Courses
SQL 中的数据处理
4小时
326.1K
在使用 SQL 时,排序数据很简单,您可以轻松使用 ORDER BY 对行进行排列。不过,仅仅排序并不能告诉您每一行在该顺序中的具体位置。这就是排名发挥作用的地方。与其只是查看已排序的数据,您可能希望根据特定条件为每一行分配第 1、2、3 名之类的位置。
RANK() 函数通过根据定义的顺序为每一行分配数值名次来解决这个问题。RANK() 属于 SQL 窗口函数,它允许您在一组行上执行计算,同时仍返回逐行结果。
在本教程中,我将向您展示 RANK() 的语法、实际示例、了解它如何处理并列,并看看它与 DENSE_RANK() 和 ROW_NUMBER() 等类似函数的比较。
如果您是 SQL 新手,请从我们的 Introduction to SQL 课程开始;如果您已有一定经验,可选择 Intermediate SQL 课程。
SQL 的 RANK() 函数是一种窗口函数,可根据指定的顺序为每一行分配名次。名次完全由窗口函数内部的 ORDER BY 决定。因此,它会根据 ORDER BY 子句为每一行给出 1、2、3 等位置。
需要注意的是,当您使用 RANK() 时:
RANK() 函数的基本语法为:
RANK() OVER (ORDER BY column)其中:
OVER 子句:定义函数要操作的窗口(行集)。
ORDER BY:确定如何应用排名,例如从高到低。
PARTITION BY(可选):将数据划分为分组,并在每个组内分别排名。
以下是带有 PARTITION BY 子句的 RANK() 语法:
RANK() OVER (PARTITION BY column1 ORDER BY column2)SQL RANK() 函数在主流数据库中均得到广泛支持,包括 PostgreSQL、MySQL(8.0+)、Microsoft SQL Server 和 Oracle Database。由于它是 ANSI SQL 标准的一部分,因此各系统的语法基本一致。
既然您已经了解了 RANK() 函数的语法,我来展示一个简单的工作示例。
假设您有一个 employees 表,其中包含每位员工的薪资信息。
您可以使用以下查询根据薪资为员工排名。
-- Rank employees by salary
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_position
FROM employees;在上述查询中,行按薪资从高到低排序,因此最高薪资获得名次 1。当两行的薪资相同,它们将获得相同的名次。
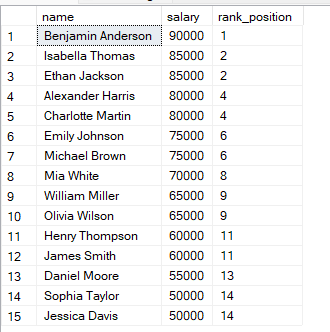
您会注意到,如果两行具有相同的值,它们会得到相同的名次。
随后会跳过下一个名次。SQL 通过跳过下一个名次值来处理并列。
我建议您学习我们的 Introduction to SQL Server 课程,以进一步学习分组与数据聚合。
如前所述,PARTITION BY 子句允许您在分组内应用排名,而不是针对整个数据集。
在下面的示例中,员工按 department 分组,并且每个部门内的排名都会重新开始。因此,每个组都有自己独立的排名序列。
-- Rank employees within each department
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dept_rank
FROM employees;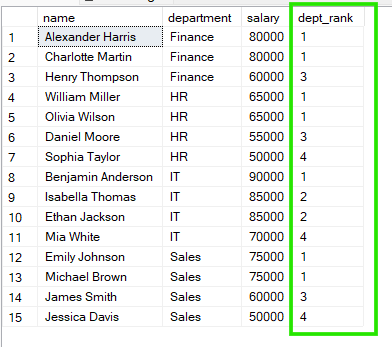
从上述结果可以看到,在“Sales”中,Emily Johnson 和 Michael Brown 并列第 1 名;在“HR”中,William Miller 和 Olivia Wilson 也并列第 1 名。
在 SQL 中进行排名时,您可以选择使用 RANK()、DENSE_RANK() 或 ROW_NUMBER()。这些函数看起来相似,但其行为如下:
RANK():并列共享同一名次,因此并列后会出现空缺。
DENSE_RANK():并列共享同一名次,但排名无空缺。
ROW_NUMBER():即使值相同,每一行也会获得唯一编号,不存在并列。
为更好地理解这些差异,让我们使用下面的查询进行并排比较:
-- Compare RANK() vs DENSE_RANK() vs ROW_NUMBER()
SELECT
name,
salary,
RANK() OVER (ORDER BY salary DESC) AS rank_val, -- allows gaps after ties
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank1, -- no gaps, consecutive ranks
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num -- always unique sequence
FROM employees;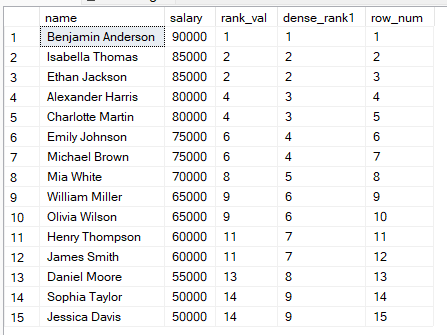
基于上述结果,您可以:
当名次位置本身很重要且可接受空缺时,使用 RANK()。
当您需要连续的排名时,使用 DENSE_RANK()。
当每一行都必须拥有唯一编号(例如数据分页)时,使用 ROW_NUMBER()。
当您希望对数据进行排序并自然处理并列时,SQL RANK() 函数最为有用。我也发现它在以下用例中特别重要:
以下是我在使用 SQL RANK() 函数时遇到的一些错误,以及如何避免它们:
忽略 ORDER BY:没有 ORDER BY 子句,排名就没有明确逻辑,可能返回意外结果。
误解并列行为:作为初学者,您可能期望 1、2、2、3,但 RANK() 会在排名中产生空缺(1、2、2、4)。
在需要 ROW_NUMBER() 时使用 RANK():如果您需要唯一的连续值,ROW_NUMBER() 是更好的选择。
在需要时未使用 PARTITION BY:没有分区时,排名会在全局范围内应用,而不是在组内应用。
为使查询简洁并确保获得预期结果,使用 SQL RANK() 函数时我建议遵循以下最佳实践:
始终定义清晰的排序:在 ORDER BY 子句中明确指定,如 DESC,以避免含糊的排名。
选择正确的排名函数:根据您希望如何处理并列,选择 RANK()、DENSE_RANK() 或 ROW_NUMBER()。
测试并列场景:在上线前,验证当存在重复值时数据的表现。
结合筛选使用:由于您无法在 WHERE 子句中直接使用 RANK(),当要筛选“Top N”时,必须将排名查询包装在子查询(Subquery)或CTE 中。
RANK() 是在 SQL 中进行有序比较的实用工具,尤其当您需要反映现实场景(如数值相等)的结果时。理解它如何处理并列、以及为何名次会重复并跳号,对于准确分析非常重要。一旦掌握其行为,您就能根据具体用例,在 DENSE_RANK() 与 ROW_NUMBER() 等替代方案之间做出合适选择。
现在您已经学会了如何在 SQL 中进行排名,如果您希望成为一名熟练的数据分析师并掌握必要技能,建议查看我们的 Associate Data Analyst in SQL 职业路径。此外,如果您想学习如何使用 SQL 构建专业的仪表板,我们的 Reporting in SQL 课程也很合适。