course
Datahantering i SQL
4 timmar
326.3K
När du arbetar med SQL är det enkelt att sortera data eftersom du kan använda ORDER BY för att ordna rader. Men att bara sortera resultat berättar inte vilken position varje rad har i den ordningen. Det är här rankning blir användbart. Istället för att bara titta på sorterad data kanske du vill tilldela en position som 1:a, 2:a eller 3:a till varje rad baserat på specifika kriterier.
Funktionen RANK() löser detta genom att tilldela en numerisk rankning till varje rad enligt den definierade ordningen. RANK() är en del av SQL:s fönsterfunktioner, som låter dig göra beräkningar över en uppsättning rader samtidigt som du fortfarande returnerar individuella rader.
I den här handledningen visar jag syntaxen för RANK(), praktiska exempel, hur den hanterar delade placeringar och hur den skiljer sig från liknande funktioner som DENSE_RANK() och ROW_NUMBER().
Om du är ny på SQL, börja med vår Introduction to SQL-kurs, eller Intermediate SQL om du har viss erfarenhet.
SQL-funktionen RANK() är en fönsterfunktion som tilldelar en rankning till varje rad baserat på en angiven ordning. Rankningen bestäms helt av ORDER BY inuti fönsterfunktionen. Den ger alltså varje rad en position som 1, 2, 3 och så vidare enligt ORDER BY-satsen.
Observera att när du använder RANK():
Den grundläggande syntaxen för funktionen RANK() är:
RANK() OVER (ORDER BY column)Där:
OVER-satsen: Definierar fönstret (mängden rader) som funktionen verkar på.
ORDER BY: Bestämmer hur rankningen tillämpas, till exempel från högst till lägst.
PARTITION BY (valfritt): Delar upp data i grupper och rankar rader separat inom varje grupp.
Nedan är syntaxen för funktionen RANK() med satsen PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)SQL-funktionen RANK() stöds brett i de största databaserna. Dessa inkluderar PostgreSQL, MySQL (8.0+), Microsoft SQL Server och Oracle Database. Syntaxen är i stort sett konsekvent mellan dessa system, eftersom den är en del av den standardiserade ANSI SQL-specifikationen.
Nu när du förstår syntaxen för RANK() vill jag visa ett enkelt exempel på hur den fungerar.
Anta att du har tabellen employees med löneinformation för varje anställd.
Du kan använda följande fråga för att ranka de anställda efter deras löner.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;I frågan ovan ordnas raderna efter lön från högst, så den högsta lönen får rank 1. När två rader har samma lön får de samma rankning.
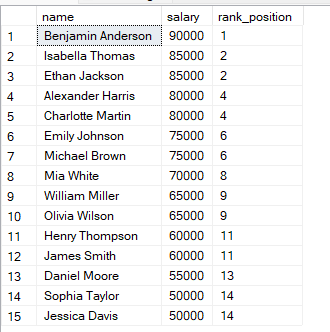
Du märker att om två rader har samma värden får de samma rank.
Därefter hoppas nästa rank över. SQL tar hänsyn till den delade placeringen genom att hoppa över nästa rankvärde.
Jag rekommenderar vår kurs Introduction to SQL Server för att lära dig mer om gruppering och dataaggregering.
Som vi lärde oss tidigare låter satsen PARTITION BY dig tillämpa rankning inom grupper istället för över hela datamängden.
I exemplet nedan grupperas de anställda efter department, och rankningen börjar om inom varje avdelning. Varje grupp har alltså sin egen oberoende rankningssekvens.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;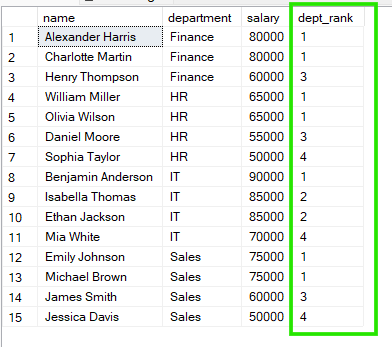
Av resultaten ovan ser vi att i ”Sales” delar både Emily Johnson och Michael Brown på rank 1, medan i ”HR” delar William Miller och Olivia Wilson också på rank 1.
När du rankar data i SQL kan du välja att använda RANK(), DENSE_RANK() eller ROW_NUMBER(). Dessa funktioner kan se lika ut, men beter sig så här:
RANK(): Delade placeringar får samma rank, därför uppstår glapp efter delningar.
DENSE_RANK(): Delade placeringar får samma rank, därför inga glapp i rankningen.
ROW_NUMBER(): Varje rad får ett unikt nummer utan delade placeringar, även om värdena är lika.
För att bättre förstå dessa skillnader gör vi en jämförelse sida vid sida med frågan nedan:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;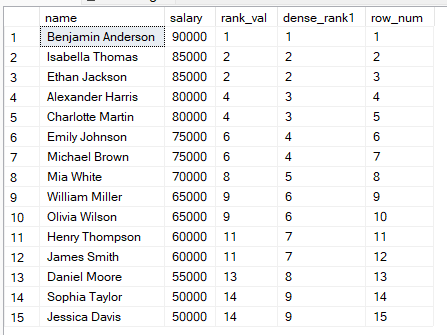
Av resultaten ovan kan du välja att:
Använda RANK() när positionen spelar roll och glapp är acceptabla.
Använda DENSE_RANK() när du vill ha en sammanhängande rankning.
Använda ROW_NUMBER() när varje rad måste ha ett unikt nummer, till exempel vid paginering av data.
SQL-funktionen RANK() är mest användbar när du vill ordna data och samtidigt hantera delade placeringar på ett naturligt sätt. Jag tycker också att den är viktig för följande användningsfall:
Här är några misstag jag har stött på när jag använder SQL-funktionen RANK(), och hur du kan undvika dem:
Glömma ORDER BY: Utan satsen ORDER BY saknar rankningen definierad logik och kan ge oväntade resultat.
Missförstå hur delade placeringar fungerar: Som nybörjare kan du förvänta dig 1, 2, 2, 3, men RANK() ger glapp (1, 2, 2, 4) i rankningen.
Använda RANK() när ROW_NUMBER() behövs: Om du behöver unika sekventiella värden är ROW_NUMBER() ett bättre val.
Inte använda PARTITION BY när det behövs: Utan partitionering tillämpas rankningen globalt istället för inom grupper.
För att hålla dina frågor rena och säkerställa att du får förväntade resultat rekommenderar jag att du följer dessa bästa metoder när du använder SQL-funktionen RANK():
Definiera alltid tydlig sortering: Var explicit med ORDER BY-satsen, som DESC, för att undvika tvetydiga rankningar.
Välj rätt rankningsfunktion: Använd RANK(), DENSE_RANK() eller ROW_NUMBER() beroende på hur du vill hantera delade placeringar.
Testa scenarier med delade värden: Innan du går i produktion, verifiera hur dina data beter sig när det finns dubbletter.
Kombinera med filtrering: Eftersom du inte kan använda RANK() direkt i en WHERE-sats måste du kapsla in din rankningsfråga i en underfråga eller en CTE när du vill filtrera ”Top N”.
RANK() är ett användbart verktyg för att göra ordnade jämförelser i SQL, särskilt när du behöver resultat som speglar verkliga scenarier som lika värden. Att förstå hur den hanterar delade placeringar och varför rankningar kan upprepas och hoppa över nummer är viktigt för korrekt analys. När du behärskar detta beteende vet du när du ska välja den framför alternativ som DENSE_RANK() och ROW_NUMBER(), beroende på vad som passar bäst för ditt specifika användningsfall.
Nu när du har lärt dig hur man rankar data i SQL rekommenderar jag att du tar en titt på vår Associate Data Analyst in SQL-karriärspår om du vill bli en skicklig dataanalytiker och lära dig nödvändiga färdigheter. Vår kurs Reporting in SQL är också lämplig om du vill lära dig att bygga professionella instrumentpaneler med SQL.
Lär dig SQL med DataCamp
course
course
course