track
Grunderna i AI-agenter
6 timmar
Alibaba släppte Qwen 3.6 Plus i april 2026. Specifikationen: SWE-bench Verified på 78,8, ett kontextfönster på 1M token som standard, inbyggda multimodala indata och alltid påslaget resonemang. För en Pythonutvecklare är det intressanta inte benchmarktabellen, utan att modellen endast finns via API och fungerar med vanliga OpenAI-paketet genom att byta bas-URL.
I den här handledningen använder vi tre av dess huvudfunktioner i ett projekt: chain-of-thought-resonemang, verktygsanrop för strukturerad utdata och bildförståelse på skannade fakturor. Resultatet är ett litet flöde för fakturahantering som läser PDF:er och JPG:er, visar sitt resonemang och returnerar validerad JSON som du kan skriva till en CSV.
Du behöver Python 3.10 eller nyare och vara bekväm med att göra API-anrop. Ingen GPU, inga modellnedladdningar, ingen self-hosting. Vi åtkommer Qwen 3.6 Plus via OpenRouter, så registreringen är enkel och OpenAI SDK fungerar oförändrat.
Jag rekommenderar starkt att du även kollar in vår handledning om finjustering av Qwen 3.6, den senaste open-weights-versionen av Qwen. Om du är intresserad av konkurrerande modeller, se till att läsa våra guider om DeepSeek v4, OpenAI:s GPT-5.5 och Anthropics Claude Opus 4.7.
Qwen 3.6 Plus är Alibabas flaggskeppsmodell från april 2026. Ryggraden är en hybrid av linjär uppmärksamhet och sparse mixture-of-experts, resonemang körs som standard, och text, bilder och video går alla genom samma API.
Funktion- (tool-) anrop använder OpenAIs protokoll för verktygsanrop. Alibaba positionerar släppet som ”mot verkliga agenter”, vilket betyder en modell för röriga indata som behöver resonemang, bildläsning och ett funktionsanrop i ett och samma steg.
Plus-nivån har stängda vikter. Du kan inte ladda ner checkpointen och köra den på din egen hårdvara (modellen är ändå för stor för konsumenthårdvara). Alibaba publicerar en öppen Qwen/Qwen3.6-35B-A3B-variant med 262K standardkontext, men det är en separat produkt. I den här handledningen använder vi det hostade API:et.
Qwen 3.6 Plus tar upp till 1M indatatoken och returnerar upp till 65 536 utdata-token per anrop. Indatatyperna inkluderar text, bild och video. Verktygsanrop är inbyggt via OpenAI-schemat. OpenRouters modellsida listar priser, leverantörslatens och genomströmning för de dirigerade backends.
Chain-of-thought körs som standard på varje anrop, och resonemangsinnehållet strömmas tillbaka i ett separat fält från svaret. En ny 3.6 Plus-parameter håller tidigare resonemangsspår kopplade till meddelanden över flera turer.
Alibaba rekommenderar det för agentloopar där senare turer drar nytta av tidigare tanke-kedjor. För engångsextraktion som vår, slösar det tokens att bevara spåret, så vi inaktiverar det.
Tre benchmarkpoäng är relevanta för den här handledningen:
De två första är skälen till att skannade fakturor är ett rimligt mål. Den tredje är varför vi kan förvänta oss att modellen följer ett protokoll för verktygsanrop utan tung prompt-ingenjörskonst.
Versionssprånget från 3.5 Plus till 3.6 Plus är litet på de flesta mått. Kodnings- och resonemangsbenchmarks får några poäng. Den större förändringen är att resonemang går från en brytare till standardläget. OCR och objektlokalisering förbättras mest.
|
Förmåga |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Resonemangsläge |
På som standard (kan inaktiveras med |
Alltid på CoT |
|
Kontextfönster |
Upp till 1M token |
1M token (standard) |
|
Multimodal |
Inbyggd vision-språk |
Inbyggd + förbättrad OCR, objektlokalisering |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Resonemang över turer |
— |
|
Om du har kört 3.5 Plus i produktion innebär uppgraderingen att du tar i bruk den nya preserve_thinking-parametern och noterar att tänkandet nu debiteras på varje anrop. De största vinsterna är i agentloopar och dokumentvision, vilket är vad den här handledningen använder.
Du kan komma åt modellen på två sätt. Det officiella är Alibaba Cloud Model Studio, som ger dig en direkt slutpunkt på https://dashscope-intl.aliyuncs.com/compatible-mode/v1. Det andra är OpenRouter, som dirigerar till Alibaba bakom ett enhetligt faktureringslager och en enklare registrering.
Handledningen använder OpenRouter eftersom flödet för nyckelskapande är snabbare och slutpunktsquirksen är färre. Om du vill gå direktvägen ändrar du två rader och fortsätter.
Alibaba Cloud Model Studio fungerar lika bra som OpenRouter för den här handledningen. Det enda som ändras är bas-URL och namnet på miljövariabeln.
Registrera dig på openrouter.ai med ett Google- eller GitHub-konto. Gratisnivån finns utan kreditkort, vilket räcker för att följa hela handledningen. Om du planerar att köra större volymer senare ger insatta krediter en högre genomströmningsnivå och tar bort per-modell-gränsen.
När du är inloggad, gå till openrouter.ai/settings/keys och skapa en nyckel. Döp den till något i stil med qwen-tutorial så att du kan återkalla den senare.
Kopiera nyckelvärdet nu, eftersom OpenRouter bara visar det en gång. Spara det sedan i en .env-fil i roten av ditt projekt:
OPENROUTER_API_KEY=sk-or-v1-...Vi laddar den med python-dotenv i nästa avsnitt. Om du hellre vill använda Alibaba Cloud direkt kommer nyckeln från modelstudio.console.alibabacloud.com och går in i DASHSCOPE_API_KEY istället.
Installera de två paket vi behöver för det första verifikationsanropet:
pip install openai python-dotenvPaketet openai är samma SDK som du skulle använda med OpenAIs slutpunkt. Både OpenRouter och Alibaba Cloud Model Studio implementerar OpenAI Chat Completions API, så klientkoden behöver inte ändras.
Skapa en fil som heter hello.py och verifiera anslutningen:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Att köra python hello.py ska skriva ut ett kort svar. Latensen till första token på gratisnivån kan ta några sekunder eftersom modellen bygger ett resonemangsspår innan den genererar det synliga svaret.
Exempelprojektet är ett flöde för fakturahantering. Det accepterar två format: text-PDF:er och skannade JPG:er. Varje faktura körs genom Qwen 3.6 Plus med resonemang påslaget, och de extraherade fälten kommer tillbaka via ett verktygsanrop. Varje faktura passerar fyra steg:
Avkoda indata (base64-koda bilden, eller konvertera varje PDF-sida till en bild först)
Strömma tillbaka resonemangsspåret från modellen
Parsa verktygsanropet till strukturerad JSON
Skriv en rad till results.csv
All kod för det här avsnittet finns i bextuychiev/qwen-invoice-pipeline-tutorial. Klona den för att följa med, eller använd den som referens när du bygger din egen variant.
Skapa en katalog invoice-pipeline/ och strukturera den så här:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtUppdelningen mellan client.py och processorerna håller OpenRouter-konfigurationen i en fil. Om du senare byter till Alibaba Cloud redigerar du client.py och inget annat.
client.py kapslar in OpenAI-klienten med rätt bas-URL och modell-ID:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example ligger bredvid så att alla som klonar repot vet vad som ska fyllas i:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Kompanjon-repot skickar med sex exempelfakturor från tre källor:
Riktiga företagsfakturor kan inte spridas offentligt på grund av PII, så vi använder dessa istället. Facit för totalsummor listas i repots README om du vill kontrollera flödet mot dem.
Om du har använt Qwen 3.5 var CoT en brytare per anrop: enable_thinking=True inne i extra_body. På 3.6 Plus körs resonemang som standard, och parametern finns mest för att stänga av det. Resonemangstoken debiteras alltid när tänkandet är aktivt, vilket gör ”alltid på” till ett kostnadsbeslut snarare än en gratisfunktion.
När du strömmar ett svar kommer delta.reasoning_content först, sedan följer delta.content (eller delta.tool_calls, i vårt fall).
Ett minimalt anrop som extraherar en faktura och skriver ut resonemangsspåret medan det strömmas ser ut så här:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Vi läser JPG-bitarna från disk, base64-kodar dem och kapslar in resultatet i ett data:-URI. Det formatet låter OpenAIs content-block-protokoll acceptera inline-bilder utan en hostad URL. image_url-blocket tar URI:n direkt, och modellen ser fakturan som om du hade skickat en länk.
extra_body={"enable_thinking": True} vidarebefordrar enable_thinking-flaggan till Qwen. OpenAI SDK känner inte till parametern, så extra_body är sättet att skicka leverantörsspecifika alternativ.
När du kör det mot invoice_04.jpg kommer det strömmade svaret tillbaka som en kort sammanfattning:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Kort är vad vi bad om: systemprompten sa ”sammanfatta” och inget mer. När uppgiften växer (radartiklar, kategorier, strukturerade fält) växer resonemangsspåret med den. Vi ser det i nästa avsnitt, där samma modell på samma bild lägger större delen av sin utdata-budget på att tänka innan den svarar.
Att lägga till /no_think till användarprompten är en mjuk brytare som inaktiverar CoT för det anropet. Användbart när du felsöker och vill ha ett snabbare svar utan tänkande.
Resonemang gör extraktionen läsbar, men utdata är fortfarande fritext i ett resonemangsspår. För att alltid få tillbaka strukturerad, parsbar JSON definierar vi ett verktyg, extract_invoice, och sätter tool_choice="auto" med en systemprompt som instruerar modellen att alltid anropa verktyget.
Schemat i tools.py beskriver sex fält. Ytterformen följer standardformatet för OpenAI-funktionsverktyg:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}De sex fälten ligger under parameters.properties. Skalära fält (vendor, date, total, tax) använder vanliga JSON Schema-typer. category använder en enum så att modellen väljer från en fast uppsättning av fyra värden istället för att hitta på etiketter. line_items är det enda strukturerade fältet, en array av objekt, var och en med sin egen required-lista:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Schemat har två nivåer av required. Den yttre listan markerar vilka toppnivåfält som måste finnas i varje extraktion. Listan per objekt markerar vilka underfält som måste finnas på varje radartikel. Hela schemat finns i tools.py i kompanjon-repot.
Argumenten kommer tillbaka som en JSON-formaterad sträng i tool_calls[0].function.arguments, inte ett parsat objekt, så du anropar json.loads själv. Vid strömning anländer argumenten som en sekvens av deltor som du konkatenerar före parsning.
En liten fallgrop: OpenRouters Qwen 3.6 Plus-endpoint stöder inte tvingade verktygsanrop. Om du provar tool_choice={"type": "function", "function": {"name": "extract_invoice"}} returnerar begäran ett fel:
No endpoints found that support the provided 'tool_choice' valueDen praktiska lösningen är att använda tool_choice="auto" och lita på systemprompten:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Över alla sex exempelfakturor i kompanjon-repot ger den här prompten ett verktygsanrop varje gång. Produktkod bör ändå gardera mot undantagsfallet: kontrollera finish_reason, verifiera att tool_calls är ifyllt, och försök igen med en skarpare instruktion om det inte är det. Qwens egna funktion-anropsdokumentation säger samma sak. Generering av verktygsanrop är inte garanterad, och produktionskod behöver en fallback.
En bieffekt: när prompten väl ber om strukturerade fält fylls delta.reasoning_content med ett långt spår. Modellen tolkar tabellen rad för rad, överväger europeisk decimalkonvention på invoice_04.jpg och korscheckar radartiklarnas belopp mot totalen. Resonemangstoken kan vara 10x fler än svarstoken på den här typen av prompt.
Det är kostnaden för alltid påslaget CoT vid strukturerad extraktion, vilket är anledningen till att preserve_thinking bara lönar sig i flerstegs agentloopar där en senare tur läser spåret. Vi gör engångsextraktion, så spåret strömmas till terminalen och vi kastar bort det.
För JPG:er är flödet tre steg:
Läs bildbitarna från disk
Base64-koda dem
Lägg resultatet i ett image_url-innehållsblock med ett data:-URI
PDF:er behöver ett extra steg eftersom Qwens visionsväg accepterar bilder snarare än PDF-filer direkt. Konvertera varje sida till en PIL-bild med pdf2image och skicka sedan sidorna som en lista med bildinnehållsblock i samma meddelande.
Båda vägarna delar samma modellanrop, så anropet ligger i processors/image.py och processors/pdf.py delegerar till det. Börja med importerna (SYSTEM_PROMPT ovan finns i samma modul):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveEnkodaren gör en JPG-sökväg till det data:-URI som API:et förväntar sig:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Den delade hjälpfunktionen _call_with_images bygger användarinnehållsarrayen (text + en eller flera bilder) och skickar det strömmande anropet. Från strömmen samlar den in två datapunkter: resonemangsspåret och argumenten till verktygsanropet. Själva begäran först:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Sedan separerar strömloopen resonemangsdelton från delton för verktygsanropsargument:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Det publika ingångssnittet för JPG:er är en one-liner som använder dessa hjälpmetoder:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)PDF-processorn återanvänder _call_with_images och lägger bara till konverteringen från sida till bild:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image kräver att poppler är installerat. Installera det med:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsFör PDF:er med flera sidor, skicka varje sida som sitt eget bildblock i samma meddelande. Qwen läser dem tillsammans och producerar en extraktion, vilket är vad du vill ha för en faktura där totalsumman finns på sida 2.
150 DPI håller fakturatexten läsbar utan att blåsa upp payloaden. Högre upplösning gör begäran större utan att förbättra noggrannheten i tester mot dessa exempel. Alibabas visionsdokumentation täcker stödformat och övre gränser.
main.py går igenom sample_invoices/, dirigerar varje fil efter filändelse, anropar rätt processor och skriver de kombinerade resultaten till en CSV. Importer och konstanter först:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Huvudloopen itererar provkatalogen i sorterad ordning, dirigerar efter filändelse och plattar ut varje extraktion till en CSV-vänlig rad:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Till sist, skriv raderna till disk och logga antalet:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Att köra python main.py går igenom de sex exemplen i ordning. Varje faktura strömmar sitt filnamn, sedan resonemangsspåret, sedan den extraherade JSON:en, innan den går vidare till nästa:
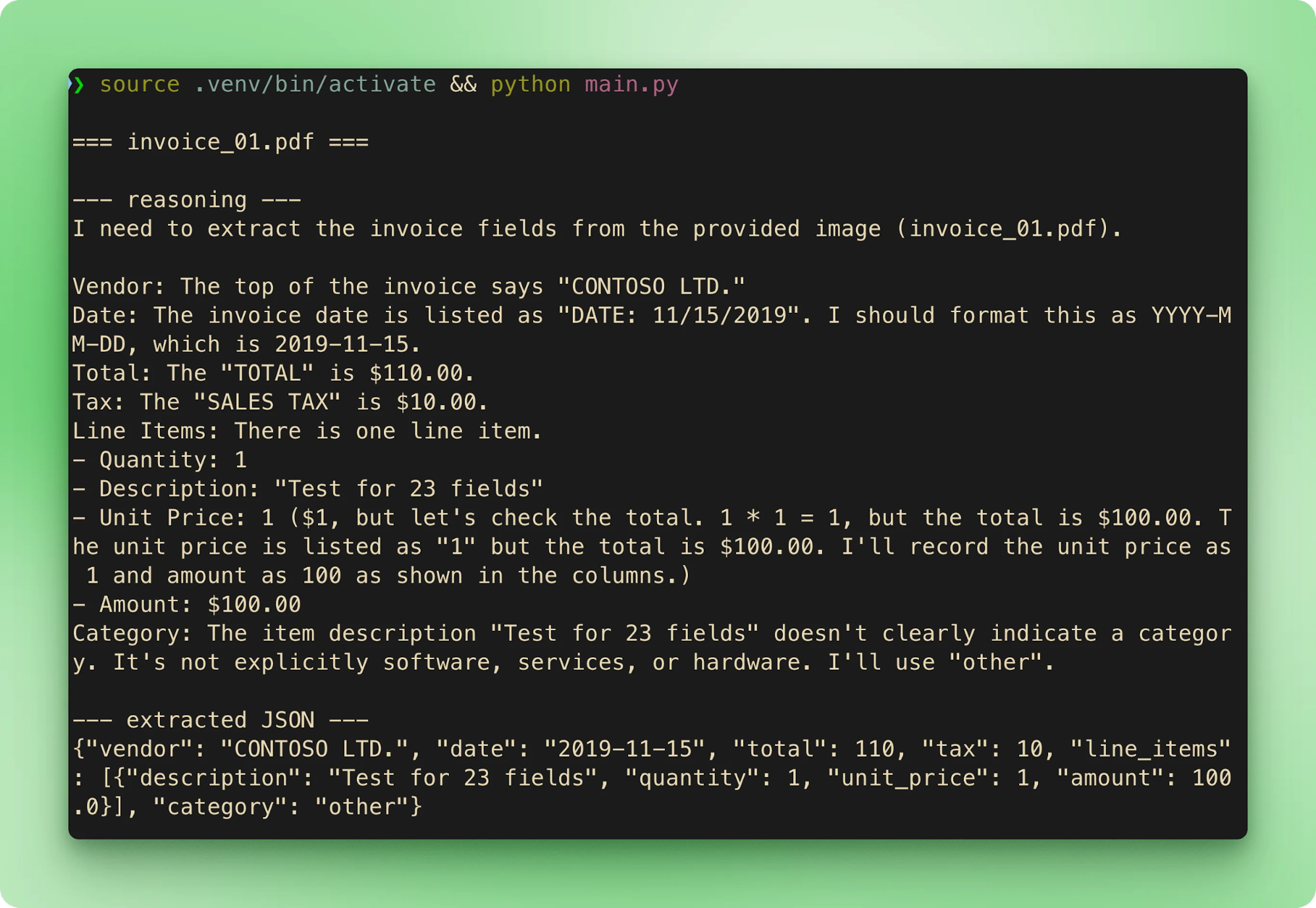
results.csv samlar varje extraktion till en rad per faktura:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Totalsummorna matchar facit på alla sex. Latensen på gratisnivån ligger på 15 till 40 sekunder per faktura. Det mesta av tiden är resonemangsfasen innan verktygsanropet börjar strömma.
Några mönster gör skillnaden mellan ett flöde som fungerar en gång och ett som fortsätter att fungera på riktiga fakturor.
Håll hemligheter borta från koden. Mönstret med .env och python-dotenv som vi har använt är baslinjen. Lägg till .env i din .gitignore innan första commiten så att nyckeln aldrig når repot.
Hantera ratelimitar med exponentiell backoff. OpenRouter upprätthåller leverantörsspecifika gränser med HTTP 429-svar. Biblioteket tenacity ger en dekoratorbaserad implementation, och OpenAIs cookbook-mönster för wait_random_exponential fungerar utan ändringar.
Strömma när svaren blir långa. Alltid påslaget CoT blåser upp svarslängden som standard. Icke-strömmande anrop innebär att vänta på hela resonemangsblocket innan du ser något. Strömning ger tidig återkoppling, håller UI:et responsivt och låter dig avbryta en begäran som uppenbart är på väg åt fel håll.
Använd preserve_thinking bara när senare turer läser tidigare resonemang. För engångsextraktorer som detta flöde är det bortkastade token. För flerstegs agentloopar (kedjor av verktygsanrop, planeringsuppgifter, debuggarbetsflöden) finns parametern just för det tvärturnssammanhanget. Alibabas djupt tänkande-dokumentation täcker också thinking_budget, ett hårt tak för resonemangstoken per anrop.
Svar på gratisnivån kan loggas för träning. OpenRouters gratisnivå dirigerar genom leverantörer som kan behålla prompts. Det gör den olämplig för fakturor med verklig PII, kundnamn eller betalningsuppgifter. Gå över till en betald OpenRouter-nivå (eller direkt till Alibaba Cloud med ett betalt konto) innan verklig data körs genom flödet.
Ingen self-hosting på Plus-nivån. Utrullningar som kräver air gap eller on-prem kan inte använda det hostade API:et. Den öppna varianten Qwen3.6-35B-A3B är ett separat alternativ värt att överväga i de fallen.
Tid till första token kan vara långsam när resonemanget startar. Sätt generösa timeouts, 30 till 60 sekunder är rimligt för bildindata. Se till att din retry-logik hanterar read timeouts separat från 429:or.
Utdata är inte deterministisk även med alltid på CoT. I tester mot exemplen i kompanjon-repot extraherades invoice_01.pdf som $610,00 i de flesta körningar. Vid minst en omkörning med identiska indata blev det $110,00. Resonemangsspåret nådde rätt svar båda gångerna, men det slutliga argumentet till verktygsanropet skilde sig. Två åtgärder: sätt låg temperature (0,1 till 0,2 för ren extraktion), och validera mot facit eller använd en andra pass när noggrannhet är tillräckligt viktig för att motivera ett extra anrop.
Härifrån är steget litet till att kapsla in flödet i ett agentramverk. Verktygsanropsloopen, den strömmande parsern och CSV-skrivaren är samma primitiv som ett agentramverk orkestrerar över många turer. DataCamps kurs Developing LLM Applications with LangChain går igenom dessa mönster med minne, tillstånd och routing mellan flera verktyg.
Agentiska AI-kurser
track
track
course