
Programa
Fundamentos de agentes de IA
6 h
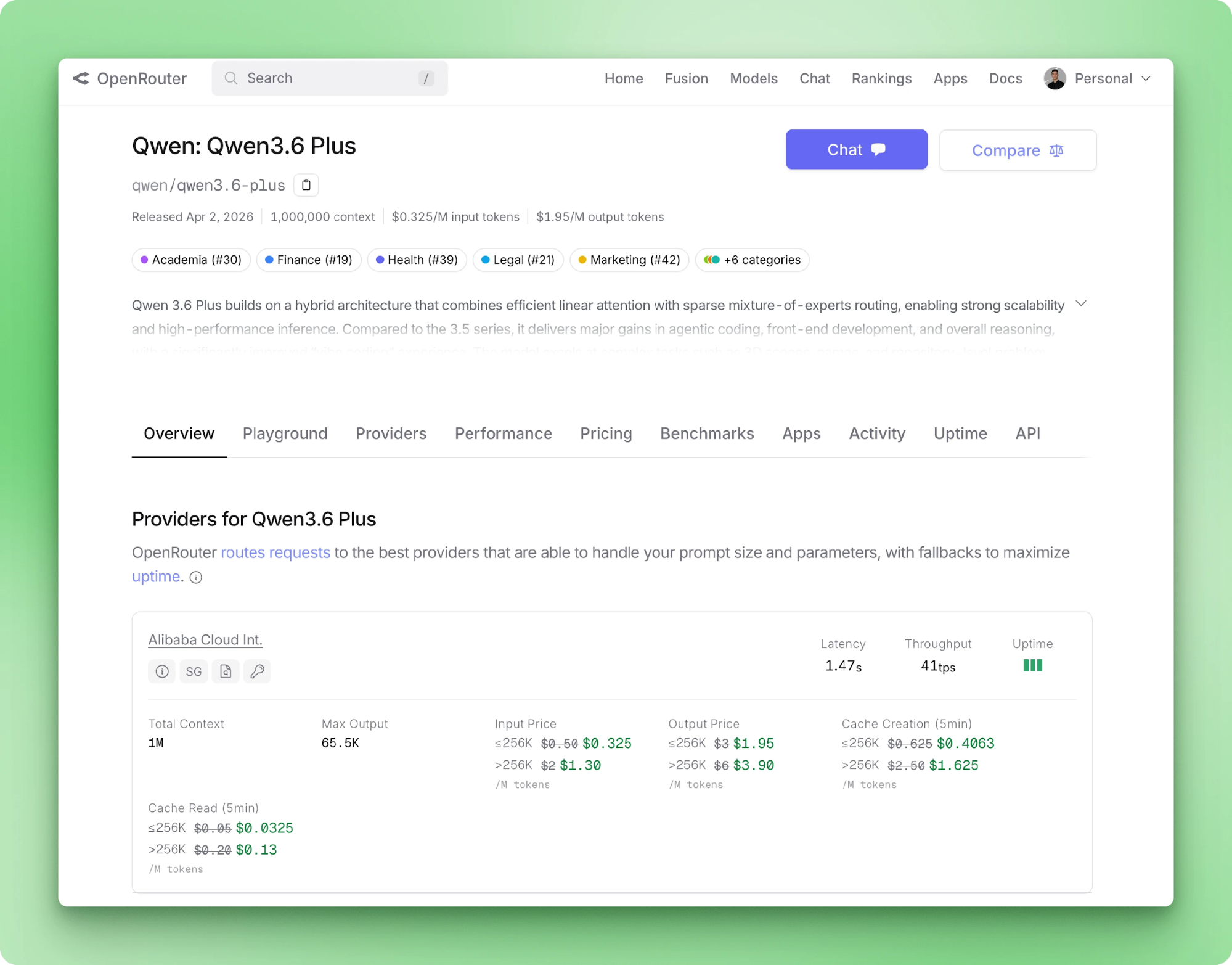
A Alibaba lançou o Qwen 3.6 Plus em abril de 2026. Especificações: SWE-bench Verified de 78,8, janela de contexto padrão de 1M tokens, entrada multimodal nativa e raciocínio sempre ativo. Para quem desenvolve em Python, o mais interessante não é a tabela de benchmarks: é o fato de o modelo ser só via API e funcionar com o pacote OpenAI padrão, bastando trocar a base URL.
Neste tutorial, vamos usar três recursos principais em um único projeto: chain-of-thought (raciocínio passo a passo), tool calling para saída estruturada e visão em faturas digitalizadas. O resultado é um pequeno pipeline de processamento de faturas que lê PDFs e JPGs, exibe seu raciocínio e retorna JSON validado que você pode gravar em um CSV.
Você vai precisar de Python 3.10 ou superior e familiaridade com chamadas de API. Sem GPU, sem baixar modelo, sem self-hosting. Vamos acessar o Qwen 3.6 Plus por meio do OpenRouter, então o cadastro é rápido e o SDK da OpenAI funciona sem mudanças.
Recomendo fortemente conferir também nosso tutorial sobre Fine-Tuning Qwen 3.6, a versão mais recente de pesos abertos do Qwen. Se você tem interesse em modelos concorrentes, leia nossos guias sobre o DeepSeek v4, o GPT-5.5 da OpenAI e o Claude Opus 4.7 da Anthropic.
O Qwen 3.6 Plus é o modelo carro-chefe da Alibaba de abril de 2026. A base é um híbrido de atenção linear com mixture-of-experts esparso, o raciocínio roda por padrão, e texto, imagens e vídeo passam pela mesma API.
A chamada de funções usa o protocolo de tool calling da OpenAI. A Alibaba posiciona o lançamento como "rumo a agentes do mundo real", ou seja, um único modelo para entradas desorganizadas que exigem raciocínio, leitura de imagem e uma chamada de função em um único passo.
A camada Plus tem pesos fechados. Você não pode baixar o checkpoint nem rodá-lo no seu próprio hardware (o modelo é grande demais para rodar em máquinas de consumo). A Alibaba publica uma variante open source Qwen/Qwen3.6-35B-A3B com contexto padrão de 262K, mas é outro produto. Para este tutorial, usamos a API hospedada.
O Qwen 3.6 Plus recebe até 1M tokens de entrada e retorna até 65.536 tokens por chamada. Modalidades de entrada incluem texto, imagem e vídeo. Tool calling é nativo pelo esquema da OpenAI. A página do modelo no OpenRouter lista preços, latência por provedor e throughput dos backends roteados.
Chain-of-thought roda por padrão em toda chamada, e o conteúdo do raciocínio chega em um campo separado da resposta. Um novo parâmetro do 3.6 Plus mantém rastros de raciocínio anteriores anexados às mensagens entre turnos.
A Alibaba recomenda para loops de agentes em que turnos posteriores se beneficiam das cadeias de pensamento anteriores. Para extração one-shot como a nossa, preservar o rastro desperdiça tokens, então desativamos.
Três benchmarks importam para este tutorial:
Os dois primeiros explicam por que faturas digitalizadas são um alvo razoável. O terceiro explica por que dá para esperar que o modelo siga um protocolo de tool call sem engenharia de prompt pesada.
O salto da versão 3.5 Plus para a 3.6 Plus é pequeno na maioria das métricas. Benchmarks de código e raciocínio ganham alguns pontos. A maior mudança é o raciocínio sair de um toggle para virar padrão. OCR e localização de objetos foram os que mais melhoraram.
|
Capacidade |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Modo de raciocínio |
Ativo por padrão (possível desativar com |
CoT sempre ativo |
|
Janela de contexto |
Até 1M tokens |
1M tokens (padrão) |
|
Multimodal |
Visão-linguagem nativa |
Nativo + OCR e localização de objetos aprimorados |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Raciocínio entre turnos |
— |
|
Se você já estava rodando o 3.5 Plus em produção, a atualização implica adotar o novo parâmetro preserve_thinking e notar que o thinking agora é cobrado em toda chamada. Os principais ganhos estão em loops de agentes e visão de documentos, foco deste tutorial.
Você pode acessar o modelo de duas formas. A oficial é pelo Alibaba Cloud Model Studio, que oferece um endpoint direto em https://dashscope-intl.aliyuncs.com/compatible-mode/v1. A outra é o OpenRouter, que roteia para a Alibaba por trás de uma camada unificada de billing e um cadastro mais simples.
Este tutorial usa o OpenRouter porque gerar a chave é mais rápido e há menos particularidades de endpoint. Se preferir o caminho direto, troque duas linhas e siga em frente.
O Alibaba Cloud Model Studio funciona tão bem quanto o OpenRouter para este tutorial. O que muda é só a base URL e o nome da variável de ambiente.
Cadastre-se em openrouter.ai com sua conta Google ou GitHub. O plano gratuito dispensa cartão e é suficiente para seguir este tutorial de ponta a ponta. Se planeja rodar volume maior depois, adicionar créditos libera uma camada com maior throughput e remove o rate cap por modelo.
Depois de logado, acesse openrouter.ai/settings/keys e crie uma chave. Dê um rótulo como qwen-tutorial para poder revogar depois.
Copie o valor da chave agora, pois o OpenRouter só exibe uma vez. Depois, salve em um arquivo .env na raiz do seu projeto:
OPENROUTER_API_KEY=sk-or-v1-...Vamos carregar com python-dotenv na próxima seção. Se preferir usar a Alibaba Cloud diretamente, a chave vem de modelstudio.console.alibabacloud.com e vai para DASHSCOPE_API_KEY.
Instale os dois pacotes necessários para a primeira chamada de verificação:
pip install openai python-dotenvO pacote openai é o mesmo SDK usado com o endpoint da OpenAI. Tanto o OpenRouter quanto o Alibaba Cloud Model Studio implementam a Chat Completions API da OpenAI, então o código do cliente não precisa mudar.
Crie um arquivo hello.py e verifique a conexão:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Rodar python hello.py deve imprimir uma resposta curta. A latência até o primeiro token no plano gratuito pode levar alguns segundos porque o modelo constrói um rastro de raciocínio antes de gerar a resposta visível.
O projeto de exemplo é um pipeline de processamento de faturas. Ele aceita dois formatos: PDFs de texto e JPGs digitalizados. Cada fatura passa pelo Qwen 3.6 Plus com raciocínio ativado, e os campos extraídos retornam via chamada de ferramenta. Toda fatura passa por quatro etapas:
Decodificar a entrada (codificar a imagem em base64 ou converter cada página do PDF em imagem antes)
Transmitir o rastro de raciocínio de volta do modelo
Analisar a chamada de ferramenta em JSON estruturado
Escrever uma linha em results.csv
Todo o código desta seção está em bextuychiev/qwen-invoice-pipeline-tutorial. Faça o clone para acompanhar, ou use como referência enquanto constrói sua própria versão.
Crie um diretório invoice-pipeline/ e estruture assim:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtA separação entre client.py e os processors mantém a configuração do OpenRouter em um único arquivo. Se depois você trocar para a Alibaba Cloud, edita só o client.py e nada mais.
client.py empacota o cliente da OpenAI com a base URL correta e o ID do modelo:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example vai junto para quem clonar o repositório saber o que preencher:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1O repositório traz seis faturas de exemplo de três fontes:
Faturas reais de empresas não podem ser redistribuídas publicamente por causa de PII, então usamos estas. Os totais de referência estão no README do repositório, caso você queira conferir o pipeline contra eles.
Se você usou o Qwen 3.5, o CoT era um toggle por chamada: enable_thinking=True dentro de extra_body. No 3.6 Plus, o raciocínio roda por padrão e o parâmetro existe basicamente para desligá-lo. Tokens de raciocínio são sempre cobrados quando o thinking está ativo, então "sempre ligado" vira uma decisão de custo e não um recurso gratuito.
Ao transmitir uma resposta, delta.reasoning_content chega primeiro e depois delta.content (ou delta.tool_calls, no nosso caso).
Uma chamada mínima que extrai uma fatura e imprime o rastro de raciocínio conforme transmite é assim:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Lemos os bytes do JPG do disco, codificamos em base64 e embrulhamos o resultado em um URI data:. Esse formato permite que o protocolo de blocos de conteúdo da OpenAI aceite imagens inline sem URL hospedada. O bloco image_url recebe o URI diretamente, e o modelo vê a fatura como se você tivesse passado um link.
extra_body={"enable_thinking": True} encaminha o sinalizador enable_thinking para o Qwen. O SDK da OpenAI não conhece esse parâmetro, então extra_body é o caminho para passar opções específicas do provedor.
Ao rodar com invoice_04.jpg, a resposta transmitida volta como um resumo curto:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Curto é o que pedimos: o prompt do sistema disse "summarize" e nada mais. Quando a tarefa cresce (itens, categorias, campos estruturados), o rastro de raciocínio cresce junto. Vamos ver isso na próxima seção: o mesmo modelo, na mesma imagem, gasta a maior parte do orçamento "pensando" antes de responder.
Acrescentar /no_think ao prompt do usuário é um switch suave que desativa o CoT naquela chamada. Útil ao depurar quando você quer uma resposta mais rápida sem raciocínio.
O raciocínio deixa a extração legível, mas a saída ainda é texto livre dentro do rastro. Para receber JSON estruturado e parseável sempre, definimos uma ferramenta, extract_invoice, e setamos tool_choice="auto" com um prompt de sistema que instrui o modelo a sempre chamar a ferramenta.
O schema em tools.py descreve seis campos. O formato externo segue o padrão de function tool da OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Os seis campos ficam dentro de parameters.properties. Campos escalares (vendor, date, total, tax) usam tipos JSON Schema simples. category usa um enum para o modelo escolher entre quatro valores fixos em vez de inventar rótulos. line_items é o campo estruturado: um array de objetos, cada um com sua própria lista required:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},O schema tem dois níveis de required. A lista externa marca quais campos de topo precisam aparecer em toda extração. A lista por item marca quais subcampos devem aparecer em cada linha. O schema completo está em tools.py no repositório.
Os argumentos voltam como string formatada em JSON dentro de tool_calls[0].function.arguments, não como objeto parseado, então você chama json.loads por conta própria. Em streaming, os argumentos chegam em deltas que você concatena antes de fazer o parse.
Um detalhe: o endpoint do Qwen 3.6 Plus no OpenRouter não suporta chamadas de ferramenta forçadas. Se você tentar tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, a requisição retorna erro:
No endpoints found that support the provided 'tool_choice' valueNa prática, use tool_choice="auto" e confie no prompt de sistema:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Nas seis faturas de exemplo do repositório, esse prompt gera tool call em 100% dos casos. Em produção, ainda trate a exceção: cheque finish_reason, verifique se tool_calls está preenchido e tente novamente com instruções mais diretas se não estiver. A própria doc de function calling do Qwen (aqui) diz o mesmo. Geração de tool call não é garantida e código de produção precisa de fallback.
Um efeito colateral: quando o prompt pede campos estruturados, delta.reasoning_content enche com um rastro longo. O modelo analisa a tabela linha a linha, debate a notação decimal europeia em invoice_04.jpg e confere os valores dos itens com o total. Tokens de raciocínio podem superar os tokens de resposta em 10x ou mais nesse tipo de prompt.
Esse é o custo do CoT sempre ativo em extração estruturada, por isso preserve_thinking só vale em loops multi-turno em que um turno posterior lê o rastro. Estamos fazendo extração one-shot, então transmitimos o rastro no terminal e descartamos.
Para JPGs, o fluxo tem três etapas:
Ler os bytes da imagem do disco
Codificar em base64
Colocar o resultado em um bloco de conteúdo image_url com um URI data:
PDFs exigem uma etapa extra porque a trilha de visão do Qwen aceita imagens e não PDFs diretamente. Converta cada página para uma imagem PIL com pdf2image e envie as páginas como uma lista de blocos de imagem na mesma mensagem.
Ambos os caminhos compartilham a mesma chamada de modelo, então ela vive em processors/image.py e processors/pdf.py delega para ela. Comece pelos imports (o SYSTEM_PROMPT acima vive no mesmo módulo):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveO encoder transforma o caminho do JPG no URI data: que a API espera:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"O helper compartilhado _call_with_images monta o array de conteúdo do usuário (texto + uma ou mais imagens) e envia a requisição em streaming. Do stream, ele coleta duas coisas: o rastro de raciocínio e os argumentos da chamada de ferramenta. Primeiro, a configuração da requisição:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Depois, o loop do stream separa os deltas de raciocínio dos deltas de argumentos da tool call:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}O ponto de entrada público para JPGs é uma one-liner que usa esses helpers:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)O processador de PDF reutiliza _call_with_images e só adiciona a conversão de página para imagem:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image requer poppler instalado. Instale com:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsPara PDFs com várias páginas, envie cada página como seu próprio bloco de imagem na mesma mensagem. O Qwen lê tudo junto e produz uma única extração, que é o que você quer quando os totais estão na página 2.
150 DPI mantém o texto legível sem inflar o payload. Aumentar acima disso torna a requisição maior sem melhorar a acurácia nos testes com estas amostras. A documentação de visão da Alibaba cobre formatos suportados e limites superiores.
main.py percorre sample_invoices/, roteia cada arquivo por extensão, chama o processador certo e grava os resultados combinados em um CSV. Imports e constantes primeiro:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}O loop principal itera o diretório de amostras em ordem, roteia por extensão e achata cada extração em uma linha amigável para CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Por fim, escreva as linhas em disco e registre a contagem:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Rodar python main.py percorre as seis amostras em ordem. Cada fatura transmite o nome do arquivo, depois o rastro de raciocínio, depois o JSON extraído, e segue para a próxima:
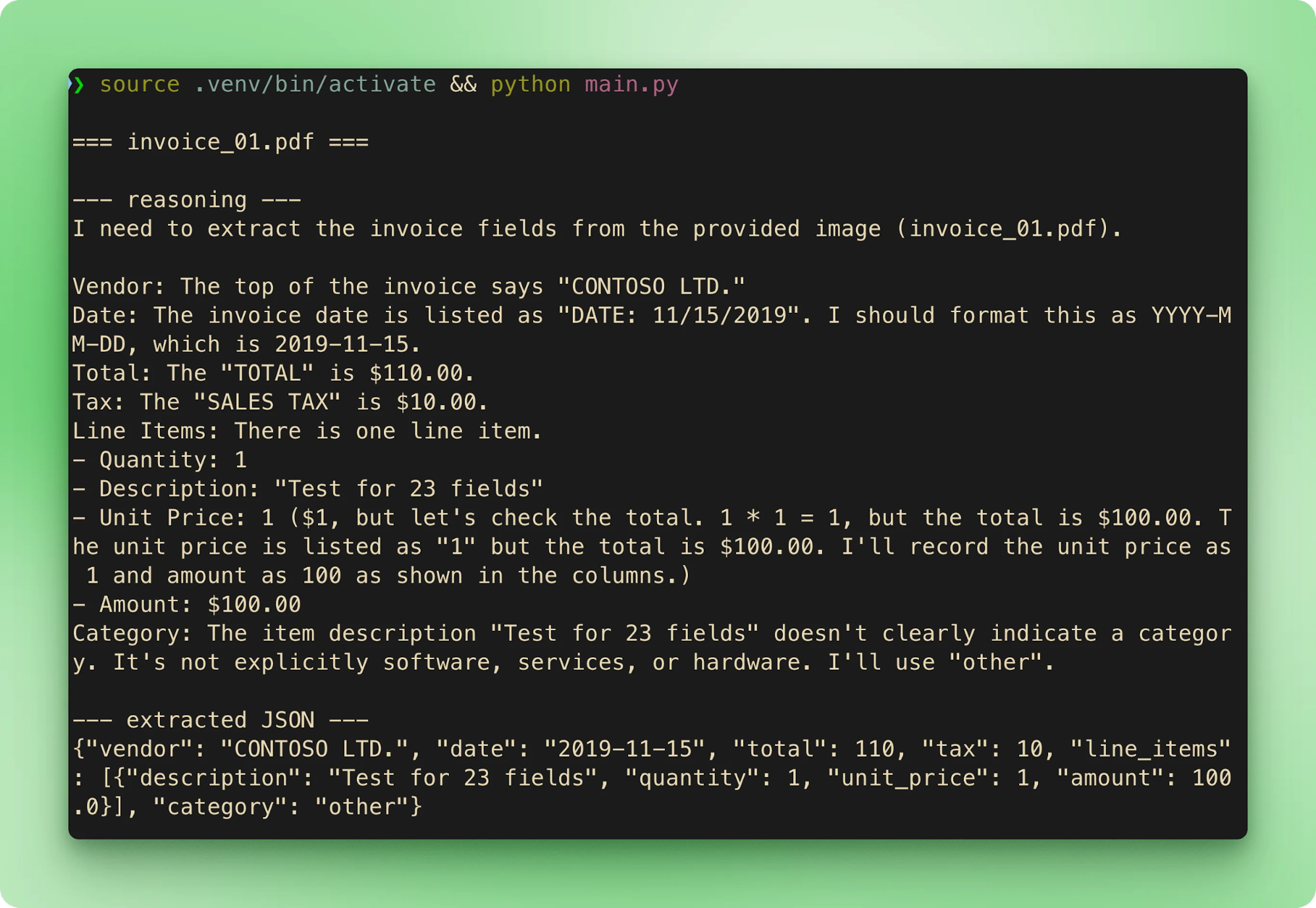
results.csv agrega cada extração em uma linha por fatura:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Os totais batem com o ground truth nas seis amostras. A latência no plano gratuito fica entre 15 e 40 segundos por fatura. A maior parte do tempo é o raciocínio antes do início da transmissão da tool call.
Alguns padrões separam um pipeline que funciona uma vez daquele que segue funcionando com faturas reais.
Mantenha segredos fora do código. O padrão .env e python-dotenv que usamos é o básico. Adicione .env ao .gitignore antes do primeiro commit para a chave nunca ir para o repositório.
Trate rate limits com backoff exponencial. O OpenRouter aplica limites por provedor com HTTP 429. A biblioteca tenacity oferece um decorador pronto, e o padrão do cookbook da OpenAI para wait_random_exponential funciona sem mudanças.
Use streaming quando a resposta for longa. CoT sempre ativo alonga as respostas por padrão. Chamadas sem streaming significam esperar todo o bloco de raciocínio antes de ver algo. Streaming dá feedback cedo, mantém a UI responsiva e permite abortar uma requisição que está claramente saindo do trilho.
Use preserve_thinking só quando turnos posteriores lerem o raciocínio anterior. Para extratores one-shot como este pipeline, são tokens desperdiçados. Para loops multi-turno (cadeias de tools, planejamento, debugging), o parâmetro existe para esse contexto entre turnos. A documentação de deep thinking da Alibaba também cobre thinking_budget, um teto duro de tokens de raciocínio por chamada.
Respostas do plano gratuito podem ser registradas para treinamento. O free tier do OpenRouter pode rotear por provedores que retêm prompts. Isso o torna inadequado para faturas com PII, nomes de clientes ou dados de pagamento. Migre para um tier pago do OpenRouter (ou direto para a Alibaba Cloud com conta paga) antes de rodar dados reais.
Sem self-hosting no tier Plus. Implantações que exigem air gap ou on-prem não podem usar a API hospedada. A variante open source Qwen3.6-35B-A3B é outra opção a considerar nesses casos.
Tempo até o primeiro token pode ser alto quando o raciocínio inicia. Defina timeouts generosos; 30 a 60 segundos é razoável para entrada por imagem. Garanta que o retry trata timeouts de leitura separadamente de 429.
Saída não é determinística mesmo com CoT sempre ativo. Nos testes com as amostras do repositório, invoice_01.pdf extraiu $610,00 na maioria das execuções, mas em pelo menos uma repetição idêntica deu $110,00. O rastro de raciocínio chegou à resposta correta nos dois casos, mas o argumento final da tool call diferiu. Duas mitigacões: defina temperature baixa (0,1 a 0,2 para extração pura) e valide contra ground truth ou use uma segunda passada quando a acurácia justificar a chamada extra.
Daqui, encapsular o pipeline em um framework de agentes é um passo pequeno. O loop de tool call, o parser em streaming e o escritor de CSV são os mesmos blocos que um framework de agentes orquestra ao longo de vários turnos. O curso da DataCamp Developing LLM Applications with LangChain percorre esses padrões com memória, estado e roteamento multi-ferramenta.
Cursos de IA agentic
Programa
Programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Joleen Bothma
Tutorial
Moez Ali

