
Corso
Manipolazione dei dati in SQL
4 h
325.8K
Quando lavori con SQL, ordinare i dati è semplice perché puoi usare facilmente ORDER BY per disporre le righe. Tuttavia, limitarsi a ordinare i risultati non ti dice la posizione di ciascuna riga all’interno di quell’ordine. Qui entra in gioco il ranking. Invece di visualizzare solo i dati ordinati, potresti voler assegnare a ogni riga una posizione come 1°, 2° o 3° in base a criteri specifici.
La funzione RANK() risolve questo problema assegnando un rango numerico a ciascuna riga secondo l’ordine definito. RANK() fa parte delle funzioni finestra di SQL, che ti permettono di eseguire calcoli su un insieme di righe restituendo comunque risultati per singola riga.
In questo tutorial ti mostrerò la sintassi di RANK(), esempi pratici, come gestisce i pari merito e come si confronta con funzioni simili come DENSE_RANK() e ROW_NUMBER().
Se sei alle prime armi con SQL, inizia dal nostro corso Introduzione a SQL, oppure al corso SQL intermedio se hai già un po’ di esperienza.
La funzione SQL RANK() è una funzione finestra che assegna un rango a ciascuna riga in base a un ordine specificato. Il ranking è determinato interamente dall’ORDER BY all’interno della funzione finestra. Quindi attribuisce a ogni riga una posizione come 1, 2, 3 e così via, secondo la clausola ORDER BY.
Tieni presente che quando usi RANK():
La sintassi di base della funzione RANK() è:
RANK() OVER (ORDER BY column)Dove:
OVER clause: definisce la finestra (insieme di righe) su cui opera la funzione.
ORDER BY: determina come viene applicato il ranking, ad esempio dal più alto al più basso.
PARTITION BY (opzionale): suddivide i dati in gruppi, classificando le righe separatamente all’interno di ciascun gruppo.
Di seguito la sintassi della funzione RANK() con la clausola PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)La funzione SQL RANK() è ampiamente supportata nei principali database, tra cui PostgreSQL, MySQL (8.0+), Microsoft SQL Server e Oracle Database. La sintassi è perlopiù coerente tra questi sistemi, poiché fa parte della specifica standard ANSI SQL.
Ora che hai capito la sintassi della funzione RANK(), ti mostro un semplice esempio di come funziona.
Supponi di avere la tabella employees con le informazioni sugli stipendi di ciascun dipendente.
Puoi usare la seguente query per classificare i dipendenti in base ai loro stipendi.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;Nella query sopra, le righe sono ordinate per stipendio dal più alto, quindi lo stipendio più alto ottiene il rango 1. Quando due righe hanno lo stesso stipendio, ricevono lo stesso rango.
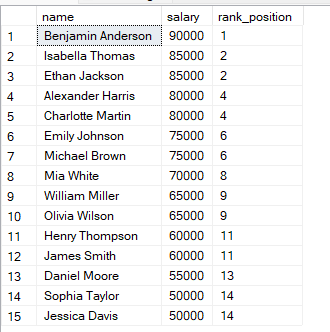
Noterai che se due righe hanno gli stessi valori, ricevono lo stesso rango.
Poi il rango successivo viene saltato. SQL tiene conto del pari merito saltando il valore di rango seguente.
Ti consiglio il nostro corso Introduzione a SQL Server per approfondire il raggruppamento e l’aggregazione dei dati.
Come abbiamo visto, la clausola PARTITION BY ti permette di applicare il ranking all’interno di gruppi invece che sull’intero dataset.
Nell’esempio seguente, i dipendenti sono raggruppati per department e il ranking riparte da zero all’interno di ciascun reparto. Pertanto, ogni gruppo ha la propria sequenza di ranking indipendente.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;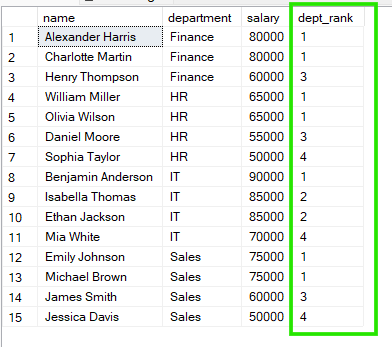
Dai risultati sopra, vediamo che in "Sales" sia Emily Johnson sia Michael Brown hanno il rango 1, mentre in "HR" anche William Miller e Olivia Wilson condividono il rango 1.
Quando classifichi i dati in SQL, puoi scegliere tra RANK(), DENSE_RANK() o ROW_NUMBER(). Queste funzioni possono sembrare simili, ma si comportano così:
RANK(): i pari merito condividono lo stesso rango, quindi dopo i pari merito compaiono salti.
DENSE_RANK(): i pari merito condividono lo stesso rango, quindi non ci sono salti nella classifica.
ROW_NUMBER(): ogni riga ottiene un numero univoco senza pari merito, anche se i valori sono uguali.
Per capire meglio queste differenze, facciamo un confronto affiancato usando la query seguente:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;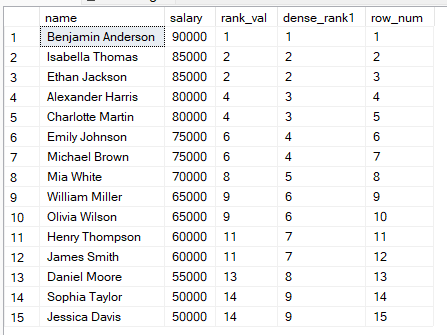
Dai risultati sopra, puoi scegliere di:
Usare RANK() quando la posizione conta e i salti sono accettabili.
Usare DENSE_RANK() quando vuoi una classifica continua.
Usare ROW_NUMBER() quando ogni riga deve avere un numero univoco, ad esempio per la paginazione dei dati.
La funzione SQL RANK() è particolarmente utile quando vuoi ordinare i dati gestendo in modo naturale i pari merito. La trovo importante anche per i seguenti casi d’uso:
Ecco alcuni errori che ho riscontrato usando la funzione SQL RANK() e come evitarli:
Dimenticare ORDER BY: senza la clausola ORDER BY, il ranking non ha una logica definita e può restituire risultati inattesi.
Fraintendere il comportamento dei pari merito: da principiante potresti aspettarti 1, 2, 2, 3, ma RANK() produce salti (1, 2, 2, 4) nei ranghi.
Usare RANK() quando serve ROW_NUMBER(): se ti servono valori sequenziali univoci, ROW_NUMBER() è la scelta migliore.
Non usare PARTITION BY quando serve: senza partizionamento, il ranking viene applicato globalmente invece che all’interno dei gruppi.
Per mantenere le query pulite e ottenere i risultati attesi, ti consiglio di seguire queste best practice quando usi la funzione SQL RANK():
Definisci sempre un ordinamento chiaro: sii esplicito con la clausola ORDER BY, ad esempio DESC, per evitare classifiche ambigue.
Scegli la funzione di ranking corretta: usa RANK(), DENSE_RANK() o ROW_NUMBER() in base a come vuoi gestire i pari merito.
Metti alla prova gli scenari di pari merito: prima di andare in produzione, verifica come si comportano i tuoi dati quando esistono valori duplicati.
Combina con il filtraggio: dato che non puoi usare RANK() direttamente in una clausola WHERE, devi incapsulare la query di ranking in una subquery o una CTE quando vuoi filtrare i "Top N".
RANK() è uno strumento utile per fare confronti ordinati in SQL, soprattutto quando ti servono risultati che riflettano scenari reali come valori uguali. Capire come gestisce i pari merito e perché i ranghi possono ripetersi e saltare numeri è importante per un’analisi accurata. Una volta padroneggiato questo comportamento, saprai quando sceglierla insieme ad alternative come DENSE_RANK() e ROW_NUMBER(), in base a ciò che meglio si adatta al tuo caso d’uso specifico.
Ora che hai imparato a classificare i dati in SQL, ti consiglio di dare un’occhiata al nostro percorso di carriera Associate Data Analyst in SQL se vuoi diventare un data analyst competente e acquisire le competenze necessarie. Il nostro corso Reporting in SQL è inoltre indicato se vuoi imparare a creare dashboard professionali usando SQL.
Impara SQL con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

