Tracks
AIエージェントの基礎
6時間
Alibaba は 2026 年 4 月に Qwen 3.6 Plus をリリースしました。仕様は次のとおりです:SWE-bench Verified 78.8、標準で 100 万トークンのコンテキストウィンドウ、ネイティブなマルチモーダル入力、常時オンの推論。Python 開発者にとって興味深いのはベンチマーク表ではなく、モデルが API 専用で、ベース URL を差し替えるだけで素の OpenAI パッケージで動作する点です。
このチュートリアルでは、主要機能のうち 3 つを 1 つのプロジェクトで使います:Chain-of-Thought 推論、構造化出力のためのツール呼び出し、そしてスキャンした請求書に対するビジョン。最終的には、PDF と JPG を読み取り、推論内容を表示し、CSV に書き出せる検証済み JSON を返す小さな請求書処理パイプラインが完成します。
必要なのは Python 3.10 以降と API コールに関する基本的な知識だけです。GPU もモデルのダウンロードもセルフホスティングも不要です。Qwen 3.6 Plus には OpenRouter 経由でアクセスします。登録は 1 フォームで済み、OpenAI SDK はそのまま使えます。
あわせて、最新のオープンウェイト版である Qwen 3.6 のファインチューニングに関するチュートリアルも強くおすすめします。競合モデルに興味がある場合は、DeepSeek v4、OpenAI の GPT-5.5、Anthropic の Claude Opus 4.7 のガイドもぜひご覧ください。
Qwen 3.6 Plus は Alibaba の 2026 年 4 月のフラッグシップモデルです。バックボーンは線形アテンションと疎 MoE のハイブリッド、推論はデフォルト実行、テキスト・画像・動画が同一 API で扱えます。
関数呼び出しは OpenAI のツールコールプロトコルを使用します。Alibaba はこれを「現実世界のエージェントへ」と位置づけており、雑多な入力に対して、推論・画像読解・関数呼び出しを 1 ステップでこなす単一モデルという狙いです。
Plus ティアはクローズドウェイトです。チェックポイントをダウンロードして手元のハードウェアで動かすことはできません(そもそもコンシューマーハードウェアでは動かせないサイズです)。Alibaba は 262K の標準コンテキストを持つオープンソースの Qwen/Qwen3.6-35B-A3B 変種を公開していますが、これは別製品です。本チュートリアルではホスト型 API を使用します。
Qwen 3.6 Plus は最大 100 万トークンの入力と、呼び出し 1 回あたり最大 65,536 トークンの出力に対応します。入力モダリティはテキスト・画像・動画。ツール呼び出しは OpenAI スキーマにネイティブ対応。OpenRouter のモデルページには価格、プロバイダのレイテンシ、バックエンドのスループットが掲載されています。
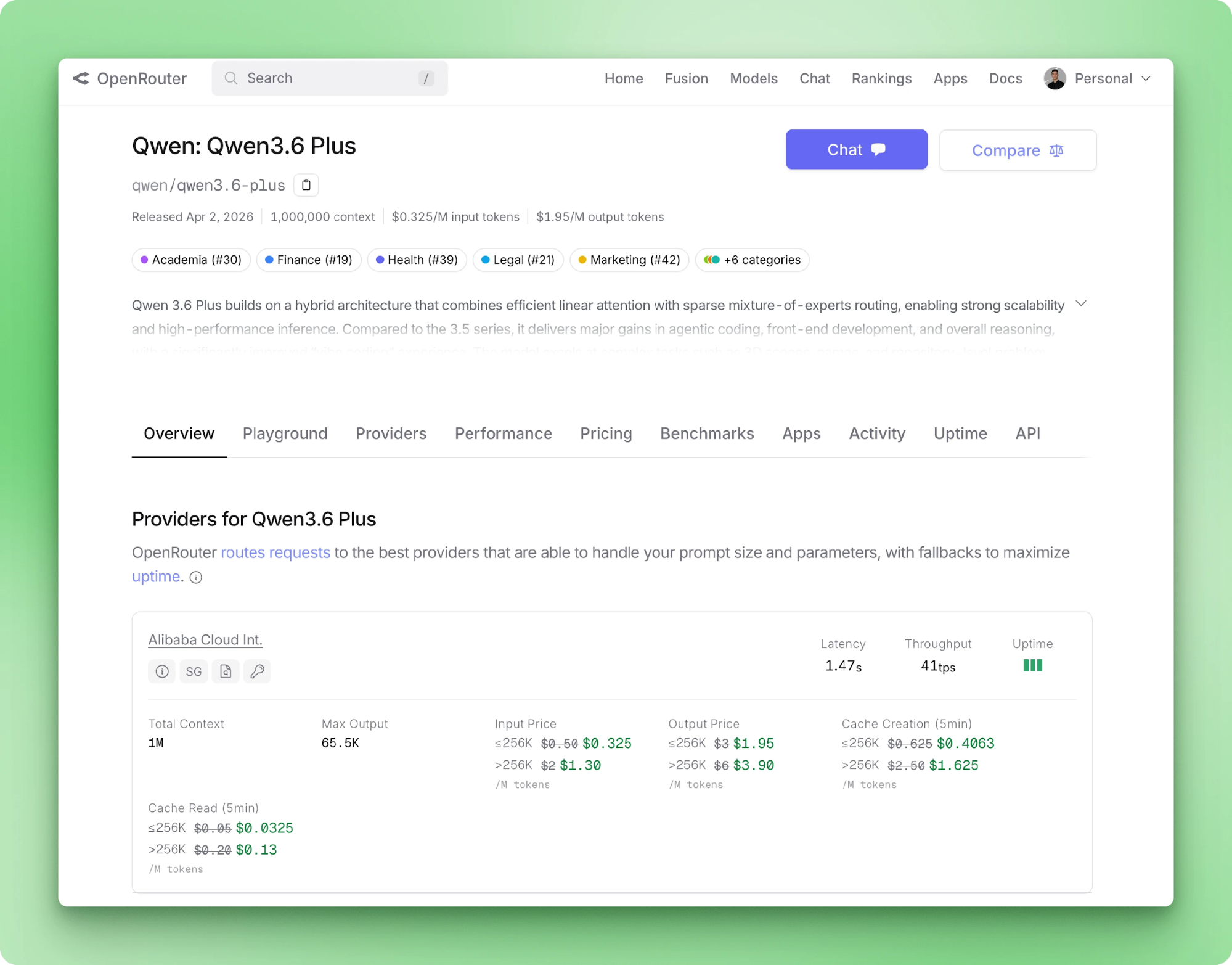
Chain-of-Thought はすべての呼び出しでデフォルト実行され、推論コンテンツは回答とは別フィールドでストリーミング返却されます。新しい 3.6 Plus のパラメータにより、ターンをまたいでメッセージに以前の推論痕跡を保持できます。
Alibaba は、後続のターンが先行する思考連鎖から利益を得るエージェントループでの利用を推奨しています。今回のようなワンショット抽出では、痕跡の保持はトークンの無駄なので無効化します。
このチュートリアルに関係するベンチマークは 3 つです:
最初の 2 つは、スキャン請求書を対象にする妥当性の根拠です。3 つ目は、重いプロンプトエンジニアリングなしでもツールコールプロトコルに従うと期待できる理由です。
3.5 Plus から 3.6 Plus へのバージョンアップは、多くの指標で小幅です。コーディングと推論系ベンチマークが数ポイント改善。より大きい変化は、推論がトグルからデフォルトになったこと。OCR と物体ローカライゼーションが最も改善しました。
|
機能 |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
推論モード |
デフォルトでオン( |
常時オンの CoT |
|
コンテキストウィンドウ |
最大 100 万トークン |
100 万トークン(標準) |
|
マルチモーダル |
ネイティブなビジョン・ランゲージ |
ネイティブ+OCR・物体ローカライゼーションの改善 |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
ターン間推論 |
— |
|
すでに 3.5 Plus を本番運用している場合、アップグレードでは新しい preserve_thinking パラメータの採用と、思考トークンがすべての呼び出しで課金対象になる点に注意が必要です。主なメリットはエージェントループとドキュメントビジョンで、まさに本チュートリアルの用途です。
モデルへのアクセス方法は 2 つあります。公式は Alibaba Cloud Model Studio で、エンドポイントは https://dashscope-intl.aliyuncs.com/compatible-mode/v1 です。もう一つは OpenRouter で、統一課金レイヤーの背後で Alibaba にルーティングされ、より簡単にサインアップできます。
このチュートリアルでは、鍵の作成が速く、エンドポイントの癖が少ないため OpenRouter を使います。直接接続に切り替えたい場合は、2 行変更するだけで続行できます。
Alibaba Cloud Model Studio も OpenRouter も、このチュートリアルでは同等に動作します。変わるのはベース URL と環境変数名だけです。
Google か GitHub アカウントで openrouter.ai にサインアップしてください。無料ティアはクレジットカード不要で、このチュートリアルを最初から最後まで進めるには十分です。今後大きなボリュームで実行する予定がある場合は、クレジットを追加するとスループットが高いティアに移行し、モデルごとのレート制限も緩和されます。
サインインしたら openrouter.ai/settings/keys に進み、キーを作成します。後で取り消しやすいように qwen-tutorial のようなラベルを付けておきます。
OpenRouter はキー値を一度しか表示しないので、今すぐコピーしてください。次に、プロジェクトのルートにある .env ファイルに保存します:
OPENROUTER_API_KEY=sk-or-v1-...次のセクションで python-dotenv で読み込みます。Alibaba Cloud を直接使う場合は、キーは modelstudio.console.alibabacloud.com から取得し、環境変数 DASHSCOPE_API_KEY に設定します。
最初の検証コールに必要な 2 パッケージをインストールします:
pip install openai python-dotenvopenai パッケージは OpenAI のエンドポイントで使用するのと同じ SDK です。OpenRouter も Alibaba Cloud Model Studio も OpenAI Chat Completions API を実装しているため、クライアントコードは変更不要です。
次のように hello.py を作成し、接続を確認します:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)python hello.py を実行すると短い返信が出力されるはずです。無料ティアでは、最初のトークンまでに数秒かかることがあります。これは、モデルが可視の回答を生成する前に推論痕跡を構築しているためです。
サンプルプロジェクトは請求書処理パイプラインです。テキスト PDF とスキャン JPG の 2 形式を受け付けます。各請求書は推論オンの Qwen 3.6 Plus に通され、抽出フィールドはツールコールで返ってきます。各請求書は次の 4 段階を通過します:
入力のデコード(画像は base64 化、PDF はまず各ページを画像に変換)
モデルから推論痕跡をストリーミング受信
ツールコールを構造化 JSON にパース
results.csv に 1 行書き込み
このセクションのコード一式は bextuychiev/qwen-invoice-pipeline-tutorial にあります。クローンして手を動かしても、独自実装時のリファレンスとして使ってもかまいません。
invoice-pipeline/ ディレクトリを作成し、次のように構成します:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtclient.py と各プロセッサを分けることで、OpenRouter の設定を 1 ファイルに集約できます。のちに Alibaba Cloud に切り替える場合も client.py だけを編集すれば済みます。
client.py は、適切なベース URL とモデル ID で OpenAI クライアントをラップします:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example も同梱して、クローンした人が何を設定すべきか分かるようにします:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1付属リポジトリには 3 つの出所から 6 件のサンプル請求書が含まれます:
実在企業の請求書は PII のため公開再配布できないので、代わりにこれらを使用します。パイプライン検証用に、正解の合計値はリポジトリの README に記載しています。
Qwen 3.5 を使っていたなら、CoT は extra_body 内の enable_thinking=True で切り替えるトグルでした。3.6 Plus では推論はデフォルト実行で、このパラメータは主にオフにするために存在します。思考が有効なときは推論トークンが常に課金対象になるため、「常時オン」は無料の機能ではなくコスト判断になります。
ストリーミング時は、まず delta.reasoning_content が届き、その後に delta.content(今回のケースでは delta.tool_calls)が続きます。
請求書を抽出し、ストリーミングされる推論痕跡を表示する最小コードは次のとおりです:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)ディスクから JPG のバイト列を読み取り、base64 化し、data: URI で包みます。この形式により、OpenAI のコンテンツブロックプロトコルがホスト済み URL なしでインライン画像を受け付けられます。 image_url ブロックは URI を直接受け取り、リンクを渡したのと同様にモデルが請求書を読み取れます。
extra_body={"enable_thinking": True} は enable_thinking フラグを Qwen に転送します。OpenAI SDK はこのパラメータを認識しないため、extra_body がプロバイダ固有オプションの受け渡し方法です。
invoice_04.jpg に対して実行すると、ストリーミングされた回答は短い要約として返ってきます:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51短いのは指定どおりです。システムプロンプトでは「要約」としか言っていません。タスクが大きくなる(明細行、カテゴリ、構造化フィールドなど)につれて、推論痕跡も増えます。次のセクションでは、同じモデル・同じ画像でも、回答する前に出力の大半を思考に費やす様子が見られます。
ユーザープロンプトに /no_think を付けるのは、そのコールで CoT を無効化するソフトスイッチです。デバッグ時に、思考なしの高速応答が欲しい場合に便利です。
推論は抽出過程を読みやすくしますが、出力は依然として推論痕跡内の自由記述テキストです。毎回構造化・パース可能な JSON を得るには、extract_invoice という 1 つのツールを定義し、モデルに常にツールを呼び出すよう指示するシステムプロンプトとともに tool_choice="auto" を設定します。
tools.py のスキーマでは 6 フィールドを記述します。外側の形は標準の OpenAI 関数ツール形式に従います:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}6 つのフィールドは parameters.properties の内側にあります。スカラーフィールド(vendor、date、total、tax)は素の JSON Schema 型を使用。category は enum を用いて、モデルがラベルを創作するのではなく 4 値の固定集合から選ぶようにします。line_items は構造化フィールドで、オブジェクトの配列。各オブジェクトは独自の required リストを持ちます:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},スキーマには 2 層の required があります。外側のリストは、あらゆる抽出で必ず現れるトップレベルフィールドを示します。各アイテム内のリストは、各明細行に必須のサブフィールドを示します。完全なスキーマは付属リポジトリの tools.py にあります。
引数は tool_calls[0].function.arguments の中に JSON 形式の文字列として返ってきます(パース済みオブジェクトではありません)。そのため json.loads を自前で呼び出します。ストリーミング時は、引数がデルタのシーケンスとして届くので、連結してからパースします。
注意点が 1 つ:OpenRouter の Qwen 3.6 Plus エンドポイントは強制ツールコールをサポートしません。tool_choice={"type": "function", "function": {"name": "extract_invoice"}} を指定すると、次のエラーになります:
No endpoints found that support the provided 'tool_choice' value実用的な対処は tool_choice="auto" を使い、システムプロンプトに頼ることです:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""付属リポジトリの 6 件すべてのサンプル請求書で、このプロンプトは毎回ツールコールを引き出せます。本番コードでは例外ケースに備えるべきです。finish_reason を確認し、tool_calls が埋まっているか検証し、そうでなければより強い指示でリトライします。Qwen の関数呼び出しドキュメントでも同様の注意が述べられています。ツールコール生成は保証されないため、本番コードにはフォールバックが必要です。
副作用として、構造化フィールドを要求するプロンプトにすると delta.reasoning_content が長文で埋まります。モデルは表を行ごとに解析し、invoice_04.jpg の欧州式小数表記を検討し、明細金額を合計と突き合わせます。この種のプロンプトでは、推論トークンが回答トークンの 10 倍以上になることがあります。
これは、構造化抽出で常時オン CoT を使うコストです。そのため preserve_thinking は、後続ターンが痕跡を読むマルチターンのエージェントループでのみ効果があります。今回はワンショット抽出なので、痕跡はターミナルに流し、破棄します。
JPG のフローは 3 ステップです:
ディスクから画像バイト列を読み取る
base64 エンコードする
data: URI を用いた image_url コンテンツブロックに入れる
PDF は、Qwen のビジョン経路が PDF ファイルではなく画像を直接受け付けるため、もう 1 ステップ必要です。 pdf2image で各ページを PIL 画像に変換し、同一メッセージ内でページごとに画像コンテンツブロックの配列として送ります。
両経路は同じモデル呼び出しを共有するため、呼び出しは processors/image.py に置き、processors/pdf.py はそれを委譲します。まずはインポート(上の SYSTEM_PROMPT は同モジュール内にあります):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveエンコーダは JPG パスを API が期待する data: URI に変換します:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"共有ヘルパー _call_with_images は、ユーザーコンテンツ配列(テキスト+1 枚以上の画像)を構築してストリーミングリクエストを送信します。ストリームからは 2 つのデータ片(推論痕跡とツールコール引数)を収集します。まずはリクエストのセットアップ:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)続いて、ストリームループで推論デルタとツールコール引数デルタを分離します:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}JPG 用の公開エントリポイントは、これらのヘルパーを使う 1 行です:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)PDF プロセッサは _call_with_images を再利用し、ページ→画像変換だけを追加します:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image は poppler のインストールが必要です。次でインストールします:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utils複数ページの PDF は、各ページを同一メッセージ内の独立した画像ブロックとして送ります。Qwen はそれらをまとめて読み取り、1 回の抽出結果を出します。合計が 2 ページ目にあるような請求書では、これが望ましい動作です。
150 DPI は、テキストの可読性を保ちつつペイロードの膨張を抑えます。これらのサンプルでの検証では、DPI を上げても精度は向上せず、リクエストだけが重くなりました。Alibaba のビジョン文書にサポート形式や上限が記載されています。
main.py は sample_invoices/ を走査し、拡張子でルーティング、該当プロセッサを呼び出し、結合結果を CSV に書き出します。まずはインポートと定数:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}メインループはサンプルディレクトリをソート順に反復し、拡張子でルーティング、各抽出を CSV 向けの 1 行に平坦化します:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})最後に、行をディスクへ書き出し、件数を出力します:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()python main.py を実行すると、6 件のサンプルを順に処理します。各請求書について、まずファイル名、ついで推論痕跡、そして抽出済み JSON がストリームされ、次の請求書へと進みます:
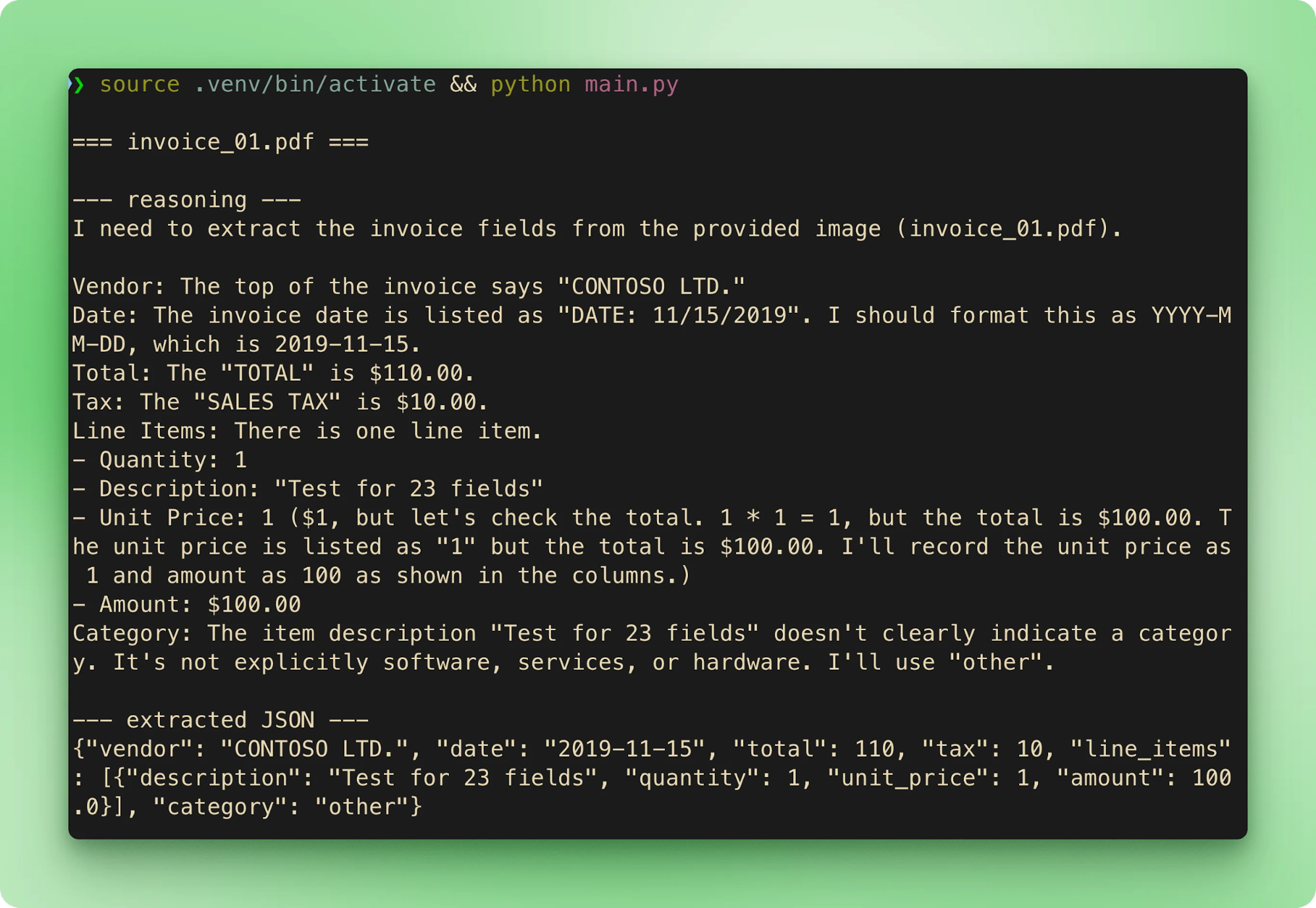
results.csv は各抽出を、請求書 1 件につき 1 行に集約します:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
合計は 6 件すべてで正解と一致しました。無料ティアでのレイテンシは請求書 1 件あたり 15〜40 秒程度。時間の大半は、ツールコールがストリーミングを始める前の推論フェーズです。
いくつかのパターンは、たまたま動くパイプラインと、実際の請求書でも継続的に動くパイプラインを分けます。
シークレットをコードに含めない。.env と python-dotenv のパターンは最低限の基準です。初回コミット前に .env を .gitignore に追加し、キーがリポジトリに入らないようにしてください。
指数バックオフでレート制限に対応する。OpenRouter はプロバイダごとの制限を HTTP 429 で課します。tenacity ライブラリはデコレータ方式の実装を提供しており、OpenAI クックブックのパターン(wait_random_exponential)はそのまま使えます。
応答が長くなる場合はストリーミングする。常時オン CoT はデフォルトで応答を膨らませます。非ストリーミングだと、可視化されるまでに推論ブロック全体の完了を待つ必要があります。ストリーミングなら早期フィードバックが得られ、UI の応答性が保たれ、明らかにおかしいリクエストを中断できます。
preserve_thinking は後続ターンが前の推論を読む場合のみ使用する。今回のようなワンショット抽出ではトークンの無駄です。マルチターンのエージェントループ(ツールコールの連鎖、計画タスク、デバッグワークフロー)では、ターンをまたぐ文脈のために存在します。Alibaba のdeep thinking ドキュメントには、1 コールあたりの推論トークン上限である thinking_budget についても記載があります。
無料ティアの応答は学習目的でログされる可能性がある。OpenRouter の無料ティアは、プロンプトを保持する可能性のあるプロバイダ経由でルーティングされます。実在の PII、顧客名、決済情報を含む請求書には不適切です。実データを流す前に、有料の OpenRouter ティア(または有料アカウントで Alibaba Cloud 直)へ移行してください。
Plus ティアはセルフホスティング不可。エアギャップやオンプレが必要なデプロイではホスト型 API は使えません。オープンソースの Qwen3.6-35B-A3B 変種は、そうした用途で検討に値する別オプションです。
推論開始時は最初のトークンまでが遅いことがある。タイムアウトは余裕を持って設定してください。画像入力では 30〜60 秒が妥当です。リトライロジックでは 429 とは別に、読み取りタイムアウトも個別に扱ってください。
常時オン CoT でも出力は決定的ではない。付属サンプルでの検証では、invoice_01.pdf は多くの実行で $610.00 と抽出されましたが、同一入力の再実行で少なくとも一度 $110.00 に反転しました。推論痕跡はいずれも正答に到達していたものの、最終的なツールコール引数が異なっていました。緩和策としては、temperature を低く設定(純粋な抽出なら 0.1〜0.2)し、正解と突き合わせるか、精度が重要なら 2 パス目を回してください。
ここから先は、パイプラインをエージェントフレームワークで包むのは小さな一歩です。ツールコールループ、ストリーミングパーサ、CSV ライターは、エージェントフレームワークが複数ターンにわたってオーケストレーションする基本要素と同じです。DataCamp の Developing LLM Applications with LangChain コースでは、メモリ、状態、マルチツールルーティングを伴うこれらのパターンを解説しています。
エージェント AI コース
Tracks
Tracks
Courses