
Courses
Xử lý dữ liệu trong SQL
4 giờ
326.1K
Khi làm việc với SQL, việc sắp xếp dữ liệu khá đơn giản vì bạn có thể dễ dàng dùng ORDER BY để sắp xếp các hàng. Tuy nhiên, chỉ sắp xếp kết quả thì không cho bạn biết vị trí của từng hàng trong thứ tự đó. Đây là lúc xếp hạng trở nên hữu ích. Thay vì chỉ xem dữ liệu đã sắp, bạn có thể muốn gán vị trí như 1, 2, hoặc 3 cho mỗi hàng dựa trên tiêu chí cụ thể.
Hàm RANK() giải quyết vấn đề này bằng cách gán một thứ hạng dạng số cho mỗi hàng theo thứ tự đã xác định. RANK() là một phần của các hàm cửa sổ (window functions) trong SQL, cho phép bạn thực hiện tính toán trên một tập các hàng nhưng vẫn trả về kết quả cho từng hàng riêng lẻ.
Trong hướng dẫn này, tôi sẽ giới thiệu cú pháp của RANK(), các ví dụ thực tế, cách hàm xử lý đồng hạng, và so sánh với các hàm tương tự như DENSE_RANK() và ROW_NUMBER().
Nếu bạn mới học SQL, hãy bắt đầu với khóa học Giới thiệu về SQL, hoặc khóa SQL Trung cấp nếu bạn đã có chút kinh nghiệm.
Hàm SQL RANK() là một hàm cửa sổ gán thứ hạng cho mỗi hàng dựa trên một thứ tự xác định. Xếp hạng hoàn toàn do ORDER BY bên trong hàm cửa sổ quyết định. Do đó, nó gán cho mỗi hàng một vị trí như 1, 2, 3, v.v., theo mệnh đề ORDER BY.
Bạn cần lưu ý rằng khi dùng RANK():
Cú pháp cơ bản của hàm RANK() là:
RANK() OVER (ORDER BY column)Trong đó:
OVER: Xác định cửa sổ (tập các hàng) mà hàm sẽ hoạt động.
ORDER BY: Quy định cách áp dụng xếp hạng, chẳng hạn từ cao xuống thấp.
PARTITION BY (tùy chọn): Chia dữ liệu thành các nhóm, xếp hạng riêng trong từng nhóm.
Dưới đây là cú pháp của hàm RANK() với mệnh đề PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)Hàm SQL RANK() được hỗ trợ rộng rãi trên các hệ quản trị cơ sở dữ liệu lớn, bao gồm PostgreSQL, MySQL (8.0+), Microsoft SQL Server và Oracle Database. Cú pháp nhìn chung nhất quán giữa các hệ này vì nó là một phần của tiêu chuẩn ANSI SQL.
Giờ bạn đã nắm cú pháp của RANK(), hãy xem một ví dụ đơn giản về cách nó hoạt động.
Giả sử bạn có bảng employees với thông tin lương của từng nhân viên.
Bạn có thể dùng truy vấn sau để xếp hạng nhân viên theo mức lương.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;Trong truy vấn trên, các hàng được sắp theo lương từ cao xuống thấp, nên mức lương cao nhất nhận hạng 1. Khi hai hàng có cùng mức lương, chúng nhận cùng một thứ hạng.
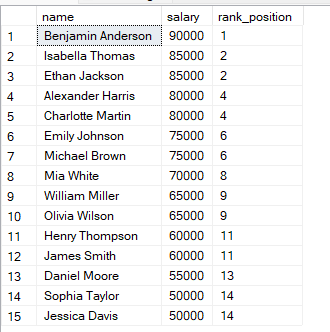
Bạn sẽ thấy rằng nếu hai hàng có cùng giá trị, chúng sẽ nhận cùng hạng.
Sau đó hạng tiếp theo sẽ bị bỏ qua. SQL tính đến trường hợp đồng hạng bằng cách bỏ qua giá trị hạng kế tiếp.
Tôi khuyến nghị bạn học khóa Giới thiệu về SQL Server để tìm hiểu thêm về nhóm dữ liệu và tổng hợp dữ liệu.
Như đã đề cập, mệnh đề PARTITION BY cho phép bạn áp dụng xếp hạng trong từng nhóm thay vì trên toàn bộ tập dữ liệu.
Trong ví dụ dưới đây, nhân viên được nhóm theo department, và việc xếp hạng bắt đầu lại trong mỗi phòng ban. Do đó, mỗi nhóm có dãy xếp hạng độc lập của riêng mình.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;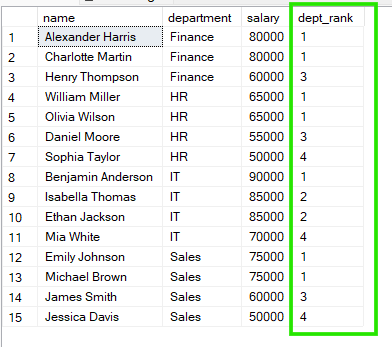
Từ kết quả trên, ta thấy ở “Sales”, cả Emily Johnson và Michael Brown cùng hạng 1, trong khi ở “HR”, William Miller và Olivia Wilson cũng cùng hạng 1.
Khi xếp hạng dữ liệu trong SQL, bạn có thể chọn dùng RANK(), DENSE_RANK() hoặc ROW_NUMBER(). Các hàm này trông giống nhau nhưng hành vi như sau:
RANK(): Đồng hạng sẽ cùng thứ hạng, do đó xuất hiện khoảng trống sau đồng hạng.
DENSE_RANK(): Đồng hạng sẽ cùng thứ hạng, không có khoảng trống trong dãy.
ROW_NUMBER(): Mỗi hàng nhận một số duy nhất, không có đồng hạng, ngay cả khi giá trị bằng nhau.
Để hiểu rõ hơn sự khác biệt, hãy so sánh song song bằng truy vấn dưới đây:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;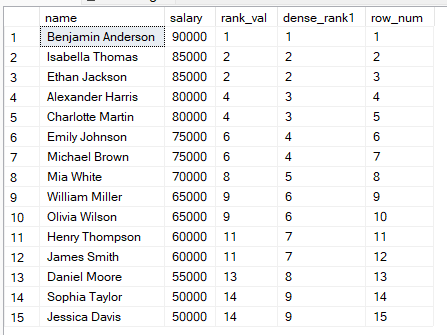
Từ các kết quả trên, bạn có thể lựa chọn:
Dùng RANK() khi vị trí có ý nghĩa và chấp nhận có khoảng trống.
Dùng DENSE_RANK() khi bạn muốn dãy xếp hạng liên tục.
Dùng ROW_NUMBER() khi mỗi hàng phải có số thứ tự duy nhất, ví dụ trong phân trang dữ liệu.
Hàm RANK() đặc biệt hữu ích khi bạn muốn sắp xếp dữ liệu đồng thời xử lý đồng hạng một cách tự nhiên. Tôi cũng thấy nó quan trọng trong các trường hợp sau:
Dưới đây là một số lỗi tôi từng gặp khi dùng hàm SQL RANK() và cách bạn có thể tránh:
Quên ORDER BY: Thiếu mệnh đề ORDER BY sẽ khiến xếp hạng không có logic xác định và có thể trả về kết quả ngoài mong đợi.
Hiểu sai hành vi đồng hạng: Là người mới, bạn có thể kỳ vọng 1, 2, 2, 3, nhưng RANK() tạo khoảng trống (1, 2, 2, 4) trong thứ hạng.
Dùng RANK() khi cần ROW_NUMBER(): Nếu bạn cần dãy số tuần tự duy nhất, ROW_NUMBER() là lựa chọn phù hợp hơn.
Không dùng PARTITION BY khi cần: Nếu không phân vùng, việc xếp hạng sẽ áp dụng trên toàn cục thay vì trong từng nhóm.
Để giữ cho truy vấn gọn gàng và đảm bảo kết quả như mong đợi, tôi khuyên bạn nên tuân theo các thực hành tốt sau khi dùng hàm SQL RANK():
Luôn xác định thứ tự rõ ràng: Chỉ rõ mệnh đề ORDER BY, như DESC, để tránh xếp hạng mơ hồ.
Chọn hàm xếp hạng phù hợp: Dùng RANK(), DENSE_RANK() hoặc ROW_NUMBER() tùy theo cách bạn muốn xử lý đồng hạng.
Kiểm thử kịch bản đồng hạng: Trước khi đưa vào sản xuất, hãy kiểm tra hành vi dữ liệu khi có giá trị trùng lặp.
Kết hợp với lọc dữ liệu: Vì bạn không thể dùng RANK() trực tiếp trong mệnh đề WHERE, bạn cần bao truy vấn xếp hạng trong một Truy vấn lồng hoặc CTE khi bạn muốn lọc “Top N”.
RANK() là công cụ hữu ích để so sánh có thứ tự trong SQL, đặc biệt khi bạn cần kết quả phản ánh các tình huống thực tế như giá trị bằng nhau. Hiểu cách nó xử lý đồng hạng và vì sao thứ hạng có thể lặp lại và bỏ qua số là rất quan trọng để phân tích chính xác. Khi nắm vững hành vi này, bạn sẽ biết khi nào nên chọn nó cùng với các lựa chọn thay thế như DENSE_RANK() và ROW_NUMBER(), tùy theo trường hợp sử dụng cụ thể.
Giờ đây bạn đã biết cách xếp hạng dữ liệu trong SQL, tôi khuyến nghị bạn xem lộ trình nghề nghiệp Associate Data Analyst in SQL nếu bạn quan tâm trở thành một nhà phân tích dữ liệu thành thạo để học các kỹ năng cần thiết. Khóa Lập báo cáo trong SQL cũng phù hợp nếu bạn muốn học cách xây dựng dashboard chuyên nghiệp bằng SQL.
Học SQL với DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút