Tracks
AI智能体基础知识
6小时
阿里巴巴于 2026 年 4 月发布了 Qwen 3.6 Plus。参数表:SWE-bench Verified 78.8,默认 100 万 token 的上下文窗口,原生多模态输入,以及始终开启的推理。对 Python 开发者而言,有趣的不在于基准表,而在于该模型仅提供 API 形式,并且只需替换 base URL 就能直接用普通的 OpenAI 包。
在本教程中,我们将在一个项目里用到它的三大特性:链式思维推理、用于结构化输出的工具调用,以及对扫描发票的视觉识别。最终我们会得到一个小型发票处理流水线:读取 PDF 和 JPG,展示其推理过程,并返回可验证的 JSON,您可以写入 CSV。
您需要 Python 3.10 或更新版本,并熟悉发起 API 调用。无需 GPU、无需下载模型、无需自托管。我们将通过 OpenRouter 访问 Qwen 3.6 Plus,这样注册只需一个表单,而且 OpenAI SDK 可直接使用,无需改动。
强烈建议您也看看我们关于最新开源权重版本 Qwen 的教程:微调 Qwen 3.6。如果您对竞品模型感兴趣,欢迎阅读我们的指南:DeepSeek v4、OpenAI 的 GPT-5.5,以及 Anthropic 的 Claude Opus 4.7。
Qwen 3.6 Plus 是阿里巴巴于 2026 年 4 月发布的旗舰模型。其骨干采用线性注意力与稀疏专家混合的混合架构,推理默认开启,文本、图像、视频都通过同一 API 处理。
函数调用遵循 OpenAI 的工具调用协议。阿里巴巴将其定位为“迈向真实世界 Agent”,也就是一个模型即可在一步内应对需要推理、读图与函数调用的复杂输入。
Plus 等级为闭源权重。您无法下载 checkpoint 在自有硬件上运行(模型也过大,消费者级硬件无法承载)。阿里巴巴发布了开源的 Qwen/Qwen3.6-35B-A3B 变体,默认上下文 262K,但那是另一个产品。本文教程使用的是托管 API。
Qwen 3.6 Plus 每次调用最多接收 100 万个输入 token,并可返回最多 65,536 个输出 token。输入模态包括文本、图像与视频。工具调用通过 OpenAI 架构原生支持。OpenRouter 的 模型页面列出了路由后端的定价、提供方时延与吞吐。
链式思维默认在每次调用中运行,且推理内容与答案分开在独立字段里流式返回。一个全新的 3.6 Plus 参数可在多轮对话中将先前的推理轨迹附着在消息上。
阿里巴巴建议在 Agent 回路中使用该功能,后续轮次可从早先的思维链中受益。对于我们这种一次性抽取,保留轨迹会浪费 token,因此我们将其关闭。
本教程相关的三项基准成绩:
前两项让扫描发票成为合理目标。第三项说明我们可以期待模型无需复杂提示工程即可遵循工具调用协议。
从 3.5 Plus 升到 3.6 Plus,多数指标提升幅度不大。编程与推理基准小幅上升。更大的变化在于推理从可切换选项变为默认开启。OCR 与目标定位提升最大。
|
能力 |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
推理模式 |
默认开启(可通过 |
始终开启 CoT |
|
上下文窗口 |
最高 100 万 token |
100 万 token(默认) |
|
多模态 |
原生视觉-语言 |
原生 + 改进的 OCR、目标定位 |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
跨轮推理 |
— |
|
如果您已在生产环境运行 3.5 Plus,升级意味着采用新的 preserve_thinking 参数,并注意推理现已在每次调用中计费。主要收益体现在 Agent 回路与文档视觉上,本教程正是围绕这些能力展开。
您可以通过两种方式访问该模型。官方方式是 阿里云 Model Studio,它会给您一个直连端点 https://dashscope-intl.aliyuncs.com/compatible-mode/v1。另一种是 OpenRouter,它在统一的计费层后路由至阿里巴巴,注册流程更简单。
本教程选择 OpenRouter,因为创建密钥更快、端点细节问题更少。如果您想走直连路径,改两行代码即可继续。
对本教程而言,阿里云 Model Studio 与 OpenRouter 一样好用。唯一变化的是 base URL 与环境变量名。
使用 Google 或 GitHub 账号在 openrouter.ai 注册。免费层无需信用卡,足够完整跟做本教程。如果您计划后续跑更大规模,充值可获得更高吞吐并解除按模型的速率限制。
登录后访问 openrouter.ai/settings/keys 并创建一个密钥。给它起个标签,比如 qwen-tutorial,方便后续撤销。
现在就复制密钥值,因为 OpenRouter 只显示一次。然后将其保存在项目根目录的 .env 文件中:
OPENROUTER_API_KEY=sk-or-v1-...我们将在下一节用 python-dotenv 加载它。如果您更愿意直接使用阿里云,密钥来自 modelstudio.console.alibabacloud.com,并且应写入 DASHSCOPE_API_KEY。
安装用于首次验证调用的两个包:
pip install openai python-dotenvopenai 包就是您在 OpenAI 端点上会用到的同一个 SDK。OpenRouter 与阿里云 Model Studio 都实现了 OpenAI Chat Completions API,因此客户端代码无需更改。
创建一个名为 hello.py 的文件并验证连接:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)运行 python hello.py 应打印一条简短回复。免费层的首 token 时延可能需要几秒,因为模型会在生成可见答案前构建推理轨迹。
该示例项目是一个发票处理流水线。它接受两种格式:文本 PDF 与扫描 JPG。每张发票都在开启推理的情况下通过 Qwen 3.6 Plus 处理,抽取的字段通过工具调用返回。每张发票经历四个阶段:
解码输入(对图像进行 base64 编码,或先将每页 PDF 转为图像)
从模型流式回传推理轨迹
将工具调用解析为结构化 JSON
写入一行到 results.csv
本节全部代码位于 bextuychiev/qwen-invoice-pipeline-tutorial。克隆以便跟做,或在自行搭建时作参考。
创建 invoice-pipeline/ 目录,并按如下结构组织:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txt将 client.py 与处理器分离,能把 OpenRouter 配置集中在一个文件里。若后续切换到阿里云,只需改 client.py,其他文件不动。
client.py 用正确的 base URL 与模型 ID 封装了 OpenAI 客户端:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example 放在旁边,方便克隆仓库的人知道需要填写什么:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1配套仓库提供了来自三个来源的六张示例发票:
真实公司发票因含 PII 无法公开再分发,所以我们使用这些数据。若要对比流水线表现,仓库 README 中列出了基准总额。
如果您用过 Qwen 3.5,CoT 是按调用切换的:在 extra_body 里设置 enable_thinking=True。在 3.6 Plus 上,推理默认运行,该参数主要用于关闭。只要思考开启,推理 token 就会计费,这让“始终开启”成为成本决策,而非免费特性。
当您以流式获取响应时,delta.reasoning_content 会先到,随后才是 delta.content(或我们的场景里是 delta.tool_calls)。
一个最小示例会抽取发票并在流式过程中打印推理轨迹,如下:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)我们从磁盘读取 JPG 字节,进行 base64 编码,并用 data: URI 封装。该格式使 OpenAI 的内容块协议无需托管 URL 即可接受内联图像。 image_url 块可直接接收该 URI,模型看到的发票就像您传入了链接。
extra_body={"enable_thinking": True} 将 enable_thinking 标志转发给 Qwen。OpenAI SDK 并不认识该参数,因此用 extra_body 传递供应商特有选项。
在 invoice_04.jpg 上运行后,流式返回的是一段简短摘要:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51简短正是我们要求的:system 提示只说了“summarize(概述)”。当任务扩展(明细、分类、结构化字段),推理轨迹也会随之增长。下一节中,您会看到对同一张图、同一模型,大部分输出预算都花在“思考”上才给出答案。
在用户提示后附加 /no_think 是一个软开关,可在该次调用关闭 CoT。调试时很有用,能更快得到不含思考的响应。
推理让抽取过程可读,但输出仍是推理轨迹中的自由文本。为确保每次都返回结构化、可解析的 JSON,我们定义一个工具 extract_invoice,并设置 tool_choice="auto",同时在 system 提示中要求模型始终调用该工具。
在 tools.py 中的模式定义了六个字段。外层结构遵循标准的 OpenAI 函数工具格式:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}六个字段位于 parameters.properties 中。标量字段(vendor、date、total、tax)使用普通 JSON Schema 类型。 category 使用 enum,让模型从四个固定值中选择,而不是自创标签。 line_items 是唯一的结构化字段:对象数组,每个对象都有自己的 required 列表:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},该模式有两层 required。外层列表标注每次抽取必须出现的顶层字段;逐项列表标注每条明细中必须出现的子字段。完整模式可在配套仓库的 tools.py 中查看。
参数会作为 JSON 格式的字符串出现在 tool_calls[0].function.arguments 中,而非已解析对象,因此需要自行调用 json.loads。在流式情况下,参数会以增量片段到达,需要先拼接再解析。
一个注意点:OpenRouter 上的 Qwen 3.6 Plus 端点不支持强制工具调用。如果尝试 tool_choice={"type": "function", "function": {"name": "extract_invoice"}},请求会返回错误:
No endpoints found that support the provided 'tool_choice' value实际的修正办法是使用 tool_choice="auto",并依赖 system 提示:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""在配套仓库的六张示例发票上,这条提示每次都能得到工具调用。生产代码仍应防范例外:检查 finish_reason,验证 tool_calls 是否有值,若没有则用更明确的指令重试。Qwen 自身的 函数调用文档也提到这一点。工具调用并不保证成功,生产代码需要兜底方案。
一个副作用是:一旦提示要求结构化字段,delta.reasoning_content 会被长轨迹填满。模型会逐行解析表格,在 invoice_04.jpg 上讨论欧洲小数记法,并将明细金额与总额交叉校验。在这类提示中,推理 token 数可能是答案 token 的 10 倍以上。
这就是结构化抽取在“始终开启 CoT”下的成本,因此 preserve_thinking 只在多轮 Agent 回路中、后续轮次需要读取先前轨迹时才有价值。我们做的是一次性抽取,因此轨迹仅流到终端,随后丢弃。
对于 JPG,流程分三步:
从磁盘读取图像字节
进行 Base64 编码
将结果放入带 data: URI 的 image_url 内容块
PDF 则需多一步,因为 Qwen 的视觉路径直接接受图像而非 PDF 文件。先用 pdf2image 将每页转换为 PIL 图像,然后在同一条消息中将这些页面作为图像内容块列表发送。
两条路径共享同一个模型调用,因此调用写在 processors/image.py 中,processors/pdf.py 代理给它。先来看导入(上面的 SYSTEM_PROMPT 位于同一模块中):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined above编码器将 JPG 路径转为 API 所需的 data: URI:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"共享的辅助函数 _call_with_images 构建用户内容数组(文本 + 一张或多张图),并发起流式请求。从流中收集两类数据:推理轨迹与工具调用参数。先看请求设置:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)随后,流式循环将推理增量与工具参数增量分离:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}针对 JPG 的对外入口是一行代码,直接调用辅助函数:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)PDF 处理器复用 _call_with_images,只新增了“页面转图像”步骤:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image 依赖 poppler。安装方式:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utils对于多页 PDF,将每一页作为单独的图像块放入同一条消息。Qwen 会一并读取并产出一次抽取结果——这正适用于总额在第 2 页的发票。
150 DPI 既保证发票文本可读,又不会让负载膨胀。更高分辨率只会增大请求体,基于这些样本的测试并未见到精度提升。阿里巴巴的 视觉文档涵盖了支持的格式与上限。
main.py 遍历 sample_invoices/,按扩展名路由至对应处理器,并将合并结果写入 CSV。先是导入与常量:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}主循环按排序后的文件名遍历样本目录,按扩展名路由,并将每次抽取扁平化为适合 CSV 的一行:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})最后,将行写入磁盘并记录数量:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()运行 python main.py 将按顺序处理六个样本。每张发票都会依次流式显示文件名、推理轨迹与抽取出的 JSON,随后进入下一张:
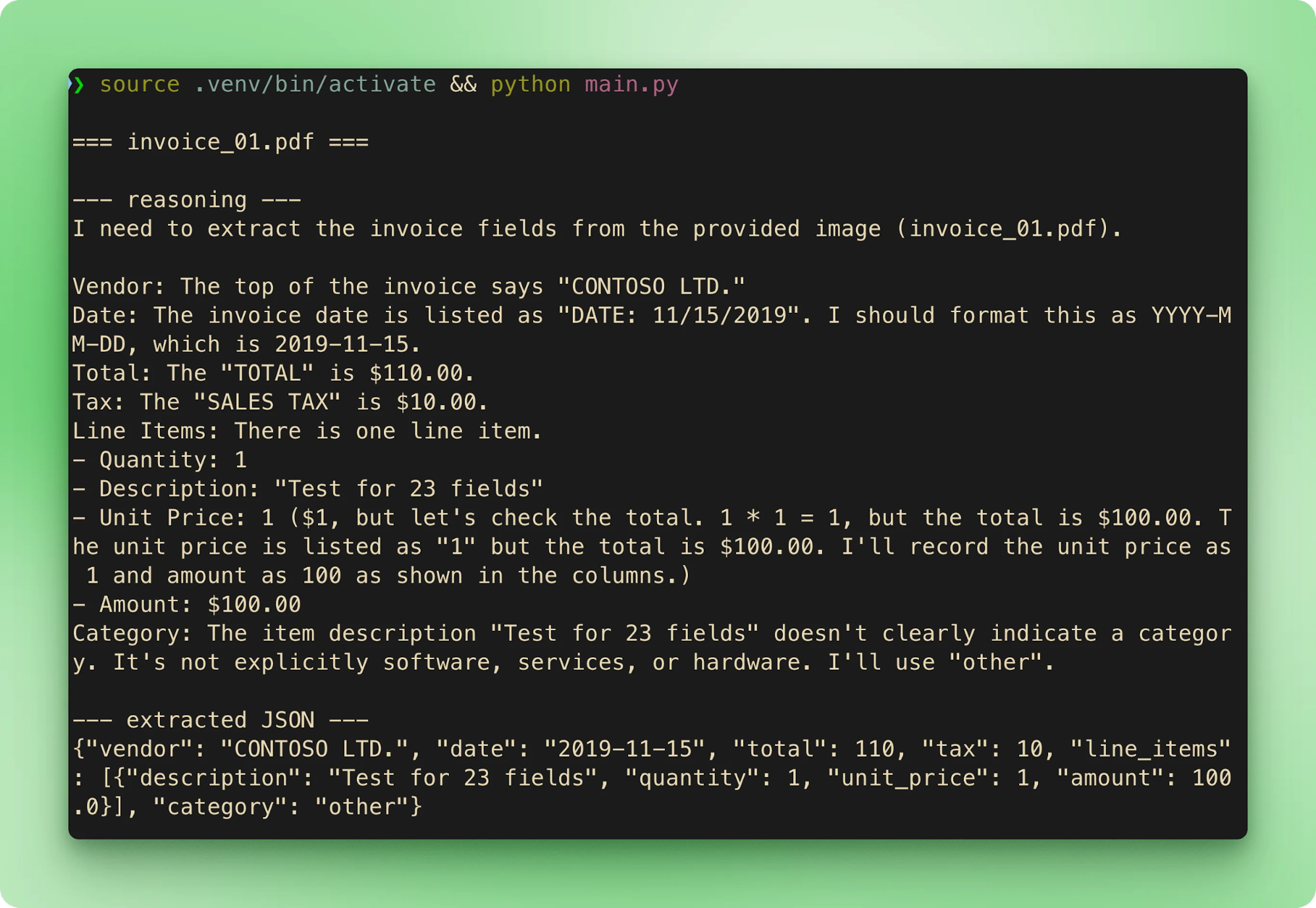
results.csv 将每次抽取汇总为每张发票一行:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
所有六个样本的总额都与基准真值一致。免费层的延迟为每张发票 15–40 秒。大部分时间花在工具调用开始流式之前的推理阶段。
有几条模式能决定一个流水线是偶尔可用,还是能在真实发票上持续可用。
将密钥与代码分离。我们始终使用的 .env 与 python-dotenv 就是基本做法。在首次提交前将 .env 加入 .gitignore,确保密钥永不进入仓库。
用指数退避处理限流。OpenRouter 以 HTTP 429 强制每个提供方的限流。tenacity 库提供装饰器式实现,OpenAI cookbook 中的 wait_random_exponential 模式可直接使用。
响应较长时尽量使用流式。始终开启的 CoT 会默认拉长响应长度。非流式意味着要等整块推理文本生成完才看到任何结果。流式能带来早期反馈、保持 UI 响应,并允许在明显出错时中止请求。
仅在后续轮次会读取先前推理时使用 preserve_thinking。对于本流水线这种一次性抽取,它只是浪费 token。对多轮 Agent 回路(工具链调用、规划任务、调试流程)来说,该参数能提供跨轮上下文。阿里巴巴的 深度思考文档也介绍了 thinking_budget,可为每次调用设置推理 token 的硬上限。
免费层响应可能被用于训练日志。OpenRouter 的免费层会经由可能保留提示的提供方路由。这让它不适合处理包含真实 PII、客户姓名或支付信息的发票。在真实数据进流水线前,请迁移到 OpenRouter 付费层(或付费的阿里云直连)。
Plus 等级无法自托管。需要物理隔离或本地部署的场景无法使用托管 API。开源的 Qwen3.6-35B-A3B 变体是可考虑的独立选项。
启用推理时首 token 时间可能较慢。合理设置较大的超时——对图像输入而言 30–60 秒是合理范围。确保重试逻辑将读取超时与 429 区分对待。
即使始终开启 CoT,输出也非确定性。在配套仓库样本测试中,invoice_01.pdf 大多数运行抽取为 $610.00,但在至少一次相同输入的重跑中变成 $110.00。两次的推理轨迹都得到正确答案,但最终工具调用参数不同。两种缓解:将 temperature 设低(纯抽取建议 0.1–0.2),并在精度足够重要时对比真值或进行第二次校验调用。
从这里开始,把流水线封装进一个 Agent 框架只差临门一脚。工具调用循环、流式解析器与 CSV 写入器,正是 Agent 框架在多轮中编排的基元。DataCamp 的 Developing LLM Applications with LangChain 课程带您结合记忆、状态与多工具路由走通这些模式。
Agentic AI 课程
Tracks
Tracks
Courses