
Cursus
Cloud Computing begrijpen
2 Hr
241.5K
Datawarehousingtechnologie is de laatste tijd geconsolideerd om schaalbaarder en goedkoper te worden door de opkomst van clouddiensten. Een van de meest gebruikte oplossingen is het datawarehouse BigQuery van Google Cloud Platform.
De Stack Overflow-enquête van 2024 bevestigt de toenemende populariteit: het heeft een adoptiepercentage van 24,1% bereikt onder cloudgebruikers wereldwijd. De vraag naar BigQuery-expertise is in verschillende sectoren sterk toegenomen, waardoor inzicht in de basisbeginselen voor dataprofessionals een professionele noodzaak is geworden.
In dit artikel vind je een overzicht van BigQuery-vragen die vaak tijdens sollicitatiegesprekken worden gesteld, zodat je je goed kunt voorbereiden. Als je net begint met BigQuery, raad ik aan om eerst deze gids over Data Warehousing op GCP te bekijken.
De basis van BigQuery kennen voordat je complexe onderwerpen aansnijdt, is essentieel. Deze vragen toetsen je begrip van de kernconcepten, architectuur en functionaliteit. Als je de volgende vragen niet kunt beantwoorden, begin dan bij het begin met de Beginner’s Guide to BigQuery en schrijf je in voor onze inleidende BigQuery-cursus.
Waarom dit wordt gevraagd: Om je inzicht te toetsen in moderne datawarehouses en hun voordelen ten opzichte van traditionele databases.
BigQuery is een volledig beheerd, serverless datawarehouse op Google Cloud, ontworpen voor grootschalige data-analyse. Het maakt razendsnelle SQL-queries mogelijk op enorme datasets zonder dat je infrastructuur hoeft te beheren, zodat je je kunt richten op inzichten in plaats van onderhoud.
In tegenstelling tot traditionele on-premises relationele databases, die doorgaans rij-gebaseerd zijn en beperkt worden door hardware, is BigQuery een cloud-native, kolomgebaseerd opslagsysteem dat vrijwel oneindige schaalbaarheid biedt. Dankzij de gedistribueerde architectuur en het pay-as-you-go-prijsmodel is het efficiënter voor analytische workloads dan conventionele databases.
Waarom dit wordt gevraagd: Om je kennis van de dataorganisatie en de structuur van BigQuery te toetsen.
Een dataset in BigQuery is de bovenste container die tabellen, views en andere resources organiseert. Dit vormt de basis voor toegangsbeheer en het lokaliseren van data. Door data efficiënt te structureren zorgen datasets voor betere queryprestaties en toegangsbeheer, waardoor ze een fundamenteel onderdeel zijn van de BigQuery-architectuur.
Waarom dit wordt gevraagd: Om je kennis te toetsen van verschillende methoden voor data-inname.
BigQuery biedt verschillende methoden voor data-inname, elk met een eigen doel.
Voor geavanceerde ETL-workflows zorgen Google Cloud Dataflow en andere pijplinetools voor een naadloze dataverplaatsing naar BigQuery. De best passende ingestiemethode hangt af van datavolume, latentie en verwerkingsbehoeften.
Waarom dit wordt gevraagd: Om je kennis te toetsen van BigQuery’s mogelijkheden voor dataverwerking.
BigQuery ondersteunt een reeks datatypes, ingedeeld in:
Elk datatype heeft een gedefinieerde logische opslaggrootte, wat invloed heeft op queryprestaties en kosten. Zo is de opslag van STRING afhankelijk van de UTF-8-gecodeerde lengte, terwijl ARRAY<INT64> 8 bytes per element vereist. Inzicht in deze typen helpt bij het optimaliseren van queries en het efficiënt beheren van kosten.
Alle ondersteunde datatypes kun je in de volgende tabel bekijken.
BigQuery-datatypes. Afbeelding uit Google Cloud-documentatie.
Waarom dit wordt gevraagd: Om zeker te weten dat je de voornaamste pluspunten van BigQuery als datawarehouse begrijpt.
Het gebruik van BigQuery biedt vijf grote voordelen ten opzichte van traditionele, zelfbeheerde oplossingen:
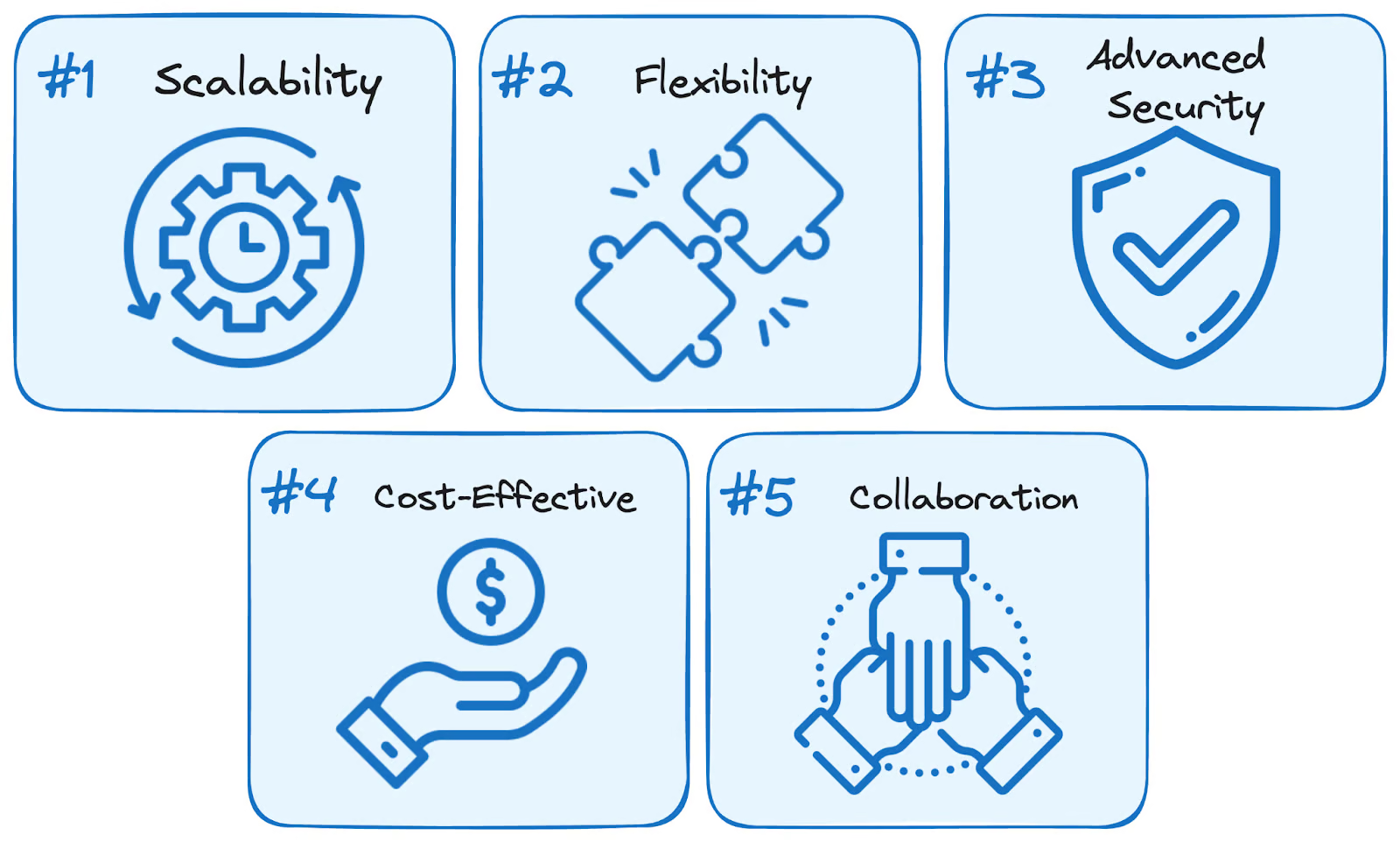
Voordelen van BigQuery. Afbeelding door auteur.
Zodra je de basis van BigQuery beheerst, is het tijd om in te zoomen op meer technische aspecten die interviewers vaak beoordelen.
Deze vragen gaan verder dan definities en toetsen je vermogen om prestaties te optimaliseren, kosten te beheren en te werken met geavanceerde functies zoals partitionering, clustering en beveiliging.
Waarom dit wordt gevraagd: Om je kennis te toetsen van technieken voor dataorganisatie en hun impact op query-efficiëntie.
Partitionering in BigQuery is een methode om grote tabellen op te delen in kleinere, beheersbare stukken op basis van een criterium zoals datum, innametijd of gehele getalwaarden. Doordat data wordt opgesplitst in partities, kan BigQuery de hoeveelheid gescande data tijdens queries beperken, wat de prestaties verhoogt en kosten aanzienlijk verlaagt.
Een voorbeeld: een gepartitioneerde tabel met dagelijkse transactiegegevens maakt het mogelijk om efficiënt op specifieke datumbereiken te filteren in plaats van de hele dataset te scannen. Partitionering is daarom bijzonder nuttig voor tijdreeksanalyse en grootschalige analytische workloads.
Waarom dit wordt gevraagd: Om je inzicht te toetsen in strategieën voor dataorganisatie die query-efficiëntie en kosten optimaliseren.
Clustering in BigQuery verwijst naar de organisatie van data binnen partities op basis van waarden uit een of meer opgegeven kolommen. Door gerelateerde rijen te groeperen via clustering reduceert BigQuery de hoeveelheid te scannen data, wat de queryprestaties verbetert en de verwerkingskosten verlaagt.
Deze manier van optimaliseren is vooral effectief bij het filteren, sorteren of aggregeren op geclustere kolommen, waar de query-engine irrelevante data kan overslaan in plaats van de volledige partitie te scannen. Clustering werkt het best in combinatie met partitionering en biedt nog meer prestatievoordelen bij grote datasets.
Waarom dit wordt gevraagd: Om je begrip van de datastructuren van BigQuery en hun use-cases te toetsen.
In BigQuery is een tabel een gestructureerde opslagunit die data fysiek bevat, terwijl een view een virtuele tabel is die dynamisch data ophaalt op basis van een vooraf gedefinieerde SQL-query. Het belangrijkste verschil is dat views zelf geen data bevatten, maar helpen bij het opbouwen van grote queries of bij het afdwingen van beveiligingsregels rond data-toegang door toegang te bieden tot een subset van data zonder deze te dupliceren. Views kunnen de uitvoeringstijd van queries ook verbeteren doordat je data opnieuw kunt benaderen zonder tabellen te herladen of te herorganiseren, wat ze krachtig maakt voor analytics, data-abstrahering en het afdwingen van security.
Kort samengevat:
Waarom dit wordt gevraagd: Om je kennis te toetsen van BigQuery-beveiliging en de bescherming van gevoelige data.
BigQuery hanteert een gelaagde aanpak voor databeveiliging, gebaseerd op een beveiligingsmodel dat data op alle niveaus van de datalevenscyclus beschermt.
Deze ingebouwde beveiligingsfuncties helpen organisaties de vertrouwelijkheid, integriteit en naleving te waarborgen.
Waarom dit wordt gevraagd: Om je inzicht te beoordelen in geautomatiseerde dataverplaatsing en integratie binnen BigQuery.
De BigQuery Data Transfer Service (BQ DTS) automatiseert en plant data-import uit diverse externe bronnen naar BigQuery, waardoor handmatige ETL-processen overbodig worden. Het integreert native met Google-diensten zoals Google Ads, YouTube en Google Cloud Storage, evenals externe SaaS-applicaties.
Door geautomatiseerde, geplande datatransfers mogelijk te maken, zorgt BQ DTS ervoor dat data up-to-date blijft voor analyse zonder tussenkomst van gebruikers. Deze service is vooral nuttig voor organisaties die terugkerende data-innameworkflows op schaal beheren, wat de efficiëntie verhoogt en de operationele overhead verlaagt.
Waarom dit wordt gevraagd: Om je begrip te toetsen van BigQuery’s ondersteuning voor semi-gestructureerde data en de voordelen ten opzichte van traditionele relationele modellen.
BigQuery ondersteunt geneste en herhaalde velden, wat efficiëntere opslag en query’s van hiërarchische of array-gebaseerde data mogelijk maakt. Geneste velden gebruiken het datatype STRUCT, waardoor een kolom subvelden kan bevatten, vergelijkbaar met een JSON-object.
Herhaalde velden functioneren als ARRAYS, zodat één kolom meerdere waarden kan opslaan. Deze structuren helpen complexe JOIN-bewerkingen te vermijden, verbeteren de queryprestaties en maken BigQuery zeer geschikt voor het verwerken van semi-gestructureerde data zoals logs, eventstreams en NoSQL-achtige datasets.
Waarom dit wordt gevraagd: Om je kennis te toetsen van het automatiseren van query-uitvoering en workflowbeheer in BigQuery.
BigQuery biedt meerdere manieren om jobs te plannen en te automatiseren, zodat terugkerende taken zonder handmatige tussenkomst draaien.
Deze automatiseringstools stroomlijnen datapijplijnen, verminderen handmatig werk en zorgen voor tijdige dataverwerking voor analytics en rapportage.
Waarom dit wordt gevraagd: Om je inzicht te toetsen in strategieën voor dataorganisatie in BigQuery en hun impact op queryprestaties en kostenefficiëntie.
Partitionering splitst grote tabellen in kleinere segmenten, waardoor queryprestaties verbeteren doordat alleen relevante data wordt gescand.
Tijdbased: Op DATE, TIMESTAMP, DATETIME (bijv. dagelijkse sales_date-partities).
Bereik van gehele getallen: Op INTEGER-waarden (bijv. user_id-bereiken).
Innametijd: Op timestamp van dataload (_PARTITIONDATE).
Het is het best voor tijdreeksdata en het verlagen van querykosten bij filtering op datum- of numerieke bereiken.
Clustering ordent data binnen een tabel of partitie door te sorteren op geselecteerde kolommen, wat queries versnelt.
Het is het best bij filteren en aggregeren op veelgevraagde velden zoals regio of user_id.
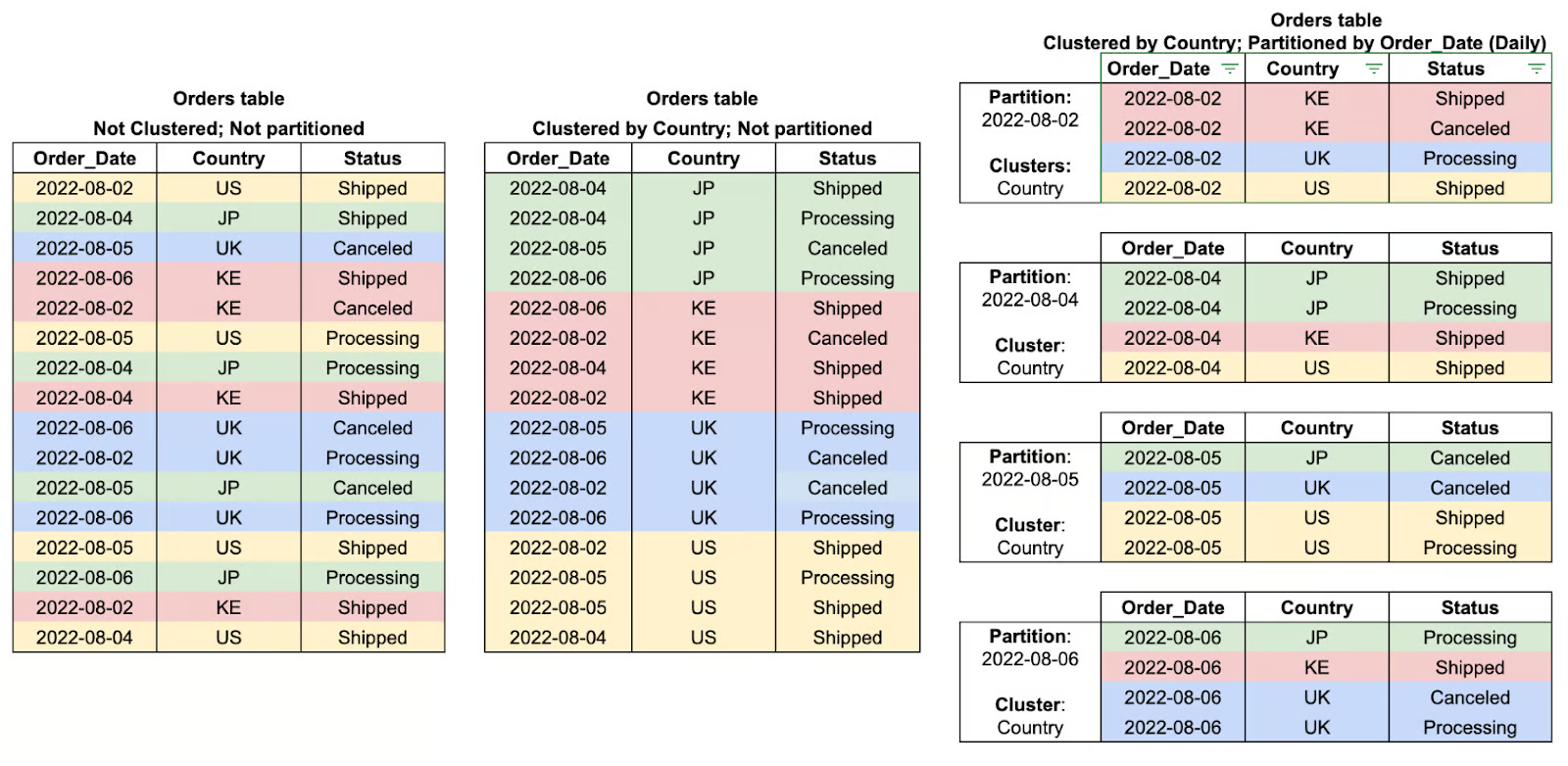
Voorbeelden van tabelclusters en -partities. Afbeelding door Google Cloud.
Waarom dit wordt gevraagd: Om je begrip te beoordelen van BigQuery’s serverless architectuur en hoe die verschilt van traditionele datawarehouses.
BigQuery heeft een serverless, volledig beheerde architectuur die opslag en compute loskoppelt, zodat beide onafhankelijk kunnen schalen op basis van de vraag. In tegenstelling tot traditionele cloud-datawarehouses of on-premises massively parallel processing (MPP)-systemen biedt deze scheiding flexibiliteit, kostenefficiëntie en hoge beschikbaarheid zonder dat gebruikers infrastructuur hoeven te beheren. BigQuery’s reken-engine wordt aangedreven door Dremel, een multi-tenant cluster dat SQL-queries efficiënt uitvoert, terwijl data is opgeslagen in Colossus, Google’s wereldwijde gedistribueerde opslagsysteem. Deze componenten communiceren via Jupiter, Google’s netwerk op petabitschaal, wat ultrasnelle datatransfer garandeert. Het geheel wordt georkestreerd door Borg, Google’s interne clustermanagementsysteem en voorloper van Kubernetes. Dankzij deze architectuur kunnen gebruikers hoog-performante, schaalbare analyses uitvoeren op enorme datasets zonder zich zorgen te hoeven maken over infrastructuurbeheer.
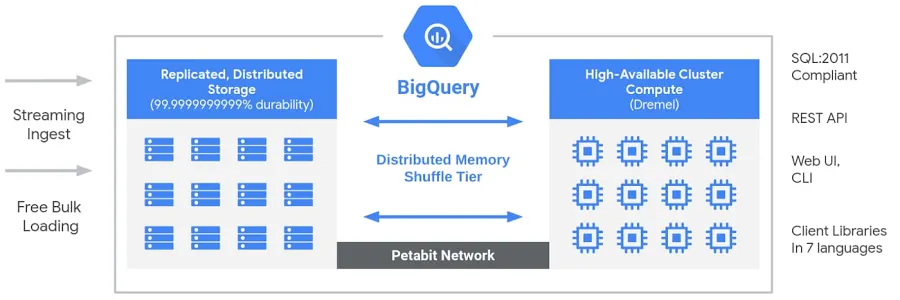
Big Query-architectuur. Afbeelding door Google.
Waarom dit wordt gevraagd: Deze vraag beoordeelt je begrip van de BigQuery-architectuur, specifiek hoe het losgekoppelde opslag- en computemodel de schaalbaarheid, kostenefficiëntie en prestaties verbetert.
BigQuery volgt een serverless, volledig beheerde architectuur waarin opslag en compute volledig gescheiden zijn:
Belangrijkste voordelen van het scheiden van opslag en compute:
Dankzij dit ontwerp kan BigQuery efficiënt queries op petabyteschaal verwerken tegen lage kosten, waardoor het een ideale keuze is voor cloudgebaseerde analytics.
Deze architecturale flexibiliteit is cruciaal nu de industrie de focus verlegt naar enorme rekenkracht. Zoals opgemerkt in de DataFramed-podcast over datatrends voor 2025:
Er is zeker een weddenschap die alle grote spelers maken. Ze bouwen meer compute, en dus zullen ze volgend jaar opschalen met meer compute. En dan is de vraag: oké, is er meer data? En daar wordt het genuanceerder. En ik denk dat het een spectrum is. Het is niet zwart-wit.
Jonathan Cornelissen, Co-founder & CEO of DataCamp
Waarom dit wordt gevraagd: Om je kennis te beoordelen van Dremel, de onderliggende query-engine van BigQuery, en hoe het boomgebaseerde, kolomgeoriënteerde uitvoeringsmodel high-performance data-analyse mogelijk maakt.
Dremel is een gedistribueerde query-uitvoeringsengine die BigQuery aandrijft. In tegenstelling tot traditionele databases die rij-gebaseerde verwerking gebruiken, hanteert Dremel een kolomgebaseerd opslagformaat en een boomgebaseerd uitvoeringsmodel voor snelheid en efficiëntie.
Hoe Dremel snelle queries mogelijk maakt:
Belangrijkste voordelen van Dremel:
Meer over Dremel lees je in de officiële documentatie van Google.
Waarom dit wordt gevraagd: Om je begrip te toetsen van datamodelleringsstrategieën en hun impact op queryprestaties in analytische databases.
Denormalisatie in BigQuery voegt bewust redundantie toe door tabellen samen te voegen en data te dupliceren om queryprestaties te optimaliseren. In tegenstelling tot normalisatie, dat redundantie minimaliseert via kleinere, gerelateerde tabellen, vermindert denormalisatie de noodzaak voor complexe joins, wat resulteert in snellere leestijden. Deze aanpak is vooral nuttig in datawarehousing en analytics, waar leesbewerkingen vaker voorkomen dan schrijfbewerkingen. Denormalisatie verhoogt echter de opslagbehoefte, daarom raadt BigQuery aan geneste en herhaalde velden te gebruiken om denormaliseerde data efficiënt te structureren met minimale opslagoverhead.
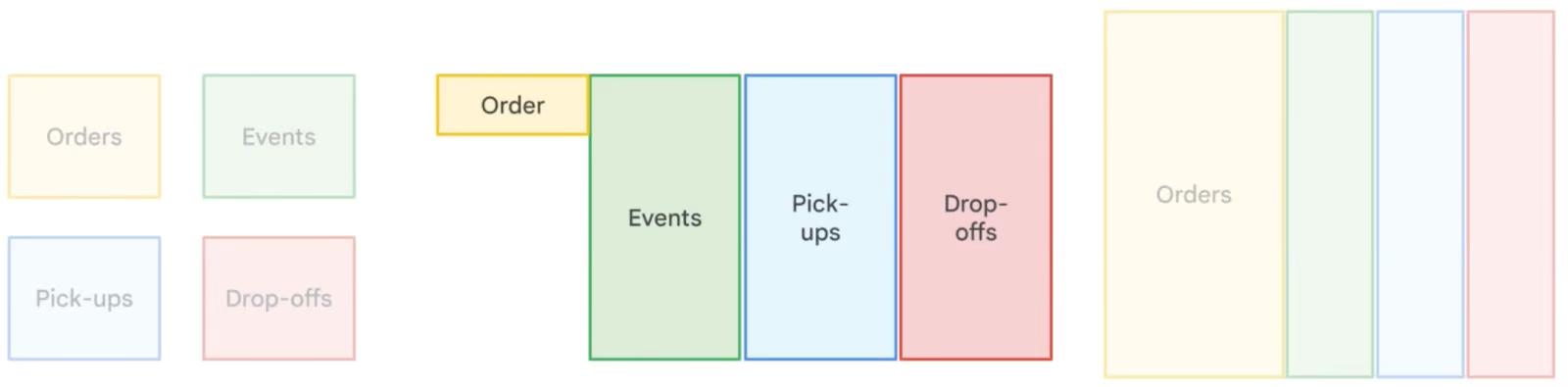
Vergelijking van verschillende normalisatiestrategieën. Afbeelding door Google Cloud.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
