
Programma
Nozioni di base sugli agenti AI
6 h
Alibaba ha rilasciato Qwen 3.6 Plus ad aprile 2026. In breve: SWE-bench Verified a 78,8, finestra di contesto da 1M token di default, input multimodali nativi e reasoning sempre attivo. Per chi sviluppa in Python, la parte interessante non è la tabella dei benchmark: il modello è solo via API e funziona con il pacchetto OpenAI standard cambiando la base URL.
In questo tutorial useremo tre delle sue funzioni principali in un unico progetto: chain-of-thought reasoning, tool calling per output strutturato e visione su fatture scansionate. Il risultato è una piccola pipeline di elaborazione fatture che legge PDF e JPG, mostra il suo ragionamento e restituisce JSON validato che puoi scrivere in un CSV.
Ti serve Python 3.10 o più recente e dimestichezza con le chiamate API. Niente GPU, niente download di modelli, niente self-hosting. Accederemo a Qwen 3.6 Plus tramite OpenRouter, così la registrazione richiede un solo form e l’SDK OpenAI funziona senza modifiche.
Ti consiglio anche di dare un'occhiata al nostro tutorial su Fine-Tuning di Qwen 3.6, l’ultima versione open-weights di Qwen. Se ti interessano i modelli concorrenti, leggi le nostre guide su DeepSeek v4, GPT-5.5 di OpenAI e Claude Opus 4.7 di Anthropic.
Qwen 3.6 Plus è il modello di punta di Alibaba di aprile 2026. Il backbone è un ibrido attenzione lineare + sparse mixture-of-experts, il reasoning gira di default e testo, immagini e video passano tutti per la stessa API.
Il function calling usa il protocollo di tool-call di OpenAI. Alibaba posiziona il rilascio come "verso agenti reali", cioè un modello unico per input disordinati che richiedono ragionamento, lettura di immagini e una function call in un solo passaggio.
Il tier Plus ha pesi chiusi. Non puoi scaricare il checkpoint ed eseguirlo sull’hardware locale (il modello è troppo grande per l’hardware consumer comunque). Alibaba pubblica una variante open-source Qwen/Qwen3.6-35B-A3B con contesto di default a 262K, ma è un prodotto separato. Per questo tutorial useremo l’API hosted.
Qwen 3.6 Plus accetta fino a 1M token in input e restituisce fino a 65.536 token in output per chiamata. Le modalità di input includono testo, immagine e video. Il tool calling è nativo tramite lo schema OpenAI. La pagina del modello di OpenRouter elenca prezzi, latenza del provider e throughput per i backend instradati.
Il chain-of-thought gira di default a ogni chiamata, e il contenuto di reasoning viene trasmesso in streaming su un campo separato rispetto alla risposta. Un nuovo parametro di 3.6 Plus mantiene i reasoning trace precedenti attaccati ai messaggi tra i turni.
Alibaba lo consiglia per agent loop in cui i turni successivi beneficiano delle catene di pensiero precedenti. Per l’estrazione one-shot come la nostra, conservare la traccia spreca token, quindi la disabilitiamo.
Tre benchmark contano per questo tutorial:
I primi due sono il motivo per cui le fatture scansionate sono un obiettivo sensato. Il terzo è il motivo per cui possiamo aspettarci che il modello segua un protocollo di tool-call senza pesante prompt engineering.
Il salto di versione da 3.5 Plus a 3.6 Plus è piccolo su molte metriche. Coding e reasoning guadagnano qualche punto. Il cambiamento maggiore è che il reasoning passa da interruttore a default. OCR e localizzazione oggetti migliorano di più.
|
Capacità |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Modalità reasoning |
Attiva di default (disattivabile con |
CoT sempre attivo |
|
Finestra di contesto |
Fino a 1M token |
1M token (default) |
|
Multimodale |
Vision-language nativa |
Nativa + OCR migliorato, localizzazione oggetti |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Reasoning tra i turni |
— |
Parametro |
Se stai gestendo 3.5 Plus in produzione, l’upgrade significa adottare il nuovo parametro preserve_thinking e considerare che il thinking ora viene fatturato a ogni chiamata. I principali benefici sono negli agent loop e nella visione dei documenti, che è ciò che usiamo in questo tutorial.
Puoi accedere al modello in due modi. Quello ufficiale è Alibaba Cloud Model Studio, che ti dà un endpoint diretto su https://dashscope-intl.aliyuncs.com/compatible-mode/v1. L’altro è OpenRouter, che instrada verso Alibaba dietro un livello di billing unificato e una registrazione più semplice.
Il tutorial usa OpenRouter perché la creazione della chiave è più rapida e le particolarità dell’endpoint sono minori. Se vuoi la via diretta, cambia due righe e continua.
Alibaba Cloud Model Studio funziona altrettanto bene di OpenRouter per questo tutorial. Le uniche cose che cambiano sono la base URL e il nome della variabile d’ambiente.
Registrati su openrouter.ai con un account Google o GitHub. Il piano gratuito è disponibile senza carta di credito ed è sufficiente per seguire questo tutorial dall’inizio alla fine. Se poi prevedi volumi maggiori, aggiungere crediti ti assegna un tier con throughput più alto e rimuove il rate cap per modello.
Una volta effettuato l’accesso, vai su openrouter.ai/settings/keys e crea una chiave. Etichettala tipo qwen-tutorial così potrai revocarla in seguito.
Copia ora il valore della chiave, perché OpenRouter lo mostra solo una volta. Poi salvalo in un file .env nella root del progetto:
OPENROUTER_API_KEY=sk-or-v1-...Lo caricheremo con python-dotenv nella prossima sezione. Se preferisci usare direttamente Alibaba Cloud, la chiave arriva da modelstudio.console.alibabacloud.com e va in DASHSCOPE_API_KEY al suo posto.
Installa i due pacchetti necessari per la prima chiamata di verifica:
pip install openai python-dotenvIl pacchetto openai è lo stesso SDK che useresti con l’endpoint di OpenAI. Sia OpenRouter sia Alibaba Cloud Model Studio implementano la Chat Completions API di OpenAI, quindi il client non va cambiato.
Crea un file chiamato hello.py e verifica la connessione:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Eseguire python hello.py dovrebbe stampare una breve risposta. La latenza del primo token sul piano gratuito può richiedere qualche secondo perché il modello costruisce una traccia di reasoning prima di generare la risposta visibile.
Il progetto di esempio è una pipeline di elaborazione fatture. Accetta due formati: PDF testuali e JPG scansionati. Ogni fattura passa per Qwen 3.6 Plus con reasoning attivo, e i campi estratti tornano tramite una tool call. Ogni fattura attraversa quattro fasi:
Decodifica dell’input (codifica base64 dell’immagine o conversione delle pagine PDF in immagini)
Streaming della traccia di reasoning dal modello
Parsing della tool call in JSON strutturato
Scrittura di una riga in results.csv
Tutto il codice di questa sezione è su bextuychiev/qwen-invoice-pipeline-tutorial. Clonalo per seguire passo passo o usalo come riferimento mentre costruisci la tua versione.
Crea una directory invoice-pipeline/ e organizzala così:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtLa divisione tra client.py e i processor mantiene la configurazione di OpenRouter in un unico file. Se in seguito passi ad Alibaba Cloud, modifichi client.py e nient’altro.
client.py incapsula il client OpenAI con la base URL corretta e l’ID del modello:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example va accanto così chi clona il repo sa cosa inserire:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Il repo di supporto include sei fatture di esempio da tre fonti:
Le fatture di aziende reali non sono redistribuibili pubblicamente per via dei dati personali, quindi usiamo queste. I totali di riferimento sono indicati nel README del repo se vuoi confrontare la pipeline.
Se hai usato Qwen 3.5, il CoT era un toggle per chiamata: enable_thinking=True dentro extra_body. Su 3.6 Plus, il reasoning gira di default e il parametro esiste soprattutto per spegnerlo. I token di reasoning sono sempre fatturati quando il thinking è attivo, quindi "sempre attivo" è una decisione di costo, non una feature gratuita.
Quando effettui lo streaming di una risposta, delta.reasoning_content arriva per primo, poi segue delta.content (o delta.tool_calls, nel nostro caso).
Una chiamata minimale che estrae una fattura e stampa la traccia di reasoning mentre arriva in streaming è così:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Leggiamo i byte del JPG dal disco, li codifichiamo in base64 e incapsuliamo il risultato in un URI data:. Questo formato consente al protocollo OpenAI dei content block di accettare immagini inline senza un URL ospitato. Il blocco image_url prende direttamente l’URI e il modello vede la fattura come se avessi passato un link.
extra_body={"enable_thinking": True} inoltra il flag enable_thinking a Qwen. L’SDK OpenAI non conosce il parametro, quindi extra_body è il modo per passare opzioni specifiche del provider.
Eseguendolo su invoice_04.jpg, la risposta in streaming torna come un breve riassunto:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Breve è quello che abbiamo chiesto: il system prompt diceva "riassumi" e nulla di più. Quando il compito cresce (voci di dettaglio, categorie, campi strutturati), cresce anche la traccia di reasoning. Lo vedremo nella prossima sezione, dove lo stesso modello sulla stessa immagine spende gran parte del budget di output pensando prima di rispondere.
Aggiungere /no_think al prompt utente è un interruttore soft che disattiva il CoT per quella chiamata. Utile in debug quando vuoi una risposta più rapida senza thinking.
Il reasoning rende l’estrazione leggibile, ma l’output resta testo libero dentro una traccia di reasoning. Per ottenere sempre JSON strutturato e parsabile, definiamo un tool, extract_invoice, e impostiamo tool_choice="auto" con un system prompt che istruisce il modello a chiamare sempre il tool.
Lo schema in tools.py descrive sei campi. La struttura esterna segue il formato standard dei function tool di OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}I sei campi si trovano dentro parameters.properties. I campi scalari (vendor, date, total, tax) usano i tipi JSON Schema semplici. category usa un enum così il modello sceglie tra quattro valori fissi invece di inventare etichette. line_items è il campo strutturato: un array di oggetti, ognuno con la propria lista di required:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Lo schema ha due livelli di required. La lista esterna indica quali campi top-level devono comparire in ogni estrazione. La lista per elemento indica quali sotto-campi devono comparire su ogni riga. Lo schema completo è in tools.py nel repo di supporto.
Gli argomenti tornano come stringa formattata JSON dentro tool_calls[0].function.arguments, non come oggetto già parsato, quindi devi chiamare json.loads tu. In streaming, gli argomenti arrivano come una sequenza di delta che concatenai prima di fare il parsing.
Una nota: l’endpoint Qwen 3.6 Plus di OpenRouter non supporta tool call forzate. Se provi tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, la richiesta restituisce un errore:
No endpoints found that support the provided 'tool_choice' valueLa soluzione pratica è usare tool_choice="auto" e affidarsi al system prompt:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Su tutte e sei le fatture di esempio del repo di supporto, questo prompt produce sempre una tool call. In produzione conviene comunque gestire l’eccezione: controlla finish_reason, verifica che tool_calls sia popolato e ritenta con un’istruzione più netta se non lo è. Le doc di Qwen sul function calling dicono lo stesso. La generazione della tool call non è garantita e in produzione serve un fallback.
Un effetto collaterale: una volta che il prompt chiede campi strutturati, delta.reasoning_content si riempie di una traccia lunga. Il modello analizza la tabella riga per riga, discute la notazione decimale europea su invoice_04.jpg e verifica le somme delle linee rispetto al totale. I token di reasoning possono superare di 10x o più i token di risposta con questo tipo di prompt.
È il costo del CoT sempre attivo nell’estrazione strutturata, motivo per cui preserve_thinking ha senso solo in agent loop multi-turno in cui un turno successivo legge la traccia. Stiamo facendo un’estrazione one-shot, quindi la traccia viene trasmessa a terminale e scartata.
Per i JPG, il flusso ha tre passaggi:
Leggere i byte dell’immagine dal disco
Codificarli in base64
Inserire il risultato in un blocco image_url con un URI data:
I PDF richiedono un passaggio in più perché il percorso di visione di Qwen accetta immagini e non file PDF direttamente. Converti ogni pagina in un’immagine PIL con pdf2image, poi invia le pagine come elenco di blocchi immagine nello stesso messaggio.
Entrambi i percorsi condividono la stessa chiamata al modello, quindi la chiamata vive in processors/image.py e processors/pdf.py delega a essa. Parti dagli import (il SYSTEM_PROMPT sopra sta nello stesso modulo):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveL’encoder trasforma un percorso JPG nell’URI data: che l’API si aspetta:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"L’helper condiviso _call_with_images costruisce l’array di contenuti utente (testo + una o più immagini) e invia la richiesta in streaming. Dallo stream raccoglie due dati: la traccia di reasoning e gli argomenti della tool call. Prima il setup della richiesta:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Poi il loop dello stream separa i delta di reasoning da quelli degli argomenti della tool call:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Il punto di ingresso pubblico per i JPG è una one-liner che usa questi helper:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Il processor PDF riusa _call_with_images e aggiunge solo la conversione pagina-immagine:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image richiede poppler installato. Installalo con:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsPer i PDF multi-pagina, invia ogni pagina come proprio blocco immagine nello stesso messaggio. Qwen le legge insieme e produce un’unica estrazione, che è ciò che vuoi per una fattura in cui i totali stanno a pagina 2.
150 DPI mantengono il testo delle fatture leggibile senza gonfiare il payload. Andare oltre rende la richiesta più grande senza migliorare l’accuratezza nei test su questi esempi. La documentazione vision di Alibaba copre formati supportati e limiti massimi.
main.py scorre sample_invoices/, instrada ogni file per estensione, chiama il processor giusto e scrive i risultati combinati in un CSV. Prima import e costanti:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Il loop principale itera la directory dei sample in ordine alfabetico, instrada per estensione del file e appiattisce ogni estrazione in una riga adatta al CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Infine, scrivi le righe su disco e registra il conteggio:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Eseguendo python main.py si percorrono i sei esempi in ordine. Ogni fattura trasmette il nome file, poi la traccia di reasoning, poi il JSON estratto, prima di passare alla successiva:
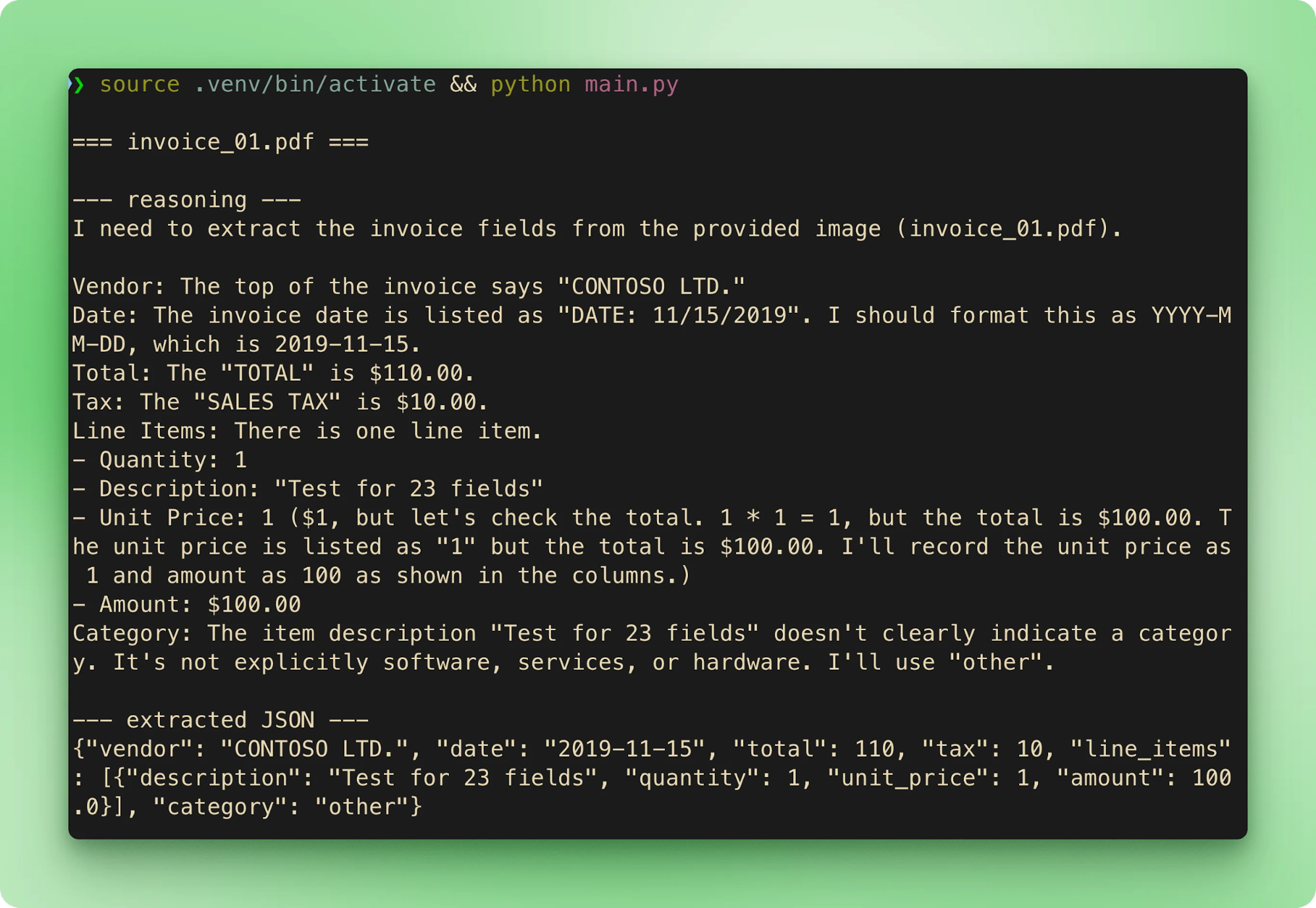
results.csv aggrega ogni estrazione in una riga per fattura:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
I totali coincidono con i dati di riferimento su tutte e sei. La latenza sul piano gratuito va da 15 a 40 secondi per fattura. Gran parte del tempo è la fase di reasoning prima che la tool call inizi lo streaming.
Alcuni pattern fanno la differenza tra una pipeline che funziona una volta e una che continua a funzionare su fatture reali.
Tieni le chiavi fuori dal codice. Il pattern .env e python-dotenv che abbiamo usato è il minimo. Aggiungi .env al tuo .gitignore prima del primo commit, così la chiave non arriva mai nel repo.
Gestisci i rate limit con backoff esponenziale. OpenRouter applica limiti per provider con risposte HTTP 429. La libreria tenacity offre un’implementazione basata su decorator e lo schema del cookbook OpenAI per wait_random_exponential funziona senza modifiche.
Usa lo streaming quando le risposte saranno lunghe. Il CoT sempre attivo gonfia la lunghezza della risposta di default. Le chiamate non in streaming significano attendere l’intero blocco di reasoning prima di vedere qualcosa. Lo streaming dà feedback precoce, mantiene la UI reattiva e ti permette di interrompere una richiesta che sta chiaramente andando male.
Usa preserve_thinking solo quando i turni successivi leggono il reasoning precedente. Per estrattori one-shot come questa pipeline, sono token sprecati. Per agent loop multi-turno (catene di tool call, task di pianificazione, workflow di debug), il parametro esiste per quel contesto cross-turn. La documentazione sul deep thinking di Alibaba copre anche thinking_budget, un tetto duro ai token di reasoning per chiamata.
Le risposte del piano gratuito possono essere registrate per training. Il piano free di OpenRouter instrada tramite provider che possono conservare i prompt. Non è adatto a fatture con PII reali, nomi clienti o dettagli di pagamento. Passa a un tier a pagamento di OpenRouter (o direttamente ad Alibaba Cloud con un account a pagamento) prima che dati reali attraversino la pipeline.
Nessun self-hosting sul tier Plus. Deployment che richiedono air-gapping o on-prem non possono usare l’API hosted. La variante open-source Qwen3.6-35B-A3B è un’opzione separata da considerare in quei casi.
Time-to-first-token può essere lento quando parte il reasoning. Imposta timeout generosi: 30–60 secondi è ragionevole per input immagine. Assicurati che la logica di retry gestisca i read timeout separatamente dai 429.
L’output non è deterministico anche con CoT sempre attivo. Nei test sul repo di supporto, invoice_01.pdf è stata estratta a $610,00 nella maggior parte delle esecuzioni. In almeno un rerun con input identici, è passata a $110,00. La traccia di reasoning è arrivata alla risposta corretta in entrambi i casi, ma l’argomento finale della tool call è differito. Due mitigazioni: imposta temperature bassa (0,1–0,2 per pura estrazione) e valida rispetto ai dati di riferimento o usa un secondo passaggio quando l’accuratezza lo giustifica.
Da qui, incapsulare la pipeline in un framework per agenti è un piccolo passo. Il loop di tool call, il parser in streaming e lo scrittore CSV sono le stesse primitive che un framework per agenti orchestra su più turni. Il corso di DataCamp Developing LLM Applications with LangChain spiega questi pattern con memoria, stato e routing multi-tool.
Corsi su Agentic AI
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

