
Kursus
Memahami Cloud Computing
2 Hr
241.5K
Teknologi data warehousing belakangan ini terkonsolidasi menjadi lebih skalabel dan lebih hemat biaya seiring populernya layanan cloud. Salah satu solusi yang paling umum adalah gudang data BigQuery milik Google Cloud Platform.
Survei Stack Overflow 2024 menegaskan peningkatan popularitasnya, dengan tingkat adopsi mencapai 24,1% di kalangan pengguna cloud di seluruh dunia. Permintaan akan keahlian BigQuery meningkat signifikan di berbagai industri, sehingga pemahaman dasar-dasarnya menjadi kebutuhan profesional bagi para praktisi data.
Dalam artikel ini, Anda akan menemukan kumpulan pertanyaan BigQuery yang sering ditanyakan saat wawancara kerja untuk membantu Anda bersiap. Jika Anda baru mulai mempelajari BigQuery, saya sarankan untuk melihat terlebih dahulu panduan tentang Data Warehousing di GCP berikut.
Mengetahui dasar-dasar BigQuery sebelum membahas topik kompleks sangatlah penting. Pertanyaan-pertanyaan ini menilai pemahaman Anda tentang konsep inti, arsitektur, dan fungsionalitasnya. Jika Anda belum bisa menjawab pertanyaan-pertanyaan berikut, saya mendorong Anda untuk mulai dari awal dengan membaca Panduan Pemula BigQuery dan mengikuti kursus pengantar BigQuery kami.
Alasan ditanyakan: Untuk mengevaluasi pemahaman Anda tentang gudang data modern dan keunggulannya dibandingkan basis data tradisional.
BigQuery adalah gudang data terkelola sepenuhnya dan serverless di Google Cloud yang dirancang untuk analitik data skala besar. BigQuery memungkinkan kueri SQL berkecepatan tinggi pada himpunan data masif tanpa perlu mengelola infrastruktur, sehingga pengguna dapat fokus pada insight alih-alih pemeliharaan.
Berbeda dengan basis data relasional on-premises tradisional, yang umumnya berbasis baris dan dibatasi keterbatasan perangkat keras, BigQuery adalah sistem penyimpanan kolumnar native-cloud yang menawarkan skalabilitas nyaris tak terbatas. Arsitektur terdistribusi dan model harga bayar-sesuai-pemakaian membuatnya lebih efisien untuk menangani beban kerja analitik dibandingkan basis data konvensional.
Alasan ditanyakan: Untuk menguji pengetahuan Anda tentang pengorganisasian data dan struktur BigQuery.
Dataset, di BigQuery, didefinisikan sebagai kontainer tingkat teratas yang mengorganisasi tabel, view, dan sumber daya lainnya. Ini membuka jalan bagi kontrol akses dan penentuan lokasi data. Dengan menstrukturkan data secara efisien, dataset memastikan kinerja kueri dan pengelolaan akses yang lebih baik, menjadikannya komponen fundamental dalam arsitektur BigQuery.
Alasan ditanyakan: Untuk menguji pengetahuan Anda tentang berbagai metode ingest data.
BigQuery menawarkan beberapa metode ingest data untuk tujuan yang berbeda.
Untuk alur kerja ETL lanjutan, Google Cloud Dataflow dan alat pipeline lainnya memfasilitasi perpindahan data tanpa hambatan ke BigQuery. Memilih metode ingest yang paling sesuai bergantung pada volume data, latensi, dan kebutuhan pemrosesan.
Alasan ditanyakan: Untuk menguji pengetahuan Anda tentang kemampuan penanganan data BigQuery.
BigQuery mendukung beragam tipe data, dikategorikan sebagai:
Setiap tipe data memiliki ukuran penyimpanan logis yang ditentukan, yang memengaruhi kinerja kueri dan biaya. Misalnya, penyimpanan STRING bergantung pada panjang yang dikodekan UTF-8, sedangkan ARRAY<INT64> membutuhkan 8 byte per elemen. Memahami tipe-tipe ini membantu mengoptimalkan kueri dan mengelola biaya secara efisien.
Anda dapat melihat semua tipe data yang didukung pada tabel berikut.
Tipe data BigQuery. Gambar dari Dokumentasi Google Cloud.
Alasan ditanyakan: Untuk memastikan Anda memahami manfaat utama menggunakan BigQuery sebagai Data Warehouse.
Menggunakan layanan BigQuery menghadirkan lima manfaat utama dibandingkan solusi yang dikelola sendiri secara tradisional:
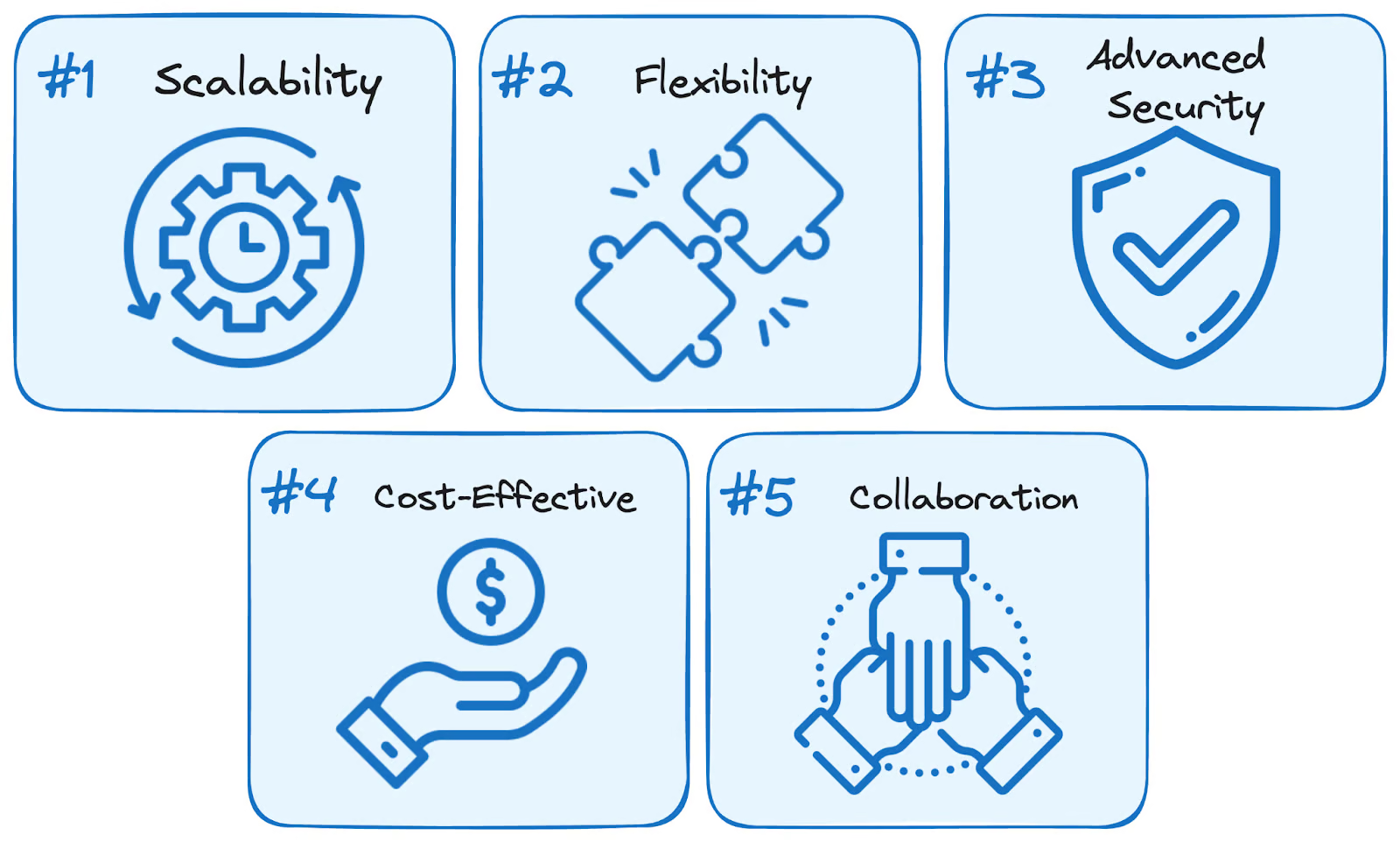
Keunggulan BigQuery. Gambar oleh Penulis.
Setelah Anda memahami dasar-dasar BigQuery, saatnya menyelami aspek teknis yang lebih sering dinilai pewawancara.
Pertanyaan-pertanyaan ini melampaui definisi dasar dan menguji kemampuan Anda mengoptimalkan kinerja, mengelola biaya, serta bekerja dengan fitur lanjutan seperti partisi, klastering, dan keamanan.
Alasan ditanyakan: Untuk menilai pengetahuan Anda tentang teknik pengorganisasian data dan dampaknya pada efisiensi kueri.
Partitioning di BigQuery adalah metode membagi tabel besar menjadi potongan-potongan yang lebih mudah dikelola berdasarkan kriteria tertentu seperti tanggal, waktu ingest, atau nilai integer. Dengan membagi data ke dalam partisi, BigQuery dapat membatasi jumlah data yang dipindai saat kueri, sehingga meningkatkan kinerja dan memangkas biaya secara signifikan.
Sebagai contoh, tabel terpartisi yang menyimpan data transaksi harian memungkinkan kueri memfilter rentang tanggal tertentu secara efisien alih-alih memindai seluruh himpunan data. Ini membuat partitioning sangat bermanfaat untuk analisis deret waktu dan beban kerja analitik skala besar.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang strategi pengorganisasian data yang mengoptimalkan efisiensi kueri dan biaya.
Clustering di BigQuery mengacu pada pengorganisasian data di dalam partisi berdasarkan nilai dari satu atau beberapa kolom yang ditentukan. Dengan mengelompokkan baris terkait melalui clustering, BigQuery mengurangi jumlah data yang dipindai, sehingga meningkatkan kinerja kueri dan menurunkan biaya pemrosesan secara keseluruhan.
Cara optimasi ini terbukti sangat efisien saat memfilter, menyortir, atau mengagregasi data berdasarkan kolom terklaster, di mana mesin kueri dapat melewati seluruh data yang tidak relevan alih-alih memindai penuh partisi. Clustering bekerja paling baik bila dipadukan dengan partitioning dan memberikan manfaat kinerja lebih besar saat bekerja dengan himpunan data besar.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang struktur data BigQuery dan kasus penggunaannya.
Di BigQuery, tabel adalah unit penyimpanan terstruktur yang secara fisik menampung data, sedangkan view adalah tabel virtual yang secara dinamis mengambil data berdasarkan kueri SQL yang telah ditentukan. Perbedaan utamanya adalah view tidak menyimpan data secara mandiri, namun berfungsi sebagai blok bangunan untuk menulis kueri besar atau menerapkan aturan keamanan seputar akses data dengan memberikan akses ke subset data tanpa menduplikasinya. View juga meningkatkan waktu eksekusi kueri dengan memungkinkan pengguna mengakses kembali data tanpa perlu memuat ulang atau menyusun ulang tabel, sehingga sangat berguna untuk analitik, abstraksi data, dan penegakan keamanan.
Jadi, sederhananya:
Alasan ditanyakan: Untuk memeriksa pengetahuan Anda tentang keamanan BigQuery beserta perlindungan data sensitif.
BigQuery menerapkan pendekatan berlapis terhadap keamanan data, dimulai dengan model aman yang dirancang untuk melindungi data di semua tingkat siklus hidup data.
Fitur keamanan bawaan ini membantu organisasi menjaga kerahasiaan, integritas, dan kepatuhan regulasi data.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang pergerakan data terotomatisasi dan integrasi di dalam BigQuery.
BigQuery Data Transfer Service (BQ DTS) mengotomatiskan dan menjadwalkan impor data dari berbagai sumber eksternal ke BigQuery, menghilangkan kebutuhan proses ETL manual. Layanan ini terintegrasi secara native dengan layanan Google seperti Google Ads, YouTube, dan Google Cloud Storage, serta aplikasi SaaS pihak ketiga.
Dengan memungkinkan transfer data otomatis dan terjadwal, BQ DTS memastikan data tetap mutakhir untuk analisis tanpa intervensi pengguna. Layanan ini sangat berguna bagi organisasi yang mengelola workflow ingest data berulang dalam skala besar, meningkatkan efisiensi dan mengurangi beban operasional.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang dukungan BigQuery terhadap data semi-terstruktur dan keunggulannya dibandingkan model relasional tradisional.
BigQuery mendukung nested dan repeated fields, sehingga penyimpanan dan pengkuerian data hierarkis atau berbasis array menjadi lebih efisien. Nested fields menggunakan tipe data STRUCT, memungkinkan sebuah kolom memiliki subkolom, mirip objek JSON.
Repeated fields berfungsi sebagai ARRAY, memungkinkan satu kolom menyimpan banyak nilai. Struktur-struktur ini membantu menghilangkan kebutuhan JOIN kompleks, meningkatkan kinerja kueri, dan membuat BigQuery sangat cocok untuk memproses data semi-terstruktur seperti log, aliran peristiwa, dan dataset ala NoSQL.
Alasan ditanyakan: Untuk menilai pengetahuan Anda dalam mengotomatiskan eksekusi kueri dan manajemen workflow di BigQuery.
BigQuery menyediakan berbagai metode untuk menjadwalkan dan mengotomatiskan job, memastikan tugas berulang berjalan tanpa intervensi manual.
Alat otomasi ini membantu merampingkan pipeline data, mengurangi beban kerja manual, dan memastikan pemrosesan data tepat waktu untuk analitik dan pelaporan.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang strategi pengorganisasian data di BigQuery dan dampaknya pada kinerja kueri serta efisiensi biaya.
Partitioning membagi tabel besar menjadi segmen-segmen lebih kecil, meningkatkan kinerja kueri dengan hanya memindai data yang relevan.
Berbasis waktu: Berdasarkan DATE, TIMESTAMP, DATETIME (mis., partisi sales_date harian).
Rentang Integer: Berdasarkan nilai INTEGER (mis., rentang user_id).
Waktu ingest: Berdasarkan timestamp pemuatan data (_PARTITIONDATE).
Paling cocok untuk data deret waktu dan mengurangi biaya kueri saat memfilter berdasarkan tanggal atau rentang numerik.
Clustering mengorganisasi data dalam sebuah tabel atau partisi dengan menyortirnya berdasarkan kolom terpilih, sehingga mempercepat kueri.
Paling cocok untuk memfilter dan mengagregasi berdasarkan kolom yang sering dikueri seperti wilayah atau user_id.
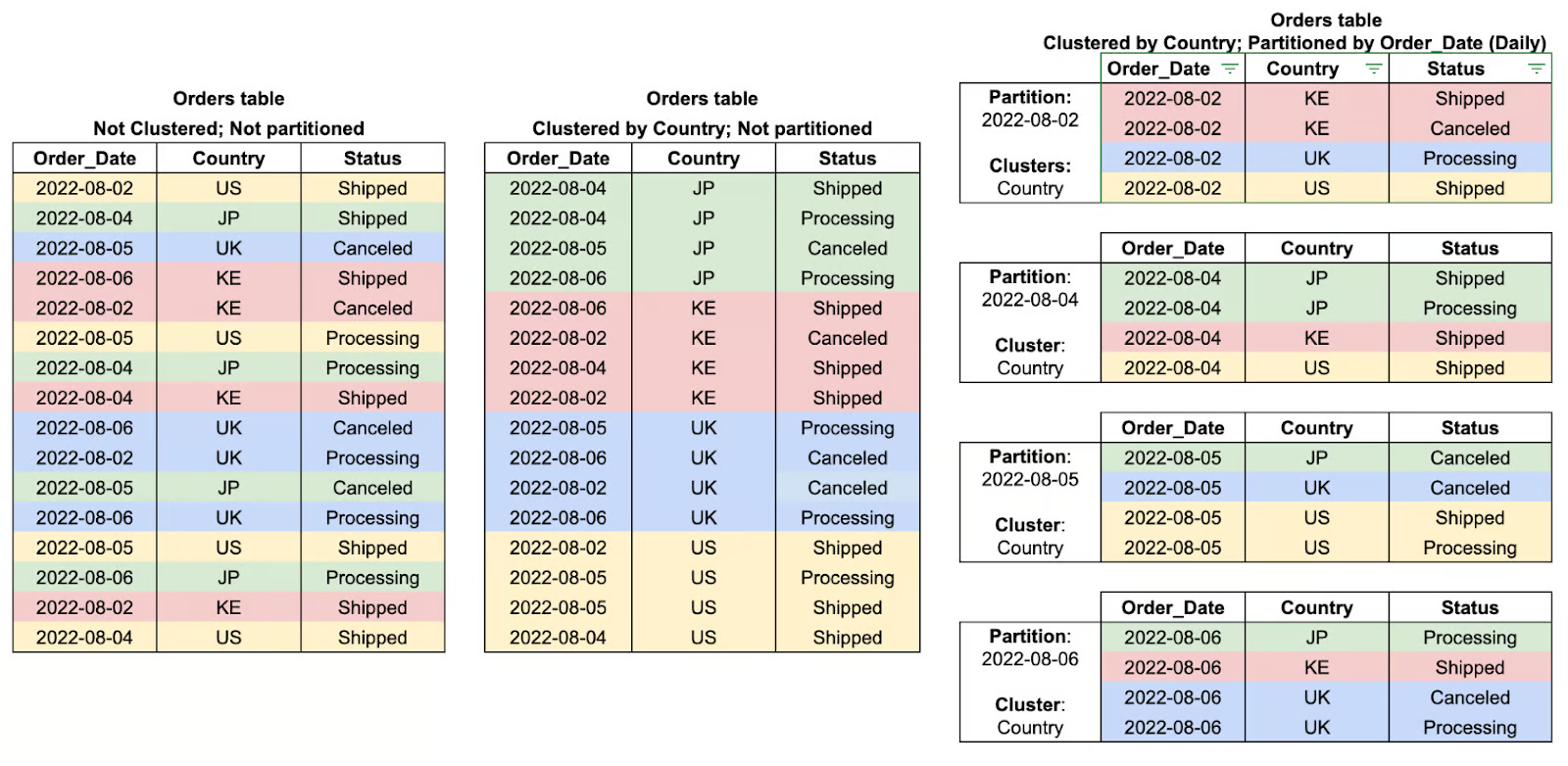
Contoh klaster dan partisi tabel. Gambar oleh Google Cloud.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang arsitektur serverless BigQuery dan bagaimana perbedaannya dari gudang data tradisional.
BigQuery memiliki arsitektur serverless yang sepenuhnya terkelola yang memisahkan penyimpanan dan komputasi, memungkinkan keduanya diskalakan secara independen sesuai permintaan. Berbeda dengan gudang data cloud tradisional atau sistem massively parallel processing (MPP) on-premises, pemisahan ini memberikan fleksibilitas, efisiensi biaya, dan ketersediaan tinggi tanpa mengharuskan pengguna mengelola infrastruktur. Mesin komputasi BigQuery didukung oleh Dremel, klaster multi-penyewa yang mengeksekusi kueri SQL secara efisien, sementara data disimpan di Colossus, sistem penyimpanan terdistribusi global Google. Komponen-komponen ini berkomunikasi melalui Jupiter, jaringan berskala petabit milik Google, yang memastikan transfer data sangat cepat. Seluruh sistem diorkestrasi oleh Borg, sistem manajemen klaster internal Google dan cikal bakal Kubernetes. Arsitektur ini memungkinkan pengguna menjalankan analitik berkinerja tinggi dan skalabel pada himpunan data masif tanpa perlu khawatir mengelola infrastruktur.
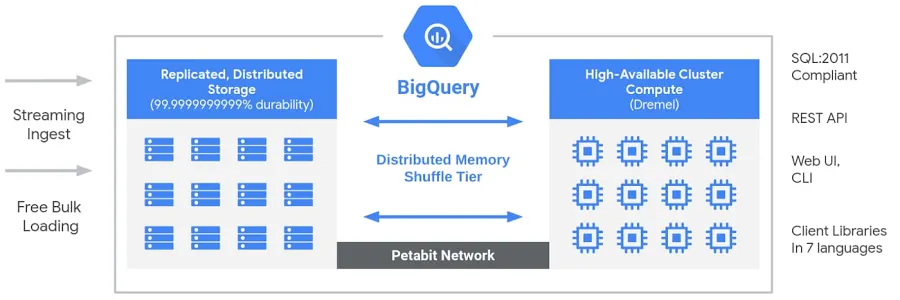
Arsitektur Big Query. Gambar oleh Google.
Alasan ditanyakan: Pertanyaan ini menilai pemahaman Anda tentang arsitektur BigQuery, khususnya bagaimana model penyimpanan dan komputasi yang terlepas meningkatkan skalabilitas, efisiensi biaya, dan kinerja.
BigQuery mengikuti arsitektur serverless yang sepenuhnya terkelola di mana penyimpanan dan komputasi benar-benar dipisahkan:
Manfaat utama dari pemisahan penyimpanan-komputasi:
Desain ini memungkinkan BigQuery memproses kueri berskala petabyte secara efisien sambil menjaga biaya tetap rendah, menjadikannya pilihan ideal untuk analitik berbasis cloud.
Fleksibilitas arsitektural ini krusial saat industri mengalihkan fokus ke daya komputasi masif. Seperti disampaikan dalam podcast DataFramed mengenai tren data 2025:
Sudah pasti ada taruhan yang diambil semua pemain besar. Mereka membangun lebih banyak komputasi, sehingga tahun depan mereka akan melakukan penskalaan melalui komputasi yang lebih besar. Lalu pertanyaannya, apakah ada lebih banyak data? Di sinilah menjadi lebih bernuansa. Dan saya pikir ini sebuah spektrum. Tidak hitam putih.
Jonathan Cornelissen, Co-founder & CEO of DataCamp
Alasan ditanyakan: Untuk menilai pengetahuan Anda tentang Dremel, mesin kueri dasar BigQuery, dan bagaimana model eksekusi kolumnar berbasis pohon memungkinkannya melakukan analitik data berkinerja tinggi.
Dremel adalah mesin eksekusi kueri terdistribusi yang menggerakkan BigQuery. Berbeda dengan basis data tradisional yang menggunakan pemrosesan berbasis baris, Dremel menggunakan format penyimpanan kolumnar dan model eksekusi kueri berbasis pohon untuk mengoptimalkan kecepatan dan efisiensi.
Bagaimana Dremel Memungkinkan Kueri Cepat:
Manfaat Utama Dremel:
Anda dapat mempelajari lebih lanjut tentang Dremel di dokumentasi resmi Google.
Alasan ditanyakan: Untuk menilai pemahaman Anda tentang strategi pemodelan data dan dampaknya pada kinerja kueri di basis data analitik.
Denormalisasi di BigQuery secara sengaja memperkenalkan redundansi dengan menggabungkan tabel dan menduplikasi data untuk mengoptimalkan kinerja kueri. Berbeda dengan normalisasi, yang meminimalkan redundansi melalui tabel-tabel kecil yang saling terkait, denormalisasi mengurangi kebutuhan JOIN kompleks, menghasilkan waktu baca yang lebih cepat. Pendekatan ini sangat berguna dalam data warehousing dan analitik, di mana operasi baca lebih sering daripada tulis. Namun, denormalisasi meningkatkan kebutuhan penyimpanan, itulah sebabnya BigQuery merekomendasikan penggunaan nested dan repeated fields untuk menstrukturkan data terdenormalisasi secara efisien sembari meminimalkan overhead penyimpanan.
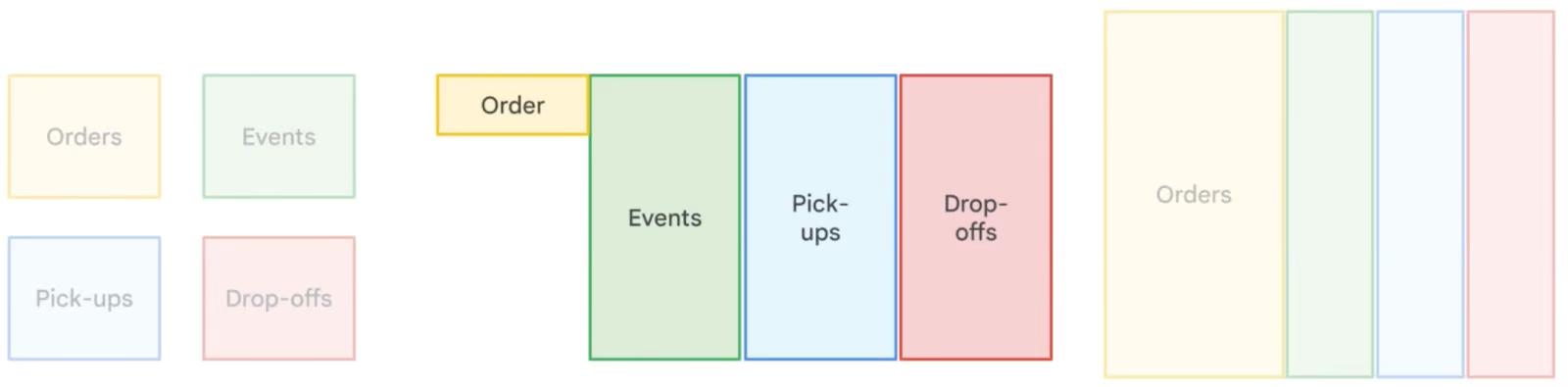
Perbandingan berbagai strategi normalisasi data. Gambar oleh Google Cloud.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
