
Kurs
Datenbearbeitung in SQL
4 Std.
326.1K
Beim Arbeiten mit SQL ist das Sortieren von Daten einfach, denn mit ORDER BY kannst du Zeilen schnell anordnen. Allein die Sortierung verrät dir jedoch nicht die Position jeder Zeile innerhalb dieser Reihenfolge. Genau hier hilft das Ranking. Statt nur sortierte Daten anzusehen, willst du Zeilen oft anhand bestimmter Kriterien mit Positionen wie 1., 2. oder 3. versehen.
Die Funktion RANK() löst dieses Problem, indem sie jeder Zeile basierend auf der definierten Ordnung einen numerischen Rang zuweist. RANK() gehört zu den SQL-Fensterfunktionen, mit denen du Berechnungen über einen Zeilensatz hinweg durchführen kannst und trotzdem einzelne Zeilen zurückerhältst.
In diesem Tutorial zeige ich dir die Syntax von RANK(), praktische Beispiele, wie Gleichstände gehandhabt werden und wie sich die Funktion von DENSE_RANK() und ROW_NUMBER() unterscheidet.
Wenn du neu in SQL bist, starte mit unserem Introduction to SQL Kurs oder dem Intermediate SQL Kurs, wenn du bereits etwas Erfahrung hast.
Die SQL-Funktion RANK() ist eine Fensterfunktion, die jeder Zeile basierend auf einer festgelegten Ordnung einen Rang zuweist. Das Ranking wird vollständig durch das ORDER BY innerhalb der Fensterfunktion bestimmt. So erhält jede Zeile gemäß der ORDER BY-Klausel eine Position wie 1, 2, 3 usw.
Beachte bei der Verwendung von RANK():
Die Grundsyntax von RANK() ist:
RANK() OVER (ORDER BY column)Dabei gilt:
OVER-Klausel: Definiert das Fenster (den Zeilensatz), auf den die Funktion angewendet wird.
ORDER BY: Legt fest, wie das Ranking vergeben wird, z. B. von hoch nach niedrig.
PARTITION BY (optional): Teilt die Daten in Gruppen und bewertet Zeilen innerhalb jeder Gruppe separat.
Unten siehst du die Syntax von RANK() mit PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)Die SQL-Funktion RANK() wird von allen großen Datenbanksystemen unterstützt, darunter PostgreSQL, MySQL (8.0+), Microsoft SQL Server und Oracle Database. Die Syntax ist weitgehend konsistent, da sie Teil des ANSI-SQL-Standards ist.
Nachdem du die Syntax von RANK() kennst, zeige ich dir ein einfaches Beispiel, wie die Funktion arbeitet.
Angenommen, du hast eine Tabelle employees mit den Gehaltsinformationen der Mitarbeitenden.
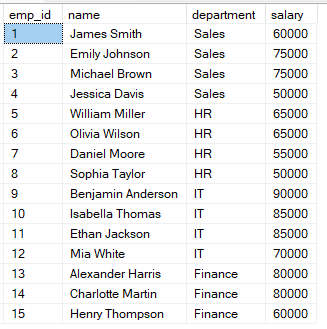
Mit der folgenden Abfrage bewertest du die Mitarbeitenden nach ihrem Gehalt.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;In dieser Abfrage werden die Zeilen nach Gehalt absteigend sortiert, das höchste Gehalt erhält also Rang 1. Haben zwei Zeilen dasselbe Gehalt, bekommen sie denselben Rang.
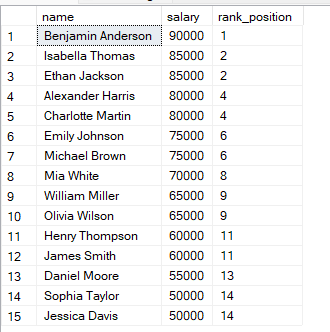
Du siehst: Haben zwei Zeilen denselben Wert, erhalten sie denselben Rang.
Der nächste Rang wird dann übersprungen. SQL berücksichtigt den Gleichstand, indem der folgende Rang ausgelassen wird.
Ich empfehle dir unseren Kurs Introduction to SQL Server, um mehr über Gruppierung und Datenaggregation zu lernen.
Wie bereits gelernt, ermöglicht PARTITION BY, Rankings innerhalb von Gruppen statt über den gesamten Datensatz zu berechnen.
Im folgenden Beispiel werden Mitarbeitende nach department gruppiert, und die Rangfolge beginnt in jeder Abteilung neu. Jede Gruppe hat also ihre eigene unabhängige Rangliste.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;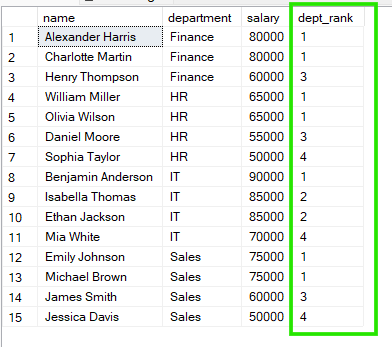
An den Ergebnissen siehst du: In „Sales“ teilen sich Emily Johnson und Michael Brown Rang 1, und in „HR“ gilt das Gleiche für William Miller und Olivia Wilson.
Beim Ranking in SQL kannst du RANK(), DENSE_RANK() oder ROW_NUMBER() verwenden. Die Funktionen ähneln sich, verhalten sich aber wie folgt:
RANK(): Gleichstände teilen sich denselben Rang, dadurch entstehen Lücken nach Gleichständen.
DENSE_RANK(): Gleichstände teilen sich denselben Rang, es gibt jedoch keine Lücken in der Reihenfolge.
ROW_NUMBER(): Jede Zeile erhält eine eindeutige Nummer ohne Gleichstände, auch wenn Werte identisch sind.
Um die Unterschiede greifbar zu machen, vergleichen wir sie nebeneinander mit dieser Abfrage:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;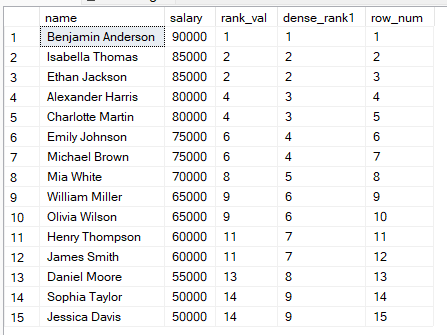
Aus den Ergebnissen lässt sich ableiten:
Nutze RANK(), wenn die Position zählt und Lücken akzeptabel sind.
Nutze DENSE_RANK(), wenn du eine durchgehende Rangfolge ohne Lücken willst.
Nutze ROW_NUMBER(), wenn jede Zeile eine eindeutige Nummer braucht, z. B. für Paginierung.
Die Funktion RANK() ist besonders hilfreich, wenn du Daten ordnen und Gleichstände natürlich abbilden willst. Außerdem ist sie nützlich für folgende Anwendungsfälle:
Hier sind typische Fehler bei der Nutzung von RANK() und wie du sie vermeidest:
ORDER BY vergessen: Ohne ORDER BY gibt es keine definierte Logik, und die Ergebnisse können unerwartet sein.
Gleichstände falsch einschätzen: Als Einsteiger erwartest du vielleicht 1, 2, 2, 3 – RANK() erzeugt jedoch Lücken (1, 2, 2, 4).
RANK() verwenden, obwohl ROW_NUMBER() nötig ist: Wenn du eindeutige fortlaufende Werte brauchst, ist ROW_NUMBER() die bessere Wahl.
PARTITION BY nicht genutzt: Ohne Partitionierung wird global statt gruppenweise bewertet.
Damit deine Abfragen klar bleiben und die erwarteten Ergebnisse liefern, empfehle ich dir diese Best Practices für die Nutzung von RANK():
Immer eindeutige Sortierung angeben: Sei beim ORDER BY explizit, z. B. mit DESC, um zweideutige Rankings zu vermeiden.
Die passende Ranking-Funktion wählen: Nutze RANK(), DENSE_RANK() oder ROW_NUMBER() je nachdem, wie du Gleichstände behandeln willst.
Gleichstand-Szenarien testen: Prüfe vor dem Go-live, wie sich deine Daten bei Duplikaten verhalten.
Mit Filtern kombinieren: Da du RANK() nicht direkt in einer WHERE-Klausel verwenden kannst, kapsle die Ranking-Abfrage in einer Subquery oder einem CTE ein, wenn du „Top N“ filtern willst.
RANK() ist ein nützliches Werkzeug für geordnete Vergleiche in SQL – besonders, wenn Ergebnisse reale Szenarien wie gleiche Werte widerspiegeln sollen. Zu verstehen, wie Gleichstände behandelt werden und warum Ränge sich wiederholen oder Zahlen übersprungen werden, ist entscheidend für eine saubere Analyse. Beherrschst du dieses Verhalten, weißt du auch, wann du Alternativen wie DENSE_RANK() und ROW_NUMBER() einsetzen solltest – passend zu deinem Use Case.
Nachdem du nun weißt, wie man Daten in SQL ranked, empfehle ich dir unseren Associate Data Analyst in SQL Lernpfad, wenn du als Datenanalyst:in durchstarten willst. Unser Kurs Reporting in SQL ist ebenfalls ideal, wenn du lernen willst, wie man professionelle Dashboards mit SQL erstellt.
Lerne SQL mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Neetika Khandelwal
Tutorial
Abid Ali Awan
