
programa
Fundamentos de agentes de IA
6 h
Alibaba lanzó Qwen 3.6 Plus en abril de 2026. Ficha técnica: SWE-bench Verified de 78,8, ventana de contexto de 1M de tokens por defecto, entrada multimodal nativa y razonamiento siempre activo. Para quien programa en Python, lo interesante no es la tabla de benchmarks: es que el modelo es solo vía API y funciona con el paquete estándar de OpenAI cambiando la URL base.
En este tutorial usaremos tres de sus funciones principales en un único proyecto: chain-of-thought (razonamiento paso a paso), llamadas a herramientas para obtener salida estructurada y visión para facturas escaneadas. El resultado es una pequeña canalización que lee PDFs y JPGs, muestra su razonamiento y devuelve JSON validado que puedes volcar a un CSV.
Necesitas Python 3.10 o superior y saber hacer llamadas a APIs. Sin GPU, sin descargas de modelos, sin autoalojamiento. Accederemos a Qwen 3.6 Plus a través de OpenRouter, así el registro se hace en un paso y el SDK de OpenAI funciona tal cual.
Te recomiendo echar un vistazo también a nuestro tutorial sobre Fine-Tuning Qwen 3.6, la última versión de Qwen con pesos abiertos. Si te interesan modelos competidores, no te pierdas nuestras guías de DeepSeek v4, el GPT-5.5 de OpenAI y el Claude Opus 4.7 de Anthropic.
Qwen 3.6 Plus es el modelo insignia de Alibaba de abril de 2026. Su columna vertebral combina atención lineal con mixture-of-experts disperso, el razonamiento viene activado por defecto y texto, imágenes y vídeo pasan por la misma API.
Las llamadas a funciones usan el protocolo de tool calling de OpenAI. Alibaba posiciona este lanzamiento como "hacia agentes para el mundo real": un único modelo para entradas desordenadas que requieren razonamiento, lectura de imágenes y una llamada a función en un solo paso.
El nivel Plus es de pesos cerrados. No puedes descargar el checkpoint ni ejecutarlo en tu propio hardware (el modelo es demasiado grande para hardware de consumo). Alibaba publica una variante open-source Qwen/Qwen3.6-35B-A3B con contexto por defecto de 262K, pero es otro producto distinto. Para este tutorial, usamos la API alojada.
Qwen 3.6 Plus acepta hasta 1M de tokens de entrada y devuelve hasta 65.536 tokens de salida por llamada. Admite texto, imagen y vídeo. Las llamadas a herramientas son nativas mediante el esquema de OpenAI. En la página del modelo de OpenRouter verás precios, latencia por proveedor y throughput de los backends enrutados.
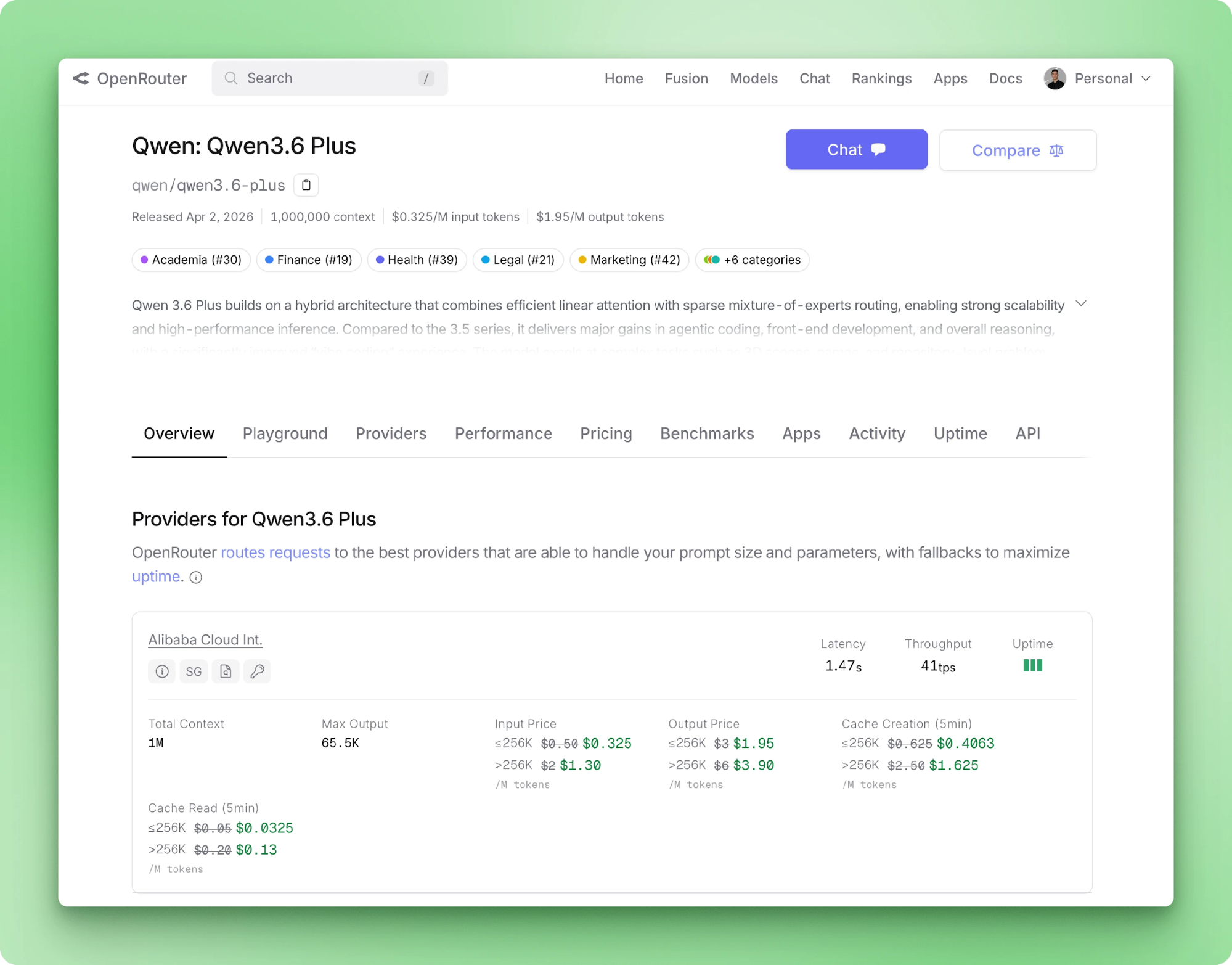
El chain-of-thought corre por defecto en cada llamada y el contenido del razonamiento se transmite en un campo separado de la respuesta. Un nuevo parámetro de 3.6 Plus mantiene los trazos de razonamiento anteriores adjuntos a los mensajes entre turnos.
Alibaba lo recomienda para bucles de agente donde turnos posteriores se benefician de cadenas de pensamiento anteriores. Para extracciones one-shot como la nuestra, preservar el trazo malgasta tokens, así que lo desactivamos.
Tres métricas importan para este tutorial:
Las dos primeras son por lo que apuntar a facturas escaneadas tiene sentido. La tercera es por lo que podemos esperar que el modelo siga un protocolo de tool call sin mucha ingeniería de prompts.
El salto de 3.5 Plus a 3.6 Plus es pequeño en la mayoría de métricas. Programación y razonamiento suben unos puntos. El mayor cambio es que el razonamiento pasa de ser un interruptor a ser el valor por defecto. El OCR y la localización de objetos son lo que más mejora.
|
Capacidad |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Modo de razonamiento |
Activado por defecto (se puede desactivar con |
CoT siempre activo |
|
Ventana de contexto |
Hasta 1M de tokens |
1M de tokens (por defecto) |
|
Multimodal |
Visión-lenguaje nativa |
Nativa + OCR y localización de objetos mejorados |
|
SWE-bench Verified |
76,8 |
78,8 |
|
Terminal-Bench 2.0 |
58,0 |
61,6 |
|
GPQA |
90,0 |
90,4 |
|
Razonamiento entre turnos |
— |
Parámetro |
Si has estado ejecutando 3.5 Plus en producción, la actualización implica adoptar el nuevo parámetro preserve_thinking y tener en cuenta que el razonamiento ahora se factura en cada llamada. Las principales mejoras están en bucles de agente y visión documental, justo lo que usamos aquí.
Puedes acceder al modelo de dos formas. La oficial es Alibaba Cloud Model Studio, que te da un endpoint directo en https://dashscope-intl.aliyuncs.com/compatible-mode/v1. La otra es OpenRouter, que enruta a Alibaba con una capa de facturación unificada y un alta más sencilla.
El tutorial usa OpenRouter porque crear la clave es más rápido y hay menos particularidades de endpoint. Si prefieres el camino directo, cambia dos líneas y sigue.
Alibaba Cloud Model Studio funciona igual de bien que OpenRouter para este tutorial. Lo único que cambia es la URL base y el nombre de la variable de entorno.
Regístrate en openrouter.ai con tu cuenta de Google o GitHub. El plan gratuito está disponible sin tarjeta y basta para seguir este tutorial de principio a fin. Si más adelante quieres procesar mayor volumen, añade créditos para subir de nivel de throughput y quitar el límite de tasa por modelo.
Una vez dentro, ve a openrouter.ai/settings/keys y crea una clave. Ponle una etiqueta tipo qwen-tutorial para poder revocarla después.
Copia ahora el valor de la clave, porque OpenRouter solo lo muestra una vez. Luego guárdalo en un archivo .env en la raíz del proyecto:
OPENROUTER_API_KEY=sk-or-v1-...La cargaremos con python-dotenv en la siguiente sección. Si prefieres ir directo con Alibaba Cloud, la clave sale de modelstudio.console.alibabacloud.com y va en DASHSCOPE_API_KEY.
Instala los dos paquetes que necesitamos para la primera llamada de verificación:
pip install openai python-dotenvEl paquete openai es el mismo SDK que usarías con el endpoint de OpenAI. Tanto OpenRouter como Alibaba Cloud Model Studio implementan la API de Chat Completions de OpenAI, así que el cliente no cambia.
Crea un archivo hello.py y verifica la conexión:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Al ejecutar python hello.py debería imprimirse una respuesta corta. La latencia hasta el primer token en el plan gratuito puede tardar unos segundos porque el modelo construye un trazo de razonamiento antes de generar la respuesta visible.
El proyecto de ejemplo es una canalización de procesamiento de facturas. Acepta dos formatos: PDFs de texto y JPGs escaneados. Cada factura pasa por Qwen 3.6 Plus con razonamiento activado y los campos extraídos vuelven mediante una llamada a herramienta. Cada factura recorre cuatro etapas:
Decodificar la entrada (codificar en base64 la imagen o convertir primero cada página del PDF a imagen)
Transmitir el trazo de razonamiento desde el modelo
Parsear la llamada a herramienta en JSON estructurado
Escribir una fila en results.csv
Todo el código de esta sección está en bextuychiev/qwen-invoice-pipeline-tutorial. Clónalo para seguir el paso a paso o úsalo como referencia mientras construyes tu propia versión.
Crea un directorio invoice-pipeline/ y organízalo así:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtLa separación entre client.py y los processors mantiene la configuración de OpenRouter en un solo archivo. Si más tarde cambias a Alibaba Cloud, editas client.py y nada más.
client.py envuelve el cliente de OpenAI con la URL base y el ID de modelo correctos:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example va al lado para que cualquiera que clone el repo sepa qué rellenar:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1El repo acompaña seis facturas de ejemplo de tres fuentes:
Las facturas reales de empresa no suelen poder redistribuirse públicamente por contener PII, así que usamos estas. En el README del repo tienes los totales de referencia si quieres comprobar la canalización contra ellos.
Si has usado Qwen 3.5, el CoT era un interruptor por llamada: enable_thinking=True dentro de extra_body. En 3.6 Plus, el razonamiento corre por defecto y el parámetro existe sobre todo para apagarlo. Los tokens de razonamiento siempre se facturan cuando está activo, así que el "siempre activo" es una decisión de coste, no una función gratis.
Cuando haces streaming de una respuesta, delta.reasoning_content llega primero y luego delta.content (o delta.tool_calls en nuestro caso).
Una llamada mínima que extrae una factura e imprime el trazo de razonamiento según llega sería así:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Leemos los bytes del JPG del disco, los codificamos en base64 y envolvemos el resultado en un URI data:. Ese formato permite que el protocolo de bloques de contenido de OpenAI acepte imágenes inline sin URL alojada. El bloque image_url toma directamente el URI y el modelo ve la factura como si hubieras pasado un enlace.
extra_body={"enable_thinking": True} reenvía la bandera enable_thinking a Qwen. El SDK de OpenAI no conoce este parámetro, así que extra_body es la forma de pasar opciones específicas del proveedor.
Al ejecutarlo con invoice_04.jpg, la respuesta en streaming llega como un resumen corto:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Corto es justo lo que pedimos: el prompt del sistema dijo "summarize" y nada más. Cuando la tarea crece (líneas, categorías, campos estructurados), el trazo de razonamiento también crece. Lo veremos en la siguiente sección: el mismo modelo con la misma imagen dedica la mayor parte de su presupuesto a pensar antes de responder.
Añadir /no_think al prompt de usuario es un interruptor suave que desactiva el CoT en esa llamada. Útil para depurar cuando quieres una respuesta más rápida sin razonamiento.
El razonamiento hace que la extracción sea legible, pero la salida sigue siendo texto libre dentro del trazo. Para recibir siempre JSON estructurado y parseable, definimos una herramienta, extract_invoice, y ponemos tool_choice="auto" con un prompt del sistema que instruye al modelo a llamar siempre a la herramienta.
El esquema en tools.py describe seis campos. La forma externa sigue el formato estándar de OpenAI para herramientas-función:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Los seis campos van dentro de parameters.properties. Los escalares (vendor, date, total, tax) usan tipos JSON Schema simples. category usa un enum para que el modelo elija de un conjunto fijo de cuatro valores en vez de inventar etiquetas. line_items es el campo estructurado: un array de objetos, cada uno con su propia lista required:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},El esquema tiene dos niveles de required. La lista externa marca los campos de nivel superior que deben aparecer en cada extracción. La lista por ítem marca los subcampos obligatorios en cada línea. El esquema completo está en tools.py en el repo.
Los argumentos vuelven como una cadena con formato JSON dentro de tool_calls[0].function.arguments, no como objeto parseado, así que debes hacer json.loads tú mismo. En streaming, los argumentos llegan como una secuencia de deltas que hay que concatenar antes de parsear.
Un detalle: el endpoint de Qwen 3.6 Plus en OpenRouter no admite forzar la llamada a una herramienta. Si intentas tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, la petición devuelve un error:
No endpoints found that support the provided 'tool_choice' valueLa solución práctica es usar tool_choice="auto" y apoyarse en el prompt del sistema:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""En las seis facturas de ejemplo del repo, este prompt obtiene siempre una llamada a herramienta. En producción, aun así, protege el caso excepcional: comprueba finish_reason, verifica que tool_calls esté poblado y reintenta con una instrucción más clara si no lo está. La propia documentación de function calling de Qwen dice lo mismo. No se garantiza la generación de llamadas a herramientas; en producción necesitas un plan B.
Un efecto secundario: cuando pides campos estructurados, delta.reasoning_content se llena con un trazo largo. El modelo parsea la tabla fila a fila, debate la notación decimal europea en invoice_04.jpg y contrasta importes por línea con el total. Los tokens de razonamiento pueden superar 10x a los de respuesta en este tipo de prompts.
Ese es el coste del CoT siempre activo en extracción estructurada, por lo que preserve_thinking solo compensa en bucles de agente multi-turno donde un turno posterior lee el trazo. Nosotros hacemos extracción one-shot: el trazo se muestra por terminal y lo descartamos.
Para JPGs, el flujo son tres pasos:
Leer los bytes de la imagen del disco
Codificarlos en base64
Poner el resultado en un bloque image_url con un URI data:
Los PDFs necesitan un paso extra porque la ruta de visión de Qwen acepta imágenes, no PDFs directamente. Convierte cada página a una imagen de PIL con pdf2image y envía las páginas como una lista de bloques de imagen en el mismo mensaje.
Ambas rutas comparten la misma llamada al modelo, así que la llamada vive en processors/image.py y processors/pdf.py delega en ella. Empieza con los imports (el SYSTEM_PROMPT de arriba vive en el mismo módulo):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveEl codificador convierte una ruta a JPG en el URI data: que espera la API:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"La ayuda compartida _call_with_images construye el array de contenido del usuario (texto + una o más imágenes) y envía la petición en streaming. Del stream, recoge dos piezas: el trazo de razonamiento y los argumentos de la llamada a herramienta. Primero, la configuración de la petición:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Luego, el bucle del stream separa los deltas de razonamiento de los deltas de argumentos de la llamada a herramienta:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}El punto de entrada público para JPGs es una sola línea que usa esas utilidades:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)El procesador de PDF reutiliza _call_with_images y solo añade la conversión de página a imagen:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image requiere poppler instalado. Instálalo con:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsPara PDFs multipágina, envía cada página como su propio bloque de imagen en el mismo mensaje. Qwen las lee juntas y produce una sola extracción, que es lo que quieres cuando los totales están en la página 2.
150 DPI mantiene el texto legible sin inflar la carga. Subir más hace la petición más grande sin mejorar la precisión en estas pruebas. La documentación de visión de Alibaba cubre formatos soportados y límites.
main.py recorre sample_invoices/, enruta cada archivo por extensión, llama al procesador adecuado y escribe los resultados combinados a un CSV. Imports y constantes primero:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}El bucle principal itera el directorio de muestras ordenado, enruta por extensión y aplana cada extracción a una fila apta para CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Por último, escribe las filas en disco y muestra el recuento:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
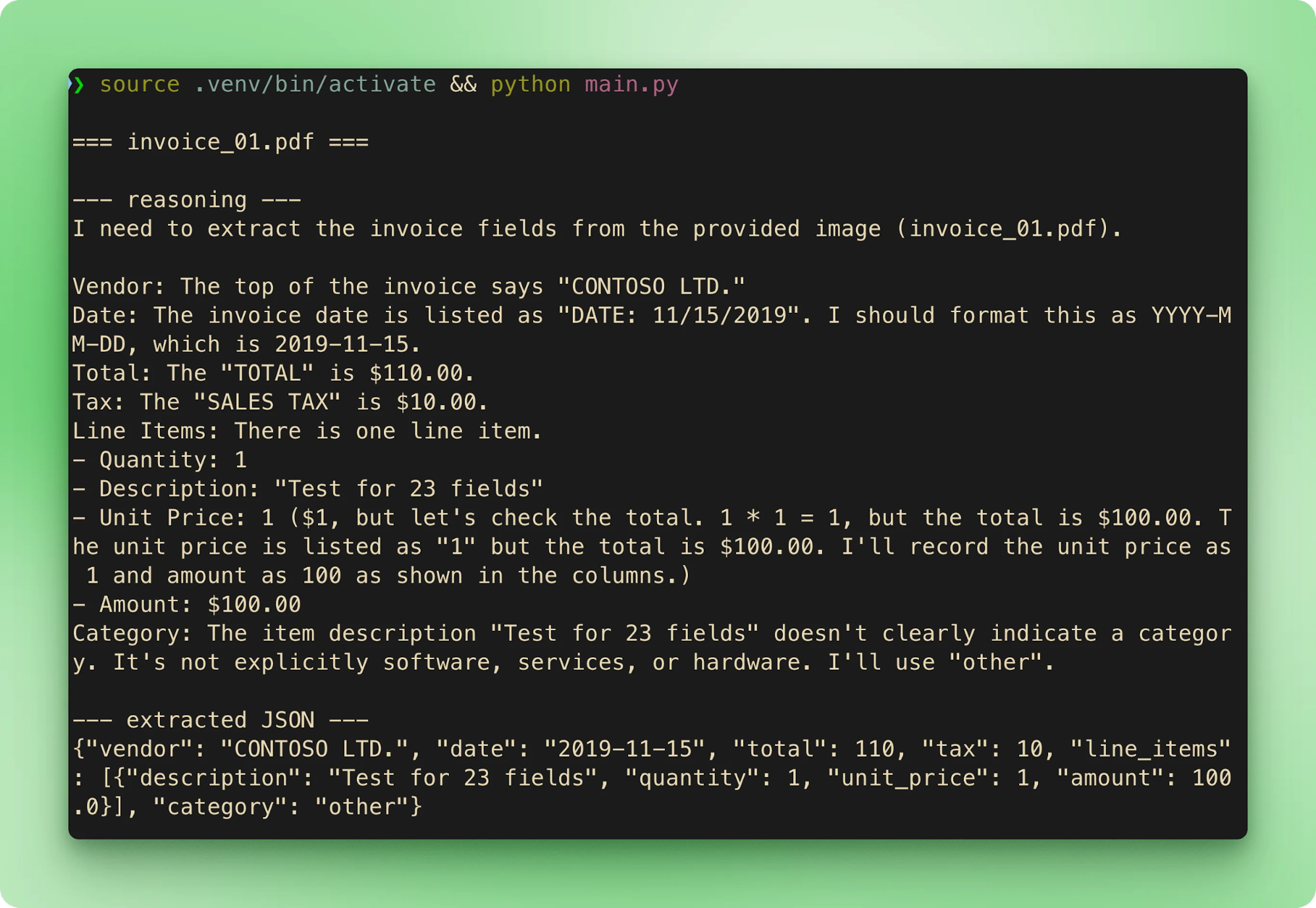
main()Al ejecutar python main.py se recorren las seis muestras en orden. Cada factura transmite su nombre de archivo, luego el trazo de razonamiento y después el JSON extraído, antes de pasar a la siguiente:
results.csv agrega cada extracción en una fila por factura:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Los totales coinciden con los de referencia en las seis. La latencia en el plan gratuito va de 15 a 40 segundos por factura. La mayor parte del tiempo es el razonamiento antes de que empiece el streaming de la llamada a herramienta.
Algunos patrones marcan la diferencia entre una canalización que funciona una vez y otra que sigue funcionando con facturas reales.
Mantén los secretos fuera del código. El patrón .env y python-dotenv que hemos usado es la base. Añade .env a tu .gitignore antes del primer commit para que la clave nunca llegue al repo.
Gestiona límites de tasa con backoff exponencial. OpenRouter aplica límites por proveedor con respuestas HTTP 429. La librería tenacity te da una implementación con decoradores y el patrón del cookbook de OpenAI para wait_random_exponential funciona sin cambios.
Usa streaming cuando esperes respuestas largas. El CoT siempre activo alarga las respuestas por defecto. Sin streaming, esperas a todo el bloque de razonamiento antes de ver nada. El streaming da feedback temprano, mantiene la UI fluida y te permite abortar una petición que va por mal camino.
Usa preserve_thinking solo si turnos posteriores leerán el razonamiento anterior. Para extractores one-shot como este, son tokens desperdiciados. Para bucles de agente multi-turno (cadenas de tool calling, planificación, depuración), el parámetro existe para ese contexto entre turnos. La documentación de deep thinking de Alibaba también cubre thinking_budget, un tope duro de tokens de razonamiento por llamada.
Las respuestas del plan gratuito pueden registrarse para entrenamiento. El plan gratis de OpenRouter enruta por proveedores que pueden retener prompts. No es apto para facturas con PII real, nombres de clientes o datos de pago. Pasa a un plan de pago en OpenRouter (o directo a Alibaba Cloud con cuenta de pago) antes de procesar datos reales.
Sin autoalojamiento en el nivel Plus. Despliegues que necesitan aislamiento total u on-prem no pueden usar la API alojada. La variante open-source Qwen3.6-35B-A3B es otra opción a valorar en esos casos.
El tiempo hasta el primer token puede ser lento cuando empieza el razonamiento. Configura timeouts generosos; 30 a 60 segundos es razonable para entrada con imagen. Asegúrate de que tu lógica de reintentos trata por separado los timeouts de lectura y los 429.
La salida no es determinista incluso con CoT siempre activo. En pruebas con las muestras del repo, invoice_01.pdf salió como $610.00 la mayoría de veces, pero cambió a $110.00 en al menos una repetición con entradas idénticas. El trazo de razonamiento llegó a la respuesta correcta en ambos casos, pero el argumento final de la llamada a herramienta difirió. Dos mitigaciones: baja temperature (0,1–0,2 para extracción pura) y valida contra referencia o usa una segunda pasada cuando la precisión lo justifique.
Desde aquí, envolver la canalización en un framework de agentes es un paso pequeño. El bucle de llamadas a herramientas, el parser en streaming y el escritor de CSV son las mismas piezas que un framework de agentes orquesta a lo largo de múltiples turnos. El curso de DataCamp Developing LLM Applications with LangChain recorre estos patrones con memoria, estado y enrutado multi-herramienta.
Cursos de IA agente
programa
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Zoumana Keita

