Track
Podstawy agentów AI
6 godz.
Alibaba udostępniła Qwen 3.6 Plus w kwietniu 2026 r. Parametry: SWE-bench Verified na poziomie 78,8, domyślne okno kontekstu 1 mln tokenów, natywne wejścia multimodalne i zawsze włączone rozumowanie. Dla programisty Pythona najciekawsze nie są tabelki z benchmarkami, tylko to, że model jest dostępny wyłącznie przez API i działa z podstawowym pakietem OpenAI po podmianie bazowego URL-a.
W tym samouczku użyjemy trzech głównych funkcji w jednym projekcie: rozumowania łańcucha myśli (chain-of-thought), wywoływania narzędzi dla ustrukturyzowanego wyjścia oraz wizji do zeskanowanych faktur. Efektem będzie mały pipeline przetwarzania faktur, który czyta pliki PDF i JPG, pokazuje swoje rozumowanie i zwraca zweryfikowany JSON, który można zapisać do CSV.
Potrzebny jest Python 3.10 lub nowszy oraz podstawowa znajomość wywołań API. Bez GPU, bez pobierania modeli, bez self-hostingu. Uzyskamy dostęp do Qwen 3.6 Plus przez OpenRouter, więc rejestracja to jeden formularz, a OpenAI SDK działa bez zmian.
Gorąco polecam także nasz samouczek o dostrajaniu Qwen 3.6, najnowszej wersji Qwen z otwartymi wagami. Jeśli interesują Pana/Panią modele konkurencyjne, proszę zajrzeć do naszych przewodników po DeepSeek v4, GPT-5.5 od OpenAI oraz Claude Opus 4.7 od Anthropic.
Qwen 3.6 Plus to flagowy model Alibaba z kwietnia 2026 r. Rdzeń to hybryda uwagi liniowej i rzadkiej mieszanki ekspertów; rozumowanie działa domyślnie, a tekst, obrazy i wideo trafiają przez to samo API.
Wywoływanie funkcji korzysta z protokołu OpenAI dla wywołań narzędzi. Alibaba pozycjonuje wydanie jako „w kierunku agentów do realnych zastosowań”, czyli jeden model do nieuporządkowanych danych wejściowych wymagających rozumowania, odczytu obrazu i wywołania funkcji w jednym kroku.
Warstwa Plus ma zamknięte wagi. Nie można pobrać checkpointu i uruchomić go na własnym sprzęcie (model i tak jest zbyt duży na sprzęt konsumencki). Alibaba publikuje otwartoźródłową wersję Qwen/Qwen3.6-35B-A3B z domyślnym kontekstem 262K, ale to osobny produkt. W tym samouczku korzystamy z hostowanego API.
Qwen 3.6 Plus przyjmuje do 1 mln tokenów wejściowych i zwraca do 65 536 tokenów wyjściowych na wywołanie. Obsługiwane modality wejściowe to tekst, obraz i wideo. Wywoływanie narzędzi jest natywne przez schemat OpenAI. Na stronie modelu OpenRouter znajdzie Pan/Pani ceny, opóźnienia po stronie dostawców oraz przepustowość trasowanych backendów.
Chain-of-thought działa domyślnie przy każdym wywołaniu, a treść rozumowania strumieniuje w osobnym polu względem odpowiedzi. Nowy parametr 3.6 Plus utrzymuje poprzednie ślady rozumowania przy wiadomościach między turami.
Alibaba zaleca to do pętli agentowych, gdzie późniejsze tury korzystają z wcześniejszych łańcuchów myśli. Przy ekstrakcji jednorazowej, jak u nas, zachowywanie śladu marnuje tokeny, więc je wyłączamy.
Dla tego samouczka istotne są trzy wyniki benchmarków:
Pierwsze dwa powody sprawiają, że zeskanowane faktury są rozsądnym celem. Trzeci oznacza, że możemy oczekiwać, iż model będzie przestrzegać protokołu wywoływania narzędzi bez ciężkiego inżynierii promptów.
Przeskok wersji z 3.5 Plus do 3.6 Plus jest niewielki w większości metryk. Benchmarki kodowania i rozumowania zyskują kilka punktów. Większą zmianą jest to, że rozumowanie z opcji staje się domyślne. Najbardziej poprawiły się OCR i lokalizacja obiektów.
|
Możliwość |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Tryb rozumowania |
Domyślnie włączony (można wyłączyć przez |
Zawsze włączony CoT |
|
Okno kontekstu |
Do 1 mln tokenów |
1 mln tokenów (domyślnie) |
|
Multimodalność |
Natywna wizja-język |
Natywna + ulepszone OCR i lokalizacja obiektów |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Rozumowanie między turami |
— |
parametr |
Jeśli uruchamia Pan/Pani 3.5 Plus w produkcji, aktualizacja oznacza przyjęcie nowego parametru preserve_thinking i świadomość, że myślenie jest teraz rozliczane przy każdym wywołaniu. Główne zyski dotyczą pętli agentowych i wizji dokumentów, z czego korzysta ten samouczek.
Do modelu można uzyskać dostęp na dwa sposoby. Oficjalny to Alibaba Cloud Model Studio, które daje bezpośredni endpoint pod https://dashscope-intl.aliyuncs.com/compatible-mode/v1. Drugim jest OpenRouter, który trasuje do Alibaba za wspólną warstwą rozliczeń i prostszą rejestracją.
W tym samouczku używamy OpenRouter, ponieważ tworzenie klucza jest szybsze, a specyfiki endpointu — mniej uciążliwe. Jeśli woli Pan/Pani ścieżkę bezpośrednią, proszę zmienić dwie linie i kontynuować.
Alibaba Cloud Model Studio sprawdzi się w tym samouczku równie dobrze jak OpenRouter. Zmieniają się tylko bazowy URL i nazwa zmiennej środowiskowej.
Proszę zarejestrować się na openrouter.ai kontem Google lub GitHub. Darmowy plan jest dostępny bez karty, co wystarczy, by przejść przez ten samouczek od początku do końca. Jeśli później planuje Pan/Pani większe wolumeny, doładowanie konta daje wyższą warstwę przepustowości i znosi limit szybkości per model.
Po zalogowaniu proszę przejść do openrouter.ai/settings/keys i utworzyć klucz. Proszę go nazwać np. qwen-tutorial, aby można go było później odwołać.
Proszę teraz skopiować wartość klucza, ponieważ OpenRouter pokazuje ją tylko raz. Następnie proszę zapisać ją w pliku .env w katalogu głównym projektu:
OPENROUTER_API_KEY=sk-or-v1-...Załadujemy go za pomocą python-dotenv w następnej sekcji. Jeśli woli Pan/Pani bezpośrednio Alibaba Cloud, klucz pochodzi z modelstudio.console.alibabacloud.com i trafia do DASHSCOPE_API_KEY.
Proszę zainstalować dwa pakiety potrzebne do pierwszego wywołania testowego:
pip install openai python-dotenvPakiet openai to to samo SDK, którego używał(a)by Pan/Pani z endpointem OpenAI. Zarówno OpenRouter, jak i Alibaba Cloud Model Studio implementują OpenAI Chat Completions API, więc kod klienta nie wymaga zmian.
Proszę utworzyć plik hello.py i zweryfikować połączenie:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Uruchomienie python hello.py powinno wydrukować krótką odpowiedź. Opóźnienie pierwszego tokena w darmowej warstwie może wynosić kilka sekund, ponieważ model buduje ślad rozumowania przed wygenerowaniem widocznej odpowiedzi.
Przykładowy projekt to pipeline przetwarzania faktur. Akceptuje dwa formaty: tekstowe PDF-y i zeskanowane JPG-i. Każda faktura przechodzi przez Qwen 3.6 Plus z włączonym rozumowaniem, a wyodrębnione pola wracają przez wywołanie narzędzia. Każda faktura przechodzi przez cztery etapy:
Dekodowanie wejścia (base64 dla obrazu lub wcześniejsza konwersja każdej strony PDF na obraz)
Strumieniowanie śladu rozumowania z modelu
Parsowanie wywołania narzędzia do ustrukturyzowanego JSON-a
Zapis wiersza do results.csv
Cały kod dla tej sekcji znajduje się w bextuychiev/qwen-invoice-pipeline-tutorial. Proszę sklonować repozytorium, aby śledzić krok po kroku lub używać go jako odniesienia przy budowie własnej wersji.
Proszę utworzyć katalog invoice-pipeline/ i ułożyć go tak:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtPodział między client.py a procesorami trzyma konfigurację OpenRouter w jednym pliku. Jeśli później przejdzie Pan/Pani na Alibaba Cloud, wystarczy edycja client.py i nic więcej.
client.py opakowuje klienta OpenAI z właściwym bazowym URL-em i identyfikatorem modelu:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example leży obok, aby każdy klonujący repozytorium wiedział, co uzupełnić:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Repozytorium towarzyszące zawiera sześć przykładowych faktur z trzech źródeł:
Prawdziwych faktur firmowych nie można publicznie rozpowszechniać z powodu danych osobowych, więc korzystamy z tych. Prawdziwe sumy znajdują się w README repozytorium, jeśli chce Pan/Pani porównać pipeline z wartościami referencyjnymi.
Jeśli używał(a) Pan/Pani Qwen 3.5, CoT był przełącznikiem per wywołanie: enable_thinking=True wewnątrz extra_body. W 3.6 Plus rozumowanie działa domyślnie, a parametr istnieje głównie po to, aby je wyłączyć. Tokeny rozumowania są zawsze rozliczane, gdy myślenie jest aktywne, co czyni „zawsze włączone” decyzją kosztową, a nie darmową funkcją.
Przy strumieniowaniu odpowiedzi delta.reasoning_content dociera jako pierwsze, a potem delta.content (albo delta.tool_calls — w naszym przypadku).
Minimalne wywołanie, które wyodrębnia fakturę i drukuje ślad rozumowania podczas strumieniowania, wygląda tak:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Czytamy bajty JPG z dysku, kodujemy base64 i opakowujemy wynik w URI data:. Ten format pozwala protokołowi bloków treści OpenAI przyjąć obrazy inline bez hostowanego URL-a. Blok image_url przyjmuje URI bezpośrednio, a model widzi fakturę tak, jakby podano link.
extra_body={"enable_thinking": True} przekazuje flagę enable_thinking do Qwen. SDK OpenAI nie zna tego parametru, więc extra_body służy do przekazywania opcji specyficznych dla dostawcy.
Przy uruchomieniu na invoice_04.jpg strumieniowana odpowiedź wraca jako krótkie podsumowanie:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Krótko — zgodnie z prośbą: w system prompt było „podsumuj” i nic więcej. Gdy zadanie rośnie (pozycje, kategorie, pola ustrukturyzowane), rośnie też ślad rozumowania. Zobaczymy to w następnej sekcji: ten sam model na tym samym obrazie większość budżetu wyjścia spędza na myśleniu, zanim odpowie.
Dodanie /no_think do promptu użytkownika to miękki przełącznik, który wyłącza CoT dla danego wywołania. Przydatne przy debugowaniu, gdy potrzebna jest szybsza odpowiedź bez rozumowania.
Rozumowanie czyni ekstrakcję czytelną, ale wyjście wciąż jest swobodnym tekstem wewnątrz śladu rozumowania. Aby zawsze otrzymywać ustrukturyzowany, parsowalny JSON, definiujemy jedno narzędzie, extract_invoice, i ustawiamy tool_choice="auto" z promptem systemowym nakazującym zawsze wywołać narzędzie.
Schemat w tools.py opisuje sześć pól. Zewnętrzny kształt podąża za standardowym formatem narzędzia-funkcji OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Sześć pól znajduje się wewnątrz parameters.properties. Pola skalarne (vendor, date, total, tax) używają zwykłych typów JSON Schema. category używa enum, aby model wybierał z ustalonego zbioru czterech wartości zamiast wymyślać etykiety. line_items to jedyne pole ustrukturyzowane — tablica obiektów, z własną listą required dla każdej pozycji:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Schemat ma dwa poziomy required. Zewnętrzna lista oznacza, które pola najwyższego poziomu muszą pojawić się w każdej ekstrakcji. Lista per pozycja oznacza, które podpola muszą pojawić się w każdej pozycji. Pełny schemat znajduje się w tools.py w repozytorium towarzyszącym.
Argumenty wracają jako łańcuch w formacie JSON wewnątrz tool_calls[0].function.arguments, a nie sparsowany obiekt, więc trzeba samodzielnie wywołać json.loads. Przy strumieniowaniu argumenty docierają jako sekwencja delt, które należy skleić przed parsowaniem.
Uwaga: endpoint Qwen 3.6 Plus w OpenRouter nie obsługuje wymuszonych wywołań narzędzi. Próba użycia tool_choice={"type": "function", "function": {"name": "extract_invoice"}} zwraca błąd:
No endpoints found that support the provided 'tool_choice' valuePraktyczne rozwiązanie to użycie tool_choice="auto" i poleganie na promcie systemowym:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""We wszystkich sześciu przykładowych fakturach w repozytorium towarzyszącym ten prompt skutkuje wywołaniem narzędzia za każdym razem. Kod produkcyjny i tak powinien zabezpieczyć przypadek wyjątkowy: sprawdzić finish_reason, zweryfikować, czy tool_calls jest wypełnione, i ponowić z ostrzejszą instrukcją, jeśli nie. Dokumentacja Qwen dotycząca wywoływania funkcji potwierdza to samo. Generowanie wywołania narzędzia nie jest gwarantowane i kod produkcyjny musi mieć fallback.
Efekt uboczny: gdy prompt prosi o pola ustrukturyzowane, delta.reasoning_content wypełnia się długim śladem. Model parsuje tabelę wiersz po wierszu, rozważa europejską notację dziesiętną na invoice_04.jpg i weryfikuje kwoty pozycji wobec sumy. Tokeny rozumowania mogą przewyższać tokeny odpowiedzi 10x lub więcej przy tego typu promptach.
Taki jest koszt zawsze włączonego CoT przy ekstrakcji ustrukturyzowanej, dlatego preserve_thinking opłaca się tylko w wieloturach agentowych, gdzie późniejsza tura czyta ślad. U nas ekstrakcja jest jednorazowa, więc ślad strumieniuje do terminala i go odrzucamy.
Dla JPG-ów przepływ to trzy kroki:
Odczyt bajtów obrazu z dysku
Kodowanie ich w base64
Wstawienie wyniku do bloku treści image_url z URI data:
PDF-y wymagają jednego dodatkowego kroku, ponieważ ścieżka wizji Qwen akceptuje obrazy, a nie pliki PDF bezpośrednio. Proszę przekonwertować każdą stronę na obraz PIL za pomocą pdf2image, a następnie wysłać strony jako listę bloków obrazów w tej samej wiadomości.
Obie ścieżki współdzielą to samo wywołanie modelu, więc wywołanie mieszka w processors/image.py, a processors/pdf.py deleguje do niego. Zacznijmy od importów (SYSTEM_PROMPT powyżej znajduje się w tym samym module):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveEnkoder zamienia ścieżkę JPG na URI data: oczekiwany przez API:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Wspólny helper _call_with_images buduje tablicę treści użytkownika (tekst + jeden lub więcej obrazów) i wysyła żądanie strumieniowe. Ze strumienia zbiera dwie rzeczy: ślad rozumowania i argumenty wywołania narzędzia. Najpierw konfiguracja żądania:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Następnie pętla strumienia rozdziela delty rozumowania od delt argumentów wywołania narzędzia:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Publiczny punkt wejścia dla JPG-ów to one-liner korzystający z tych helperów:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Procesor PDF ponownie wykorzystuje _call_with_images i dodaje tylko konwersję strony na obraz:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image wymaga zainstalowanego poppler. Instalacja:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsDla wielostronicowych PDF-ów proszę wysłać każdą stronę jako osobny blok obrazu w tej samej wiadomości. Qwen czyta je razem i produkuje jedną ekstrakcję — tak jak potrzeba, gdy sumy są na stronie 2.
150 DPI utrzymuje tekst faktury czytelny bez nadmiernego powiększania ładunku. Wyższe wartości zwiększają rozmiar żądania bez poprawy dokładności w testach na tych próbkach. Dokumentacja wizji Alibaba (vision documentation) obejmuje obsługiwane formaty i limity.
main.py przechodzi po sample_invoices/, kieruje każdy plik po rozszerzeniu, wywołuje odpowiedni procesor i zapisuje łączne wyniki do CSV. Najpierw importy i stałe:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Główna pętla iteruje katalog próbek w porządku sortowania, kieruje wg rozszerzenia pliku i spłaszcza każdą ekstrakcję do wiersza przyjaznego dla CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Na koniec zapis wierszy na dysk i log liczby:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Uruchomienie python main.py przechodzi przez sześć próbek po kolei. Każda faktura strumieniuje swoją nazwę pliku, potem ślad rozumowania, potem wyodrębniony JSON, po czym przechodzi do następnej:
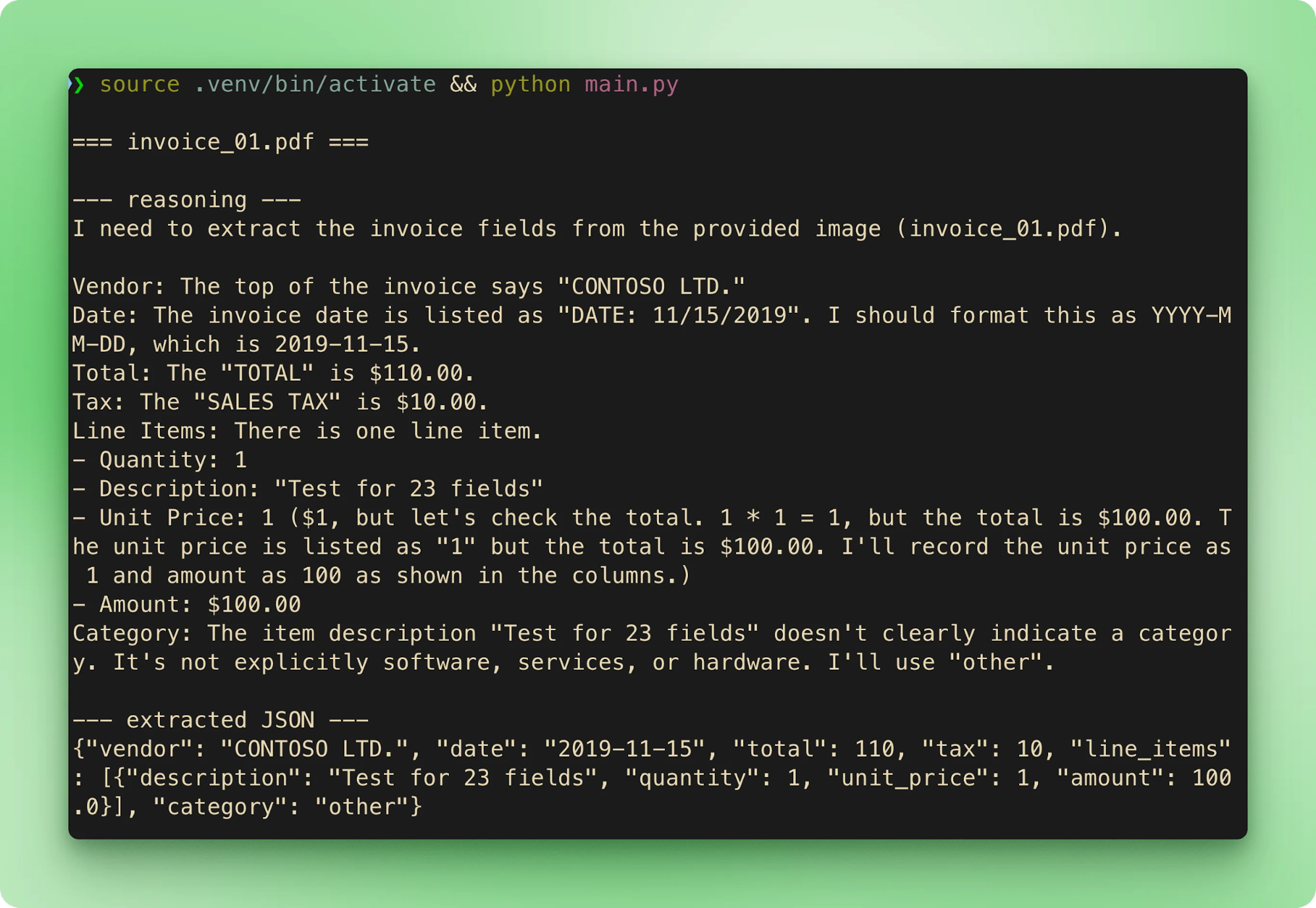
results.csv agreguje każdą ekstrakcję do jednego wiersza na fakturę:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Suma zgadza się z wartościami referencyjnymi dla wszystkich sześciu. Opóźnienie w darmowej warstwie wynosi 15–40 sekund na fakturę. Większość czasu to faza rozumowania przed rozpoczęciem strumieniowania wywołania narzędzia.
Kilka wzorców decyduje o tym, czy pipeline zadziała raz, czy będzie działał na prawdziwych fakturach.
Nie umieszczać sekretów w kodzie. Wzorzec z .env i python-dotenv, którego używamy, to podstawa. Proszę dodać .env do .gitignore przed pierwszym commitem, aby klucz nigdy nie trafił do repozytorium.
Obsługiwać limity zapytań przez wykładniczy backoff. OpenRouter egzekwuje limity per dostawca kodem HTTP 429. Biblioteka tenacity oferuje implementację dekoratorową, a wzorzec z cookbooka OpenAI dla wait_random_exponential działa bez zmian.
Strumieniować, gdy odpowiedzi będą długie. Zawsze włączony CoT domyślnie wydłuża odpowiedzi. Wywołania niestreamingowe oznaczają czekanie na cały blok rozumowania, zanim cokolwiek się pojawi. Strumieniowanie daje wczesny feedback, utrzymuje responsywność UI i pozwala przerwać żądanie, które wyraźnie idzie w złą stronę.
Używać preserve_thinking tylko wtedy, gdy późniejsze tury czytają wcześniejsze rozumowanie. W ekstraktorach jednorazowych, jak ten pipeline, to zmarnowane tokeny. W wieloturach agentowych (łańcuchy wywołań narzędzi, zadania planistyczne, workflow debugowania) parametr służy właśnie temu kontekstowi między turami. Dokumentacja Alibaba o deep thinking opisuje też thinking_budget, twardy limit tokenów rozumowania na wywołanie.
Odpowiedzi w darmowej warstwie mogą być logowane do trenowania. Darmowy plan OpenRouter trasuje przez dostawców, którzy mogą zachowywać prompty. To go dyskwalifikuje dla faktur z prawdziwymi danymi osobowymi, nazwami klientów czy danymi płatności. Przed uruchomieniem prawdziwych danych proszę przejść na płatny plan OpenRouter (lub bezpośrednio do Alibaba Cloud na koncie płatnym).
Brak self-hostingu w warstwie Plus. Wdrożenia wymagające izolacji sieciowej lub on-prem nie mogą używać hostowanego API. Otwartoźródłowy wariant Qwen3.6-35B-A3B to osobna opcja do rozważenia w takich przypadkach.
Czas do pierwszego tokena może być długi przy starcie rozumowania. Proszę ustawiać timeouty hojnie — 30–60 sekund to rozsądnie dla wejścia obrazowego. Warto też rozdzielić w logice retry timeouty odczytu od błędów 429.
Wyjście nie jest deterministyczne, nawet przy zawsze włączonym CoT. W testach na próbkach z repo, invoice_01.pdf zwykle dawała 610,00 $, ale przynajmniej raz przy identycznych wejściach wyszło 110,00 $. Ślad rozumowania dochodził do poprawnej odpowiedzi w obu przypadkach, ale ostateczny argument wywołania narzędzia się różnił. Dwie mitigacje: niskie temperature (0,1–0,2 dla czystej ekstrakcji) oraz walidacja względem prawdy referencyjnej lub drugi przebieg, gdy dokładność uzasadnia dodatkowe wywołanie.
Stąd do opakowania pipeline'u w framework agentski jest już niedaleko. Pętla wywołań narzędzi, parser strumienia i zapis do CSV to te same prymitywy, które framework agentowy orkiestruje przez wiele tur. Kurs DataCamp Developing LLM Applications with LangChain prowadzi przez te wzorce z pamięcią, stanem i trasowaniem między narzędziami.
Kursy o agentach AI
Track
Track
course