
Tracks
Cơ bản về Trợ lý Trí tuệ Nhân tạo
6 giờ
Alibaba phát hành Qwen 3.6 Plus vào tháng 4/2026. Thông số: SWE-bench Verified đạt 78.8, cửa sổ ngữ cảnh 1M token theo mặc định, đầu vào đa phương thức gốc và tư duy luôn bật. Với lập trình viên Python, điểm thú vị không nằm ở bảng benchmark, mà ở chỗ mô hình chỉ có API và hoạt động với gói OpenAI tiêu chuẩn bằng cách thay base URL.
Trong hướng dẫn này, chúng ta sẽ dùng ba tính năng chính của nó trong một dự án: chain-of-thought (lập luận chuỗi), gọi công cụ để xuất dữ liệu có cấu trúc, và thị giác trên hóa đơn quét. Kết quả là một pipeline xử lý hóa đơn nhỏ đọc PDF và JPG, hiển thị quá trình suy luận và trả về JSON đã được kiểm tra mà bạn có thể ghi vào CSV.
Bạn cần Python 3.10 trở lên và quen với việc gọi API. Không cần GPU, không tải mô hình, không tự lưu trữ. Chúng ta sẽ truy cập Qwen 3.6 Plus qua OpenRouter, nên quy trình đăng ký chỉ một bước, và OpenAI SDK dùng y nguyên.
Tôi cũng rất khuyến nghị bạn xem hướng dẫn Fine-Tuning Qwen 3.6, phiên bản open-weights mới nhất của Qwen. Nếu bạn quan tâm đến các mô hình đối thủ, hãy đọc các bài về DeepSeek v4, GPT-5.5 của OpenAI và Claude Opus 4.7 của Anthropic.
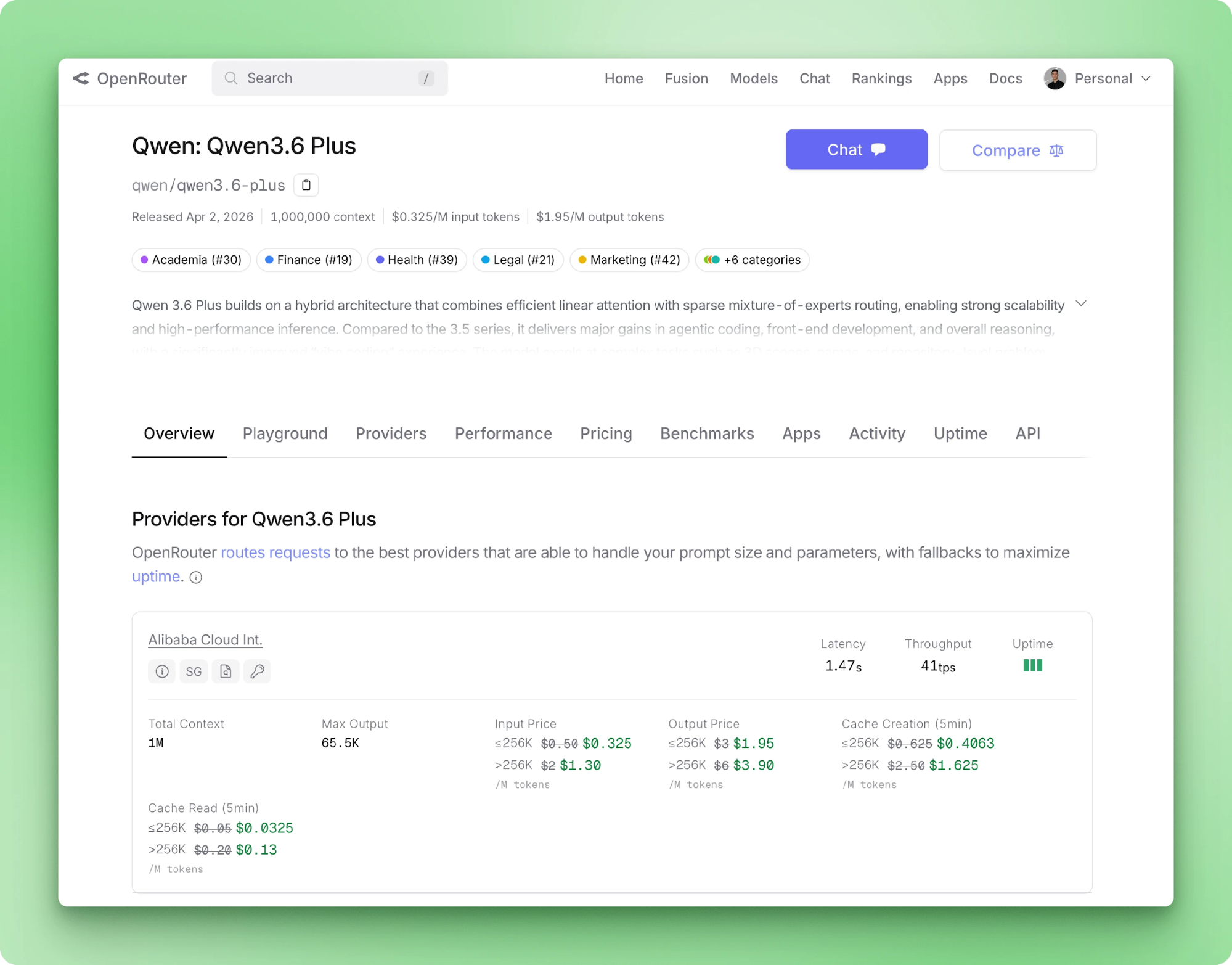
Qwen 3.6 Plus là mô hình chủ lực tháng 4/2026 của Alibaba. Kiến trúc xương sống là tổ hợp attention tuyến tính lai cộng với sparse mixture-of-experts, tư duy chạy mặc định, và văn bản, ảnh, video đều dùng chung một API.
Function calling dùng giao thức tool-call của OpenAI. Alibaba định vị bản phát hành là "hướng tới agent thực tế," tức một mô hình cho đầu vào lộn xộn cần suy luận, đọc ảnh và gọi hàm trong một bước.
Phiên bản Plus là closed weights. Bạn không thể tải checkpoint và chạy trên phần cứng của mình (mô hình quá lớn để chạy trên phần cứng phổ thông). Alibaba phát hành biến thể mã nguồn mở Qwen/Qwen3.6-35B-A3B với ngữ cảnh mặc định 262K, nhưng đó là sản phẩm khác. Trong hướng dẫn này, chúng ta dùng API được lưu trữ.
Qwen 3.6 Plus nhận tối đa 1M token đầu vào và trả về tối đa 65.536 token đầu ra mỗi lượt gọi. Các phương thức đầu vào gồm văn bản, ảnh và video. Gọi công cụ là tính năng gốc qua schema của OpenAI. Trang mô hình của OpenRouter liệt kê giá, độ trễ nhà cung cấp và thông lượng cho các backend được định tuyến.
Chain-of-thought chạy mặc định trên mọi lượt gọi, và nội dung suy luận được stream về ở một trường riêng so với câu trả lời. Một tham số mới của 3.6 Plus giữ lại dấu vết suy luận đính kèm vào tin nhắn qua nhiều lượt.
Alibaba khuyến nghị dùng cho vòng lặp agent nơi các lượt sau hưởng lợi từ chuỗi suy luận trước đó. Với trích xuất one-shot như của chúng ta, giữ dấu vết sẽ lãng phí token, nên ta tắt đi.
Ba điểm benchmark quan trọng cho hướng dẫn này:
Hai điểm đầu là lý do hóa đơn quét là mục tiêu hợp lý. Điểm thứ ba là lý do ta có thể kỳ vọng mô hình tuân theo giao thức gọi công cụ mà không cần prompt engineering nặng tay.
Bước nhảy từ 3.5 Plus lên 3.6 Plus là nhỏ trên hầu hết chỉ số. Benchmark code và suy luận tăng vài điểm. Thay đổi lớn hơn là tư duy chuyển từ công tắc bật/tắt sang mặc định. OCR và định vị đối tượng cải thiện nhiều nhất.
|
Năng lực |
Qwen 3.5 Plus |
Qwen 3.6 Plus |
|
Chế độ suy luận |
Bật mặc định (có thể tắt với |
CoT luôn bật |
|
Cửa sổ ngữ cảnh |
Tối đa 1M token |
1M token (mặc định) |
|
Đa phương thức |
Thị giác-ngôn ngữ gốc |
Gốc + cải thiện OCR, định vị đối tượng |
|
SWE-bench Verified |
76.8 |
78.8 |
|
Terminal-Bench 2.0 |
58.0 |
61.6 |
|
GPQA |
90.0 |
90.4 |
|
Suy luận qua nhiều lượt |
— |
Tham số |
Nếu bạn đã chạy 3.5 Plus trong sản xuất, việc nâng cấp đồng nghĩa áp dụng tham số preserve_thinking mới và lưu ý rằng suy luận sẽ bị tính phí trên mọi lượt gọi. Lợi ích chính là ở vòng lặp agent và thị giác tài liệu, cũng là trọng tâm của hướng dẫn này.
Bạn có thể truy cập mô hình theo hai cách. Cách chính thức là Alibaba Cloud Model Studio, cung cấp endpoint trực tiếp tại https://dashscope-intl.aliyuncs.com/compatible-mode/v1. Cách còn lại là OpenRouter, định tuyến đến Alibaba phía sau lớp thanh toán thống nhất và quy trình đăng ký đơn giản hơn.
Hướng dẫn dùng OpenRouter vì quy trình tạo khóa nhanh hơn và ít khác biệt endpoint hơn. Nếu bạn muốn đi đường trực tiếp, chỉ cần đổi hai dòng và tiếp tục.
Alibaba Cloud Model Studio hoạt động tốt như OpenRouter cho hướng dẫn này. Chỉ thay đổi base URL và tên biến môi trường.
Đăng ký tại openrouter.ai bằng tài khoản Google hoặc GitHub. Tầng miễn phí không cần thẻ tín dụng, đủ để bạn theo hướng dẫn này từ đầu đến cuối. Nếu sau này bạn định chạy khối lượng lớn hơn, nạp tiền sẽ đưa bạn lên tầng thông lượng cao hơn và gỡ giới hạn tốc độ theo mô hình.
Sau khi đăng nhập, vào openrouter.ai/settings/keys và tạo một khóa. Đặt nhãn như qwen-tutorial để sau này bạn có thể thu hồi.
Sao chép giá trị khóa ngay bây giờ, vì OpenRouter chỉ hiển thị một lần. Sau đó lưu vào file .env ở thư mục gốc dự án:
OPENROUTER_API_KEY=sk-or-v1-...Chúng ta sẽ nạp nó bằng python-dotenv ở phần tiếp theo. Nếu bạn muốn dùng Alibaba Cloud trực tiếp, khóa lấy từ modelstudio.console.alibabacloud.com và đưa vào DASHSCOPE_API_KEY.
Cài hai gói cần cho lượt gọi xác minh đầu tiên:
pip install openai python-dotenvGói openai chính là SDK bạn sẽ dùng với endpoint của OpenAI. Cả OpenRouter và Alibaba Cloud Model Studio đều triển khai OpenAI Chat Completions API, nên mã client không cần đổi.
Tạo file tên hello.py và kiểm tra kết nối:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)
response = client.chat.completions.create(
model="qwen/qwen3.6-plus",
messages=[{"role": "user", "content": "Say hi in five words."}],
)
print(response.choices[0].message.content)Chạy python hello.py sẽ in ra một phản hồi ngắn. Độ trễ token đầu tiên ở tầng miễn phí có thể vài giây vì mô hình tạo dấu vết suy luận trước khi sinh câu trả lời hiển thị.
Dự án mẫu là pipeline xử lý hóa đơn. Nó nhận hai định dạng: PDF văn bản và JPG quét. Mỗi hóa đơn chạy qua Qwen 3.6 Plus với suy luận bật, và các trường trích xuất trả về qua một cuộc gọi công cụ. Mỗi hóa đơn đi qua bốn giai đoạn:
Giải mã đầu vào (mã hóa base64 ảnh, hoặc chuyển từng trang PDF sang ảnh trước)
Stream dấu vết suy luận từ mô hình
Phân tích tool call thành JSON có cấu trúc
Ghi một dòng vào results.csv
Toàn bộ mã cho phần này nằm ở bextuychiev/qwen-invoice-pipeline-tutorial. Hãy clone để theo cùng, hoặc dùng làm tham chiếu khi bạn tự xây dựng phiên bản của mình.
Tạo thư mục invoice-pipeline/ và sắp xếp như sau:
invoice-pipeline/
├── .env
├── .env.example
├── client.py
├── tools.py
├── main.py
├── processors/
│ ├── image.py
│ └── pdf.py
├── sample_invoices/
│ ├── invoice_01.pdf
│ ├── invoice_02.pdf
│ ├── invoice_03.pdf
│ ├── invoice_04.jpg
│ ├── invoice_05.jpg
│ └── invoice_06.jpg
└── requirements.txtSự tách biệt giữa client.py và các processor giữ cấu hình OpenRouter trong một file. Nếu sau này bạn chuyển sang Alibaba Cloud, bạn chỉ sửa client.py mà không cần đổi gì khác.
client.py bọc OpenAI client với base URL đúng và ID mô hình:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
MODEL_ID = "qwen/qwen3.6-plus"
def get_client() -> OpenAI:
return OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
).env.example đi kèm để ai clone repo cũng biết cần điền gì:
OPENROUTER_API_KEY=your-openrouter-key
# Optional: Alibaba Cloud Model Studio (direct path)
# DASHSCOPE_API_KEY=your-dashscope-key
# DASHSCOPE_BASE_URL=https://dashscope-intl.aliyuncs.com/compatible-mode/v1Repo đi kèm cung cấp sáu hóa đơn mẫu từ ba nguồn:
Hóa đơn công ty thật không thể phân phối công khai vì PII, nên ta dùng các mẫu này. Tổng tiền chuẩn được liệt kê trong README của repo nếu bạn muốn đối chiếu pipeline.
Nếu bạn đã dùng Qwen 3.5, CoT là công tắc theo lượt gọi: enable_thinking=True trong extra_body. Ở 3.6 Plus, suy luận chạy mặc định, và tham số chủ yếu để tắt. Token suy luận luôn bị tính phí khi thinking bật, biến "luôn bật" thành quyết định chi phí thay vì tính năng miễn phí.
Khi bạn stream phản hồi, delta.reasoning_content đến trước, sau đó là delta.content (hoặc delta.tool_calls trong trường hợp của chúng ta).
Một lượt gọi tối thiểu để trích xuất hóa đơn và in dấu vết suy luận khi stream trông như sau:
import base64
from pathlib import Path
from client import get_client, MODEL_ID
client = get_client()
image_bytes = Path("sample_invoices/invoice_04.jpg").read_bytes()
data_uri = f"data:image/jpeg;base64,{base64.b64encode(image_bytes).decode()}"
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": "Read the invoice and summarize the vendor, date, and total."},
{"role": "user", "content": [
{"type": "text", "text": "Here is the invoice:"},
{"type": "image_url", "image_url": {"url": data_uri}},
]},
],
extra_body={"enable_thinking": True},
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
print(reasoning, end="", flush=True)
if delta.content:
print(delta.content, end="", flush=True)Chúng ta đọc byte JPG từ đĩa, mã hóa base64 và bọc kết quả trong URI data:. Định dạng này cho phép giao thức content-block của OpenAI nhận ảnh inline mà không cần URL host. Khối image_url nhận URI trực tiếp, và mô hình nhìn thấy hóa đơn như thể bạn đã truyền một liên kết.
extra_body={"enable_thinking": True} chuyển tiếp cờ enable_thinking đến Qwen. OpenAI SDK không biết về tham số này, nên extra_body là cách truyền tùy chọn riêng của nhà cung cấp.
Khi chạy với invoice_04.jpg, câu trả lời được stream về là một tóm tắt ngắn:
Based on the invoice provided:
* **Vendor:** Dunn PLC
* **Date:** 01/23/2019
* **Total:** $ 3 120,51Ngắn gọn đúng như yêu cầu: system prompt chỉ nói "summarize" và không gì thêm. Khi tác vụ lớn hơn (hạng mục, danh mục, trường có cấu trúc), dấu vết suy luận cũng dài hơn. Ta sẽ thấy ở phần tiếp theo, nơi cùng mô hình trên cùng ảnh dành phần lớn ngân sách đầu ra cho suy nghĩ trước khi trả lời.
Thêm /no_think vào prompt người dùng là một công tắc mềm để tắt CoT cho lượt đó. Hữu ích khi debug và bạn muốn phản hồi nhanh không suy luận.
Suy luận giúp quá trình trích xuất dễ đọc, nhưng đầu ra vẫn là văn bản tự do trong dấu vết suy luận. Để luôn nhận về JSON có cấu trúc, có thể phân tích, ta định nghĩa một công cụ, extract_invoice, và đặt tool_choice="auto" với system prompt yêu cầu mô hình luôn gọi công cụ.
Schema trong tools.py mô tả sáu trường. Hình dạng ngoài theo định dạng function-tool chuẩn của OpenAI:
EXTRACT_INVOICE_TOOL = {
"type": "function",
"function": {
"name": "extract_invoice",
"description": "Extract structured fields from an invoice image.",
"parameters": {
"type": "object",
"properties": {
# fields defined below
},
"required": ["vendor", "date", "total", "tax", "line_items", "category"],
},
},
}Sáu trường nằm trong parameters.properties. Trường vô hướng (vendor, date, total, tax) dùng kiểu JSON Schema thuần. category dùng enum để mô hình chọn từ bốn giá trị cố định thay vì tự bịa nhãn. line_items là trường có cấu trúc, một mảng đối tượng, mỗi đối tượng có danh sách required riêng:
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"},
"amount": {"type": "number"},
},
"required": ["description", "amount"],
},
},
"category": {
"type": "string",
"enum": ["software", "services", "hardware", "other"],
},Schema có hai cấp required. Danh sách ngoài đánh dấu các trường cấp cao bắt buộc xuất hiện trong mọi lần trích xuất. Danh sách theo từng mục đánh dấu các trường con bắt buộc có ở mọi dòng. Schema đầy đủ nằm trong tools.py của repo đi kèm.
Các đối số trả về là chuỗi định dạng JSON trong tool_calls[0].function.arguments, không phải đối tượng đã parse, nên bạn cần gọi json.loads. Khi stream, các đối số đến dưới dạng chuỗi delta mà bạn cần nối lại trước khi parse.
Một lưu ý: endpoint Qwen 3.6 Plus của OpenRouter không hỗ trợ bắt buộc gọi công cụ. Nếu bạn thử tool_choice={"type": "function", "function": {"name": "extract_invoice"}}, yêu cầu sẽ trả lỗi:
No endpoints found that support the provided 'tool_choice' valueCách khắc phục thực tế là dùng tool_choice="auto" và dựa vào system prompt:
SYSTEM_PROMPT = """You are an invoice extraction assistant. Read the invoice
image and respond by calling the extract_invoice tool with the fields you find.
Do not reply in prose, always call the tool. If a field is missing from the
invoice, use a sensible default: empty string for text fields, 0 for numeric
fields, an empty array for line_items."""Trên cả sáu hóa đơn mẫu trong repo đi kèm, prompt này luôn nhận được một tool call. Mã sản xuất vẫn nên phòng trường hợp ngoại lệ: kiểm tra finish_reason, xác minh tool_calls có dữ liệu, và thử lại với chỉ dẫn rõ hơn nếu không. Tài liệu function-calling của chính Qwen cũng nêu điều này. Việc tạo tool-call không được đảm bảo, và mã sản xuất cần phương án dự phòng.
Một hệ quả: khi prompt yêu cầu trường có cấu trúc, delta.reasoning_content sẽ đầy dấu vết dài. Mô hình phân tích bảng theo từng dòng, tranh luận về ký pháp thập phân châu Âu trên invoice_04.jpg, và đối chiếu số tiền hạng mục với tổng. Token suy luận có thể nhiều gấp 10 lần token câu trả lời trong kiểu prompt này.
Đó là chi phí của CoT luôn bật trong trích xuất có cấu trúc, và vì thế preserve_thinking chỉ hữu ích trên vòng lặp agent nhiều lượt nơi lượt sau đọc dấu vết. Chúng ta trích xuất one-shot, nên dấu vết stream ra terminal và bị loại bỏ.
Với JPG, luồng gồm ba bước:
Đọc byte ảnh từ đĩa
Mã hóa base64
Đưa kết quả vào khối nội dung image_url với URI data:
PDF cần thêm một bước vì đường thị giác của Qwen nhận ảnh thay vì file PDF trực tiếp. Chuyển từng trang thành ảnh PIL với pdf2image, rồi gửi các trang như danh sách khối ảnh trong cùng một tin nhắn.
Cả hai đường dùng chung một cuộc gọi mô hình, nên lời gọi nằm trong processors/image.py và processors/pdf.py ủy quyền cho nó. Bắt đầu với import (SYSTEM_PROMPT ở trên nằm cùng module):
# processors/image.py
import base64
import json
from pathlib import Path
from openai import OpenAI
from client import MODEL_ID
from tools import EXTRACT_INVOICE_TOOL
# SYSTEM_PROMPT defined aboveBộ mã hóa chuyển đường dẫn JPG thành URI data: mà API mong đợi:
def _encode_image(image_path: Path) -> str:
data = image_path.read_bytes()
b64 = base64.b64encode(data).decode("ascii")
suffix = image_path.suffix.lower().lstrip(".")
mime = "jpeg" if suffix in ("jpg", "jpeg") else suffix
return f"data:image/{mime};base64,{b64}"Hàm trợ giúp chung _call_with_images xây dựng mảng nội dung người dùng (văn bản + một hoặc nhiều ảnh) và gửi yêu cầu streaming. Từ stream, nó thu hai phần dữ liệu: dấu vết suy luận và đối số tool-call. Cấu hình yêu cầu trước:
def _call_with_images(client: OpenAI, data_uris: list[str], filename: str) -> dict:
user_content = [{"type": "text", "text": f"Invoice file: {filename}"}]
for uri in data_uris:
user_content.append({"type": "image_url", "image_url": {"url": uri}})
stream = client.chat.completions.create(
model=MODEL_ID,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
tools=[EXTRACT_INVOICE_TOOL],
tool_choice="auto",
extra_body={"enable_thinking": True},
stream=True,
)Sau đó vòng lặp stream tách delta suy luận khỏi delta đối số tool-call:
reasoning_parts: list[str] = []
tool_args_parts: list[str] = []
for chunk in stream:
delta = chunk.choices[0].delta
reasoning = getattr(delta, "reasoning_content", None)
if reasoning:
reasoning_parts.append(reasoning)
if delta.tool_calls:
for tc in delta.tool_calls:
if tc.function and tc.function.arguments:
tool_args_parts.append(tc.function.arguments)
extracted = json.loads("".join(tool_args_parts))
return {"file": filename, "reasoning": "".join(reasoning_parts), "extracted": extracted}Điểm vào công khai cho JPG là một dòng dùng các helper đó:
def process_image_invoice(client: OpenAI, image_path: Path) -> dict:
uri = _encode_image(image_path)
return _call_with_images(client, [uri], image_path.name)Processor PDF tái sử dụng _call_with_images và chỉ thêm chuyển đổi trang-sang-ảnh:
# processors/pdf.py
import base64
import io
from pathlib import Path
from openai import OpenAI
from pdf2image import convert_from_path
from processors.image import _call_with_images
def _page_to_data_uri(page) -> str:
buf = io.BytesIO()
page.save(buf, format="PNG")
b64 = base64.b64encode(buf.getvalue()).decode("ascii")
return f"data:image/png;base64,{b64}"
def process_pdf_invoice(client: OpenAI, pdf_path: Path) -> dict:
pages = convert_from_path(str(pdf_path), dpi=150)
uris = [_page_to_data_uri(p) for p in pages]
return _call_with_images(client, uris, pdf_path.name)pdf2image yêu cầu cài poppler. Cài bằng:
# macOS
brew install poppler
# Debian / Ubuntu
apt install poppler-utilsVới PDF nhiều trang, gửi mỗi trang như một khối ảnh riêng trong cùng một tin nhắn. Qwen đọc chúng cùng nhau và tạo một lần trích xuất, đúng như mong muốn khi tổng tiền nằm ở trang 2.
150 DPI giữ văn bản hóa đơn đủ đọc mà không phình to payload. Cao hơn làm yêu cầu lớn hơn mà không cải thiện độ chính xác trong thử nghiệm với các mẫu này. Tài liệu thị giác của Alibaba nêu các định dạng hỗ trợ và giới hạn trên.
main.py duyệt sample_invoices/, định tuyến từng file theo phần mở rộng, gọi processor phù hợp và ghi kết quả hợp nhất vào CSV. Import và hằng số trước:
# main.py
import csv
from pathlib import Path
from client import get_client
from processors.image import process_image_invoice
from processors.pdf import process_pdf_invoice
SAMPLES_DIR = Path(__file__).parent / "sample_invoices"
RESULTS_PATH = Path(__file__).parent / "results.csv"
IMAGE_EXTS = {".jpg", ".jpeg", ".png"}
PDF_EXTS = {".pdf"}Vòng lặp chính duyệt thư mục mẫu theo thứ tự, định tuyến theo phần mở rộng, và làm phẳng mỗi lần trích xuất thành một dòng phù hợp CSV:
def main() -> None:
client = get_client()
results = []
invoice_paths = sorted(
p for p in SAMPLES_DIR.iterdir()
if p.suffix.lower() in IMAGE_EXTS | PDF_EXTS
)
for path in invoice_paths:
if path.suffix.lower() in PDF_EXTS:
result = process_pdf_invoice(client, path)
else:
result = process_image_invoice(client, path)
extracted = result["extracted"]
results.append({
"file": result["file"],
"vendor": extracted.get("vendor", ""),
"date": extracted.get("date", ""),
"total": extracted.get("total", ""),
"tax": extracted.get("tax", ""),
"category": extracted.get("category", ""),
"line_item_count": len(extracted.get("line_items", [])),
})Cuối cùng, ghi các dòng ra đĩa và log số lượng:
with RESULTS_PATH.open("w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(results[0].keys()))
writer.writeheader()
writer.writerows(results)
print(f"\nProcessed {len(results)} invoices → {RESULTS_PATH.name}")
if __name__ == "__main__":
main()Chạy python main.py sẽ duyệt sáu mẫu theo thứ tự. Mỗi hóa đơn stream tên file, sau đó là dấu vết suy luận, rồi JSON trích xuất, trước khi chuyển sang hóa đơn tiếp theo:
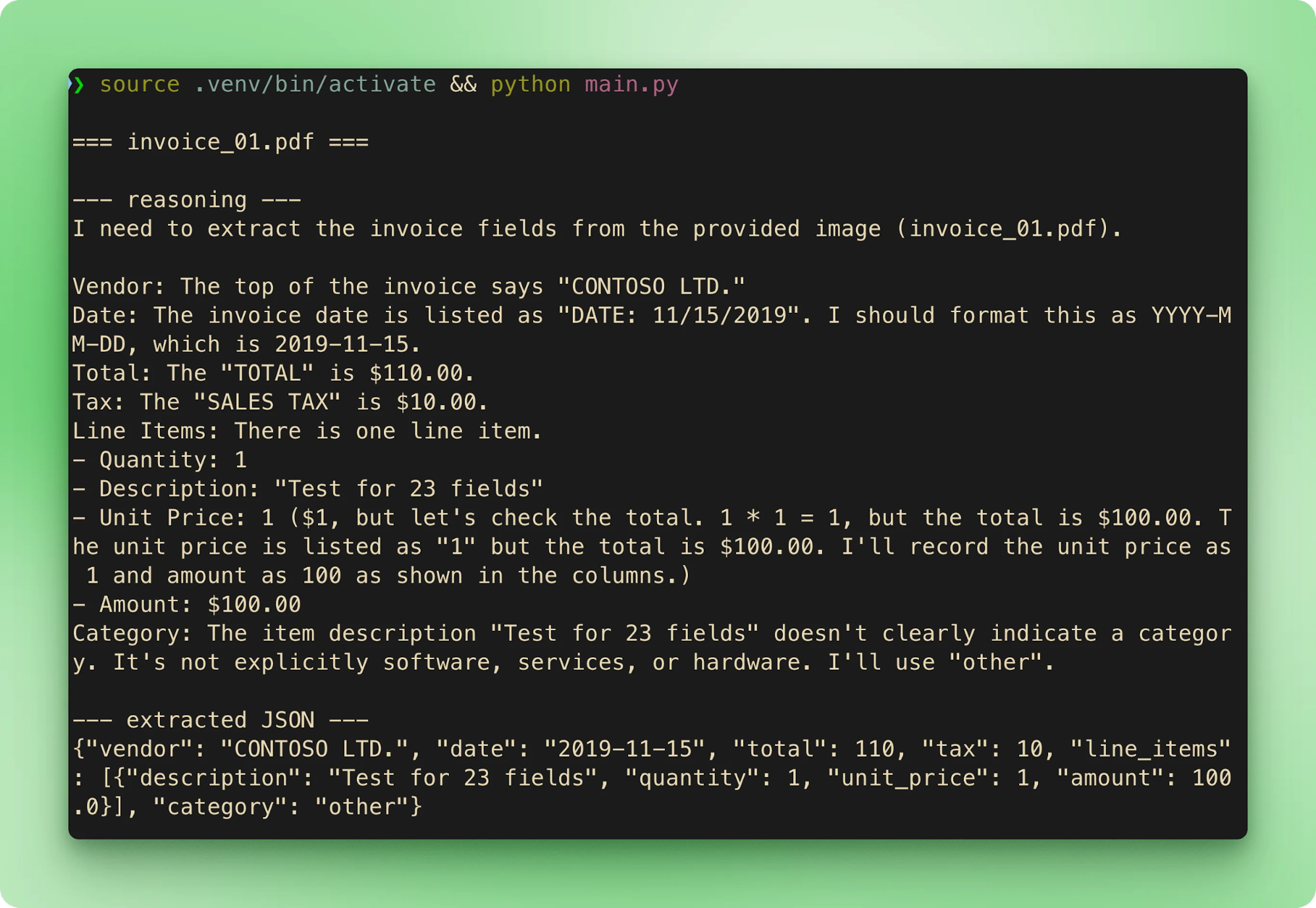
results.csv tổng hợp mỗi lần trích xuất thành một dòng mỗi hóa đơn:
|
file |
vendor |
date |
total |
tax |
category |
line_item_count |
|
|
CONTOSO LTD. |
2019-11-15 |
610.00 |
10.00 |
other |
1 |
|
|
Contoso, Ltd. |
2020-09-10 |
10686.25 |
311.25 |
services |
3 |
|
|
ABC Private Limited |
2021-01-01 |
6231.09 |
61.69 |
other |
4 |
|
|
Dunn PLC |
2019-01-23 |
3120.51 |
283.68 |
hardware |
4 |
|
|
Crawford, Acosta and Solomon |
2012-08-22 |
60.45 |
5.50 |
hardware |
1 |
|
|
Paul, Wilson and Gonzalez |
2016-02-25 |
1025.61 |
93.24 |
other |
5 |
Tổng tiền khớp với ground truth trên cả sáu. Độ trễ ở tầng miễn phí từ 15 đến 40 giây mỗi hóa đơn. Phần lớn thời gian là giai đoạn suy luận trước khi tool call bắt đầu stream.
Một vài mẫu thiết kế quyết định khác biệt giữa pipeline chạy được một lần và pipeline bền bỉ trên hóa đơn thực.
Giữ bí mật ngoài mã nguồn. Mẫu .env và python-dotenv chúng ta dùng là mức cơ bản. Thêm .env vào .gitignore trước commit đầu tiên để khóa không bao giờ lên repo.
Xử lý rate limit với exponential backoff. OpenRouter áp hạn mức theo nhà cung cấp bằng HTTP 429. Thư viện tenacity cung cấp triển khai dạng decorator, và mẫu OpenAI cookbook cho wait_random_exponential dùng được ngay.
Stream khi phản hồi sẽ dài. CoT luôn bật làm phản hồi dài hơn mặc định. Gọi không-stream đồng nghĩa chờ toàn bộ khối suy luận trước khi thấy gì. Streaming cho phản hồi sớm, giữ UI phản hồi tốt và cho phép bạn hủy yêu cầu khi thấy sai hướng.
Chỉ dùng preserve_thinking khi lượt sau đọc suy luận lượt trước. Với bộ trích xuất one-shot như pipeline này, đó là lãng phí token. Với vòng lặp agent nhiều lượt (chuỗi gọi công cụ, tác vụ lập kế hoạch, quy trình debug), tham số này tồn tại cho ngữ cảnh qua lượt. Tài liệu deep thinking của Alibaba cũng đề cập thinking_budget, giới hạn cứng token suy luận mỗi lượt.
Phản hồi tầng miễn phí có thể bị ghi nhật ký để huấn luyện. Tầng miễn phí của OpenRouter định tuyến qua các nhà cung cấp có thể giữ lại prompt. Điều này không phù hợp với hóa đơn chứa PII, tên khách hàng hay chi tiết thanh toán. Chuyển sang tầng trả phí của OpenRouter (hoặc trực tiếp Alibaba Cloud với tài khoản trả phí) trước khi đưa dữ liệu thật qua pipeline.
Không tự lưu trữ ở bản Plus. Triển khai cần air-gap hoặc on-prem không thể dùng API lưu trữ. Biến thể mã nguồn mở Qwen3.6-35B-A3B là lựa chọn khác đáng cân nhắc cho các trường hợp đó.
Thời gian tới token đầu tiên có thể chậm khi bắt đầu suy luận. Đặt timeout rộng rãi, 30 đến 60 giây là hợp lý cho đầu vào ảnh. Đảm bảo logic retry xử lý read timeout tách biệt với 429.
Đầu ra không tất định ngay cả với CoT luôn bật. Trong thử nghiệm với mẫu của repo đi kèm, invoice_01.pdf thường trích xuất $610.00. Ít nhất một lần chạy lại với đầu vào giống hệt, nó chuyển thành $110.00. Dấu vết suy luận đến đáp án đúng cả hai lần, nhưng đối số tool-call cuối cùng khác nhau. Hai cách giảm thiểu: đặt temperature thấp (0.1–0.2 cho trích xuất thuần), và xác thực với ground truth hoặc chạy lượt thứ hai khi độ chính xác đủ quan trọng để biện minh cuộc gọi thêm.
Từ đây, bọc pipeline trong một framework agent chỉ là bước nhỏ. Vòng lặp gọi công cụ, bộ phân tích stream và trình ghi CSV chính là các nguyên thủy mà một framework agent điều phối qua nhiều lượt. Khóa học Developing LLM Applications with LangChain của DataCamp hướng dẫn các mẫu này với bộ nhớ, trạng thái và định tuyến đa công cụ.
Khóa học về Agentic AI
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút