
Cursus
Gegevens manipuleren in SQL
4 Hr
326.3K
Als je met SQL werkt, is data sorteren eenvoudig omdat je met ORDER BY rijen kunt ordenen. Alleen vertellen gesorteerde resultaten je nog niet de positie van elke rij binnen die volgorde. Daar komt ranking om de hoek kijken. In plaats van alleen gesorteerde data te bekijken, wil je misschien elke rij een positie zoals 1e, 2e of 3e toekennen op basis van specifieke criteria.
De functie RANK() lost dit op door elke rij een numerieke rang toe te kennen volgens de gedefinieerde volgorde. RANK() is onderdeel van SQL window-functies, waarmee je berekeningen over een set rijen kunt uitvoeren terwijl je toch individuele rijen retourneert.
In deze tutorial laat ik je de syntaxis van RANK() zien, praktische voorbeelden, hoe het met gelijke waarden omgaat en hoe het zich verhoudt tot vergelijkbare functies zoals DENSE_RANK() en ROW_NUMBER().
Ben je nieuw met SQL, begin dan met onze Introduction to SQL-cursus, of de Intermediate SQL-cursus als je al wat ervaring hebt.
De SQL-functie RANK() is een window-functie die elke rij een rang toekent op basis van een opgegeven volgorde. De ranking wordt volledig bepaald door de ORDER BY binnen de window-functie. Dus het geeft elke rij een positie zoals 1, 2, 3, enzovoort, volgens de ORDER BY-clausule.
Let erop dat wanneer je RANK() gebruikt:
De basis-syntaxis van de functie RANK() is:
RANK() OVER (ORDER BY column)Waarbij:
OVER-clausule: Definieert het venster (de set rijen) waarop de functie wordt toegepast.
ORDER BY: Bepaalt hoe de ranking wordt toegepast, bijvoorbeeld van hoog naar laag.
PARTITION BY (optioneel): Verdeelt data in groepen en rangschikt rijen afzonderlijk binnen elke groep.
Hieronder staat de syntaxis van de functie RANK() met de PARTITION BY-clausule:
RANK() OVER (PARTITION BY column1 ORDER BY column2)De SQL-functie RANK() wordt breed ondersteund door de belangrijkste databases. Dit zijn onder andere PostgreSQL, MySQL (8.0+), Microsoft SQL Server en Oracle Database. De syntaxis is grotendeels consistent tussen deze systemen, omdat het onderdeel is van de standaard ANSI SQL-specificatie.
Nu je de syntaxis van de functie RANK() begrijpt, laat ik je een eenvoudig voorbeeld zien van hoe het werkt.
Stel dat je de tabel employees hebt met de salarisinformatie van elke medewerker.
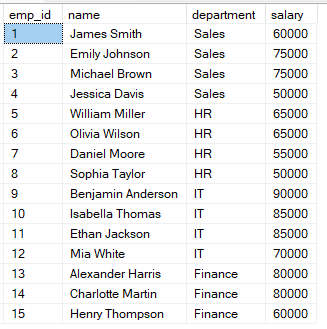
Je kunt de volgende query gebruiken om de medewerkers te rangschikken op basis van hun salaris.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;In de bovenstaande query worden de rijen vanaf het hoogste salaris geordend, dus het hoogste salaris krijgt rang 1. Wanneer twee rijen hetzelfde salaris hebben, krijgen ze dezelfde rang.
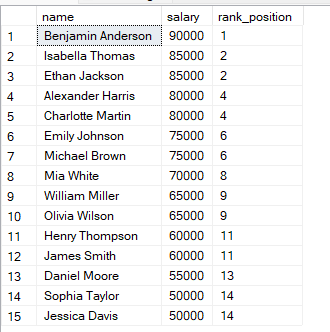
Je ziet dat als twee rijen dezelfde waarden hebben, ze dezelfde rang krijgen.
Daarna wordt de volgende rang overgeslagen. SQL houdt rekening met de gelijke stand door de volgende rangwaarde over te slaan.
Ik raad je aan onze cursus Introduction to SQL Server te volgen om meer te leren over groeperen en data-aggregatie.
Zoals we eerder leerden, kun je met de PARTITION BY-clausule binnen groepen rangschikken in plaats van over de hele dataset.
In het onderstaande voorbeeld worden medewerkers gegroepeerd op department, en begint de ranking opnieuw binnen elke afdeling. Elke groep heeft dus een eigen, onafhankelijke rangvolgorde.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;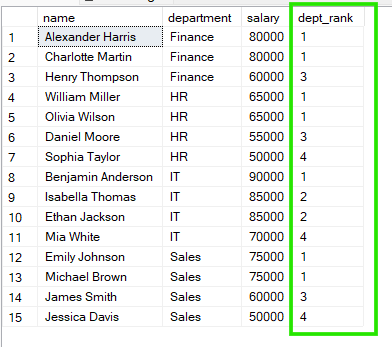
Uit de bovenstaande resultaten zien we dat in “Sales” zowel Emily Johnson als Michael Brown rang 1 delen, terwijl in “HR” William Miller en Olivia Wilson ook rang 1 delen.
Bij het rangschikken van data in SQL kun je kiezen voor RANK(), DENSE_RANK() of ROW_NUMBER(). Deze functies lijken op elkaar, maar gedragen zich als volgt:
RANK(): Gelijke standen delen dezelfde rang, daardoor ontstaan er gaten na gelijke standen.
DENSE_RANK(): Gelijke standen delen dezelfde rang, zonder gaten in de rangorde.
ROW_NUMBER(): Elke rij krijgt een uniek nummer zonder gelijke standen, ook als waarden gelijk zijn.
Om deze verschillen beter te begrijpen, doen we een vergelijking naast elkaar met de onderstaande query:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;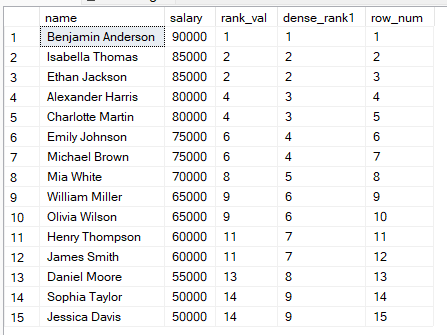
Uit de bovenstaande resultaten kun je ervoor kiezen om:
RANK() te gebruiken wanneer positie belangrijk is en gaten acceptabel zijn.
DENSE_RANK() te gebruiken wanneer je een doorlopende rangorde wil.
ROW_NUMBER() te gebruiken wanneer elke rij een uniek nummer moet hebben, zoals bij paginering van data.
De SQL-functie RANK() is vooral handig wanneer je data wil ordenen en gelijke standen op een natuurlijke manier wil afhandelen. Ik vind het ook belangrijk voor de volgende use-cases:
Hier zijn enkele fouten die ik ben tegengekomen bij het gebruik van de SQL-functie RANK(), en hoe je ze kunt vermijden:
ORDER BY vergeten: Zonder de ORDER BY-clausule heeft ranking geen gedefinieerde logica en kan die onverwachte resultaten opleveren.
Gedrag bij gelijke standen verkeerd begrijpen: Als beginner verwacht je misschien 1, 2, 2, 3, maar RANK() veroorzaakt gaten (1, 2, 2, 4) in de rangen.
RANK() gebruiken wanneer ROW_NUMBER() nodig is: Als je unieke opeenvolgende waarden nodig hebt, is ROW_NUMBER() de betere keuze.
PARTITION BY niet gebruiken wanneer nodig: Zonder partitionering wordt de ranking globaal toegepast in plaats van binnen groepen.
Om je queries overzichtelijk te houden en de verwachte resultaten te krijgen, raad ik aan deze best practices te volgen bij het gebruik van de SQL-functie RANK():
Definieer altijd een duidelijke sortering: Wees expliciet met de ORDER BY-clausule, zoals DESC, om dubbelzinnige rankings te voorkomen.
Kies de juiste rankingfunctie: Gebruik RANK(), DENSE_RANK() of ROW_NUMBER() afhankelijk van hoe je gelijke standen wil afhandelen.
Test scenario’s met gelijke waarden: Controleer vóór productie hoe je data zich gedraagt wanneer dubbele waarden voorkomen.
Combineer met filtering: Omdat je RANK() niet direct in een WHERE-clausule kunt gebruiken, moet je je ranking-query in een Subquery of CTE wikkelen wanneer je “Top N” wil filteren.
RANK() is een handig hulpmiddel om geordende vergelijkingen in SQL te maken, vooral wanneer je resultaten nodig hebt die realistische scenario’s zoals gelijke waarden weerspiegelen. Begrijpen hoe het met gelijke standen omgaat en waarom rangen zich kunnen herhalen en nummers kunnen overslaan, is belangrijk voor nauwkeurige analyses. Als je dit gedrag eenmaal beheerst, weet je wanneer je het moet kiezen naast alternatieven zoals DENSE_RANK() en ROW_NUMBER(), afhankelijk van wat het beste past bij jouw use-case.
Nu je hebt geleerd hoe je data in SQL rangschikt, raad ik je aan onze Associate Data Analyst in SQL-carrièretrack te bekijken als je een vaardige data-analist wil worden en de nodige skills wil leren. Onze cursus Reporting in SQL is ook geschikt als je wil leren hoe je professionele dashboards bouwt met SQL.
Leer SQL met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
