Courses
การจัดการข้อมูลใน SQL
4 ชม.
326.3K
เมื่อทำงานกับ SQL การจัดเรียงข้อมูลทำได้ไม่ยากเพราะสามารถใช้ ORDER BY เพื่อเรียงแถวได้อย่างง่ายดาย อย่างไรก็ตาม การเรียงผลลัพธ์เพียงอย่างเดียวไม่ได้บอกตำแหน่งของแต่ละแถวภายในลำดับนั้น ซึ่งตรงนี้เองที่การจัดอันดับช่วยได้ แทนที่จะดูข้อมูลที่ถูกเรียงเฉย ๆ อาจต้องการกำหนดตำแหน่งอย่างที่ 1 ที่ 2 หรือที่ 3 ให้แต่ละแถวตามเกณฑ์ที่กำหนด
ฟังก์ชัน RANK() แก้ปัญหานี้โดยกำหนดลำดับเชิงตัวเลขให้แต่ละแถวตามลำดับที่กำหนดไว้ RANK() เป็นส่วนหนึ่งของฟังก์ชันหน้าต่าง (window functions) ของ SQL ที่ช่วยให้คำนวณผ่านชุดของแถวพร้อมทั้งยังคืนผลลัพธ์เป็นรายแถวได้
ในบทแนะนำนี้ ฉจะแสดงไวยากรณ์ของ RANK() ตัวอย่างการใช้งานจริง อธิบายวิธีจัดการกรณีคะแนนเท่ากัน และเปรียบเทียบกับฟังก์ชันที่คล้ายกันอย่าง DENSE_RANK() และ ROW_NUMBER()
หากเป็นมือใหม่ใน SQL เริ่มจากคอร์ส Introduction to SQL หรือคอร์ส Intermediate SQL หากมีประสบการณ์มาบ้างแล้ว
ฟังก์ชัน SQL RANK() เป็น window function ที่กำหนดอันดับให้แต่ละแถวตามลำดับที่ระบุ การจัดอันดับถูกกำหนดโดย ORDER BY ภายในฟังก์ชันหน้าต่างโดยสมบูรณ์ ดังนั้นจึงให้ตำแหน่ง 1, 2, 3 เป็นต้น แก่แต่ละแถวตามเงื่อนไข ORDER BY
ควรสังเกตว่าเมื่อใช้ RANK():
ไวยากรณ์พื้นฐานของฟังก์ชัน RANK() คือ:
RANK() OVER (ORDER BY column)โดย:
OVER: กำหนดหน้าต่าง (ชุดของแถว) ที่ฟังก์ชันจะทำงาน
ORDER BY: กำหนดวิธีการจัดอันดับ เช่น จากมากไปน้อย
PARTITION BY (ไม่บังคับ): แบ่งข้อมูลออกเป็นกลุ่ม ๆ และจัดอันดับแยกกันในแต่ละกลุ่ม
ด้านล่างเป็นไวยากรณ์ของฟังก์ชัน RANK() ที่ใช้ร่วมกับ PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)ฟังก์ชัน SQL RANK() รองรับอย่างกว้างขวางในฐานข้อมูลหลัก ๆ ได้แก่ PostgreSQL, MySQL (8.0+), Microsoft SQL Server และ Oracle Database ไวยากรณ์ส่วนใหญ่สอดคล้องกันระหว่างระบบเหล่านี้ เนื่องจากเป็นส่วนหนึ่งของมาตรฐาน ANSI SQL
เมื่อเข้าใจไวยากรณ์ของ RANK() แล้ว มาดูตัวอย่างง่าย ๆ ของการทำงานกัน
สมมติว่ามีตาราง employees ที่เก็บข้อมูลเงินเดือนของแต่ละพนักงาน
สามารถใช้คิวรีด้านล่างเพื่อจัดอันดับพนักงานตามเงินเดือนได้
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;ในคิวรีข้างต้น แถวถูกเรียงตามเงินเดือนจากมากไปน้อย ดังนั้นเงินเดือนสูงสุดจะได้อันดับ 1 เมื่อสองแถวมีเงินเดือนเท่ากัน ทั้งคู่จะได้รับอันดับเดียวกัน
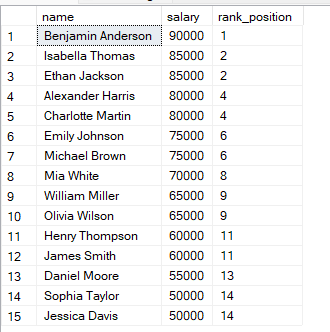
จะสังเกตได้ว่าหากสองแถวมีค่าเท่ากัน จะได้รับอันดับเดียวกัน
จากนั้นอันดับถัดไปจะถูกข้าม SQL จะนับกรณีเสมอโดยข้ามค่าอันดับถัดไป
ขอแนะนำคอร์ส Introduction to SQL Server เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับการจัดกลุ่มและการรวมข้อมูล
ดังที่ได้เรียนรู้ไปแล้ว PARTITION BY ทำให้สามารถจัดอันดับภายในกลุ่ม แทนที่จะจัดอันดับทั่วทั้งชุดข้อมูล
ในตัวอย่างด้านล่าง พนักงานถูกจัดกลุ่มตาม department และการจัดอันดับจะเริ่มใหม่ภายในแต่ละแผนก ดังนั้นแต่ละกลุ่มจะมีลำดับอันดับเป็นของตนเอง
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;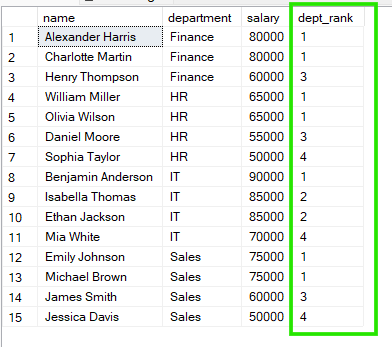
จากผลลัพธ์ด้านบนจะเห็นว่าใน “Sales” ทั้ง Emily Johnson และ Michael Brown มีอันดับ 1 ร่วมกัน ขณะที่ใน “HR” William Miller และ Olivia Wilson ก็มีอันดับ 1 ร่วมกันเช่นกัน
เมื่อต้องจัดอันดับข้อมูลใน SQL สามารถเลือกใช้ RANK(), DENSE_RANK() หรือ ROW_NUMBER() ฟังก์ชันเหล่านี้ดูคล้ายกันแต่มีพฤติกรรมดังนี้:
RANK(): กรณีเสมอจะใช้อันดับเดียวกัน ดังนั้นจะเกิดช่องว่างหลังการเสมอ
DENSE_RANK(): กรณีเสมอใช้อันดับเดียวกัน และไม่มีช่องว่างในลำดับอันดับ
ROW_NUMBER(): ทุกแถวจะได้หมายเลขไม่ซ้ำกันเสมอ แม้ว่าค่าจะเท่ากัน
เพื่อให้เข้าใจความแตกต่างเหล่านี้มากขึ้น มาลองเปรียบเทียบแบบเคียงข้างกันด้วยคิวรีด้านล่าง:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;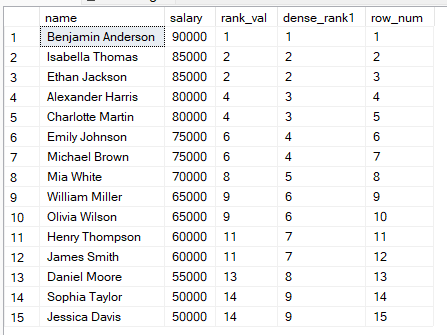
จากผลลัพธ์ข้างต้น อาจเลือกได้ว่า:
ใช้ RANK() เมื่อตำแหน่งมีความสำคัญ และยอมรับการมีช่องว่างได้
ใช้ DENSE_RANK() เมื่ออยากได้ลำดับที่ต่อเนื่องไม่ขาดช่วง
ใช้ ROW_NUMBER() เมื่อทุกแต้ต้องมีหมายเลขเฉพาะ เช่น การแบ่งหน้า (pagination) ของข้อมูล
ฟังก์ชัน SQL RANK() มีประโยชน์มากเมื่ออยากจัดเรียงข้อมูลพร้อมจัดการกรณีเสมออย่างเป็นธรรมชาติ นอกจากนี้ยังสำคัญสำหรับกรณีใช้งานต่อไปนี้:
นี่คือข้อผิดพลาดที่เคยพบเมื่อใช้ฟังก์ชัน SQL RANK() และวิธีหลีกเลี่ยง:
ลืมใส่ ORDER BY: หากไม่มี ORDER BY การจัดอันดับจะไม่มีตรรกะที่ชัดเจนและอาจให้ผลลัพธ์ที่ไม่คาดคิด
เข้าใจพฤติกรรมกรณีเสมอผิด: สำหรับผู้เริ่มต้นอาจคาดหวัง 1, 2, 2, 3 แต่ RANK() จะมีช่องว่าง (1, 2, 2, 4) ในอันดับ
ใช้ RANK() แทน ROW_NUMBER() ที่จำเป็น: หากต้องการหมายเลขลำดับที่ไม่ซ้ำกัน ROW_NUMBER() จะเหมาะสมกว่า
ไม่ใช้ PARTITION BY เมื่อควรใช้: หากไม่แบ่งพาร์ทิชัน การจัดอันดับจะถูกนำไปใช้ในภาพรวมทั้งชุดข้อมูล แทนที่จะเป็นภายในแต่ละกลุ่ม
เพื่อให้คิวรีสะอาดและได้ผลลัพธ์ตามคาด แนะนำให้ปฏิบัติตามแนวทางต่อไปนี้เมื่อใช้ฟังก์ชัน SQL RANK():
กำหนดการเรียงอย่างชัดเจนเสมอ: ระบุ ORDER BY ให้ชัด เช่น DESC เพื่อเลี่ยงการจัดอันดับที่คลุมเครือ
เลือกฟังก์ชันจัดอันดับให้ถูกต้อง: ใช้ RANK(), DENSE_RANK() หรือ ROW_NUMBER() ตามวิธีที่ต้องการจัดการกรณีเสมอ
ทดสอบกรณีเสมอ: ก่อนขึ้นโปรดักชัน ให้ตรวจสอบว่าข้อมูลทำงานอย่างไรเมื่อมีค่าที่ซ้ำกัน
ใช้ร่วมกับการกรองผลลัพธ์: เนื่องจากไม่สามารถใช้ RANK() ใน WHERE ได้โดยตรง จึงต้องครอบคิวรีจัดอันดับไว้ใน Subquery หรือ CTE เมื่ออยากกรอง “Top N”
RANK() เป็นเครื่องมือที่มีประโยชน์สำหรับการเปรียบเทียบแบบมีลำดับใน SQL โดยเฉพาะเมื่อจำเป็นต้องสะท้อนสถานการณ์จริงอย่างค่าที่เท่ากัน การเข้าใจวิธีจัดการกรณีเสมอ และเหตุผลที่อันดับอาจซ้ำและข้ามตัวเลขได้ เป็นสิ่งสำคัญต่อการวิเคราะห์ที่แม่นยำ เมื่อเชี่ยวชาญพฤติกรรมนี้แล้ว จะรู้ว่าเมื่อใดควรเลือกใช้ควบคู่กับทางเลือกอย่าง DENSE_RANK() และ ROW_NUMBER() ตามกรณีใช้งานที่เหมาะสม
เมื่อเรียนรู้วิธีจัดอันดับข้อมูลใน SQL แล้ว แนะนำให้ดู เส้นทางอาชีพ Associate Data Analyst in SQL หากสนใจพัฒนาสู่การเป็นนักวิเคราะห์ข้อมูลมืออาชีพเพื่อเรียนรู้ทักษะที่จำเป็น และคอร์ส Reporting in SQL ก็เหมาะสำหรับการเรียนรู้การสร้างแดชบอร์ดระดับมืออาชีพด้วย SQL
เรียนรู้ SQL กับ DataCamp
Courses
Courses
Courses