courses
SQL에서의 데이터 조작
4
326.4K
SQL로 작업할 때 데이터 정렬은 ORDER BY로 행을 쉽게 정리할 수 있어 간단합니다. 하지만 정렬만으로는 각 행이 그 순서에서 몇 번째 위치인지 알 수 없습니다. 이럴 때 순위 매기기가 유용합니다. 정렬된 데이터를 보는 데서 더 나아가, 특정 기준에 따라 각 행에 1위, 2위, 3위와 같은 위치를 부여하고 싶을 수 있습니다.
RANK() 함수는 정의된 순서에 따라 각 행에 숫자 순위를 부여하여 이 문제를 해결합니다. RANK()는 SQL 윈도 함수의 일부로, 개별 행 결과를 반환하면서도 행 집합에 걸친 계산을 수행할 수 있게 해줍니다.
이 튜토리얼에서는 RANK()의 문법과 실용적인 예제를 살펴보고, 동점 처리 방식과 DENSE_RANK(), ROW_NUMBER() 같은 유사 함수와의 차이점도 알아보겠습니다.
SQL이 처음이라면 Introduction to SQL 과정을 먼저 살펴보세요. 어느 정도 경험이 있다면 Intermediate SQL 과정을 추천합니다.
SQL의 RANK() 함수는 지정한 순서에 따라 각 행에 순위를 부여하는 윈도 함수입니다. 순위는 윈도 함수 내부의 ORDER BY에 의해 완전히 결정됩니다. 따라서 ORDER BY 절에 따라 각 행에 1, 2, 3 등의 위치를 부여합니다.
다음과 같은 점을 유의하세요. RANK()를 사용하면:
RANK() 함수의 기본 문법은 다음과 같습니다.
RANK() OVER (ORDER BY column)설명:
OVER 절: 함수가 적용되는 윈도(행 집합)를 정의합니다.
ORDER BY: 순위를 적용하는 기준을 결정합니다. 예: 높은 값에서 낮은 값 순.
PARTITION BY(선택): 데이터를 그룹으로 나누어 각 그룹 내에서 별도로 순위를 매깁니다.
다음은 PARTITION BY 절과 함께 사용하는 RANK()의 문법입니다.
RANK() OVER (PARTITION BY column1 ORDER BY column2)SQL RANK() 함수는 주요 데이터베이스에서 폭넓게 지원됩니다. 여기에는 PostgreSQL, MySQL(8.0+), Microsoft SQL Server, Oracle Database가 포함됩니다. 표준 ANSI SQL 명세의 일부이므로 시스템 전반에서 문법은 대부분 일관됩니다.
이제 RANK() 함수의 문법을 이해했으니, 간단한 예시로 작동 방식을 살펴보겠습니다.
직원별 급여 정보가 담긴 employees 테이블이 있다고 가정해 봅시다.
다음 쿼리를 사용해 급여에 따라 직원의 순위를 매길 수 있습니다.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;위 쿼리는 급여를 높은 금액부터 정렬하고, 가장 높은 급여가 순위 1을 받습니다. 두 행의 급여가 같다면 동일한 순위를 부여합니다.
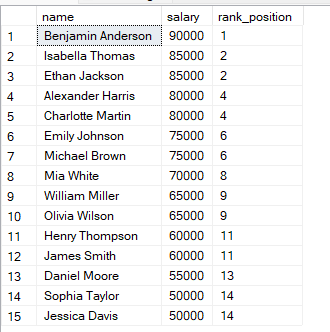
값이 같은 두 행은 동일한 순위를 받는 것을 확인할 수 있습니다.
그 다음 순위는 건너뜁니다. SQL은 동점을 고려하여 다음 순위 값을 스킵합니다.
그룹화와 데이터 집계를 더 배우려면 Introduction to SQL Server 과정을 추천합니다.
앞서 살펴본 대로, PARTITION BY 절을 사용하면 전체 데이터셋이 아니라 그룹 내에서 순위를 적용할 수 있습니다.
아래 예시에서는 직원을 department로 그룹화하고, 각 부서에서 새롭게 순위를 시작합니다. 즉, 각 그룹은 독립적인 순위 시퀀스를 가집니다.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;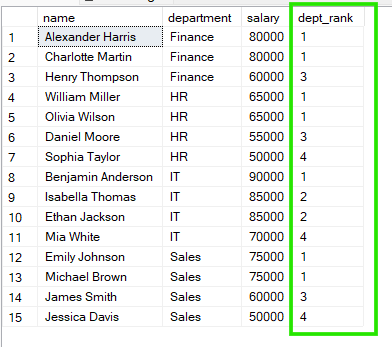
위 결과에서 “Sales”에서는 Emily Johnson과 Michael Brown이 함께 1위를 차지하고, “HR”에서는 William Miller와 Olivia Wilson이 함께 1위를 차지합니다.
SQL에서 데이터를 순위화할 때 RANK(), DENSE_RANK(), ROW_NUMBER() 중에서 선택할 수 있습니다. 이 함수들은 비슷해 보이지만 동작은 다음과 같습니다.
RANK(): 동점은 같은 순위를 공유하며, 그 뒤에는 공백이 생깁니다.
DENSE_RANK(): 동점은 같은 순위를 공유하지만, 순위에 공백이 없습니다.
ROW_NUMBER(): 값이 같아도 각 행에 고유한 번호를 부여하여 동점이 없습니다.
이 차이를 더 잘 이해하기 위해 아래 쿼리로 나란히 비교해 보겠습니다.
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;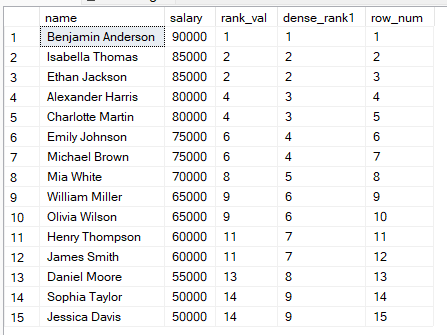
위 결과를 바탕으로 다음과 같이 선택할 수 있습니다.
RANK(): 순위의 “위치”가 중요하고 공백을 허용할 때 사용합니다.
DENSE_RANK(): 연속적인 순위를 원할 때 사용합니다.
ROW_NUMBER(): 데이터 페이지네이션처럼 모든 행에 고유한 번호가 필요할 때 사용합니다.
SQL RANK() 함수는 동점을 자연스럽게 처리하면서 데이터를 정렬하고자 할 때 가장 유용합니다. 또한 다음과 같은 사용 사례에서도 중요합니다.
SQL RANK()를 사용할 때 자주 보는 실수와 피하는 방법은 다음과 같습니다.
ORDER BY 누락: ORDER BY 절이 없으면 순위에 대한 논리가 정의되지 않아 예기치 않은 결과가 나올 수 있습니다.
동점 동작 오해: 초보자는 1, 2, 2, 3을 기대할 수 있지만, RANK()는 순위에 공백(1, 2, 2, 4)을 만듭니다.
ROW_NUMBER()가 필요한데 RANK() 사용: 고유하고 연속적인 값이 필요하다면 ROW_NUMBER()가 더 적합합니다.
필요할 때 PARTITION BY 미사용: 파티셔닝하지 않으면 순위가 그룹 내가 아니라 전체에 적용됩니다.
쿼리를 깔끔하게 유지하고 기대한 결과를 얻으려면 SQL RANK() 함수를 사용할 때 다음 모범 사례를 따르세요.
항상 명확한 정렬을 정의: 모호한 순위를 피하려면 DESC와 같은 방향을 ORDER BY 절에 명시하세요.
올바른 순위 함수 선택: RANK(), DENSE_RANK(), ROW_NUMBER() 중 동점 처리 방식에 맞는 것을 선택하세요.
동점 시나리오 테스트: 운영에 반영하기 전에 중복 값이 있을 때 데이터가 어떻게 동작하는지 확인하세요.
필터링과 결합: RANK()는 WHERE 절에서 직접 사용할 수 없으므로, “Top N”을 필터링하려면 랭킹 쿼리를 서브쿼리나 CTE로 감싸야 합니다.
RANK()는 동점처럼 현실 세계의 상황을 반영한 결과가 필요할 때 SQL에서 정렬 비교를 수행하는 데 유용한 도구입니다. 동점을 어떻게 처리하는지, 그리고 왜 순위가 반복되거나 숫자를 건너뛸 수 있는지 이해하는 것은 정확한 분석을 위해 중요합니다. 이 동작을 익히면, 특정 사용 사례에 가장 적합한지에 따라 DENSE_RANK()나 ROW_NUMBER() 같은 대안과 함께 적절히 선택할 수 있습니다.
이제 SQL에서 데이터를 순위화하는 방법을 배웠으니, 숙련된 데이터 분석가가 되기 위한 기술을 배우고 싶다면 Associate Data Analyst in SQL 커리어 트랙을 확인해 보세요. SQL로 프로페셔널 대시보드를 만드는 법을 배우고 싶다면 Reporting in SQL 과정도 적합합니다.
DataCamp로 SQL 배우기
courses
courses
courses