
Corso
Comprendere il Cloud Computing
2 h
241.8K
La tecnologia di data warehousing è stata recentemente consolidata per diventare più scalabile e meno costosa grazie alla diffusione dei servizi cloud. Una delle soluzioni più comuni è BigQuery, il data warehouse di Google Cloud Platform.
Il sondaggio Stack Overflow 2024 conferma la sua crescente popolarità, avendo raggiunto una percentuale di adozione del 24,1% tra gli utenti cloud di tutto il mondo. La domanda di competenze su BigQuery è aumentata in modo significativo in vari settori, rendendo la comprensione dei suoi fondamentali una necessità professionale tra i data professional.
In questo articolo troverai una raccolta di domande su BigQuery spesso poste durante i colloqui, per aiutarti a prepararti. Se stai iniziando ora a conoscere BigQuery, ti suggerisco prima di consultare questa guida sul Data Warehousing su GCP.
Conoscere le basi di BigQuery prima di affrontare argomenti complessi è essenziale. Queste domande valutano la tua comprensione dei concetti chiave, dell'architettura e delle funzionalità. Se non riesci a rispondere alle domande seguenti, ti incoraggio a partire dall'inizio consultando la Guida per principianti a BigQuery e iscrivendoti al nostro corso introduttivo su BigQuery.
Perché viene chiesto: per valutare la tua comprensione dei moderni data warehouse e dei loro vantaggi rispetto ai database tradizionali.
BigQuery è un data warehouse completamente gestito e serverless su Google Cloud, progettato per l'analisi di dati su larga scala. Permette di eseguire query SQL ad alta velocità su dataset enormi senza dover gestire l'infrastruttura, consentendo agli utenti di concentrarsi sugli insight invece che sulla manutenzione.
A differenza dei database relazionali on-premise tradizionali, tipicamente basati su righe e limitati dall'hardware, BigQuery è un sistema cloud-native con storage colonnare che offre una scalabilità quasi infinita. La sua architettura distribuita e il modello di prezzo pay-as-you-go lo rendono più efficiente nella gestione dei carichi analitici rispetto ai database convenzionali.
Perché viene chiesto: per testare la tua conoscenza dell'organizzazione dei dati e della struttura di BigQuery.
Un dataset, in BigQuery, è definito come il contenitore di livello più alto che organizza tabelle, viste e altre risorse. Ciò consente il controllo degli accessi e l'individuazione dei dati. Strutturando i dati in modo efficiente, i dataset garantiscono migliori prestazioni delle query e una gestione ottimale degli accessi, rendendoli un componente fondamentale dell'architettura di BigQuery.
Perché viene chiesto: per testare la tua conoscenza dei diversi metodi di ingestione dei dati.
BigQuery offre diversi metodi di ingestione dei dati pensati per scopi differenti.
Per workflow ETL avanzati, Google Cloud Dataflow e altri strumenti di pipeline facilitano il trasferimento fluido dei dati in BigQuery. La scelta del metodo di ingestione più adatto dipende da volume dei dati, latenza e necessità di elaborazione.
Perché viene chiesto: per testare la tua conoscenza delle capacità di gestione dei dati di BigQuery.
BigQuery supporta una varietà di tipi di dati, categorizzati in:
Ogni tipo di dato ha una dimensione logica di archiviazione definita, che influisce sulle prestazioni delle query e sui costi. Ad esempio, l'archiviazione di STRING dipende dalla lunghezza codificata in UTF-8, mentre ARRAY<INT64> richiede 8 byte per elemento. Comprendere questi tipi aiuta a ottimizzare le query e gestire i costi in modo efficiente.
Puoi consultare tutti i tipi di dati supportati nella seguente tabella.
Tipi di dati di BigQuery. Immagine da Google Cloud Documentation.
Perché viene chiesto: per assicurarsi che tu capisca i principali benefici dell'uso di BigQuery come Data Warehouse.
Usare i servizi BigQuery porta cinque benefici principali rispetto alle soluzioni autogestite tradizionali:
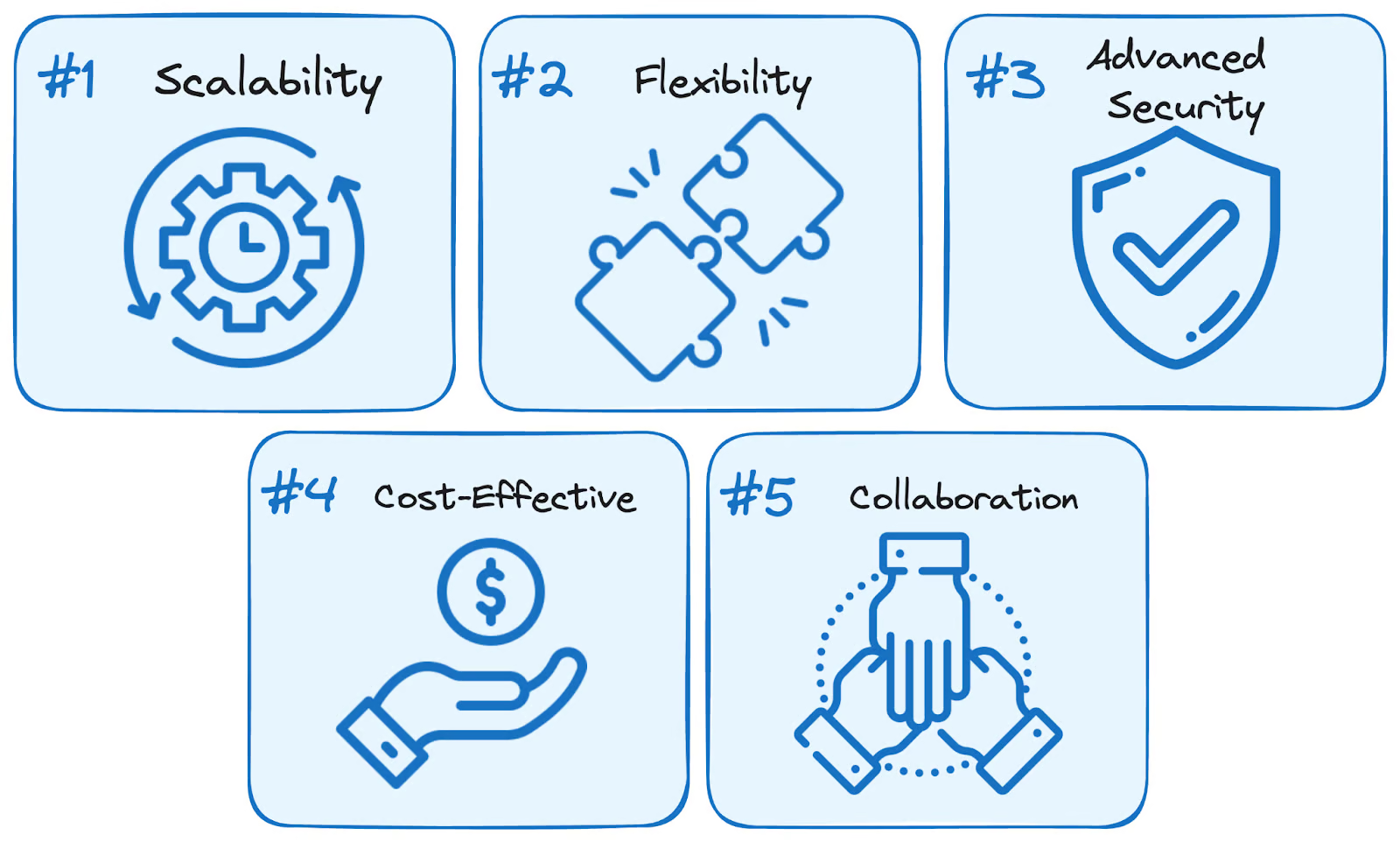
Vantaggi di BigQuery. Immagine dell'autore.
Una volta compresi i fondamenti di BigQuery, è il momento di approfondire gli aspetti più tecnici che gli intervistatori valutano di frequente.
Queste domande vanno oltre le definizioni di base e testano la tua capacità di ottimizzare le prestazioni, gestire i costi e lavorare con funzionalità avanzate come partizionamento, clustering e sicurezza.
Perché viene chiesto: per valutare la tua conoscenza delle tecniche di organizzazione dei dati e del loro impatto sull'efficienza delle query.
Il partizionamento in BigQuery è un metodo per suddividere tabelle grandi in parti più piccole e gestibili in base a un determinato criterio, come data, tempo di ingestione o valori interi. Segmentando i dati in partizioni, BigQuery può limitare la quantità di dati scansionati durante le query, aumentando le prestazioni e riducendo notevolmente i costi.
Ad esempio, una tabella partizionata che archivia i dati delle transazioni giornaliere consente alle query di filtrare in modo efficiente intervalli di date specifici invece di scansionare l'intero dataset. Questo rende il partizionamento particolarmente utile per l'analisi di serie temporali e i carichi analitici su larga scala.
Perché viene chiesto: per valutare la tua comprensione delle strategie di organizzazione dei dati che ottimizzano l'efficienza e i costi delle query.
Il clustering in BigQuery si riferisce all'organizzazione dei dati all'interno delle partizioni in base ai valori di una o più colonne specificate. Raggruppando di fatto le righe correlate, il clustering riduce la quantità di dati scansionati, migliorando così le prestazioni delle query e diminuendo i costi di elaborazione complessivi.
Questo tipo di ottimizzazione delle query è particolarmente efficace quando si filtrano, ordinano o aggregano dati in base alle colonne clusterizzate, dove il motore di query può ignorare del tutto i dati non pertinenti anziché eseguire una scansione completa della partizione. Il clustering dà il meglio se combinato con il partizionamento e offre ulteriori vantaggi prestazionali quando si lavora con grandi dataset.
Perché viene chiesto: per valutare la tua comprensione delle strutture dati di BigQuery e dei loro casi d'uso.
In BigQuery, una tabella è un'unità di archiviazione strutturata che contiene fisicamente i dati, mentre una vista è una tabella virtuale che recupera dinamicamente i dati in base a una query SQL predefinita. La distinzione chiave è che le viste non possono contenere dati di per sé, ma servono come base per scrivere query complesse o per applicare regole di sicurezza sull'accesso ai dati offrendo l'accesso a un sottoinsieme di dati senza duplicarli. Le viste migliorano anche i tempi di esecuzione delle query permettendo di riaccedere ai dati senza dover ricaricare o riorganizzare le tabelle, risultando potenti per analisi, astrazione dei dati e applicazione della sicurezza.
In parole semplici:
Perché viene chiesto: per verificare la tua conoscenza della sicurezza in BigQuery unita alla protezione dei dati sensibili.
BigQuery adotta un approccio stratificato alla sicurezza dei dati, partendo da un modello sicuro progettato per salvaguardare i dati a tutti i livelli del ciclo di vita.
Queste funzionalità di sicurezza integrate aiutano le organizzazioni a mantenere riservatezza, integrità e conformità normativa dei dati.
Perché viene chiesto: per valutare la tua comprensione della movimentazione e integrazione automatizzata dei dati in BigQuery.
Il BigQuery Data Transfer Service (BQ DTS) automatizza e pianifica le importazioni di dati da varie fonti esterne in BigQuery, eliminando la necessità di processi ETL manuali. Si integra nativamente con i servizi Google come Google Ads, YouTube e Google Cloud Storage, oltre che con applicazioni SaaS di terze parti.
Abilitando trasferimenti di dati automatici e pianificati, BQ DTS garantisce che i dati rimangano aggiornati per l'analisi senza richiedere intervento dell'utente. Questo servizio è particolarmente utile per le organizzazioni che gestiscono workflow ricorrenti di ingestione dati su larga scala, migliorando l'efficienza e riducendo l'overhead operativo.
Perché viene chiesto: per valutare la tua comprensione del supporto di BigQuery ai dati semi-strutturati e dei suoi vantaggi rispetto ai modelli relazionali tradizionali.
BigQuery consente campi annidati e ripetuti, abilitando un'archiviazione e una interrogazione più efficienti di dati gerarchici o basati su array. I campi annidati usano il tipo di dato STRUCT, permettendo a una colonna di contenere sotto-campi, simile a un oggetto JSON.
I campi ripetuti funzionano come ARRAY, consentendo a una singola colonna di archiviare valori multipli. Queste strutture aiutano a eliminare la necessità di JOIN complessi, migliorano le prestazioni delle query e rendono BigQuery particolarmente adatto all'elaborazione di dati semi-strutturati come log, flussi di eventi e dataset in stile NoSQL.
Perché viene chiesto: per valutare la tua conoscenza dell'automazione dell'esecuzione delle query e della gestione dei workflow in BigQuery.
BigQuery offre diversi metodi per pianificare e automatizzare i job, assicurando che le attività ricorrenti vengano eseguite senza intervento manuale.
Questi strumenti di automazione aiutano a semplificare le pipeline di dati, ridurre il lavoro manuale e garantire un'elaborazione puntuale dei dati per analisi e reportistica.
Perché viene chiesto: per valutare la tua comprensione delle strategie di organizzazione dei dati in BigQuery e del loro impatto su prestazioni e costi.
Partizionamento suddivide grandi tabelle in segmenti più piccoli, migliorando le prestazioni delle query scansionando solo i dati rilevanti.
Basato sul tempo: per DATE, TIMESTAMP, DATETIME (es., partizioni giornaliere su sales_date).
Intervallo di interi: per valori INTEGER (es., intervalli di user_id).
Tempo di ingestione: per timestamp di caricamento dati (_PARTITIONDATE).
È ideale per dati di serie temporali e per ridurre i costi delle query quando si filtra per intervalli di date o numerici.
Clustering organizza i dati all'interno di una tabella o partizione ordinandoli in base a colonne selezionate, velocizzando le query.
È ideale per filtrare e aggregare in base a campi interrogati di frequente come regione o user_id.
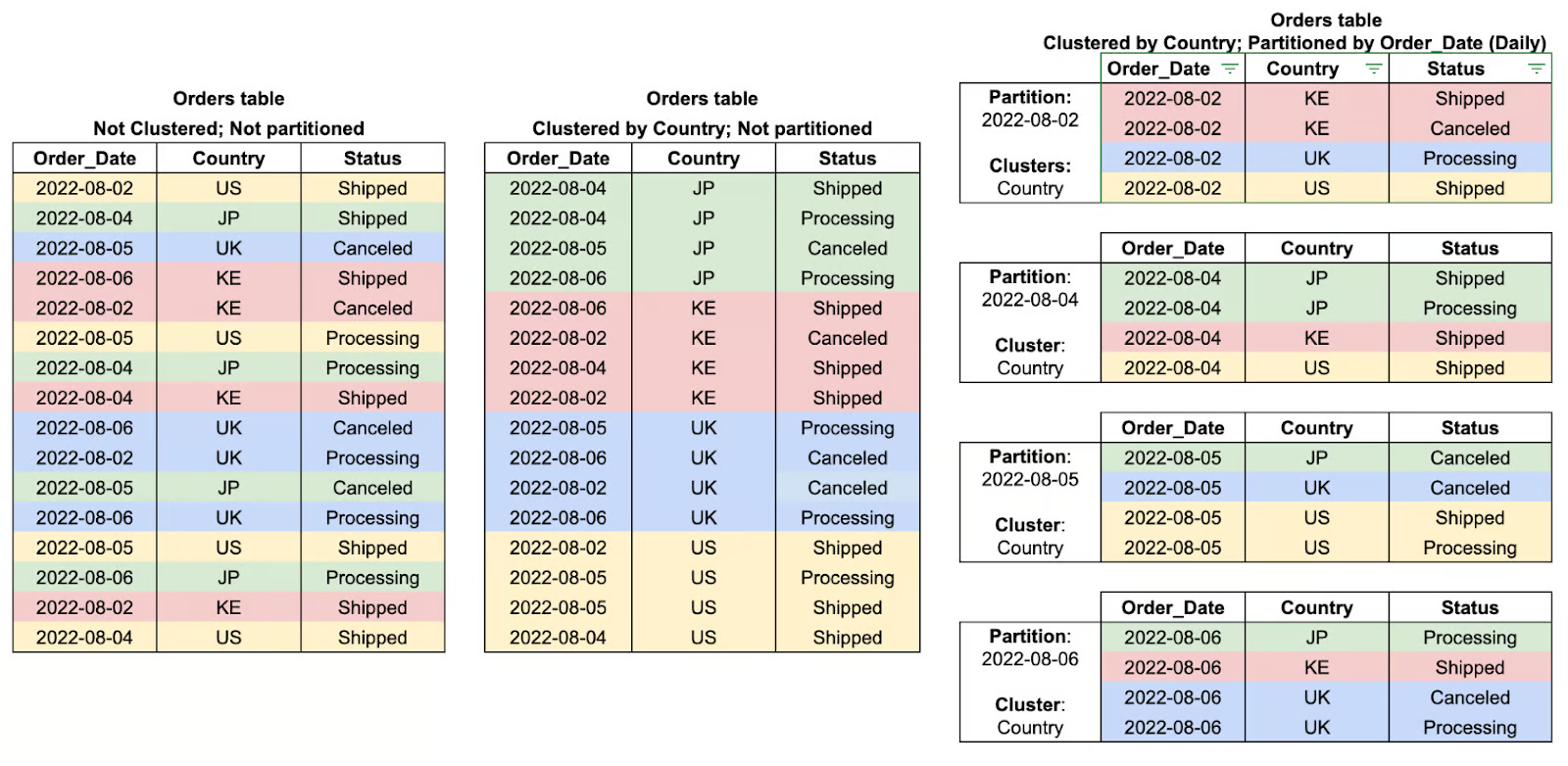
Esempi di cluster e partizioni di tabelle. Immagine di Google Cloud.
Perché viene chiesto: per valutare la tua comprensione dell'architettura serverless di BigQuery e di come differisce dai data warehouse tradizionali.
BigQuery presenta un'architettura serverless completamente gestita che disaccoppia storage e compute, permettendo loro di scalare indipendentemente in base alla domanda. A differenza dei tradizionali data warehouse cloud o dei sistemi on-premise MPP (massively parallel processing), questa separazione offre flessibilità, convenienza economica e alta disponibilità senza richiedere la gestione dell'infrastruttura da parte degli utenti. Il motore di calcolo di BigQuery è alimentato da Dremel, un cluster multi-tenant che esegue efficientemente query SQL, mentre i dati sono archiviati in Colossus, il sistema di archiviazione distribuita globale di Google. Questi componenti comunicano tramite Jupiter, la rete su scala petabit di Google, garantendo trasferimenti di dati ultra veloci. L'intero sistema è orchestrato da Borg, il sistema interno di gestione dei cluster di Google e precursore di Kubernetes. Questa architettura consente di eseguire analisi ad alte prestazioni e scalabili su dataset massivi senza doversi preoccupare della gestione dell'infrastruttura.
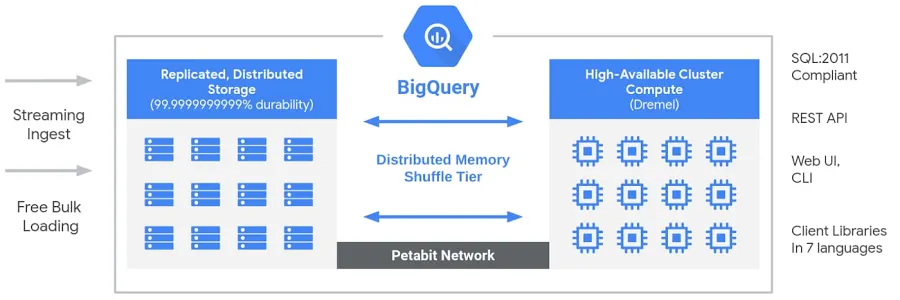
Architettura di Big Query. Immagine di Google.
Perché viene chiesto: questa domanda valuta la tua comprensione dell'architettura di BigQuery, in particolare come il suo modello disaccoppiato di storage e compute migliori scalabilità, costi e prestazioni.
BigQuery segue un'architettura serverless completamente gestita in cui storage e compute sono completamente separati:
Vantaggi chiave della separazione storage-compute:
Questo design consente a BigQuery di elaborare query su scala petabyte in modo efficiente mantenendo bassi i costi, rendendolo una scelta ideale per l'analisi nel cloud.
Questa flessibilità architetturale è cruciale mentre il settore sposta l'attenzione verso una potenza computazionale massiva. Come osservato nel podcast DataFramed riguardo ai trend dei dati per il 2025:
C'è sicuramente una scommessa che stanno facendo tutti i grandi player. Stanno costruendo più capacità di calcolo e quindi scaleranno attraverso più compute il prossimo anno. Poi la domanda è: OK, ci sono più dati? Ed è qui che diventa più sfumato. E penso sia uno spettro. Non è bianco o nero.
Jonathan Cornelissen, Co-founder & CEO of DataCamp
Perché viene chiesto: per valutare la tua conoscenza di Dremel, il motore di query sottostante di BigQuery, e di come il suo modello di esecuzione ad albero e colonnare abiliti analisi dei dati ad alte prestazioni.
Dremel è un motore distribuito di esecuzione delle query che alimenta BigQuery. A differenza dei database tradizionali che usano l'elaborazione basata su righe, Dremel utilizza un formato di archiviazione colonnare e un modello di esecuzione delle query ad albero per ottimizzare velocità ed efficienza.
Come Dremel rende le query veloci:
Benefici chiave di Dremel:
Puoi saperne di più su Dremel nella documentazione ufficiale di Google.
Perché viene chiesto: per valutare la tua comprensione delle strategie di modellazione dei dati e del loro impatto sulle prestazioni delle query nei database analitici.
La denormalizzazione in BigQuery introduce intenzionalmente ridondanza unendo tabelle e duplicando dati per ottimizzare le prestazioni delle query. A differenza della normalizzazione, che minimizza la ridondanza tramite tabelle più piccole e correlate, la denormalizzazione riduce la necessità di join complessi, con conseguenti tempi di lettura più rapidi. Questo approccio è particolarmente utile in data warehousing e analytics, dove le operazioni di lettura sono più frequenti delle scritture. Tuttavia, la denormalizzazione aumenta i requisiti di storage, motivo per cui BigQuery raccomanda di usare campi annidati e ripetuti per strutturare in modo efficiente i dati denormalizzati riducendo al minimo l'overhead di archiviazione.
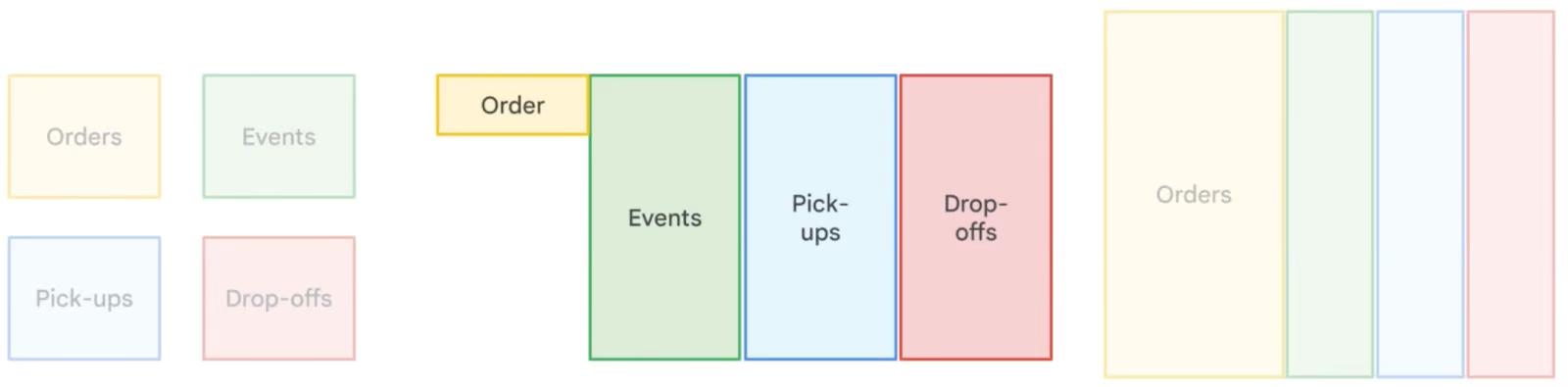
Confronto tra diverse strategie di normalizzazione dei dati. Immagine di Google Cloud.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

