course
Manipularea datelor în SQL
4 oră
326.1K
Când lucrați cu SQL, sortarea datelor este simplă, deoarece puteți folosi cu ușurință ORDER BY pentru a aranja rândurile. Totuși, simpla ordonare a rezultatelor nu vă spune poziția fiecărui rând în acea ordine. Aici intervine ierarhizarea. În loc să vedeți doar date sortate, este posibil să doriți să atribuiți fiecărui rând o poziție precum 1, 2 sau 3 pe baza unor criterii specifice.
Funcția RANK() rezolvă această problemă atribuind un rang numeric fiecărui rând conform ordinii definite. RANK() face parte din funcțiile de fereastră (window functions) din SQL, care vă permit să efectuați calcule pe un set de rânduri, returnând totodată rezultate la nivel de rând individual.
În acest tutorial, vă voi arăta sintaxa funcției RANK(), exemple practice, cum gestionează egalitățile și cum se compară cu funcții similare precum DENSE_RANK() și ROW_NUMBER().
Dacă sunteți la început cu SQL, începeți cu cursul nostru Introducere în SQL sau cu cursul SQL intermediar dacă aveți deja ceva experiență.
Funcția SQL RANK() este o funcție de fereastră care atribuie un rang fiecărui rând pe baza unei ordini specificate. Ierarhizarea este determinată în întregime de ORDER BY din interiorul funcției de fereastră. Astfel, atribuie fiecărui rând o poziție 1, 2, 3 și așa mai departe, conform clauzei ORDER BY.
Trebuie să rețineți că atunci când folosiți RANK():
Sintaxa de bază a funcției RANK() este:
RANK() OVER (ORDER BY column)Unde:
OVER: Definește fereastra (setul de rânduri) asupra căreia operează funcția.
ORDER BY: Determină modul în care se aplică ierarhizarea, de exemplu de la cel mai mare la cel mai mic.
PARTITION BY (opțional): Împarte datele în grupuri, ierarhizând rândurile separat în fiecare grup.
Mai jos este sintaxa funcției RANK() cu clauza PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)Funcția SQL RANK() este larg suportată în principalele baze de date. Acestea includ PostgreSQL, MySQL (8.0+), Microsoft SQL Server și Oracle Database. Sintaxa este în mare parte consecventă între aceste sisteme, deoarece face parte din specificația standard ANSI SQL.
Acum că ați înțeles sintaxa funcției RANK(), permiteți-mi să vă arăt un exemplu simplu despre cum funcționează.
Presupuneți că aveți tabelul employees cu informațiile despre salariul fiecărui angajat.
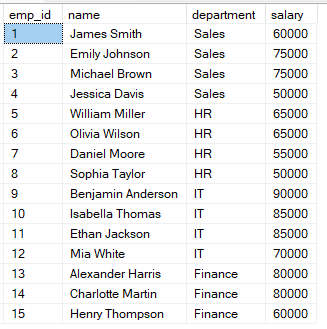
Puteți folosi interogarea de mai jos pentru a ierarhiza angajații în funcție de salariile lor.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;În interogarea de mai sus, rândurile sunt ordonate după salariu de la cel mai mare, așa că salariul cel mai mare primește rangul 1. Când două rânduri au același salariu, primesc același rang.
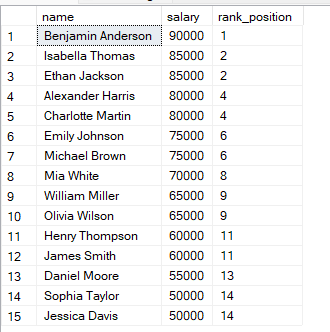
Veți observa că, dacă două rânduri au aceleași valori, ele primesc același rang.
Apoi, următorul rang este sărit. SQL ține cont de egalitate prin sărirea următorului rang.
Vă recomandăm cursul nostru Introducere în SQL Server pentru a afla mai multe despre grupare și agregarea datelor.
După cum am învățat mai devreme, clauza PARTITION BY vă permite să aplicați ierarhizarea în interiorul grupurilor, în loc de întregul set de date.
În exemplul de mai jos, angajații sunt grupați după department, iar ierarhizarea reîncepe în fiecare departament. Prin urmare, fiecare grup are propria sa secvență de clasament independentă.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;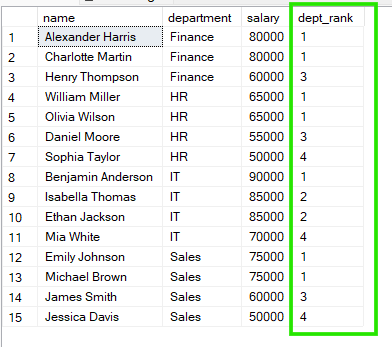
Din rezultatele de mai sus, putem vedea că în „Sales”, atât Emily Johnson, cât și Michael Brown împart rangul 1, iar în „HR”, William Miller și Olivia Wilson împart de asemenea rangul 1.
Când ierarhizați date în SQL, puteți alege să folosiți RANK(), DENSE_RANK() sau ROW_NUMBER(). Aceste funcții pot părea similare, dar se comportă astfel:
RANK(): Egalitățile împart același rang, prin urmare apar goluri după egalități.
DENSE_RANK(): Egalitățile împart același rang, deci nu apar goluri în ierarhizare.
ROW_NUMBER(): Fiecare rând primește un număr unic, fără egalități, chiar dacă valorile sunt egale.
Pentru a înțelege mai bine aceste diferențe, să facem o comparație directă folosind interogarea de mai jos:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;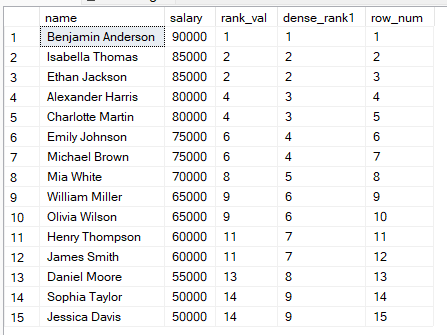
Din rezultatele de mai sus, puteți alege să:
Folosiți RANK() atunci când contează poziția și golurile sunt acceptabile.
Folosiți DENSE_RANK() atunci când doriți o ierarhizare continuă.
Folosiți ROW_NUMBER() atunci când fiecare rând trebuie să aibă un număr unic, de exemplu, în paginarea datelor.
Funcția SQL RANK() este cea mai utilă atunci când doriți să ordonați datele gestionând în mod natural egalitățile. De asemenea, o consider importantă pentru următoarele cazuri de utilizare:
Iată câteva greșeli pe care le-am întâlnit la utilizarea funcției SQL RANK() și cum le puteți evita:
Omiterea clauzei ORDER BY: Fără clauza ORDER BY, ierarhizarea nu are o logică definită și poate returna rezultate neașteptate.
Neînțelegerea comportamentului la egalitate: Ca începător, v-ați putea aștepta la 1, 2, 2, 3, dar RANK() produce goluri (1, 2, 2, 4) în ranguri.
Folosirea RANK() când este nevoie de ROW_NUMBER(): Dacă aveți nevoie de valori secvențiale unice, ROW_NUMBER() este alegerea mai bună.
Neutilizarea PARTITION BY când este necesar: Fără partiționare, ierarhizarea se aplică global, nu în interiorul grupurilor.
Pentru a vă menține interogările curate și a vă asigura că obțineți rezultatele așteptate, vă recomand să urmați aceste bune practici când folosiți funcția SQL RANK():
Definiți întotdeauna o ordonare clară: Fiți expliciți cu clauza ORDER BY, precum DESC, pentru a evita ierarhizările ambigue.
Alegeți funcția de ierarhizare corectă: Folosiți RANK(), DENSE_RANK() sau ROW_NUMBER() în funcție de modul în care doriți să fie tratate egalitățile.
Testați scenariile cu egalități: Înainte de a trece în producție, verificați comportamentul datelor când există valori duplicate.
Combinați cu filtrare: Deoarece nu puteți folosi RANK() direct într-o clauză WHERE, trebuie să înfășurați interogarea cu ierarhizare într-o subinterogare sau un CTE când doriți să filtrați „Top N”.
RANK() este un instrument util pentru a face comparații ordonate în SQL, mai ales când aveți nevoie de rezultate care reflectă scenarii din lumea reală, precum valori egale. Înțelegerea modului în care gestionează egalitățile și de ce rangurile se pot repeta și pot sări numere este importantă pentru analize corecte. Odată ce stăpâniți acest comportament, veți ști când să o alegeți alături de alternative precum DENSE_RANK() și ROW_NUMBER(), în funcție de ceea ce se potrivește cel mai bine cazului dumneavoastră specific.
Acum că ați învățat cum să ierarhizați datele în SQL, vă recomandăm să consultați parcursul nostru de carieră Associate Data Analyst in SQL dacă sunteți interesat(ă) să deveniți un analist de date competent și să învățați abilitățile necesare. Cursul nostru Reporting in SQL este, de asemenea, potrivit dacă doriți să învățați cum să construiți tablouri de bord profesionale folosind SQL.
Învățați SQL cu DataCamp
course
course
course