
Curso
Manipulação de dados em SQL
4 h
326.1K
Ao trabalhar com SQL, ordenar dados é simples, já que você pode usar ORDER BY para organizar as linhas. Porém, apenas ordenar o resultado não informa a posição de cada linha nessa ordem. É aqui que a classificação entra em cena. Em vez de só ver os dados ordenados, você pode querer atribuir uma posição como 1º, 2º ou 3º a cada linha com base em critérios específicos.
A função RANK() resolve esse problema ao atribuir uma classificação numérica a cada linha conforme a ordem definida. RANK() faz parte das window functions do SQL, que permitem realizar cálculos sobre um conjunto de linhas e ainda retornar resultados por linha.
Neste tutorial, vou mostrar a sintaxe de RANK(), exemplos práticos, explicar como ela lida com empates e comparar com funções semelhantes como DENSE_RANK() e ROW_NUMBER().
Se você está começando em SQL, comece pelo nosso curso Introduction to SQL ou pelo curso Intermediate SQL se você já tem alguma experiência.
A função SQL RANK() é uma window function que atribui uma classificação a cada linha com base em uma ordem especificada. A classificação é totalmente determinada pelo ORDER BY dentro da window function. Assim, cada linha recebe uma posição como 1, 2, 3 e assim por diante, de acordo com a cláusula ORDER BY.
Vale destacar que, ao usar RANK():
A sintaxe básica da função RANK() é:
RANK() OVER (ORDER BY column)Onde:
OVER: Define a janela (conjunto de linhas) na qual a função opera.
ORDER BY: Determina como a classificação é aplicada, como da maior para a menor.
PARTITION BY (opcional): Divide os dados em grupos, classificando as linhas separadamente dentro de cada grupo.
Veja abaixo a sintaxe de RANK() com a cláusula PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)A função SQL RANK() é amplamente suportada nos principais bancos de dados, incluindo PostgreSQL, MySQL (8.0+), Microsoft SQL Server e Oracle Database. A sintaxe é, em geral, consistente entre esses sistemas, por fazer parte do padrão ANSI SQL.
Agora que você entendeu a sintaxe de RANK(), veja um exemplo simples de como ela funciona.
Suponha que você tenha a tabela employees com as informações de salário de cada colaborador.
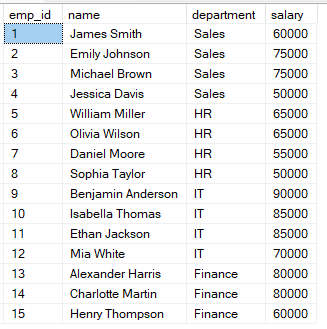
Você pode usar a consulta abaixo para classificar os funcionários de acordo com seus salários.
-- Classificar funcionários por salário
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;Na consulta acima, as linhas são ordenadas do maior salário para o menor, então o maior salário recebe classificação 1. Quando duas linhas têm o mesmo salário, elas recebem a mesma classificação.
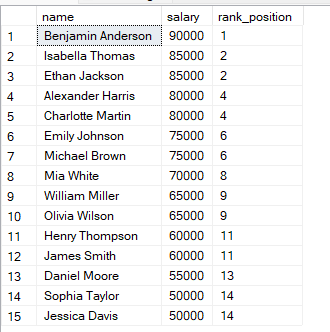
Você vai notar que, se duas linhas tiverem os mesmos valores, elas recebem a mesma classificação.
Em seguida, a próxima posição é pulada. O SQL considera o empate e ignora o próximo valor de classificação.
Recomendo o nosso curso Introduction to SQL Server para aprender mais sobre agrupamento e agregação de dados.
Como vimos, a cláusula PARTITION BY permite aplicar a classificação dentro de grupos, em vez de no conjunto inteiro.
No exemplo abaixo, os funcionários são agrupados por department, e a classificação recomeça dentro de cada departamento. Assim, cada grupo tem sua própria sequência independente.
-- Classificar funcionários dentro de cada departamento
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;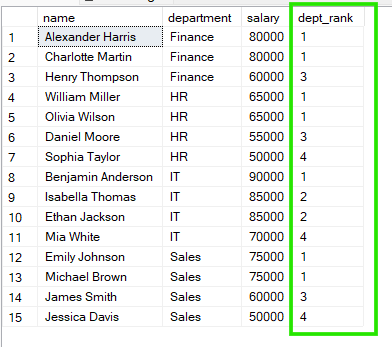
Pelos resultados acima, vemos que em “Sales”, Emily Johnson e Michael Brown compartilham a posição 1, enquanto em “HR”, William Miller e Olivia Wilson também estão empatados em 1.
Ao classificar dados em SQL, você pode usar RANK(), DENSE_RANK() ou ROW_NUMBER(). Essas funções parecem semelhantes, mas se comportam assim:
RANK(): Empates compartilham a mesma posição, portanto surgem lacunas após empates.
DENSE_RANK(): Empates compartilham a mesma posição, mas sem lacunas na sequência.
ROW_NUMBER(): Cada linha recebe um número exclusivo, sem empates, mesmo que os valores sejam iguais.
Para entender melhor essas diferenças, vamos comparar lado a lado usando a consulta abaixo:
-- Comparar RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- permite lacunas após empates
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- sem lacunas, posições consecutivas
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- sempre sequência única
FROM employees;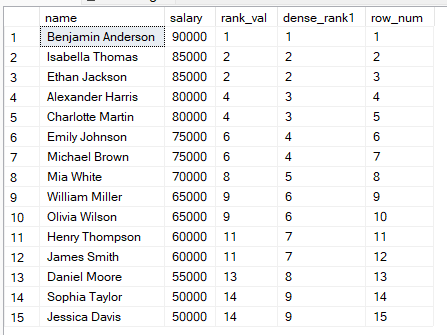
A partir dos resultados, você pode optar por:
Usar RANK() quando a posição importa e lacunas são aceitáveis.
Usar DENSE_RANK() quando você quer uma sequência contínua.
Usar ROW_NUMBER() quando cada linha precisa ter um número único, como em paginação de dados.
A função RANK() é mais útil quando você deseja ordenar dados tratando empates de forma natural. Ela também é importante nos seguintes casos de uso:
Aqui estão alguns erros que já vi ao usar RANK() no SQL, e como evitá-los:
Esquecer o ORDER BY: sem a cláusula ORDER BY, a classificação não tem lógica definida e pode gerar resultados inesperados.
Entender errado o comportamento em empates: como iniciante, você pode esperar 1, 2, 2, 3, mas RANK() cria lacunas (1, 2, 2, 4).
Usar RANK() quando o certo é ROW_NUMBER(): se você precisa de valores sequenciais únicos, ROW_NUMBER() é a melhor escolha.
Não usar PARTITION BY quando necessário: sem particionar, a classificação é aplicada globalmente em vez de dentro dos grupos.
Para manter suas consultas limpas e garantir os resultados esperados, siga estas boas práticas ao usar a função SQL RANK():
Defina sempre uma ordenação clara: seja explícito com a cláusula ORDER BY, como DESC, para evitar classificações ambíguas.
Escolha a função certa para classificar: use RANK(), DENSE_RANK() ou ROW_NUMBER() conforme a forma como você quer tratar empates.
Teste cenários com empates: antes de ir para produção, verifique como seus dados se comportam quando existem valores duplicados.
Combine com filtros: como você não pode usar RANK() diretamente em um WHERE, envolva sua consulta de classificação em uma Subquery ou CTE quando quiser filtrar “Top N”.
RANK() é uma ferramenta útil para comparações ordenadas em SQL, principalmente quando você precisa refletir cenários do mundo real, como valores iguais. Entender como ela trata empates e por que as posições podem se repetir e pular números é essencial para uma análise precisa. Depois que você dominar esse comportamento, saberá quando escolhê-la em conjunto com alternativas como DENSE_RANK() e ROW_NUMBER(), conforme o que melhor se encaixa no seu caso de uso.
Agora que você aprendeu a ranquear dados em SQL, vale conferir nossa trilha de carreira Associate Data Analyst in SQL se você quer se tornar um analista de dados completo e desenvolver as habilidades necessárias. Nosso curso Reporting in SQL também é ideal para aprender a construir dashboards profissionais usando SQL.
Aprenda SQL com a DataCamp
Curso
Curso
Curso
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team