Track
एआई एजेंट मूलभूत बातें
6 घंटा
Alibaba ने अप्रैल 2026 में Qwen 3.6 Plus जारी किया। स्पेक शीट: SWE-bench Verified 78.8, डिफॉल्ट रूप से 1M-टोकन कॉन्टेक्स्ट विंडो, नैटिव मल्टीमॉडल इनपुट, और हमेशा-ऑन रीजनिंग। एक Python डेवलपर के लिए दिलचस्प बात बेंचमार्क तालिका नहीं है। यह है कि मॉडल केवल API के माध्यम से उपलब्ध है और बेस URL बदल कर साधारण OpenAI पैकेज के साथ काम करता है।
इस ट्यूटोरियल में, हम एक ही प्रोजेक्ट में इसकी तीन मुख्य क्षमताएँ इस्तेमाल करेंगे: चेन-ऑफ-थॉट रीजनिंग, स्ट्रक्चर्ड आउटपुट के लिए टूल कॉलिंग, और स्कैन की गई इनवॉइस पर विज़न। नतीजा एक छोटी इनवॉइस-प्रोसेसिंग पाइपलाइन है जो PDF और JPG पढ़ती है, अपनी सोच दिखाती है, और वैलिडेटेड JSON लौटाती है जिसे आप CSV में लिख सकते हैं।
आपको Python 3.10 या नया संस्करण और API कॉल करने की समझ चाहिए। न GPU, न मॉडल डाउनलोड, न सेल्फ-होस्टिंग। हम Qwen 3.6 Plus को OpenRouter के जरिए एक्सेस करेंगे, इसलिए साइनअप एक ही फॉर्म में हो जाएगा, और OpenAI SDK बिना बदलाव के काम करेगा।
मैं यह भी अत्यधिक सलाह दूंगा कि आप हमारे Fine-Tuning Qwen 3.6 ट्यूटोरियल को देखें, जो Qwen का नवीनतम ओपन-वेट्स संस्करण है। यदि आप प्रतियोगी मॉडलों में रुचि रखते हैं, तो हमारे DeepSeek v4, OpenAI के GPT-5.5, और Anthropic के Claude Opus 4.7 पर गाइड भी अवश्य पढ़ें।
Qwen 3.6 Plus Alibaba का अप्रैल 2026 का फ्लैगशिप मॉडल है। बैकबोन एक हाइब्रिड लीनियर-अटेंशन + स्पैर्स मिक्सचर-ऑफ-एक्सपर्ट्स है, रीजनिंग डिफॉल्ट रूप से चलती है, और टेक्स्ट, इमेज तथा वीडियो सभी एक ही API से गुजरते हैं।
फंक्शन कॉलिंग OpenAI टूल-कॉल प्रोटोकॉल का उपयोग करती है। Alibaba इस रिलीज़ को "रियल-वर्ल्ड एजेंट्स की ओर" के रूप में पेश करता है, यानी गड़बड़ इनपुट्स के लिए एक ही मॉडल जो एक ही स्टेप में रीजनिंग, इमेज रीडिंग, और एक फंक्शन कॉल कर सके।
Plus टियर क्लोज़्ड वेट्स है। आप चेकपॉइंट डाउनलोड करके इसे अपने हार्डवेयर पर नहीं चला सकते (मॉडल वैसे भी कंज्यूमर हार्डवेयर पर चलाने के लिए बहुत बड़ा है)। Alibaba एक ओपन-सोर्स Qwen/Qwen3.6-35B-A3B वेरिएंट प्रकाशित करता है, जिसका डिफॉल्ट कॉन्टेक्स्ट 262K है, पर वह अलग उत्पाद है। इस ट्यूटोरियल में हम होस्टेड API का उपयोग कर रहे हैं।
Qwen 3.6 Plus प्रति कॉल अधिकतम 1M इनपुट टोकन लेता है और 65,536 आउटपुट टोकन वापस कर सकता है। इनपुट मोडालिटीज़ में टेक्स्ट, इमेज, और वीडियो शामिल हैं। टूल कॉलिंग OpenAI स्कीमा के माध्यम से नैटिव है। OpenRouter के मॉडल पेज पर प्राइसिंग, प्रोवाइडर लेटेंसी, और रूटेड बैकएंड्स के थ्रूपुट सूचीबद्ध हैं।
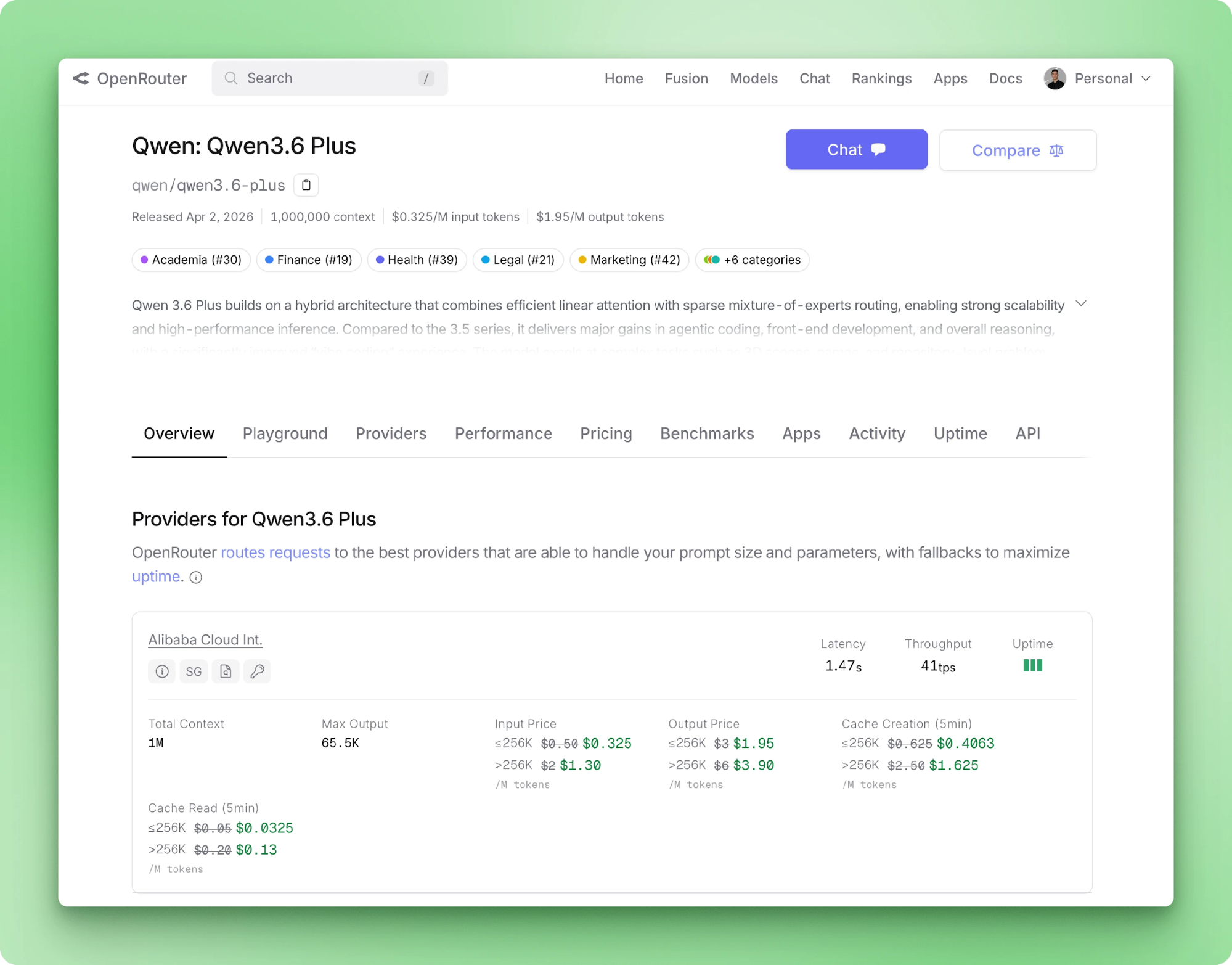
चेन-ऑफ-थॉट हर कॉल पर डिफॉल्ट रूप से चलता है, और रीजनिंग कंटेंट उत्तर से अलग फील्ड में स्ट्रीम होता है। एक नया 3.6 Plus पैरामीटर मल्टी-टर्न में मैसेजों पर पिछले रीजनिंग ट्रेसेज़ को अटैच रखता है।
Alibaba इसे ऐसे एजेंट लूप्स के लिए सुझाता है जहाँ बाद के टर्न पहले की चेन-ऑफ-थॉट से लाभ उठाते हैं। हमारी तरह वन-शॉट एक्सट्रैक्शन में ट्रेस को बचाए रखना टोकन बर्बाद करता है, इसलिए हम इसे अक्षम करते हैं।
इस ट्यूटोरियल के लिए तीन बेंचमार्क स्कोर महत्वपूर्ण हैं:
पहले दो कारण हैं कि स्कैन की गई इनवॉइस एक उपयुक्त लक्ष्य हैं। तीसरा कारण है कि हम उम्मीद कर सकते हैं कि मॉडल भारी-भरकम प्रॉम्प्ट इंजीनियरिंग के बिना टूल-कॉल प्रोटोकॉल का पालन करेगा।
3.5 Plus से 3.6 Plus पर संस्करण की छलांग अधिकांश मेट्रिक्स पर छोटी है। कोडिंग और रीजनिंग बेंचमार्क कुछ अंक बढ़ते हैं। बड़ा बदलाव यह है कि रीजनिंग टॉगल से डिफॉल्ट में बदल गई है। OCR और ऑब्जेक्ट लोकलाइज़ेशन में सबसे अधिक सुधार हुआ है।
|
क्षमता |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
रीजनिंग मोड |
डिफॉल्ट रूप से ऑन (इसे |
हमेशा-ऑन CoT |
|
कॉन्टेक्स्ट विंडो |
1M टोकन तक |
1M टोकन (डिफॉल्ट) |
|
मल्टीमॉडल |
नैटिव विज़न-लैंग्वेज |
नैटिव + बेहतर OCR, ऑब्जेक्ट लोकलाइज़ेशन |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
टर्न्स-अक्रॉस रीजनिंग |
— |
|
यदि आप प्रोडक्शन में 3.5 Plus चला रहे थे, तो अपग्रेड का मतलब है नए preserve_thinking पैरामीटर को अपनाना और नोट करना कि अब हर कॉल पर थिंकिंग का बिल लगता है। मुख्य लाभ एजेंट लूप्स और डॉक्यूमेंट विज़न में हैं, जो इस ट्यूटोरियल का फोकस है।
आप मॉडल तक दो तरीकों से पहुँच सकते हैं। आधिकारिक तरीका है Alibaba Cloud Model Studio, जो आपको सीधे https://dashscope-intl.aliyuncs.com/compatible-mode/v1 एंडपॉइंट देता है। दूसरा है OpenRouter, जो एकीकृत बिलिंग लेयर और सरल साइनअप के पीछे Alibaba तक रूट करता है।
ट्यूटोरियल OpenRouter का उपयोग करता है क्योंकि की क्रिएशन फ्लो तेज है और एंडपॉइंट के अड़चनें कम हैं। यदि आप सीधे रास्ता चाहते हैं, तो दो लाइनें बदलें और आगे बढ़ें।
Alibaba Cloud Model Studio इस ट्यूटोरियल के लिए OpenRouter जितना ही अच्छा काम करता है। केवल बेस URL और एनवायरनमेंट वेरिएबल का नाम बदलता है।
Google या GitHub खाते के साथ openrouter.ai पर साइन अप करें। फ्री टियर बिना क्रेडिट कार्ड के उपलब्ध है, जो इस ट्यूटोरियल को शुरू से अंत तक फॉलो करने के लिए पर्याप्त है। यदि आप बाद में बड़े वॉल्यूम चलाने की योजना बनाते हैं, तो क्रेडिट जोड़ने से आपको उच्च-थ्रूपुट टियर मिलता है और प्रति-मॉडल रेट कैप हट जाता है।
साइन इन होने के बाद, openrouter.ai/settings/keys पर जाएँ और एक कुंजी क्रेएट करें। इसे qwen-tutorial जैसा कोई लेबल दें ताकि आप बाद में इसे रद्द कर सकें।
कुंजी मान अभी कॉपी करें, क्योंकि OpenRouter इसे केवल एक बार दिखाता है। फिर इसे अपने प्रोजेक्ट की रूट में .env फ़ाइल में सेव करें:
OPENROUTER_API_KEY=sk-or-v1-...हम इसे अगला सेक्शन में python-dotenv से लोड करेंगे। यदि आप सीधे Alibaba Cloud का उपयोग करना चाहें, तो कुंजी modelstudio.console.alibabacloud.com से आती है और DASHSCOPE_API_KEY में जाती है।
पहली वेरिफिकेशन कॉल के लिए हमें जिन दो पैकेजों की आवश्यकता है, उन्हें इंस्टॉल करें:
pip install openai python-dotenvopenai पैकेज वही SDK है जिसका आप OpenAI के एंडपॉइंट के साथ उपयोग करेंगे। OpenRouter और Alibaba Cloud Model Studio, दोनों OpenAI Chat Completions API को इम्प्लीमेंट करते हैं, इसलिए क्लाइंट कोड बदलने की जरूरत नहीं।
एक hello.py फ़ाइल बनाइए और कनेक्शन वेरिफ़ाई करें:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)python hello.py चलाने पर एक छोटा उत्तर प्रिंट होना चाहिए। फ्री टियर पर फर्स्ट-टोकन लेटेंसी कुछ सेकंड ले सकती है क्योंकि मॉडल दृश्यमान उत्तर बनाने से पहले रीजनिंग ट्रेस बना रहा होता है।
सैंपल प्रोजेक्ट एक इनवॉइस-प्रोसेसिंग पाइपलाइन है। यह दो फॉर्मैट स्वीकार करता है: टेक्स्ट PDF और स्कैन की गई JPG। प्रत्येक इनवॉइस Qwen 3.6 Plus के जरिए रीजनिंग ऑन के साथ चलती है, और एक्सट्रैक्टेड फील्ड्स एक टूल कॉल के माध्यम से लौटते हैं। हर इनवॉइस चार चरणों से गुजरती है:
इनपुट डिकोड करें (इमेज को base64-एन्कोड करें, या पहले हर PDF पेज को इमेज में बदलें)
मॉडल से रीजनिंग ट्रेस स्ट्रीम करें
टूल कॉल को स्ट्रक्चर्ड JSON में पार्स करें
results.csv में एक पंक्ति लिखें
इस सेक्शन का सारा कोड bextuychiev/qwen-invoice-pipeline-tutorial में है। इसे क्लोन करें ताकि आप साथ-साथ फॉलो कर सकें, या अपना संस्करण बनाते वक्त इसे रेफ़रेंस के तौर पर इस्तेमाल करें।
एक invoice-pipeline/ डायरेक्टरी बनाएं और इसे इस तरह संरचित करें:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtclient.py और प्रोसेसर के बीच विभाजन OpenRouter कॉन्फ़िग को एक फ़ाइल में रखता है। यदि आप बाद में Alibaba Cloud पर स्वैप करते हैं, तो आप केवल client.py एडिट करेंगे, बाकी नहीं।
client.py OpenAI क्लाइंट को सही बेस URL और मॉडल ID के साथ रैप करता है:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example इसके साथ रहता है ताकि कोई भी रिपो क्लोन करने वाला जान सके कि क्या भरना है:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1कंपैनियन रिपो तीन स्रोतों से छह सैंपल इनवॉइस देता है:
वास्तविक कंपनी इनवॉइस PII के कारण सार्वजनिक रूप से पुनर्वितरित नहीं किए जा सकते, इसलिए हम इनका उपयोग करते हैं। यदि आप पाइपलाइन की जाँच करना चाहें, तो ग्राउंड-ट्रुथ टोटल्स रिपो के README में सूचीबद्ध हैं।
यदि आपने Qwen 3.5 का उपयोग किया है, तो CoT प्रति-कॉल टॉगल था: enable_thinking=True extra_body के अंदर। 3.6 Plus पर, रीजनिंग डिफॉल्ट रूप से चलती है, और यह पैरामीटर मुख्यतः इसे बंद करने के लिए है। जब थिंकिंग सक्रिय है, तो रीजनिंग टोकन का बिल हमेशा लगता है, जो "हमेशा-ऑन" को एक लागत निर्णय बनाता है, मुफ्त फीचर नहीं।
जब आप रिस्पॉन्स स्ट्रीम करते हैं, delta.reasoning_content पहले आता है, फिर delta.content (या हमारे केस में delta.tool_calls) आता है।
एक न्यूनतम कॉल जो एक इनवॉइस एक्सट्रैक्ट करता है और स्ट्रीमिंग के दौरान रीजनिंग ट्रेस प्रिंट करता है, इस तरह दिखता है:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)हम डिस्क से JPG बाइट्स पढ़ते हैं, उन्हें base64-एन्कोड करते हैं, और परिणाम को data: URI में रैप करते हैं। यह फॉर्मैट OpenAI कंटेंट-ब्लॉक प्रोटोकॉल को बिना होस्टेड URL के इनलाइन इमेज स्वीकार करने देता है। image_url ब्लॉक सीधे URI लेता है, और मॉडल इनवॉइस को ऐसे देखता है मानो आपने लिंक पास किया हो।
extra_body={"enable_thinking": True} Qwen को enable_thinking फ़्लैग फ़ॉरवर्ड करता है। OpenAI SDK इस पैरामीटर को नहीं जानता, इसलिए extra_body प्रोवाइडर-विशिष्ट विकल्प पास करने का तरीका है।
जब आप इसे invoice_04.jpg पर चलाते हैं, तो स्ट्रीम हुआ उत्तर एक छोटे से सारांश के रूप में आता है:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51छोटा होना वही है जो हमने माँगा था: सिस्टम प्रॉम्प्ट ने "summarize" कहा था और कुछ नहीं। जब टास्क बड़ा होता है (लाइन आइटम, श्रेणियाँ, स्ट्रक्चर्ड फील्ड्स), तो रीजनिंग ट्रेस भी साथ में बढ़ता है। हम यह अगली धारा में देखेंगे, जहाँ वही मॉडल उसी इमेज पर जवाब देने से पहले अपने आउटपुट बजट का अधिकांश हिस्सा सोचने में खर्च करता है।
/no_think को यूज़र प्रॉम्प्ट में जोड़ना उस कॉल के लिए CoT को अक्षम करने वाला एक सॉफ्ट स्विच है। डिबगिंग के समय उपयोगी, जब आपको बिना सोचे तेज़ प्रतिक्रिया चाहिए।
रीजनिंग एक्सट्रैक्शन को पढ़ने योग्य बनाती है, लेकिन आउटपुट अभी भी रीजनिंग ट्रेस के अंदर मुक्त-रूप टेक्स्ट है। हर बार स्ट्रक्चर्ड, पार्स करने योग्य JSON पाने के लिए, हम एक टूल extract_invoice परिभाषित करते हैं, और सिस्टम प्रॉम्प्ट के साथ tool_choice="auto" सेट करते हैं जो मॉडल को हमेशा टूल कॉल करने का निर्देश देता है।
स्कीमा tools.py में छह फ़ील्ड्स का वर्णन करता है। बाहरी संरचना मानक OpenAI फंक्शन-टूल फॉर्मैट का अनुसरण करती है:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}छह फ़ील्ड्स parameters.properties के अंदर बैठती हैं। स्केलर फील्ड्स (vendor, date, total, tax) साधारण JSON Schema टाइप्स का उपयोग करते हैं। category एक enum का उपयोग करता है ताकि मॉडल चार निश्चित मूल्यों में से चुने, लेबल न गढ़े। line_items एक स्ट्रक्चर्ड फील्ड है, ऑब्जेक्ट्स की एक ऐरे, प्रत्येक का अपना required लिस्ट है:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},स्कीमा में required के दो स्तर हैं। बाहरी सूची यह चिह्नित करती है कि हर एक्सट्रैक्शन में कौन-से टॉप-लेवल फील्ड्स होने चाहिए। प्रति-आइटम सूची बताती है कि हर लाइन आइटम पर कौन-से सब-फील्ड्स होने चाहिए। पूरा स्कीमा कंपैनियन रिपो के tools.py में है।
आर्गुमेंट्स tool_calls[0].function.arguments के अंदर JSON-फॉर्मैटेड स्ट्रिंग के रूप में वापस आते हैं, पार्स किया हुआ ऑब्जेक्ट नहीं, इसलिए आपको स्वयं json.loads कॉल करना होता है। स्ट्रीमिंग के समय, आर्गुमेंट्स डेल्टाज़ की सीक्वेंस के रूप में आते हैं जिन्हें पार्स करने से पहले जोड़ना होता है।
एक पेंच: OpenRouter का Qwen 3.6 Plus एंडपॉइंट फोर्स्ड टूल कॉल्स को सपोर्ट नहीं करता। यदि आप tool_choice={"type": "function", "function": {"name": "extract_invoice"}} ट्राई करते हैं, तो रिक्वेस्ट एक एरर लौटाती है:
No endpoints found that support the provided 'tool_choice' valueव्यावहारिक समाधान है tool_choice="auto" का उपयोग करना और सिस्टम प्रॉम्प्ट पर भरोसा करना:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""कंपैनियन रिपो की सभी छह सैंपल इनवॉइस पर, यह प्रॉम्प्ट हर बार टूल कॉल करवाता है। प्रोडक्शन कोड को फिर भी अपवाद केस के खिलाफ सावधानी रखनी चाहिए: finish_reason जाँचें, tool_calls भरा हुआ है, यह वेरिफ़ाई करें, और यदि न हो, तो तेज़ निर्देश के साथ रिट्राई करें। Qwen के फंक्शन-कॉलिंग डॉक्युमेंट्स भी यही बात कहते हैं। टूल-कॉल जेनरेशन गारंटीड नहीं है, और प्रोडक्शन कोड को फॉलबैक चाहिए।
एक साइड इफेक्ट: एक बार जब प्रॉम्प्ट स्ट्रक्चर्ड फील्ड्स माँगता है, तो delta.reasoning_content एक लंबे ट्रेस से भर जाता है। मॉडल टेबल को पंक्ति-दर-पंक्ति पार्स करता है, invoice_04.jpg पर यूरोपीय दशमलव नोटेशन पर विचार करता है, और लाइन-आइटम अमाउंट्स को टोटल से क्रॉस-चेक करता है। इस तरह के प्रॉम्प्ट पर रीजनिंग टोकन उत्तर टोकन से 10x या अधिक हो सकते हैं।
यह स्ट्रक्चर्ड एक्सट्रैक्शन पर हमेशा-ऑन CoT की लागत है, यही कारण है कि preserve_thinking केवल उन्हीं मल्टी-टर्न एजेंट लूप्स पर फायदा देता है जहाँ बाद का टर्न ट्रेस पढ़ता है। हम वन-शॉट एक्सट्रैक्शन कर रहे हैं, इसलिए ट्रेस टर्मिनल पर स्ट्रीम होता है, और हम उसे त्याग देते हैं।
JPG के लिए फ़्लो तीन स्टेप्स का है:
डिस्क से इमेज बाइट्स पढ़ें
उन्हें Base64-एन्कोड करें
नतीजे को data: URI के साथ एक image_url कंटेंट ब्लॉक में डालें
PDFs को एक अतिरिक्त स्टेप चाहिए क्योंकि Qwen का विज़न पाथ सीधे PDF फाइल्स के बजाय इमेज स्वीकार करता है। हर पेज को pdf2image से PIL इमेज में बदलें, फिर पेजों को उसी मैसेज में इमेज कंटेंट ब्लॉक्स की लिस्ट के रूप में भेजें।
दोनों पाथ्स एक ही मॉडल कॉल साझा करते हैं, इसलिए कॉल processors/image.py में रहती है और processors/pdf.py उससे डेलीगेट करता है। इम्पोर्ट्स से शुरू करें (ऊपर दिया गया SYSTEM_PROMPT इसी मॉड्यूल में रहता है):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveएन्कोडर JPG पाथ को API द्वारा अपेक्षित data: URI में बदलता है:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"साझा हेल्पर _call_with_images यूज़र-कंटेंट ऐरे (टेक्स्ट + एक या अधिक इमेज) बनाता है और स्ट्रीमिंग रिक्वेस्ट भेजता है। स्ट्रीम से, यह दो डेटा पीस इकट्ठा करता है: रीजनिंग ट्रेस और टूल-कॉल आर्गुमेंट्स। रिक्वेस्ट सेटअप पहले आता है:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)फिर स्ट्रीम लूप रीजनिंग डेल्टाज़ को टूल-कॉल आर्गुमेंट डेल्टाज़ से अलग करता है:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}JPGs के लिए पब्लिक एंट्री पॉइंट एक वन-लाइनर है जो इन्हीं हेल्पर्स का उपयोग करता है:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)PDF प्रोसेसर _call_with_images का पुन: उपयोग करता है और केवल पेज-टू-इमेज कन्वर्ज़न जोड़ता है:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image के लिए poppler इंस्टॉल होना आवश्यक है। इसे ऐसे इंस्टॉल करें:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsमल्टी-पेज PDF के लिए, हर पेज को उसी मैसेज में अलग इमेज ब्लॉक के रूप में भेजें। Qwen उन्हें साथ पढ़ता है और एक ही एक्सट्रैक्शन देता है, जो इनवॉइस के लिए उपयुक्त है जहाँ टोटल पेज 2 पर होते हैं।
150 DPI इनवॉइस टेक्स्ट को पढ़ने योग्य रखता है बिना पेलोड को फुलाए। इससे ऊपर जाना रिक्वेस्ट को बड़ा करता है पर इन सैंपल्स पर एक्यूरेसी नहीं बढ़ाता। Alibaba के विज़न दस्तावेज़ समर्थित फॉर्मैट्स और ऊपरी सीमाएँ कवर करते हैं।
main.py sample_invoices/ को वॉक करता है, हर फ़ाइल को एक्सटेंशन से रूट करता है, सही प्रोसेसर कॉल करता है, और संयोजित परिणामों को CSV में लिखता है। इम्पोर्ट्स और कॉन्स्टैंट्स पहले:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}मुख्य लूप सैंपल्स डायरेक्टरी को सोर्टेड क्रम में इटरेट करता है, फ़ाइल एक्सटेंशन से रूट करता है, और हर एक्सट्रैक्शन को CSV-फ्रेंडली रो में फ्लैट करता है:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})अंत में, पंक्तियाँ डिस्क पर लिखें और काउंट लॉग करें:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()python main.py चलाने पर छह सैंपल क्रम से वॉक होते हैं। हर इनवॉइस पहले फ़ाइलनाम, फिर रीजनिंग ट्रेस, फिर एक्सट्रैक्टेड JSON स्ट्रीम करती है, उसके बाद अगली पर बढ़ती है:
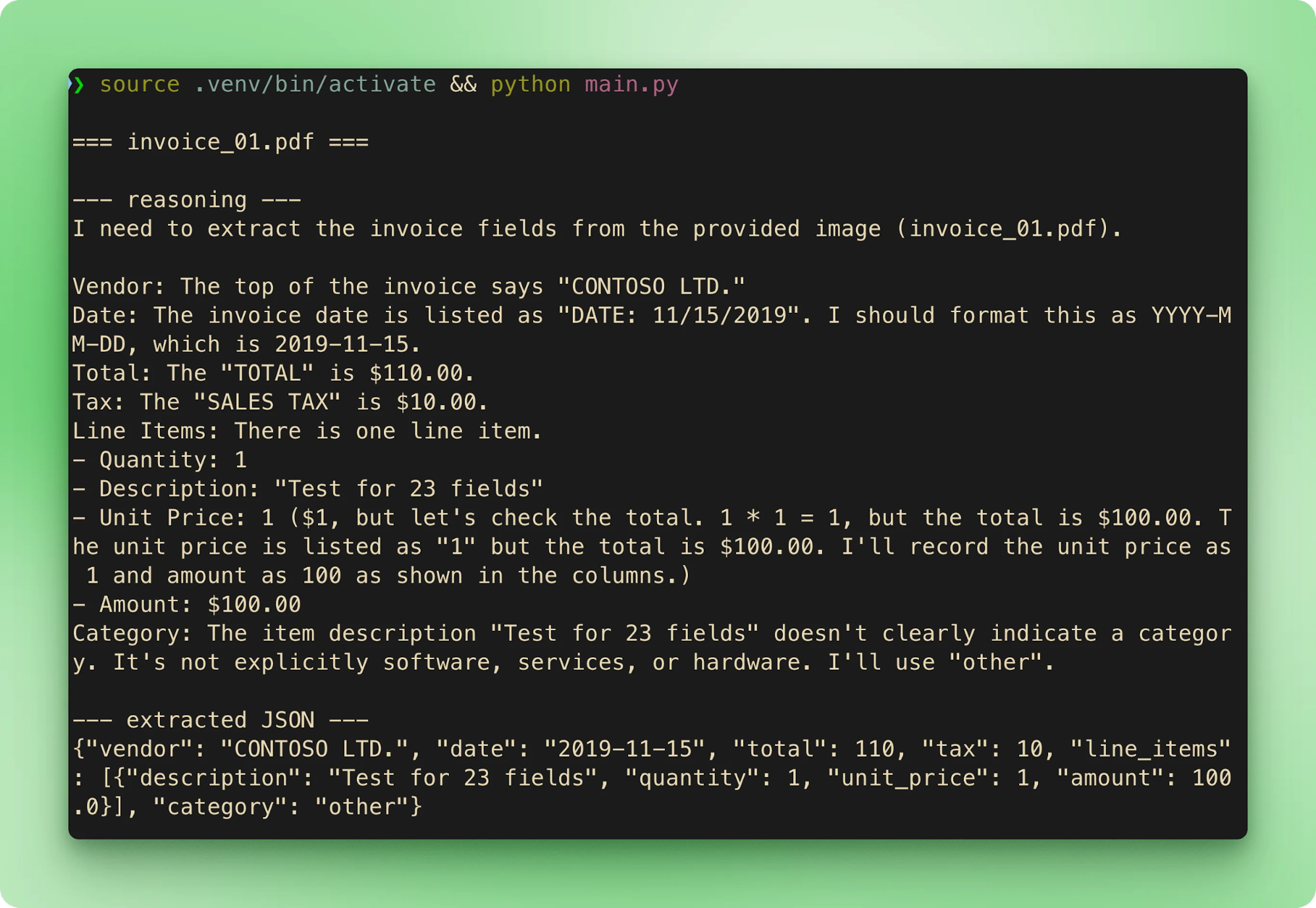
results.csv हर एक्सट्रैक्शन को प्रति इनवॉइस एक पंक्ति में एकत्रित करता है:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
टोटल्स सभी छह पर ग्रोउंड ट्रुथ से मेल खाते हैं। फ्री टियर पर लेटेंसी प्रति इनवॉइस 15 से 40 सेकंड चलती है। अधिकांश समय टूल कॉल स्ट्रीमिंग शुरू होने से पहले की रीजनिंग फेज़ में जाता है।
कुछ पैटर्न तय करते हैं कि पाइपलाइन एक बार काम करती है या वास्तविक इनवॉइस पर लगातार काम करती रहती है।
सीक्रेट्स को कोड से बाहर रखें। .env और python-dotenv पैटर्न जिसे हमने पूरे समय उपयोग किया है, बेसलाइन है। पहली कमिट से पहले .env को अपने .gitignore में जोड़ें ताकि कुंजी कभी रिपो तक न पहुँचे।
रेट लिमिट्स को एक्सपोनेंशियल बैकऑफ से संभालें। OpenRouter प्रति-प्रोवाइडर लिमिट्स HTTP 429 रिस्पॉन्सेस के साथ लागू करता है। tenacity लाइब्रेरी आपको डेकोरेटर-आधारित इम्प्लीमेंटेशन देती है, और OpenAI कुकबुक पैटर्न का wait_random_exponential बिना बदलाव काम करता है।
जब रिस्पॉन्स लंबे होंगे तो स्ट्रीमिंग करें। हमेशा-ऑन CoT डिफॉल्ट रूप से रिस्पॉन्स लंबा कर देता है। नॉन-स्ट्रीमिंग कॉल्स का मतलब है कि पूरी रीजनिंग ब्लॉक का इंतज़ार करना। स्ट्रीमिंग जल्दी फीडबैक देती है, UI को रिस्पॉन्सिव रखती है, और आपको ऐसी रिक्वेस्ट अबॉर्ट करने देती है जो स्पष्ट रूप से गलत जा रही हो।
preserve_thinking का उपयोग केवल तब करें जब बाद के टर्न पहले की रीजनिंग पढ़ेंगे। इस पाइपलाइन जैसे वन-शॉट एक्सट्रैक्टर्स के लिए यह टोकन की बर्बादी है। मल्टी-टर्न एजेंट लूप्स (टूल-कॉलिंग चेन, प्लानिंग टास्क, डिबगिंग वर्कफ़्लोज़) के लिए यह पैरामीटर क्रॉस-टर्न कॉन्टेक्स्ट के लिए बना है। Alibaba का डीप थिंकिंग दस्तावेज़ thinking_budget को भी कवर करता है, जो प्रति कॉल रीजनिंग टोकन की हार्ड कैप है।
फ्री-टियर रिस्पॉन्सेस ट्रेनिंग के लिए लॉग किए जा सकते हैं। OpenRouter का फ्री टियर ऐसे प्रोवाइडर्स से रूट करता है जो प्रॉम्प्ट्स रख सकते हैं। इससे यह वास्तविक PII, कस्टमर नामों, या भुगतान विवरण वाली इनवॉइस के लिए अनुपयुक्त हो जाता है। असली डेटा पाइपलाइन से गुजरने से पहले पेड OpenRouter टियर (या पेड अकाउंट के साथ सीधे Alibaba Cloud) पर जाएँ।
Plus टियर पर सेल्फ-होस्टिंग नहीं। जिन डिप्लॉयमेंट्स को एयर-गैपिंग या ऑन-प्रेम चाहिए, वे होस्टेड API का उपयोग नहीं कर सकते। ओपन-सोर्स Qwen3.6-35B-A3B वेरिएंट उन मामलों के लिए अलग विकल्प है, जिसे विचार करना चाहिए।
रीजनिंग शुरू होने पर टाइम-टू-फर्स्ट-टोकन धीमा हो सकता है। टाइमआउट्स उदार रखें, इमेज इनपुट के लिए 30 से 60 सेकंड उचित है। सुनिश्चित करें कि आपका रिट्राई लॉजिक रीड टाइमआउट्स को 429 से अलग तरीके से संभालता है।
हमेशा-ऑन CoT के बावजूद आउटपुट निर्धारक नहीं है। कंपैनियन रिपो के सैंपल्स पर टेस्टिंग में, invoice_01.pdf अधिकांश रन पर $610.00 एक्सट्रैक्ट हुआ। कम से कम एक री-रन पर समान इनपुट्स के साथ यह $110.00 पर पलट गया। रीजनिंग ट्रेस दोनों बार सही उत्तर तक पहुँचा, लेकिन अंतिम टूल-कॉल आर्गुमेंट अलग था। दो उपाय: temperature कम रखें (शुद्ध एक्सट्रैक्शन के लिए 0.1 से 0.2), और जब एक्यूरेसी मायने रखती हो तो ग्राउंड ट्रुथ के विरुद्ध वैलिडेट करें या सेकंड पास चलाएँ।
यहाँ से, पाइपलाइन को किसी एजेंट फ्रेमवर्क में रैप करना एक छोटा कदम है। टूल-कॉल लूप, स्ट्रीमिंग पार्सर, और CSV राइटर वही प्रिमिटिव्स हैं जिन्हें कोई एजेंट फ्रेमवर्क मल्टीपल टर्न्स में ऑर्केस्ट्रेट करता है। DataCamp का Developing LLM Applications with LangChain कोर्स इन पैटर्न्स को मेमोरी, स्टेट, और मल्टी-टूल रूटिंग के साथ समझाता है।
एजेंटिक AI कोर्सेज
Track
Track
course