Course
Манипуляции с данными в SQL
4 ч
326.3K
При работе с SQL сортировка данных проста: вы можете использовать ORDER BY, чтобы упорядочить строки. Однако простая сортировка не показывает положение каждой строки внутри этого порядка. Здесь и пригодится ранжирование. Вместо того чтобы просто смотреть на отсортированные данные, вы можете присвоить каждой строке позицию — например, 1-ю, 2-ю или 3-ю — по определённым критериям.
Функция RANK() решает эту задачу, присваивая каждой строке числовой ранг в соответствии с заданным порядком. RANK() относится к оконным функциям SQL, которые позволяют выполнять вычисления по набору строк, при этом возвращая результаты по каждой строке.
В этом руководстве я покажу синтаксис RANK(), практические примеры, разберу, как функция обрабатывает совпадения, и сравню её с похожими функциями DENSE_RANK() и ROW_NUMBER().
Если вы новичок в SQL, начните с нашего курса Introduction to SQL, или курса Intermediate SQL, если у вас уже есть некоторый опыт.
Функция SQL RANK() — это оконная функция, которая присваивает каждой строке ранг на основе указанного порядка. Ранжирование полностью определяется ORDER BY внутри оконной функции. То есть каждой строке присваивается позиция 1, 2, 3 и так далее в соответствии с выражением ORDER BY.
Обратите внимание, что при использовании RANK():
Базовый синтаксис функции RANK() выглядит так:
RANK() OVER (ORDER BY column)Где:
OVER: определяет окно (набор строк), по которому работает функция.
ORDER BY: задаёт, как применяется ранжирование, например от наибольшего к наименьшему.
PARTITION BY (необязательно): разбивает данные на группы и ранжирует строки отдельно в каждой группе.
Ниже приведён синтаксис функции RANK() с предложением PARTITION BY:
RANK() OVER (PARTITION BY column1 ORDER BY column2)Функция SQL RANK() широко поддерживается основными СУБД, включая PostgreSQL, MySQL (8.0+), Microsoft SQL Server и Oracle Database. Синтаксис в основном единообразен между этими системами, поскольку он является частью стандарта ANSI SQL.
Разобравшись с синтаксисом функции RANK(), давайте посмотрим простой пример её работы.
Предположим, у вас есть таблица employees с информацией о зарплате каждого сотрудника.
Вы можете использовать следующий запрос, чтобы ранжировать сотрудников по уровню зарплаты.
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;В этом запросе строки упорядочены по зарплате по убыванию, поэтому наивысшая зарплата получает ранг 1. Если две строки имеют одинаковую зарплату, они получают одинаковый ранг.
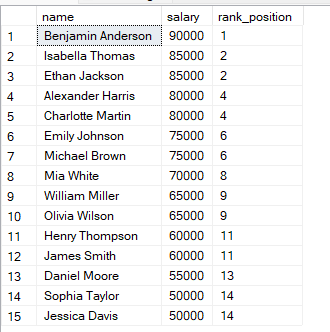
Вы заметите, что если две строки имеют одинаковые значения, они получают одинаковый ранг.
Затем следующий ранг пропускается. SQL учитывает ничью, пропуская следующее значение ранга.
Рекомендую пройти наш курс Introduction to SQL Server, чтобы узнать больше о группировке и агрегировании данных.
Как мы уже узнали, предложение PARTITION BY позволяет применять ранжирование внутри групп, а не по всему набору данных.
В примере ниже сотрудники сгруппированы по полю department, и ранжирование начинается заново в каждом отделе. Таким образом, у каждой группы своя независимая последовательность рангов.
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;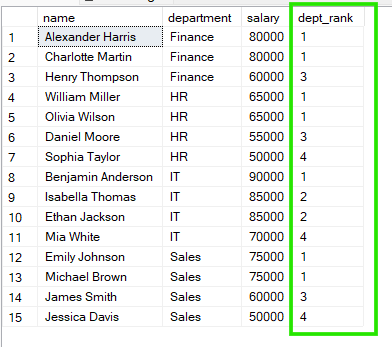
Из результатов видно, что в отделе «Sales» и Emily Johnson, и Michael Brown делят 1-й ранг, а в отделе «HR» William Miller и Olivia Wilson также делят 1-й ранг.
При ранжировании данных в SQL вы можете использовать RANK(), DENSE_RANK() или ROW_NUMBER(). Эти функции выглядят схоже, но ведут себя так:
RANK(): ничьи получают одинаковый ранг, поэтому после них возникают пропуски.
DENSE_RANK(): ничьи получают одинаковый ранг, но без пропусков в последовательности.
ROW_NUMBER(): каждая строка получает уникальный номер без ничьих, даже при равных значениях.
Чтобы лучше понять различия, выполните сравнительный запрос ниже:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;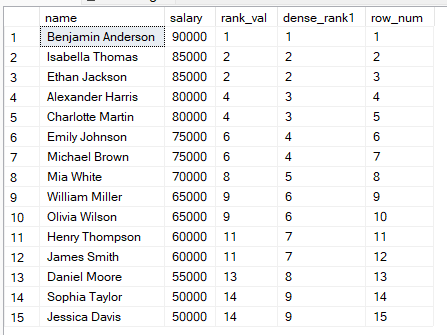
Исходя из этих результатов, вы можете:
Использовать RANK(), когда важна позиция и допустимы пропуски.
Использовать DENSE_RANK(), когда нужен непрерывный ряд рангов.
Использовать ROW_NUMBER(), когда каждой строке нужен уникальный номер, например для пагинации данных.
Функция SQL RANK() особенно полезна, когда нужно упорядочить данные и при этом естественно обработать ничьи. Также она важна в следующих случаях:
Вот некоторые ошибки, с которыми я сталкивался при использовании SQL RANK(), и как их избежать:
Забытый ORDER BY: без предложения ORDER BY ранжирование не имеет определённой логики и может вернуть неожиданные результаты.
Непонимание поведения при ничьих: новички могут ожидать 1, 2, 2, 3, но RANK() создаёт пропуски (1, 2, 2, 4) в рангах.
Использование RANK(), когда нужен ROW_NUMBER(): если требуются уникальные последовательные значения, лучше выбрать ROW_NUMBER().
Неиспользование PARTITION BY при необходимости: без разбиения ранжирование выполняется глобально, а не внутри групп.
Чтобы ваши запросы были чистыми и давали ожидаемые результаты, рекомендую соблюдать следующие практики при использовании функции SQL RANK():
Всегда задавайте чёткий порядок: явно указывайте в ORDER BY, например DESC, чтобы избежать неоднозначного ранжирования.
Выбирайте правильную функцию ранжирования: используйте RANK(), DENSE_RANK() или ROW_NUMBER() в зависимости от того, как нужно обрабатывать ничьи.
Тестируйте сценарии с ничьими: перед выводом в продакшен проверьте, как ведут себя данные при наличии дубликатов значений.
Комбинируйте с фильтрацией: поскольку использовать RANK() напрямую в WHERE нельзя, оборачивайте запрос с ранжированием в подзапрос или CTE, когда нужно отфильтровать «Top N».
RANK() — полезный инструмент для упорядоченных сравнений в SQL, особенно когда нужно учитывать реальные сценарии с равными значениями. Важно понимать, как функция обрабатывает ничьи и почему ранги могут повторяться и пропускать номера. Освоив это поведение, вы сможете выбирать её или альтернативы — DENSE_RANK() и ROW_NUMBER() — в зависимости от задач.
Теперь, когда вы узнали, как ранжировать данные в SQL, рекомендую ознакомиться с нашим карьерным треком Associate Data Analyst in SQL, если вы хотите стать компетентным аналитиком данных и освоить необходимые навыки. Курс Reporting in SQL также подойдёт, если вы хотите научиться создавать профессиональные дашборды на SQL.
Изучайте SQL с DataCamp
Course
Course
Course