam contoh faktur dari tiga sumber:
Faktur perusahaan asli tidak dapat didistribusikan ulang secara publik karena PII, jadi kita menggunakan ini sebagai gantinya. Total ground-truth tercantum di README repo jika Anda ingin memeriksa pipeline terhadapnya.
Jika Anda pernah menggunakan Qwen 3.5, CoT adalah sakelar per panggilan: enable_thinking=True di dalam extra_body. Pada 3.6 Plus, penalaran berjalan secara default, dan parameter ini lebih untuk mematikannya. Token penalaran selalu ditagihkan saat thinking aktif, yang membuat "selalu aktif" menjadi keputusan biaya, bukan fitur gratis.
Saat Anda melakukan streaming respons, delta.reasoning_content tiba lebih dulu, lalu delta.content menyusul (atau delta.tool_calls, dalam kasus kita).
Panggilan minimal yang mengekstrak faktur dan mencetak jejak penalaran saat streaming tampak seperti ini:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Kita membaca byte JPG dari disk, melakukan base64-encode, dan membungkus hasilnya dalam URI data:. Format itu memungkinkan protokol content-block OpenAI menerima gambar inline tanpa URL yang di-host. Blok image_url menerima URI secara langsung, dan model melihat faktur seolah Anda mengirim tautan.
extra_body={"enable_thinking": True} meneruskan flag enable_thinking ke Qwen. OpenAI SDK tidak mengenal parameter ini, jadi extra_body adalah cara untuk mengirim opsi khusus penyedia.
Saat Anda menjalankannya pada invoice_04.jpg, jawaban yang di-stream kembali berupa ringkasan singkat:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Singkat sesuai yang diminta: sistem prompt mengatakan "summarize" dan tidak lebih. Saat tugas bertambah (item baris, kategori, field terstruktur), jejak penalaran ikut memanjang. Kita akan melihatnya di bagian berikut, di mana model yang sama pada gambar yang sama menghabiskan sebagian besar anggaran output untuk berpikir sebelum menjawab.
Menambahkan /no_think ke prompt pengguna adalah sakelar lunak yang menonaktifkan CoT untuk panggilan itu. Berguna saat debugging dan Anda menginginkan respons lebih cepat tanpa thinking.
Penalaran membuat ekstraksi dapat dibaca, tetapi outputnya masih berupa teks bebas di dalam jejak penalaran. Untuk selalu mendapatkan JSON terstruktur yang bisa di-parse, kita mendefinisikan satu tool, extract_invoice, dan mengatur tool_choice="auto" dengan sistem prompt yang menginstruksikan model untuk selalu memanggil tool tersebut.
Skema dalam tools.py menjelaskan enam field. Bentuk luarnya mengikuti format standar function-tool OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Enam field berada di dalam parameters.properties. Field skalar (vendor, date, total, tax) menggunakan tipe JSON Schema biasa. category menggunakan enum sehingga model memilih dari empat nilai tetap alih-alih menciptakan label. line_items adalah field terstruktur, berupa array objek, masing-masing dengan daftar required sendiri:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Skema memiliki dua tingkat required. Daftar luar menandai field tingkat atas yang wajib muncul pada setiap ekstraksi. Daftar per item menandai sub-field yang wajib ada pada setiap baris item. Skema lengkap ada di tools.py di repo pendamping.
Argumen kembali sebagai string berformat JSON di dalam tool_calls[0].function.arguments, bukan objek yang sudah di-parse, jadi Anda perlu memanggil json.loads sendiri. Saat streaming, argumen datang sebagai rangkaian delta yang Anda gabungkan sebelum parsing.
Satu catatan: endpoint Qwen 3.6 Plus OpenRouter tidak mendukung pemanggilan tool secara paksa. Jika Anda mencoba tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, permintaan akan mengembalikan error:
No endpoints found that support the provided 'tool_choice' valueSolusi praktisnya adalah menggunakan tool_choice="auto" dan mengandalkan sistem prompt:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Di keenam contoh faktur pada repo pendamping, prompt ini selalu menghasilkan pemanggilan tool. Kode produksi tetap harus menjaga kasus pengecualian: periksa finish_reason, verifikasi tool_calls terisi, dan coba ulang dengan instruksi yang lebih tegas jika tidak. Dokumentasi function-calling Qwen juga menyebutkan hal yang sama. Generasi tool-call tidak dijamin, dan kode produksi memerlukan fallback.
Satu efek samping: begitu prompt meminta field terstruktur, delta.reasoning_content terisi jejak yang panjang. Model mem-parsing tabel baris demi baris, mempertimbangkan notasi desimal Eropa pada invoice_04.jpg, dan mencocokkan jumlah item baris dengan total. Token penalaran bisa melebihi token jawaban hingga 10x atau lebih pada jenis prompt ini.
Itulah biaya CoT selalu aktif pada ekstraksi terstruktur, yang sebabnya preserve_thinking hanya menguntungkan pada loop agen multi-giliran di mana giliran berikutnya membaca jejak tersebut. Kita melakukan ekstraksi satu kali, jadi jejaknya di-stream ke terminal, lalu kita buang.
Untuk JPG, alurnya tiga langkah:
Baca byte gambar dari disk
Lakukan base64-encode
Masukkan hasilnya ke blok konten image_url dengan URI data:
PDF memerlukan satu langkah ekstra karena jalur visi Qwen menerima gambar, bukan file PDF secara langsung. Konversi setiap halaman menjadi gambar PIL dengan pdf2image, lalu kirim halaman-halaman sebagai daftar blok konten gambar dalam pesan yang sama.
Kedua jalur berbagi panggilan model yang sama, jadi panggilan ditempatkan di processors/image.py dan processors/pdf.py mendelegasikannya. Mulailah dengan impor (SYSTEM_PROMPT di atas berada di modul yang sama):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveEncoder mengubah path JPG menjadi URI data: yang diharapkan API:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Helper bersama _call_with_images membangun array user-content (teks + satu atau lebih gambar) dan mengirim permintaan streaming. Dari stream, ia mengumpulkan dua data: jejak penalaran dan argumen pemanggilan tool. Setup permintaan ada terlebih dahulu:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Lalu loop stream memisahkan delta penalaran dari delta argumen pemanggilan tool:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Entry point publik untuk JPG adalah one-liner yang menggunakan helper tersebut:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Processor PDF menggunakan kembali _call_with_images dan hanya menambahkan konversi halaman ke gambar:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image memerlukan poppler terpasang. Instal dengan:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsUntuk PDF multi-halaman, kirim setiap halaman sebagai blok gambar tersendiri dalam pesan yang sama. Qwen membacanya bersama dan menghasilkan satu ekstraksi, yang memang Anda inginkan untuk faktur yang totalnya muncul di halaman 2.
150 DPI menjaga teks faktur tetap terbaca tanpa membengkakkan payload. Lebih tinggi membuat permintaan lebih besar tanpa meningkatkan akurasi pada pengujian terhadap sampel ini. Dokumentasi visi Alibaba membahas format yang didukung dan batas atas.
main.py menelusuri sample_invoices/, merutekan setiap file berdasarkan ekstensi, memanggil processor yang tepat, dan menulis hasil gabungan ke CSV. Impor dan konstanta terlebih dahulu:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Loop utama mengiterasi direktori sampel secara terurut, merutekan berdasarkan ekstensi file, dan meratakan setiap ekstraksi menjadi baris yang ramah CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Terakhir, tulis baris-baris ke disk dan catat jumlahnya:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Menjalankan python main.py akan menelusuri enam sampel secara berurutan. Setiap faktur men-stream nama filenya, lalu jejak penalaran, kemudian JSON hasil ekstraksi, sebelum beralih ke berikutnya:
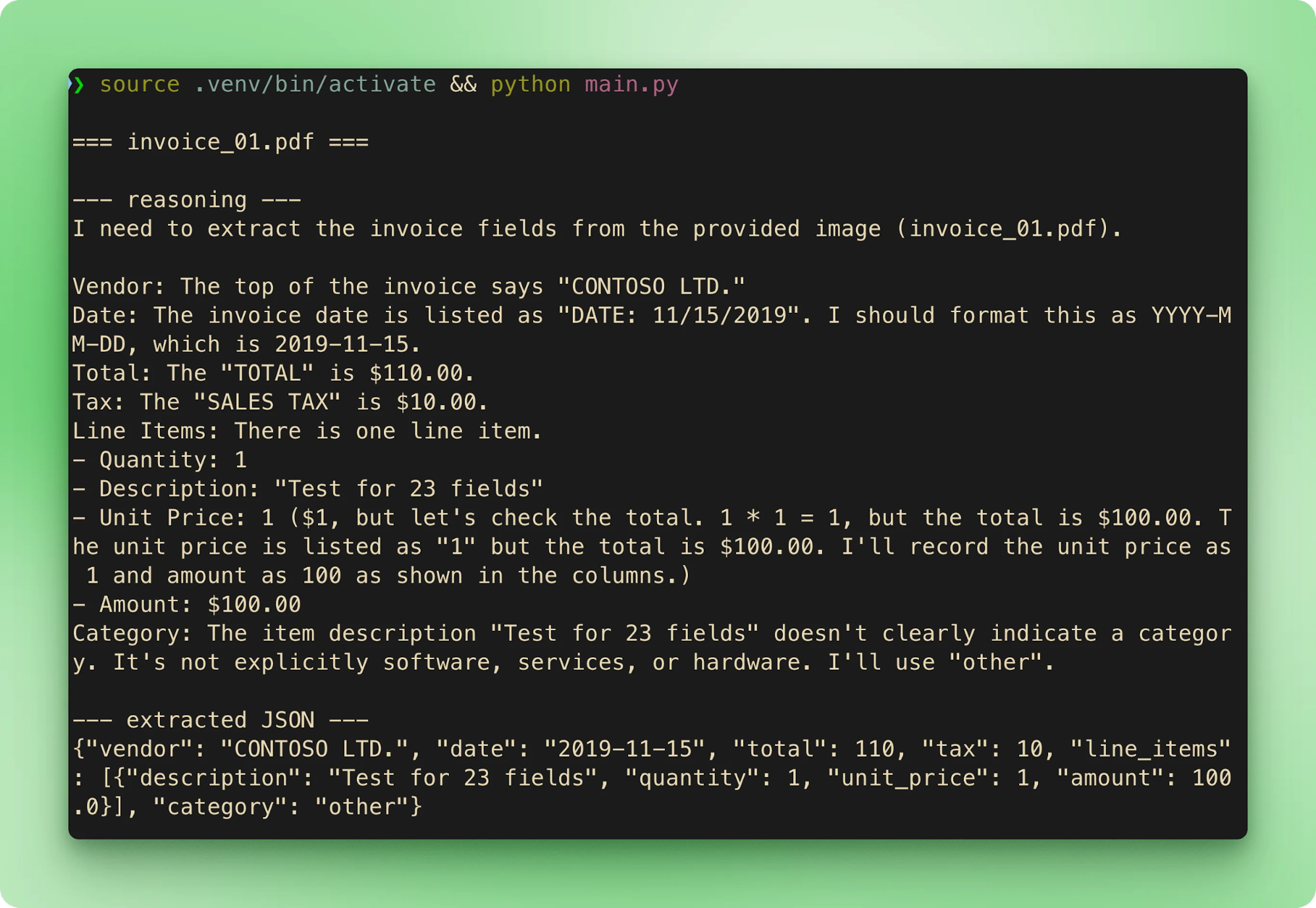
results.csv menggabungkan setiap ekstraksi menjadi satu baris per faktur:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Total sesuai dengan ground truth pada semua enam sampel. Latensi pada tier gratis berkisar 15 hingga 40 detik per faktur. Sebagian besar waktu tersebut adalah fase penalaran sebelum pemanggilan tool mulai streaming.
Beberapa pola membuat perbedaan antara pipeline yang hanya sekali jalan dengan yang terus bekerja pada faktur nyata.
Jauhkan rahasia dari kode. Pola .env dan python-dotenv yang kita gunakan adalah baseline. Tambahkan .env ke .gitignore sebelum commit pertama agar key tidak pernah masuk ke repo.
Tangani rate limit dengan exponential backoff. OpenRouter memberlakukan batas per penyedia dengan respons HTTP 429. Pustaka tenacity menyediakan implementasi berbasis dekorator, dan pola cookbook OpenAI untuk wait_random_exponential berfungsi tanpa perubahan.
Gunakan streaming saat respons akan panjang. CoT selalu aktif memperpanjang respons secara default. Panggilan non-streaming berarti menunggu seluruh blok penalaran sebelum melihat apa pun. Streaming memberi umpan balik awal, menjaga UI responsif, dan memungkinkan Anda membatalkan permintaan yang jelas-jelas melenceng.
Gunakan preserve_thinking hanya saat giliran selanjutnya membaca penalaran sebelumnya. Untuk ekstraktor satu kali seperti pipeline ini, itu pemborosan token. Untuk loop agen multi-giliran (rantai pemanggilan tool, tugas perencanaan, alur debugging), parameter ini ada untuk konteks lintas giliran. Dokumentasi deep thinking Alibaba juga membahas thinking_budget, batas keras token penalaran per panggilan.
Respons tier gratis dapat dicatat untuk pelatihan. Tier gratis OpenRouter merutekan melalui penyedia yang dapat menyimpan prompt. Ini tidak cocok untuk faktur dengan PII nyata, nama pelanggan, atau detail pembayaran. Beralihlah ke tier berbayar OpenRouter (atau langsung ke Alibaba Cloud dengan akun berbayar) sebelum data nyata melewati pipeline.
Tidak ada self-hosting pada tier Plus. Deployment yang membutuhkan air-gapping atau on-prem tidak bisa menggunakan API yang di-host. Varian open-source Qwen3.6-35B-A3B adalah opsi terpisah yang layak dipertimbangkan untuk kasus tersebut.
Waktu ke token pertama bisa lambat saat penalaran dimulai. Tetapkan timeout dengan longgar, 30 hingga 60 detik wajar untuk input gambar. Pastikan logika retry Anda menangani read timeout secara terpisah dari 429.
Output tidak deterministik meski dengan CoT selalu aktif. Dalam pengujian terhadap sampel di repo pendamping, invoice_01.pdf terekstrak $610,00 pada sebagian besar run. Pada setidaknya satu run ulang dengan input identik, nilainya berubah menjadi $110,00. Jejak penalaran mencapai jawaban benar pada keduanya, tetapi argumen pemanggilan tool akhir berbeda. Dua mitigasi: atur temperature rendah (0,1 hingga 0,2 untuk ekstraksi murni), dan validasi terhadap ground truth atau gunakan lintasan kedua saat akurasi sangat penting hingga layak menambah panggilan.
Dari sini, membungkus pipeline dalam kerangka agen tinggal selangkah lagi. Loop pemanggilan tool, parser streaming, dan penulis CSV adalah primitif yang sama yang diorkestrasi kerangka agen lintas beberapa giliran. Kursus DataCamp Developing LLM Applications with LangChain membahas pola-pola tersebut dengan memori, state, dan multi-tool routing.
Kursus AI Agenik
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
