Courses
SQL のデータ操作
4時間
326.3K
SQLでの作業では、ORDER BYを使えば行を並べ替えることは簡単です。しかし、並べ替えただけでは、その順序の中で各行が何番目に位置するのかは分かりません。ここで役立つのが「順位付け」です。単に並んだデータを見るのではなく、特定の基準に基づいて各行に1位、2位、3位のような順位を与えたい場合があります。
RANK()関数は、指定した順序に従って各行に数値の順位を割り当てることでこの問題を解決します。RANK()はウィンドウ関数の一種で、行集合にまたがる計算を行いながらも、個々の行の結果を返すことができます。
このチュートリアルでは、RANK()の構文、実用的な例、同順位の扱い方、そしてDENSE_RANK()やROW_NUMBER()のような類似関数との違いを解説します。
SQLが初めての場合は、まず当社のIntroduction to SQLコースから始めてください。多少の経験がある場合はIntermediate SQLコースがおすすめです。
SQLのRANK()関数は、ウィンドウ関数であり、指定した順序に基づいて各行に順位を割り当てます。順位付けはウィンドウ関数内のORDER BYによって完全に決まります。つまり、ORDER BY句に従って各行に1、2、3…といった位置を与えます。
RANK()を使用する際の注意点は次のとおりです。
RANK()関数の基本構文は次のとおりです。
RANK() OVER (ORDER BY column)各要素の意味は次のとおりです。
OVER句: 関数が作用するウィンドウ(行集合)を定義します。
ORDER BY: 例えば高い順など、順位付けの基準を決めます。
PARTITION BY(任意): データをグループに分割し、各グループ内で個別に順位付けします。
以下はPARTITION BY句を用いたRANK()関数の構文です。
RANK() OVER (PARTITION BY column1 ORDER BY column2)SQLのRANK()関数は主要なデータベースで広くサポートされています。対象にはPostgreSQL、MySQL(8.0以降)、Microsoft SQL Server、Oracle Databaseが含まれます。標準のANSI SQL仕様に含まれるため、構文はこれらのシステム間で概ね一貫しています。
ここまででRANK()の構文を理解できたので、実際の動作をシンプルな例で示します。
各従業員の給与情報を持つemployeesテーブルがあるとします。
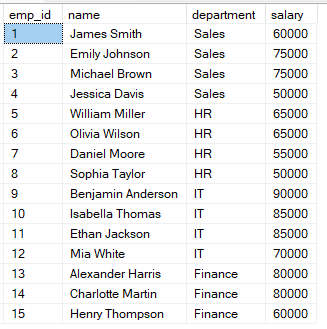
次のクエリで、従業員を給与に応じて順位付けできます。
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;このクエリでは給与が高い順に並べられるため、最高給与が順位1となります。2行の給与が同じ場合は、同じ順位になります。
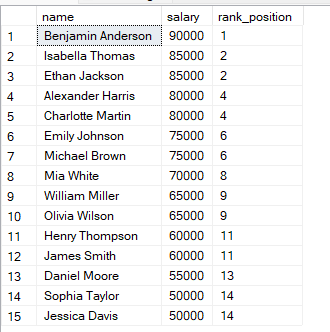
同じ値の行がある場合、同じ順位が割り当てられることに気付くはずです。
その場合、次の順位は飛ばされます。SQLは同順位を考慮して、次の順位の値をスキップします。
グループ化や集計について詳しく学ぶには、当社のIntroduction to SQL Serverコースを受講することをおすすめします。
先ほど学んだとおり、PARTITION BY句を使うと、データ全体ではなくグループ内で順位付けを適用できます。
次の例では、従業員をdepartmentでグループ化し、各部門内で順位付けをやり直しています。したがって、各グループは独立した順位の並びを持ちます。
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;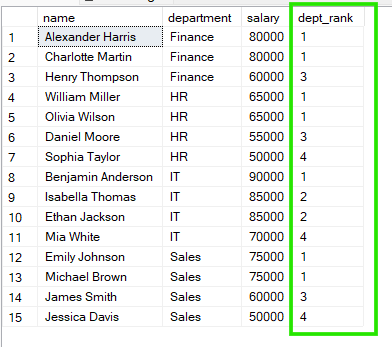
この結果から、「Sales」ではEmily JohnsonとMichael Brownがいずれも1位、「HR」ではWilliam MillerとOlivia Wilsonがいずれも1位であることが分かります。
SQLで順位付けを行う際は、RANK()、DENSE_RANK()、ROW_NUMBER()から選べます。見た目は似ていますが、次のように動作が異なります。
RANK(): 同順位は同じ順位番号を共有するため、タイの後に欠番が生じます。
DENSE_RANK(): 同順位は同じ順位番号を共有しますが、欠番は生じません。
ROW_NUMBER(): 値が同じでも各行に一意の番号を付与し、同順位はありません。
違いをより明確にするため、以下のクエリで並べて比較します。
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;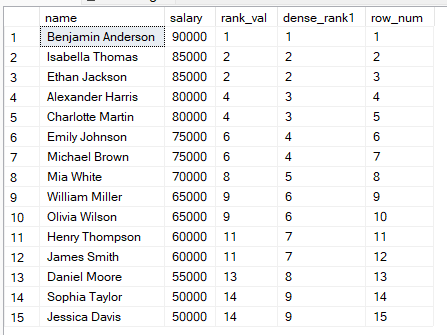
この結果から、次のように使い分けられます。
RANK()は順位そのものが重要で、欠番が許容できる場合に使用します。
DENSE_RANK()は連続した順位が必要な場合に使用します。
ROW_NUMBER()は各行に一意の番号が必要な場合(ページネーションなど)に使用します。
SQLのRANK()関数は、同順位を自然に扱いながらデータを並べたいときに最も有用です。ほかにも、次のような用途で重要だと感じています。
SQLのRANK()関数で見かける誤りと、その回避方法をいくつか挙げます。
ORDER BYの指定漏れ: ORDER BY句がないと順位付けの論理が定まらず、予期しない結果になります。
同順位の挙動の誤解: 初学者は1, 2, 2, 3を期待しがちですが、RANK()は1, 2, 2, 4のように欠番を生じます。
ROW_NUMBER()が必要な場面でRANK()を使用: 連番が一意である必要がある場合は、ROW_NUMBER()の方が適切です。
必要なのにPARTITION BYを使わない: パーティションを指定しないと、グループ内ではなく全体に対して順位付けが適用されます。
クエリを明快に保ち、期待どおりの結果を得るために、SQLのRANK()関数を使用する際は次のベストプラクティスに従うことをおすすめします。
明確な並べ替えを常に定義する: DESCなどを含むORDER BY句を明示して、曖昧な順位付けを避けます。
適切な順位関数を選ぶ: 同順位の扱い方に応じて、RANK()、DENSE_RANK()、ROW_NUMBER()を使い分けます。
タイのシナリオをテストする: 本番適用前に、重複値がある場合の挙動を確認します。
フィルタリングと組み合わせる: RANK()はWHERE句で直接使えないため、上位N件を抽出したい場合は、順位付けのクエリをサブクエリまたはCTEでラップしてフィルタリングします。
RANK()は、同値が存在する現実的なシナリオを反映した結果が必要なときに、SQLで順序付きの比較を行うのに有用なツールです。同順位の扱い方、なぜ順位が重複したり番号が飛んだりするのかを理解することは、正確な分析に不可欠です。この挙動を理解すれば、DENSE_RANK()やROW_NUMBER()などの代替手段と併せて、用途に最も適したものを選べるようになります。
SQLでデータに順位を付ける方法を学んだら、データアナリストとして必要なスキルを身につけたい方に向けたAssociate Data Analyst in SQLキャリアトラックもぜひご覧ください。また、SQLでプロフェッショナルなダッシュボードを構築する方法を学びたい場合は、Reporting in SQLコースも適しています。
DataCampでSQLを学ぶ
Courses
Courses
Courses