
Courses
Hiểu về Điện toán đám mây
2 giờ
241.5K
Công nghệ kho dữ liệu gần đây đã được hợp nhất để trở nên dễ mở rộng hơn và ít tốn kém hơn nhờ sự phổ biến của các dịch vụ đám mây. Một trong những giải pháp phổ biến nhất là kho dữ liệu BigQuery của Google Cloud Platform.
Khảo sát Stack Overflow 2024 xác nhận mức độ phổ biến gia tăng của công cụ này, với tỷ lệ chấp nhận đạt 24,1% trong số người dùng đám mây trên toàn thế giới. Nhu cầu về chuyên môn BigQuery đã tăng đáng kể trong nhiều ngành, khiến việc nắm vững các nguyên lý cơ bản của nó trở thành yêu cầu nghề nghiệp bắt buộc đối với các chuyên gia dữ liệu.
Trong bài viết này, bạn sẽ tìm thấy tuyển tập một số câu hỏi về BigQuery thường được hỏi trong các buổi phỏng vấn tuyển dụng để giúp bạn sẵn sàng. Nếu bạn mới bắt đầu tìm hiểu về BigQuery, tôi khuyên bạn nên xem trước hướng dẫn về Data Warehousing trên GCP sau đây.
Biết các kiến thức cơ bản về BigQuery trước khi xử lý các chủ đề phức tạp là điều thiết yếu. Những câu hỏi này đánh giá mức độ nắm bắt các khái niệm cốt lõi, kiến trúc và chức năng của bạn. Nếu bạn chưa thể trả lời các câu hỏi sau, tôi khuyến khích bạn bắt đầu từ đầu bằng cách xem Hướng dẫn BigQuery cho người mới bắt đầu và đăng ký khóa học BigQuery nhập môn của chúng tôi.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về các kho dữ liệu hiện đại và ưu điểm của chúng so với cơ sở dữ liệu truyền thống.
BigQuery là kho dữ liệu hoàn toàn do Google Cloud quản lý, không máy chủ (serverless), được thiết kế cho phân tích dữ liệu quy mô lớn. Nó cho phép chạy các truy vấn SQL tốc độ cao trên tập dữ liệu khổng lồ mà không cần quản lý hạ tầng, giúp người dùng tập trung vào khai thác insight thay vì bảo trì.
Không giống các cơ sở dữ liệu quan hệ on-premises truyền thống, vốn thường lưu trữ theo hàng và bị giới hạn bởi phần cứng, BigQuery là hệ thống lưu trữ dạng cột gốc đám mây, cung cấp khả năng mở rộng gần như vô hạn. Kiến trúc phân tán và mô hình tính phí theo mức sử dụng giúp BigQuery xử lý khối lượng công việc phân tích hiệu quả hơn so với các cơ sở dữ liệu thông thường.
Vì sao hỏi câu này: Để kiểm tra kiến thức của bạn về cách tổ chức dữ liệu và cấu trúc của BigQuery.
Trong BigQuery, dataset được định nghĩa là vùng chứa cấp cao nhất dùng để tổ chức bảng, view và các tài nguyên khác. Điều này mở đường cho kiểm soát truy cập và định vị dữ liệu. Bằng cách cấu trúc dữ liệu hiệu quả, dataset giúp cải thiện hiệu năng truy vấn và quản lý truy cập, trở thành thành phần nền tảng trong kiến trúc của BigQuery.
Vì sao hỏi câu này: Để kiểm tra hiểu biết của bạn về các phương thức đưa dữ liệu vào.
BigQuery cung cấp nhiều phương thức nạp dữ liệu dành cho các mục đích khác nhau.
Với các quy trình ETL nâng cao, Google Cloud Dataflow và các công cụ pipeline khác giúp di chuyển dữ liệu liền mạch vào BigQuery. Lựa chọn phương thức nạp phù hợp phụ thuộc vào khối lượng dữ liệu, độ trễ và nhu cầu xử lý.
Vì sao hỏi câu này: Để kiểm tra hiểu biết của bạn về khả năng xử lý dữ liệu của BigQuery.
BigQuery hỗ trợ nhiều kiểu dữ liệu, phân loại như sau:
Mỗi kiểu dữ liệu có kích thước lưu trữ logic được xác định, ảnh hưởng đến hiệu năng truy vấn và chi phí. Ví dụ, lưu trữ STRING phụ thuộc vào độ dài mã hóa UTF-8, trong khi ARRAY<INT64> cần 8 byte mỗi phần tử. Hiểu rõ các kiểu này giúp tối ưu truy vấn và quản lý chi phí hiệu quả.
Bạn có thể xem tất cả các kiểu dữ liệu được hỗ trợ trong bảng sau.
Các kiểu dữ liệu BigQuery. Hình ảnh từ Tài liệu Google Cloud.
Vì sao hỏi câu này: Để đảm bảo bạn hiểu các điểm mạnh chính khi sử dụng BigQuery làm Data Warehouse.
Sử dụng dịch vụ BigQuery mang lại năm lợi ích chính so với các giải pháp tự quản lý truyền thống:
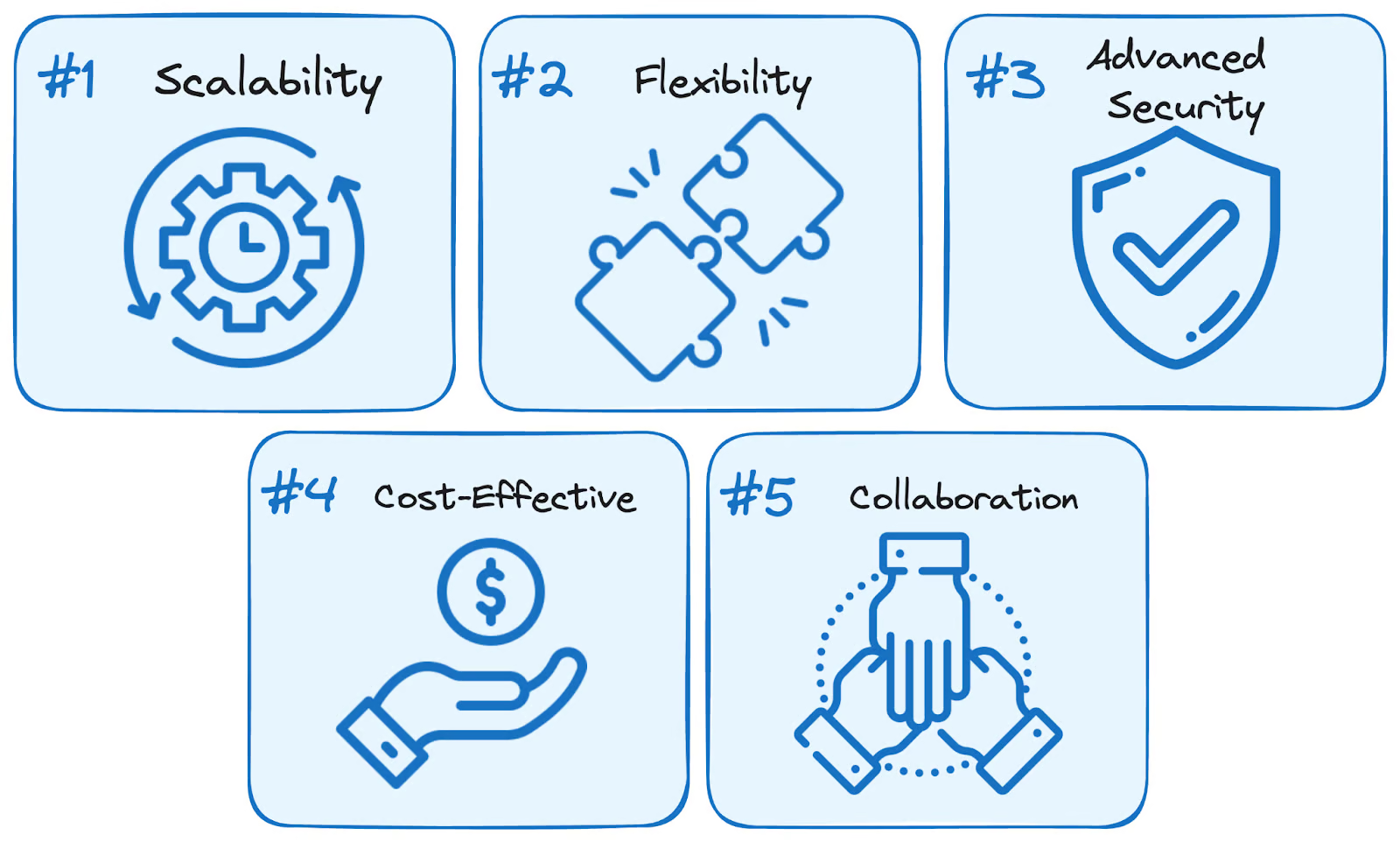
Ưu điểm của BigQuery. Hình minh họa của Tác giả.
Khi bạn đã nắm vững các nguyên lý cơ bản của BigQuery, đã đến lúc đi sâu vào các khía cạnh kỹ thuật hơn mà nhà tuyển dụng thường đánh giá.
Các câu hỏi này vượt ra ngoài định nghĩa cơ bản và kiểm tra khả năng tối ưu hiệu năng, quản lý chi phí, cũng như làm việc với các tính năng nâng cao như phân vùng, phân cụm và bảo mật.
Vì sao hỏi câu này: Để đánh giá kiến thức của bạn về kỹ thuật tổ chức dữ liệu và tác động của nó đến hiệu quả truy vấn.
Phân vùng trong BigQuery là phương pháp chia nhỏ các bảng lớn thành những phần dễ quản lý hơn dựa trên một tiêu chí nào đó như ngày, thời điểm nạp dữ liệu hoặc giá trị số nguyên. Nhờ phân đoạn dữ liệu thành các phân vùng, BigQuery có thể hạn chế lượng dữ liệu phải quét trong quá trình truy vấn, qua đó tăng tốc hiệu năng và giảm đáng kể chi phí.
Ví dụ, một bảng phân vùng lưu dữ liệu giao dịch hằng ngày cho phép truy vấn lọc theo khoảng ngày cụ thể một cách hiệu quả thay vì quét toàn bộ tập dữ liệu. Điều này đặc biệt hữu ích cho phân tích chuỗi thời gian và các khối công việc phân tích quy mô lớn.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về các chiến lược tổ chức dữ liệu nhằm tối ưu hiệu quả truy vấn và chi phí.
Phân cụm trong BigQuery là việc tổ chức dữ liệu bên trong các phân vùng dựa trên giá trị của một hoặc nhiều cột được chỉ định. Bằng cách nhóm các hàng có liên quan thông qua phân cụm, BigQuery giảm lượng dữ liệu phải quét, từ đó cải thiện hiệu năng truy vấn và giảm chi phí xử lý tổng thể.
Cách tối ưu này đặc biệt hiệu quả khi lọc, sắp xếp hoặc tổng hợp theo các cột được phân cụm, nơi công cụ truy vấn có thể bỏ qua hoàn toàn dữ liệu không liên quan thay vì quét toàn bộ phân vùng. Phân cụm hoạt động tốt nhất khi kết hợp với phân vùng và mang lại lợi ích hiệu năng lớn hơn khi làm việc với các tập dữ liệu lớn.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về các cấu trúc dữ liệu của BigQuery và trường hợp sử dụng của chúng.
Trong BigQuery, bảng là đơn vị lưu trữ có cấu trúc chứa dữ liệu thực, còn view là bảng ảo truy xuất dữ liệu động dựa trên một truy vấn SQL được định nghĩa sẵn. Khác biệt chính là view không tự chứa dữ liệu mà phục vụ như khối xây dựng để viết các truy vấn lớn hoặc áp dụng quy tắc bảo mật quanh quyền truy cập dữ liệu bằng cách cung cấp quyền vào một tập con dữ liệu mà không cần nhân bản. View cũng cải thiện thời gian thực thi truy vấn bằng cách cho phép người dùng truy cập lại dữ liệu mà không phải nạp lại hay tổ chức lại bảng, khiến chúng trở nên hữu ích cho phân tích, trừu tượng hóa dữ liệu và thực thi bảo mật.
Tóm lại:
Vì sao hỏi câu này: Để kiểm tra kiến thức của bạn về bảo mật BigQuery kết hợp với việc bảo vệ dữ liệu nhạy cảm.
BigQuery áp dụng cách tiếp cận nhiều lớp đối với bảo mật dữ liệu, bắt đầu bằng một mô hình bảo mật nhằm bảo vệ dữ liệu ở mọi giai đoạn của vòng đời dữ liệu.
Các tính năng bảo mật tích hợp này giúp tổ chức duy trì tính bảo mật, toàn vẹn và tuân thủ quy định cho dữ liệu.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về tự động hóa di chuyển và tích hợp dữ liệu trong BigQuery.
BigQuery Data Transfer Service (BQ DTS) tự động hóa và lập lịch nhập dữ liệu từ nhiều nguồn bên ngoài vào BigQuery, loại bỏ nhu cầu về các quy trình ETL thủ công. Nó tích hợp gốc với các dịch vụ Google như Google Ads, YouTube và Google Cloud Storage, cũng như các ứng dụng SaaS của bên thứ ba.
Bằng cách cho phép chuyển dữ liệu tự động theo lịch, BQ DTS đảm bảo dữ liệu luôn được cập nhật phục vụ phân tích mà không cần can thiệp của người dùng. Dịch vụ này đặc biệt hữu ích cho các tổ chức quản lý quy trình nạp dữ liệu định kỳ ở quy mô lớn, nâng cao hiệu quả và giảm chi phí vận hành.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về hỗ trợ dữ liệu bán cấu trúc của BigQuery và ưu điểm so với mô hình quan hệ truyền thống.
BigQuery cho phép sử dụng trường lồng nhau và trường lặp, giúp lưu trữ và truy vấn dữ liệu dạng phân cấp hoặc mảng hiệu quả hơn. Trường lồng nhau dùng kiểu dữ liệu STRUCT, cho phép một cột chứa các trường con tương tự đối tượng JSON.
Trường lặp hoạt động như ARRAY, cho phép một cột lưu nhiều giá trị. Các cấu trúc này giúp loại bỏ nhu cầu JOIN phức tạp, cải thiện hiệu năng truy vấn và khiến BigQuery đặc biệt phù hợp để xử lý dữ liệu bán cấu trúc như log, luồng sự kiện và các tập dữ liệu tương tự NoSQL.
Vì sao hỏi câu này: Để đánh giá kiến thức của bạn về tự động hóa thực thi truy vấn và quản lý luồng công việc trong BigQuery.
BigQuery cung cấp nhiều phương thức để lập lịch và tự động hóa các job, đảm bảo các tác vụ định kỳ chạy mà không cần can thiệp thủ công.
Các công cụ tự động hóa này giúp hợp lý hóa pipeline dữ liệu, giảm khối lượng công việc thủ công và đảm bảo xử lý dữ liệu kịp thời cho phân tích và báo cáo.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về các chiến lược tổ chức dữ liệu trong BigQuery và tác động của chúng đến hiệu năng truy vấn và hiệu quả chi phí.
Phân vùng tách các bảng lớn thành những phần nhỏ hơn, cải thiện hiệu năng truy vấn bằng cách chỉ quét dữ liệu liên quan.
Theo thời gian: Theo DATE, TIMESTAMP, DATETIME (ví dụ: phân vùng sales_date hằng ngày).
Theo khoảng số nguyên: Theo giá trị INTEGER (ví dụ: khoảng user_id).
Theo thời điểm nạp dữ liệu: Theo timestamp nạp dữ liệu (_PARTITIONDATE).
Phù hợp nhất cho dữ liệu chuỗi thời gian và giảm chi phí truy vấn khi lọc theo ngày hoặc các khoảng số.
Phân cụm sắp xếp dữ liệu trong bảng hoặc trong từng phân vùng theo các cột được chọn, từ đó tăng tốc truy vấn.
Phù hợp nhất khi lọc và tổng hợp theo các trường thường xuyên được truy vấn như region hoặc user_id.
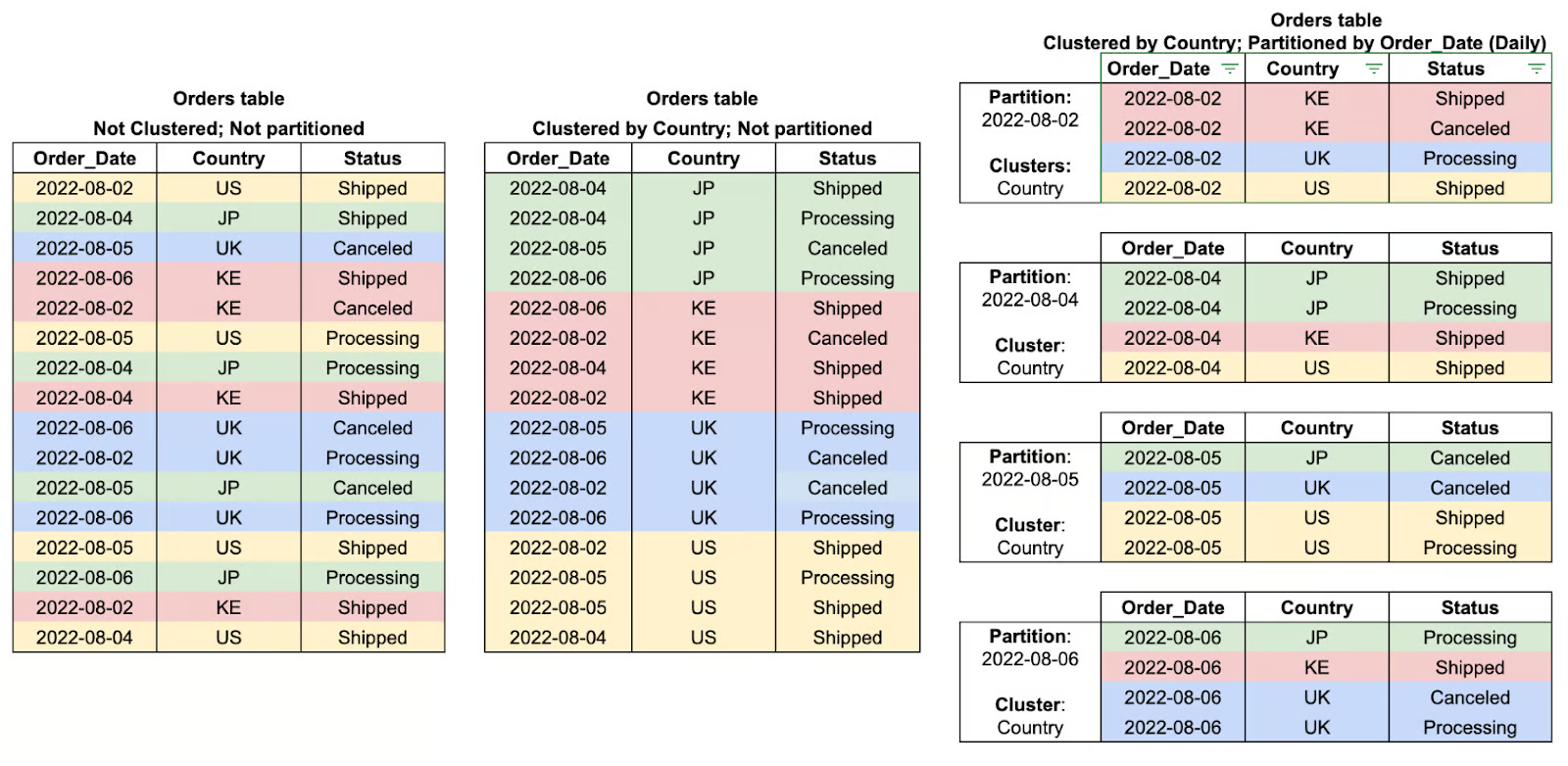
Ví dụ về phân cụm và phân vùng bảng. Hình ảnh bởi Google Cloud.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về kiến trúc không máy chủ (serverless) của BigQuery và cách nó khác với các kho dữ liệu truyền thống.
BigQuery có kiến trúc serverless, được quản lý hoàn toàn, tách rời lưu trữ và tính toán, cho phép chúng mở rộng độc lập theo nhu cầu. Không giống các kho dữ liệu đám mây truyền thống hay hệ thống MPP (xử lý song song khối lượng lớn) on-premises, sự tách biệt này mang lại tính linh hoạt, hiệu quả chi phí và tính sẵn sàng cao mà không yêu cầu người dùng quản lý hạ tầng. Công cụ tính toán của BigQuery được vận hành bởi Dremel, một cụm đa thuê (multi-tenant) thực thi truy vấn SQL hiệu quả, trong khi dữ liệu được lưu trên Colossus, hệ thống lưu trữ phân tán toàn cầu của Google. Các thành phần này giao tiếp qua Jupiter, mạng ở quy mô petabit của Google, đảm bảo truyền dữ liệu siêu nhanh. Toàn bộ hệ thống được điều phối bởi Borg, hệ thống quản lý cụm nội bộ của Google và là tiền thân của Kubernetes. Kiến trúc này cho phép người dùng chạy phân tích hiệu năng cao, khả năng mở rộng lớn trên các tập dữ liệu khổng lồ mà không phải bận tâm quản lý hạ tầng.
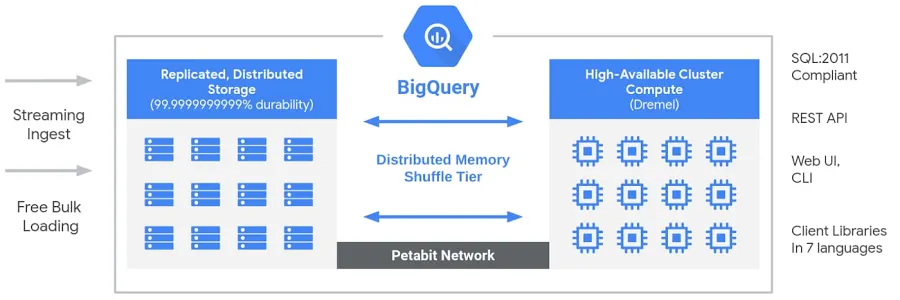
Kiến trúc Big Query. Hình ảnh bởi Google.
Vì sao hỏi câu này: Câu hỏi này đánh giá hiểu biết của bạn về kiến trúc BigQuery, cụ thể là cách mô hình tách rời lưu trữ và tính toán cải thiện khả năng mở rộng, hiệu quả chi phí và hiệu năng.
BigQuery tuân theo kiến trúc serverless, được quản lý hoàn toàn, trong đó lưu trữ và tính toán hoàn toàn tách biệt:
Lợi ích chính của việc tách lưu trữ - tính toán:
Thiết kế này cho phép BigQuery xử lý các truy vấn ở quy mô petabyte hiệu quả trong khi vẫn giữ chi phí thấp, trở thành lựa chọn lý tưởng cho phân tích trên đám mây.
Tính linh hoạt kiến trúc này đặc biệt quan trọng khi ngành đang chuyển trọng tâm sang sức mạnh tính toán khổng lồ. Như được đề cập trong podcast DataFramed về xu hướng dữ liệu năm 2025:
Chắc chắn có một canh bạc mà tất cả các ông lớn đều đặt cược. Họ đang xây dựng nhiều năng lực tính toán hơn, và vì vậy họ sẽ mở rộng quy mô thông qua việc tăng cường tính toán trong năm tới. Và rồi câu hỏi là, ừ, liệu có nhiều dữ liệu hơn không? Và đây là chỗ trở nên tinh tế hơn. Tôi nghĩ đó là một phổ liên tục. Không phải trắng đen rạch ròi.
Jonathan Cornelissen, Co-founder & CEO of DataCamp
Vì sao hỏi câu này: Để đánh giá kiến thức của bạn về Dremel, động cơ truy vấn nền tảng của BigQuery, và cách mô hình thực thi dạng cây, theo cột của nó cho phép phân tích dữ liệu hiệu năng cao.
Dremel là công cụ thực thi truy vấn phân tán cung cấp sức mạnh cho BigQuery. Không giống các cơ sở dữ liệu truyền thống sử dụng xử lý theo hàng, Dremel áp dụng định dạng lưu trữ theo cột và mô hình thực thi truy vấn dạng cây để tối ưu tốc độ và hiệu quả.
Dremel tăng tốc truy vấn bằng cách:
Lợi ích chính của Dremel:
Bạn có thể tìm hiểu thêm về Dremel trong tài liệu chính thức của Google.
Vì sao hỏi câu này: Để đánh giá hiểu biết của bạn về chiến lược mô hình dữ liệu và tác động của chúng đến hiệu năng truy vấn trong các cơ sở dữ liệu phân tích.
Phi chuẩn hóa trong BigQuery cố ý đưa vào tính dư thừa bằng cách gộp bảng và nhân bản dữ liệu để tối ưu hiệu năng truy vấn. Không giống chuẩn hóa, vốn giảm thiểu dư thừa bằng các bảng nhỏ có quan hệ, phi chuẩn hóa giảm nhu cầu JOIN phức tạp, dẫn đến thời gian đọc nhanh hơn. Cách tiếp cận này đặc biệt hữu ích trong kho dữ liệu và phân tích, nơi thao tác đọc nhiều hơn ghi. Tuy nhiên, phi chuẩn hóa làm tăng nhu cầu lưu trữ, vì vậy BigQuery khuyến nghị dùng trường lồng nhau và trường lặp để cấu trúc dữ liệu phi chuẩn hóa hiệu quả trong khi tối thiểu hóa chi phí lưu trữ.
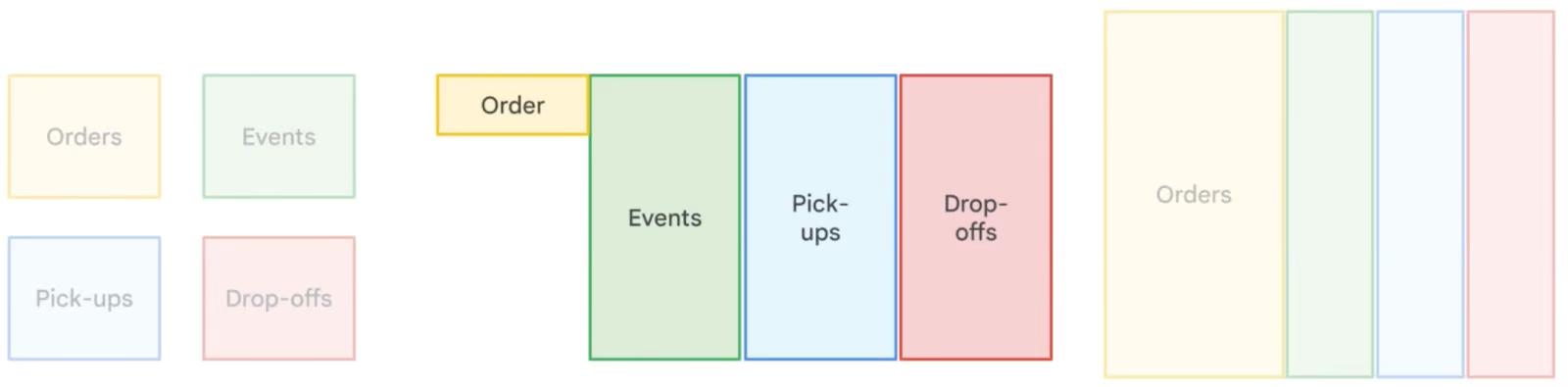
So sánh các chiến lược chuẩn hóa dữ liệu khác nhau. Hình ảnh bởi Google Cloud.
Học cùng DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút