Track
Основы AI-агентов
6 ч
Alibaba выпустила Qwen 3.6 Plus в апреле 2026 года. Характеристики: SWE-bench Verified — 78.8, контекстное окно 1M токенов по умолчанию, нативные мультимодальные входы и постоянное рассуждение. Для разработчика на Python главное не таблица бенчмарков. Важно, что модель доступна только по API и работает с обычным пакетом OpenAI, если поменять базовый URL.
В этом руководстве мы используем три ключевые возможности в одном проекте: chain-of-thought рассуждение, вызов инструментов для структурированного вывода и зрение для сканов счетов. Результат — небольшой конвейер для обработки счетов, который читает PDF и JPG, показывает ход рассуждений и возвращает проверенный JSON, который можно записать в CSV.
Понадобится Python 3.10 или новее и базовое умение вызывать API. Не нужен ни GPU, ни загрузка моделей, ни self-hosting. Мы получим доступ к Qwen 3.6 Plus через OpenRouter, так что регистрация — одна форма, а SDK OpenAI работает без изменений.
Настоятельно рекомендую также ознакомиться с нашим учебником по тонкой настройке Qwen 3.6 — актуальной версии Qwen с открытыми весами. Если вас интересуют конкурирующие модели, обязательно прочитайте наши обзоры по DeepSeek v4, GPT-5.5 от OpenAI и Claude Opus 4.7 от Anthropic.
Qwen 3.6 Plus — флагманская модель Alibaba за апрель 2026 года. В основе — гибрид линейного внимания и разреженной смеси экспертов, рассуждение включено по умолчанию, а текст, изображения и видео обрабатываются одним и тем же API.
Function calling использует протокол вызова инструментов OpenAI. Alibaba позиционирует релиз как «на пути к агентам реального мира», то есть одна модель для «грязных» входов, где в одном шаге нужны рассуждение, чтение изображения и вызов функции.
Тариф Plus — с закрытыми весами. Вы не можете скачать контрольную точку и запустить её на своём оборудовании (к тому же модель слишком велика для потребительского «железа»). Alibaba публикует открытый вариант Qwen/Qwen3.6-35B-A3B с контекстом 262K по умолчанию, но это отдельный продукт. В этом руководстве мы используем хостируемый API.
Qwen 3.6 Plus принимает до 1M входных токенов и возвращает до 65 536 выходных токенов за вызов. Входные модальности: текст, изображение и видео. Вызов инструментов — нативный по схеме OpenAI. На странице модели OpenRouter указаны цены, задержки провайдера и пропускная способность маршрутизируемых бэкендов.
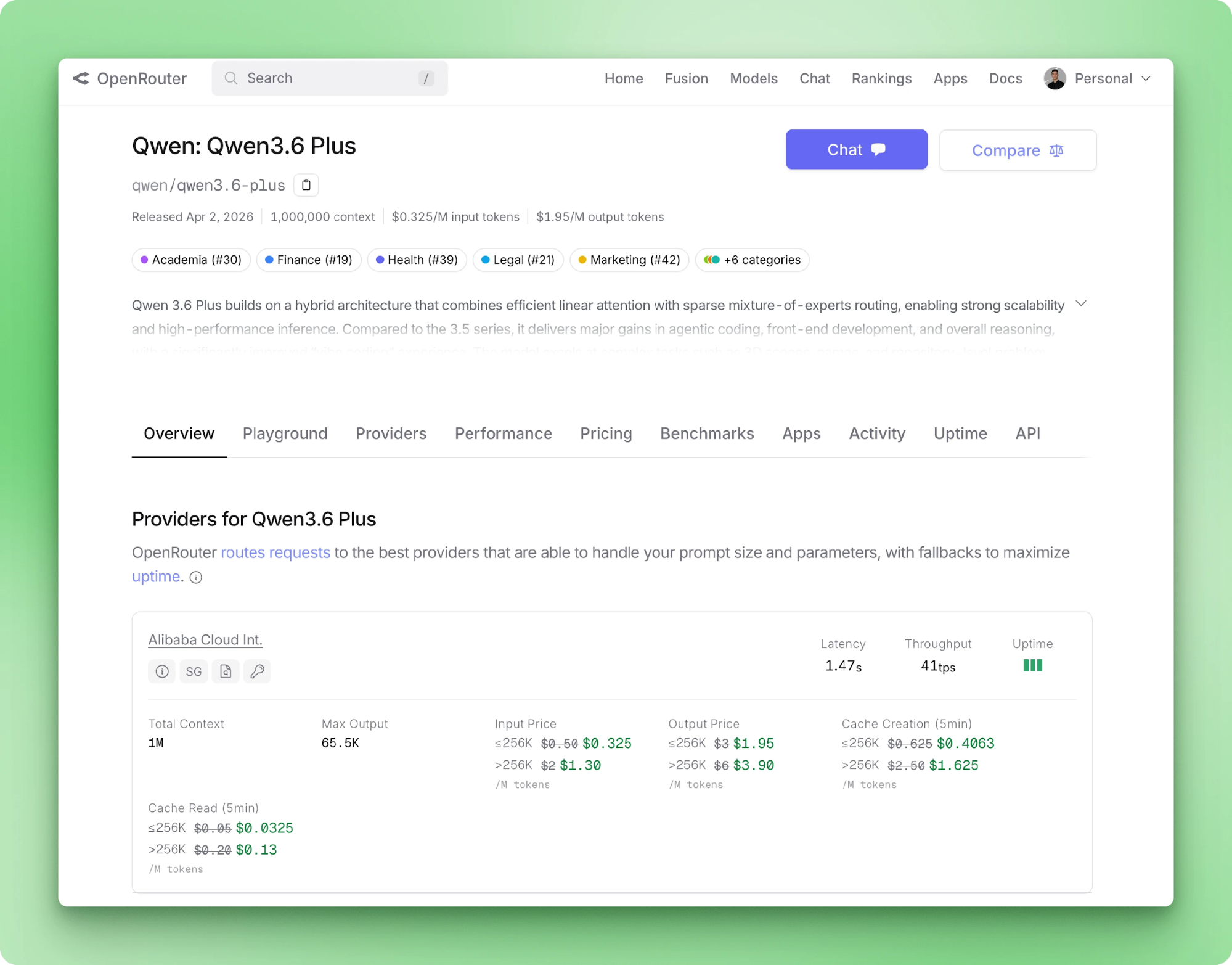
Chain-of-thought запускается по умолчанию при каждом вызове, а содержимое рассуждения приходит в отдельном поле, отличном от ответа. Новый параметр 3.6 Plus сохраняет следы рассуждений в сообщениях между репликами.
Alibaba рекомендует это для агентных циклов, когда поздние шаги выигрывают от более ранних цепочек мыслей. Для одношагового извлечения, как у нас, хранить трейс — пустая трата токенов, поэтому мы его отключаем.
Для этого руководства важны три бенчмарка:
Первые два — причина, почему сканированные счета — разумная цель. Третий — почему можно ожидать, что модель будет следовать протоколу вызова инструмента без тяжёлого промпт-инжиниринга.
Переход с 3.5 Plus на 3.6 Plus по большинству метрик невелик. Кодинг и рассуждения прибавили несколько пунктов. Главное изменение — рассуждение стало не опцией, а режимом по умолчанию. Больше всего выросли OCR и локализация объектов.
|
Возможность |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Режим рассуждений |
Включён по умолчанию (можно отключить через |
Всегда включённый CoT |
|
Контекстное окно |
До 1M токенов |
1M токенов (по умолчанию) |
|
Мультимодальность |
Нативное vision-language |
Нативное + улучшенные OCR и локализация объектов |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
Reasoning-across-turns |
— |
|
Если вы уже работали с 3.5 Plus в проде, обновление означает переход на новый параметр preserve_thinking и учёт того, что «мышление» теперь тарифицируется при каждом вызове. Основные выигрыши — в агентных циклах и зрении по документам, что и используется в этом руководстве.
Доступ к модели возможен двумя способами. Официальный — Alibaba Cloud Model Studio, который даёт прямую точку доступа по адресу https://dashscope-intl.aliyuncs.com/compatible-mode/v1. Другой вариант — OpenRouter, который маршрутизирует на Alibaba с единой биллинговой обёрткой и более простым онбордингом.
В руководстве мы используем OpenRouter, потому что создание ключа быстрее, а нюансов эндпоинта меньше. Если хотите прямой путь — поменяйте две строки и продолжайте.
Alibaba Cloud Model Studio подходит для этого руководства так же хорошо, как и OpenRouter. Меняются только базовый URL и имя переменной окружения.
Зарегистрируйтесь на openrouter.ai через аккаунт Google или GitHub. Бесплатный тариф доступен без карты — этого достаточно, чтобы пройти руководство от начала до конца. Если позже планируете большие объёмы, пополнение баланса даст более высокую пропускную способность и снимет лимит по моделям.
После входа перейдите на openrouter.ai/settings/keys и создайте ключ. Пометьте его, например, как qwen-tutorial, чтобы при необходимости можно было отозвать.
Скопируйте значение ключа сейчас: OpenRouter показывает его только один раз. Затем сохраните его в файле .env в корне проекта:
OPENROUTER_API_KEY=sk-or-v1-...Мы загрузим его с помощью python-dotenv в следующем разделе. Если предпочитаете напрямую Alibaba Cloud, ключ берём из modelstudio.console.alibabacloud.com и записываем в DASHSCOPE_API_KEY.
Установите два пакета, которые понадобятся для первого проверочного вызова:
pip install openai python-dotenvПакет openai — тот же SDK, что и для эндпоинта OpenAI. И OpenRouter, и Alibaba Cloud Model Studio реализуют OpenAI Chat Completions API, так что клиентский код менять не нужно.
Создайте файл hello.py и проверьте соединение:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Запуск python hello.py должен напечатать короткий ответ. Задержка до первого токена на бесплатном тарифе может быть несколько секунд — модель строит трейс рассуждения перед генерацией видимого ответа.
Пример — конвейер обработки счетов. Он принимает два формата: текстовые PDF и сканированные JPG. Каждый счёт проходит через Qwen 3.6 Plus с включёнными рассуждениями, а извлечённые поля приходят через вызов инструмента. Каждый счёт проходит четыре этапа:
Декодирование входа (base64-кодирование изображения или предварительная конвертация каждой страницы PDF в изображение)
Потоковая передача трейса рассуждений от модели
Парсинг вызова инструмента в структурированный JSON
Запись строки в results.csv
Весь код для этого раздела находится в bextuychiev/qwen-invoice-pipeline-tutorial. Клонируйте, чтобы повторять шаги или используйте как справочник при создании собственной версии.
Создайте каталог invoice-pipeline/ и организуйте так:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtРазделение между client.py и процессорами хранит конфигурацию OpenRouter в одном файле. Если позже перейдёте на Alibaba Cloud, меняется только client.py.
client.py оборачивает клиент OpenAI с нужным базовым URL и ID модели:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example лежит рядом, чтобы тем, кто клонирует репозиторий, было ясно, что заполнять:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1В сопроводительном репозитории — шесть примеров счетов из трёх источников:
Реальные счета компаний нельзя свободно распространять из‑за PII, поэтому мы используем эти. Эталонные суммы указаны в README репозитория, если захотите проверить конвейер на соответствие.
Если вы работали с Qwen 3.5, CoT был тумблером на вызов: enable_thinking=True внутри extra_body. В 3.6 Plus рассуждение идёт по умолчанию, а параметр в основном нужен, чтобы его отключить. Токены рассуждений всегда тарифицируются, когда «мышление» активно, поэтому «always-on» — это вопрос стоимости, а не бесплатная опция.
При стриминге ответа delta.reasoning_content приходит первым, затем следует delta.content (или delta.tool_calls в нашем случае).
Минимальный вызов, который извлекает счёт и печатает трейс рассуждений по мере стриминга, выглядит так:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Мы читаем байты JPG с диска, кодируем в base64 и оборачиваем результат в URI data:. Этот формат позволяет протоколу OpenAI для контент-блоков принимать встроенные изображения без хостинга. Блок image_url принимает URI напрямую, и модель видит счёт так же, как если бы вы передали ссылку.
extra_body={"enable_thinking": True} пробрасывает флаг enable_thinking в Qwen. SDK OpenAI не знает об этом параметре, поэтому extra_body — способ передавать опции, специфичные для провайдера.
При запуске на invoice_04.jpg потоковый ответ приходит в виде краткого резюме:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Краткость ожидаема: системный промпт просил «summarize» и ничего больше. Когда задача растёт (позиции, категории, структурированные поля), растёт и трейс рассуждений. Увидим это в следующем разделе: та же модель на том же изображении тратит большую часть бюджета на «мышление», прежде чем ответить.
Добавление /no_think к пользовательскому промпту — это мягкий переключатель, который отключает CoT для этого вызова. Полезно при отладке, когда нужен более быстрый ответ без «мышления».
Рассуждения делают процесс читаемым, но вывод по‑прежнему свободный текст внутри трейса. Чтобы всегда получать структурированный, парсируемый JSON, мы определяем один инструмент — extract_invoice — и ставим tool_choice="auto" с системным промптом, который велит модели всегда вызывать инструмент.
Схема в tools.py описывает шесть полей. Внешняя структура следует стандартному формату инструмента-функции OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Шесть полей находятся внутри parameters.properties. Скалярные поля (vendor, date, total, tax) используют обычные типы JSON Schema. category использует enum, чтобы модель выбирала из фиксированного набора из четырёх значений, а не придумывала ярлыки. line_items — единственное структурированное поле, массив объектов, у каждого свой список required:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Схема имеет два уровня required. Внешний список указывает, какие верхнеуровневые поля должны быть в каждом извлечении. Перечень на уровне элемента указывает, какие под‑поля должны быть в каждой позиции. Полная схема — в tools.py сопроводительного репозитория.
Аргументы возвращаются как JSON-строка внутри tool_calls[0].function.arguments, а не распарсенный объект, поэтому нужно вызвать json.loads самостоятельно. При стриминге аргументы приходят как последовательность дельт, которые нужно склеить перед парсингом.
Нюанс: эндпоинт Qwen 3.6 Plus в OpenRouter не поддерживает принудительные вызовы инструмента. Если попробовать tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, запрос вернёт ошибку:
No endpoints found that support the provided 'tool_choice' valueПрактичное решение — использовать tool_choice="auto" и положиться на системный промпт:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""На всех шести примерах из сопроводительного репозитория этот промпт даёт вызов инструмента каждый раз. В проде всё равно стоит подстраховаться на случай исключений: проверять finish_reason, удостоверяться, что tool_calls заполнен, и повторять с более жёсткой инструкцией, если нет. Документация Qwen по вызову функций говорит о том же. Генерация вызова инструмента не гарантирована, и прод-код должен иметь запасной план.
Побочный эффект: как только промпт просит структурированные поля, delta.reasoning_content заполняется длинным трейсом. Модель парсит таблицу построчно, спорит о европейской десятичной записи на invoice_04.jpg и сверяет суммы по позициям с итогом. Токены рассуждений могут превышать токены ответа в 10 раз и более для такого промпта.
Это стоимость always-on CoT при структурированном извлечении, поэтому preserve_thinking окупается только в мультиходовых агентных циклах, где поздняя реплика читает трейс. Мы делаем одношаговое извлечение, поэтому трейс стримится в терминал, а затем отбрасывается.
Для JPG шагов три:
Прочитать байты изображения с диска
Закодировать их в base64
Поместить результат в контент-блок image_url с URI data:
PDF требуют дополнительный шаг, потому что зрительная часть Qwen принимает непосредственно изображения, а не файлы PDF. Конвертируйте каждую страницу в изображение PIL с помощью pdf2image, затем отправьте страницы как список блоков изображений в одном сообщении.
Обе ветки используют один и тот же вызов модели, поэтому сам вызов живёт в processors/image.py, а processors/pdf.py делегирует ему. Начнём с импортов (SYSTEM_PROMPT выше в том же модуле):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveКодировщик превращает путь к JPG в ожидаемый API URI data::
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Общий помощник _call_with_images формирует массив пользовательского контента (текст + одно или несколько изображений) и отправляет стриминговый запрос. Из потока он собирает две сущности: трейс рассуждений и аргументы вызова инструмента. Сначала — подготовка запроса:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Затем цикл по потоку разделяет дельты рассуждений и аргументов вызова инструмента:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Публичная точка входа для JPG — однострочная обёртка над этими помощниками:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Процессор PDF переиспользует _call_with_images и добавляет только конвертацию страниц в изображения:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image требует установленного poppler. Установите его так:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsДля многостраничных PDF отправляйте каждую страницу отдельным блоком изображения в одном сообщении. Qwen читает их вместе и выдаёт одно извлечение — именно то, что нужно для счёта, где итоги на второй странице.
150 DPI сохраняет читаемость текста без раздувания полезной нагрузки. Выше — больше размер запроса без прироста точности на этих примерах. Документация Alibaba по зрению охватывает поддерживаемые форматы и верхние пределы.
main.py обходит sample_invoices/, маршрутизирует файлы по расширению, вызывает нужный процессор и пишет объединённые результаты в CSV. Сначала — импорты и константы:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Главный цикл перебирает каталог примеров в отсортированном порядке, маршрутизирует по расширению файла и разворачивает каждое извлечение в строку, удобную для CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Наконец, записываем строки на диск и логируем счётчик:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Запуск python main.py обходит шесть примеров по порядку. Каждый счёт стримит имя файла, затем трейс рассуждений, затем извлечённый JSON и переходит к следующему:
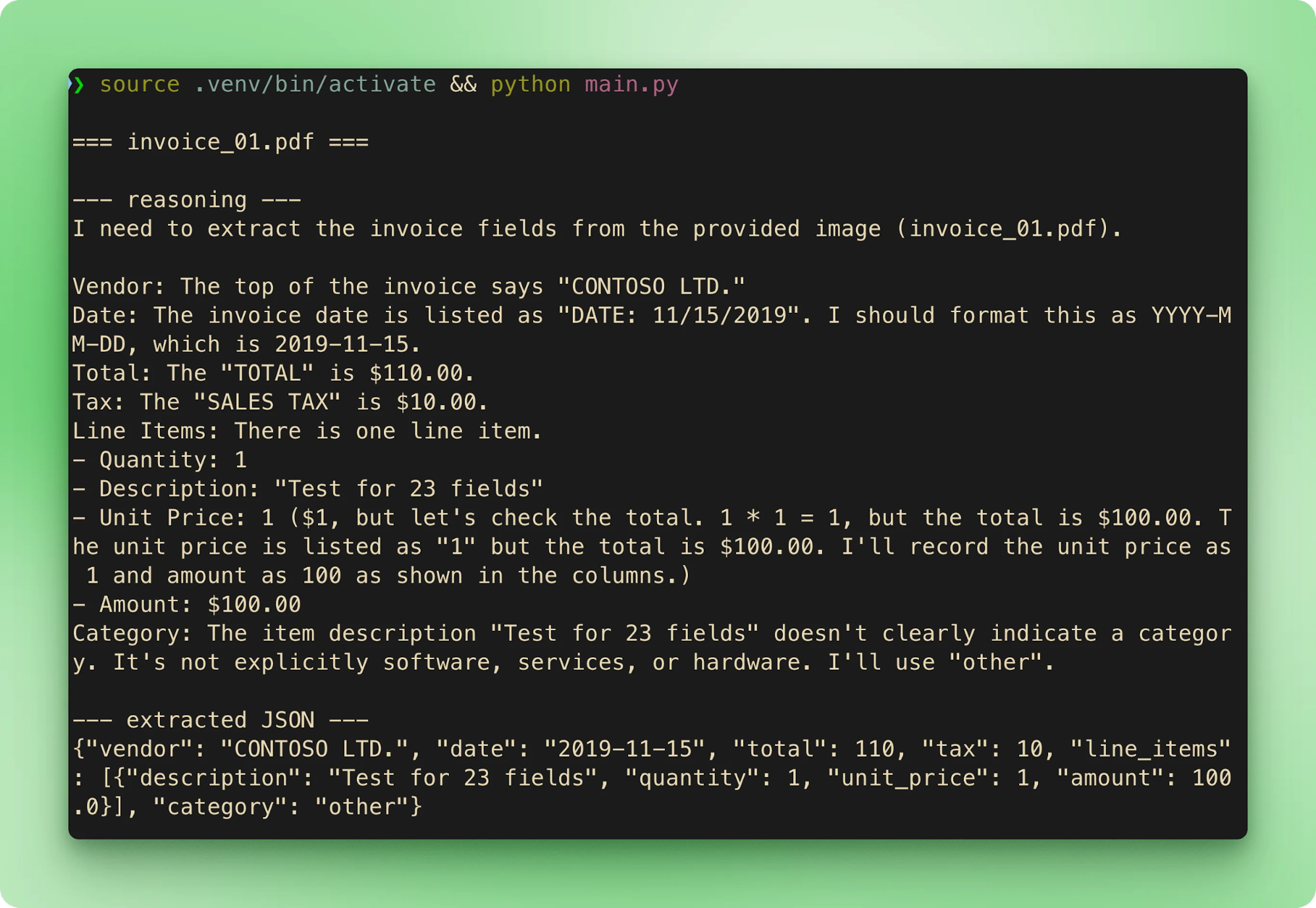
results.csv агрегирует каждое извлечение в одну строку на счёт:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Итоги совпадают с эталонными на всех шести. Задержка на бесплатном тарифе — 15–40 секунд на счёт. Большая часть времени уходит на фазу рассуждений до начала стриминга вызова инструмента.
Есть несколько шаблонов, которые отличают конвейер, срабатывающий один раз, от того, который стабильно работает на реальных счетах.
Держите секреты вне кода. Используемый нами паттерн с .env и python-dotenv — базовый минимум. Добавьте .env в .gitignore до первого коммита, чтобы ключ не попал в репозиторий.
Обрабатывайте rate limit экспоненциальным бэкоффом. OpenRouter применяет лимиты провайдеров через HTTP 429. Библиотека tenacity даёт реализацию на декораторах, а паттерн из кулинарной книги OpenAI для wait_random_exponential подходит без изменений.
Стримьте везде, где ответы будут длинными. Always-on CoT по умолчанию раздувает длину ответа. Нестриминговые вызовы означают ожидание всего блока рассуждений перед любым выводом. Стриминг даёт раннюю обратную связь, держит UI отзывчивым и позволяет отменить заведомо неверный запрос.
Используйте preserve_thinking только когда последующие шаги читают ранние рассуждения. Для одношаговых извлекателей, как в этом конвейере, это пустые токены. Для многотуровых агентных циклов (цепочки вызовов инструментов, планирование, отладка) параметр и существует для межрепликового контекста. В документации Alibaba по deep thinking также описан thinking_budget — жёсткий лимит токенов рассуждения на вызов.
Ответы на бесплатном тарифе могут логироваться для обучения. Бесплатный маршрут OpenRouter может проходить через провайдеров, которые сохраняют промпты. Это делает его непригодным для счетов с реальными PII, именами клиентов или платёжными данными. Перейдите на платный тариф OpenRouter (или напрямую к Alibaba Cloud с платным аккаунтом), прежде чем пропускать через конвейер реальные данные.
Нет self-hosting в тарифе Plus. Развёртываниям с air-gap или on-prem недоступен хостируемый API. Открытый вариант Qwen3.6-35B-A3B — отдельная опция, которую стоит рассмотреть для таких случаев.
Время до первого токена может быть высоким при старте рассуждений. Ставьте щедрые таймауты, 30–60 секунд разумно для входа-изображения. Убедитесь, что логика повторов отдельно обрабатывает read timeout и 429.
Вывод не детерминирован даже при always-on CoT. В тестах на примерах из сопроводительного репо invoice_01.pdf чаще всего извлекался как $610.00, но хотя бы один повтор с теми же входами дал $110.00. В обоих случаях трейс рассуждений приходил к верному ответу, но итоговые аргументы вызова инструмента различались. Две меры: ставьте низкую temperature (0.1–0.2 для чистого извлечения) и валидируйте по эталону или делайте второй проход, если точность критична.
Дальше — небольшой шаг до обёртки конвейера в агентный фреймворк. Цикл вызова инструмента, стриминговый парсер и писатель CSV — это те же примитивы, которыми фреймворк оркестрирует многоходовые сценарии. Курс DataCamp Developing LLM Applications with LangChain разбирает эти паттерны с памятью, состоянием и маршрутизацией между инструментами.
Курсы по агентному ИИ
Track
Track
Course