Cursus
Machine Learning met PySpark
4 Hr
29.8K
Deze machine-learningprojecten voor beginners draaien om gestructureerde, tabelvormige data. Je past skills toe als data opschonen, verwerken en visualiseren voor analyse en gebruikt het scikit-learn-framework om machine-learningmodellen te trainen en te valideren.
Wil je eerst de basisconcepten van machine learning leren? We hebben een no-code Understanding Machine Learning-cursus. Bekijk ook onze AI-projecten als je juist die skills wilt verbeteren.
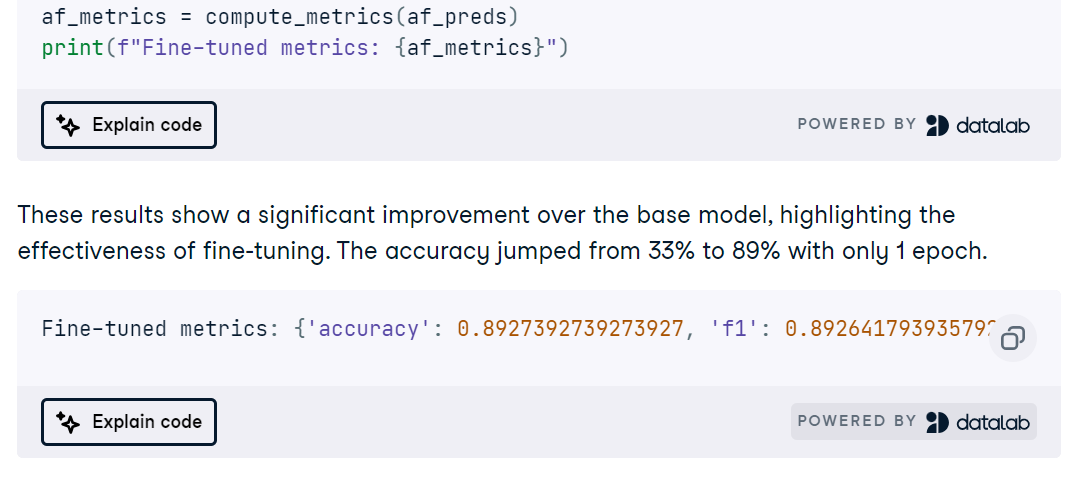
In het Predict Energy Consumption-project gebruik je regressie en machine-learningmodellen om het dagelijkse stroomverbruik te voorspellen op basis van temporele factoren zoals tijdstip en temperatuur. Het doel is patronen te ontdekken die het energiegebruik kunnen optimaliseren, om zo efficiency te verbeteren en kosten te verlagen. Dit is vooral belangrijk voor nutsbedrijven en organisaties die operationele kosten willen drukken, energiebesparing willen stimuleren en hun middelen duurzamer willen beheren.
Predict Energy Consumption is een begeleid project, maar je kunt dezelfde doelen nastreven op een andere dataset, zoals Seouls vraag naar deelfietsen. Werken met een volledig nieuwe dataset helpt bij het debuggen van code en scherpt je probleemoplossend vermogen.
In het From Data to Dollars - Predicting Insurance Charges-project kruip je in de huid van data scientist bij een zorgverzekeraar. Je bouwt een voorspellend model om verzekeringskosten te schatten op basis van eigenschappen van de klant, zoals leeftijd en gezondheidsfactoren. Dit project is een praktische toepassing van machine learning in business: het maakt nauwkeuriger prijzen mogelijk en helpt bedrijven risico te beheren en gepersonaliseerde prijsstrategieën te bieden.
Predicting Insurance Charges is een begeleid project. Je kunt het resultaat repliceren op een andere dataset, zoals de Hotel Booking Demand-dataset. Daarmee kun je voorspellen of een klant een boeking annuleert of niet.
In het Predicting Credit Card Approvals-project bouw je een automatische applicatie voor creditcardtoekenning met behulp van hyperparameteroptimalisatie en logistische regressie.
Je past skills toe als omgaan met missende waarden, verwerken van categorische features, features schalen, omgaan met onevenwichtige data en automatische hyperparameteroptimalisatie met GridCV. Dit project daagt je uit voorbij simpele, schone data.

Afbeelding door auteur
Predicting Credit Card Approvals is een begeleid project. Je kunt het resultaat repliceren op een andere dataset, zoals de Loan Data van LendingClub.com. Daarmee kun je een automatische voorspeller voor leningtoekenning bouwen.
Je kunt een project opzetten om wijnkwaliteit te voorspellen met een dataset met fysisch-chemische wijn-eigenschappen, zoals alcoholpercentage, zuurgraad en suikergehalte. Met classificatiemodellen, zoals logistische regressie in scikit-learn, kun je wijnen indelen op een schaal van 1–10.
Dit project is belangrijk voor sectoren die betrokken zijn bij wijnproductie en kwaliteitscontrole, omdat het hen in staat stelt de kwaliteit consistent te monitoren en te voorspellen en zo productexcellentie te borgen.
In het Predictive Modeling for Agriculture Data Science Project bouw je een eenvoudig aanbevelingssysteem voor gewassen met supervised machine learning en featureselectie. Je werkt met vier essentiële bodemattributen: stikstof, fosfor, kalium en pH. Je krijgt een realistische beperking: de boer kan er maar één meten. Jouw taak is om te bepalen welke enkele feature de beste voorspeller is voor het juiste gewas en vervolgens een lichtgewicht classifier te trainen die die aanbeveling betrouwbaar kan doen.
Je oefent praktische skills zoals omgaan met missende waarden, labels encoden, features schalen, modellen evalueren en vooral twee technieken voor featureselectie toepassen en vergelijken om bodemmetingen te rangschikken.
Store Sales is een Kaggle-competitie voor beginners waarin deelnemers verschillende tijdreeksmodellen trainen om hun score op het leaderboard te verbeteren. In dit project krijg je winkelverkoopdata, die je opschoont, waarna je uitgebreide tijdreeksanalyse, feature scaling en training van een multivariate tijdreeks doet.
Om je score op het leaderboard te verbeteren kun je ensembling gebruiken, zoals Bagging en Voting Regressors.
Afbeelding van Kaggle
Store Sales is een Kaggle-gebaseerd project waarbij je de notebooks van andere deelnemers kunt bekijken.
Wil je tijdreeksvoorspellen beter begrijpen? Pas je skill dan toe op de Stock Exchange-dataset en gebruik Facebook Prophet om een univariaat tijdreeksvoorspellingsmodel te trainen.
Deze projecten voor gevorderde beginners richten zich op datapreprocessing en het trainen van modellen voor gestructureerde en ongestructureerde datasets. Leer de dataset opschonen, verwerken en verrijken met diverse statistische tools.
Het Reveal Categories Found in Data-project helpt je klantfeedback te verkennen met clustering en natural language processing (NLP). Je organiseert reviews uit de Google Play Store in duidelijke categorieën met K-means-clustering. De rode draden in klantfeedback begrijpen is cruciaal voor productteams om pijnpunten aan te pakken, features te verbeteren en met actiegerichte inzichten de gebruikerstevredenheid te verhogen.
Probeer het resultaat te repliceren op een andere dataset, zoals de Netflix Movie-dataset.
In het Word Frequency in Moby Dick-project scrape je de tekst van Herman Melvilles Moby Dick en analyseer je de woordfrequentie met de nltk-bibliotheek van Python. Dit project introduceert kerntechnieken uit NLP en helpt je te begrijpen hoe veelgebruikte woorden patronen in de tekst onthullen. Een mooi project voor literatuurliefhebbers, historici of onderzoekers die geïnteresseerd zijn in text mining en linguïstische analyse.
In het Facial Recognition with Supervised Learning-project bouw je een gezichtsherkenningsmodel met supervised learning-technieken in Python en scikit-learn. Het model onderscheidt beelden van Arnold Schwarzenegger en anderen. Dit project is relevant in het groeiende veld van gezichtsherkenning, met toepassingen in security, authenticatiesystemen en zelfs social media, waar gezichtsdetectie vaak wordt gebruikt.
Bouw een voorspeller voor boekpopulariteit voor een online boekwinkel door gemengde data, zoals tekst (bijv. boektitels en beschrijvingen) en numerieke data (bijv. beoordelingen en aantallen), om te zetten in effectieve features. Je doorloopt de volledige machine-learningworkflow: snelle EDA (exploratieve data-analyse), datatypes corrigeren, zowel tekst- als numerieke variabelen transformeren en een model fine-tunen voor maximale nauwkeurigheid.
Je leert hoe je rommelige, multiformaat data beheert en resultaten evalueert met een schone, herbruikbare pipeline. Aan het eind kun je dezelfde aanpak toepassen op elk catalogus, van je eigen leeslijst tot publieke datasets, om potentiële bestsellers te voorspellen en aanbevelingssystemen te versterken.
In het Clustering Antarctic Penguin Species-project gebruik je unsupervised learning om natuurlijke groepen pinguïns te ontdekken zonder labels. Je maakt een dataset in Palmer Penguins-stijl schoon, gaat om met missende waarden, schaalt numerieke features zoals snavellengte, snaveldiepte, vleugellengte en lichaamsmassa, en encodeert desgewenst eenvoudige categorische variabelen zoals eiland of geslacht voordat je K-means-clustering toepast.
Vervolgens kies je het aantal clusters met elbow- en silhouette-scores, visualiseer je de structuur met PCA en vergelijk je clusters met bekende soorten als snelle sanitycheck.
In het Taxi Route Optimization with Reinforcement Learning-project train je een Q-learning-agent om de Taxi-v3 Gymnasium-omgeving op te lossen door efficiënte ophaal- en afzetroutes te leren. Je bouwt een staat–actie-waardetabel, balanceert exploratie en exploitatie met een epsilon-greedy policy, en stelt kernhyperparameters af zoals learning rate, discontovoet en epsilonverval om sneller te convergeren.

Daarna evalueer je de performance met gemiddelde beloning per episode en stappen tot voltooiing, visualiseer je de leercurve en test je het getrainde beleid op ongeziene episodes.
Gebruik de Wisconsin Breast Cancer-dataset om te voorspellen of een tumor kwaadaardig of goedaardig is. De dataset bevat details over tumorkenmerken, zoals textuur, omtrek en oppervlakte. Je doel is een classificatiemodel te bouwen dat op basis van deze kenmerken een diagnose voorspelt.
Dit project is essentieel in zorgtoepassingen: het levert waardevolle inzichten op in medische data-analyse en draagt bij aan de ontwikkeling van diagnostische tools die kunnen helpen bij vroege kankerdetectie.
In het Speech Emotion Recognition with Librosa-project verwerk je geluidsbestanden met Librosa, soundfile en sklearn voor de MLPClassifier om emotie uit audio te herkennen.
Je laadt en verwerkt audiobestanden, doet feature-extractie en traint het Multi-Layer Perceptron-classificatiemodel. Het project leert je de basis van audiobewerking, zodat je kunt doorgroeien naar het trainen van een deep-learningmodel voor betere nauwkeurigheid.
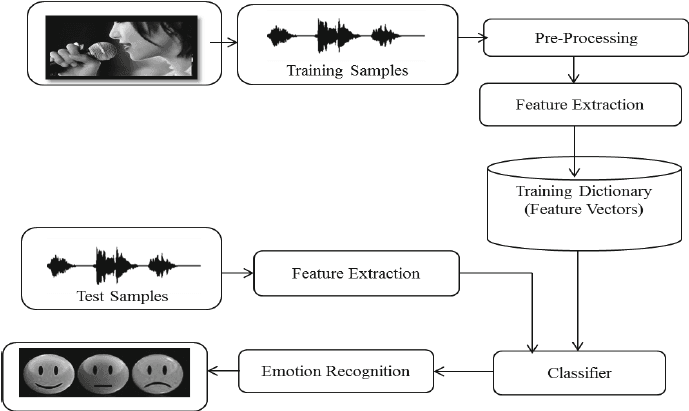
Afbeelding van researchgate.net
Deze geavanceerde projecten richten zich op het bouwen en trainen van deep-learningmodellen en het verwerken van ongestructureerde datasets. Je traint convolutionele neurale netwerken, gated recurrent units, finetunet large language models en reinforcement-learningmodellen.
In het Service Desk Ticket Classification with Deep Learning-project bouw je in PyTorch een tekstclassifier die inkomende tickets automatisch naar de juiste categorie routeert. Je schoonmaakt en tokenized tekst, maakt train- en validatiesets, zet tickets om in vectorrepresentaties en traint een compact neuraal model terwijl je batchgrootte, learning rate en regularisatie afstemt voor stabiele convergentie.
Vervolgens evalueer je met accuracy en gewogen F1, bekijk je een confusion matrix om verkeerd gelabelde of overlappende categorieën te spotten en pas je technieken toe tegen klasonbalans, zoals weighted loss.
In het Build Rick Sanchez Bot Using Transformers-project gebruik je DialoGPT en de Hugging Face Transformer-bibliotheek om je eigen AI-chatbot te bouwen.
Je verwerkt en transformeert je data, bouwt en finetunet Microsofts Large-scale Pretrained Response Generation Model (DialoGPT) op de Rick and Morty-dialoogdataset. Je kunt ook een eenvoudige Gradio-app maken om je model realtime te testen: Rick & Morty Block Party.
Het Building an E-Commerce Clothing Classifier Model with Keras-project draait om beeldclassificatie in een e-commercesetting. Je gebruikt Keras om een machine-learningmodel te bouwen dat kleding automatisch classificeert op basis van afbeeldingen. Dit verbetert de shopervaring doordat klanten sneller producten vinden en stroomlijnt voorraadbeheer. Nauwkeurige classificatie ondersteunt ook gepersonaliseerde aanbevelingen, wat betrokkenheid en verkoop verhoogt.
In het Detect Traffic Signs with Deep Learning-project gebruik je Keras om een deep-learningmodel te ontwikkelen dat verkeersborden, zoals stopborden en verkeerslichten, kan detecteren. Deze technologie is cruciaal voor autonome voertuigen, waar snelle en accurate herkenning van signalen essentieel is voor veilige navigatie. Dit project legt de basis voor geavanceerdere, veilige en betrouwbare zelfrijdende systemen.
In het Building a Demand Forecasting Model-project gebruik je PySpark om op schaal de vraag naar e-commerceproducten te voorspellen. Je laadt transactiegegevens, maakt tijdgebaseerde features zoals lags en rollende gemiddelden, splitst op tijd voor eerlijke evaluatie en traint een baseline naast een leermodel zoals Gradient-Boosted Trees of Random Forest om trends en seizoenspatronen te vangen.
Daarna evalueer je met MAE, RMSE en MAPE, vergelijk je met de baseline en analyseer je fouten per SKU en tijdvenster om bias en volatiliteit te ontdekken.
In het Predicting Temperature in London-project voer je een gestructureerd ML-experiment uit om de gemiddelde dagtemperatuur te voorspellen op basis van historische weersdata. Je laadt en schoonmaakt de dataset, maakt tijdsgevoelige splits, ontwerpt features zoals rollende gemiddelden en vertraagde waarden en traint verschillende kandidaatmodellen met scikit-learn.
Vervolgens orkestreer je de workflow met herbruikbare functies en track je alles in MLflow, waarbij je parameters, metrics en artifacts logt om runs te vergelijken.
Connect X is een simulatiecompetitie van Kaggle. Bouw een RL-agent (reinforcement learning) om te concurreren met andere deelnemers.
Je leert eerst hoe het spel werkt en maakt een simpele werkende agent als baseline. Daarna ga je experimenteren met verschillende RL-algoritmen en modelarchitecturen. Je kunt bijvoorbeeld een model bouwen met Deep Q-learning of het Proximal Policy Optimization-algoritme.
Voor je afstudeerproject besteed je flink wat tijd aan een unieke oplossing. Je onderzoekt meerdere modelarchitecturen, gebruikt verschillende machine-learningframeworks om datasets te normaliseren en te verrijken, doorgrondt de wiskunde achter het proces en schrijft een thesis op basis van je resultaten.
In het Multi-Lingual ASR-model finetune je het Wave2Vec XLS-R-model met Turkse audio en transcripties om een systeem voor automatische spraakherkenning te bouwen.
Eerst verken je de audiobestanden en de tekstdataset, vervolgens gebruik je een tokenizer, extraheer je features en verwerk je de audiobestanden. Daarna maak je een trainer en WER-functie, laad je pretrained modellen, stem je hyperparameters af en train en evalueer je het model.
Je kunt het Hugging Face-platform gebruiken om modelgewichten op te slaan en webapps te publiceren die spraak realtime transcriberen: Streaming Urdu Asr.
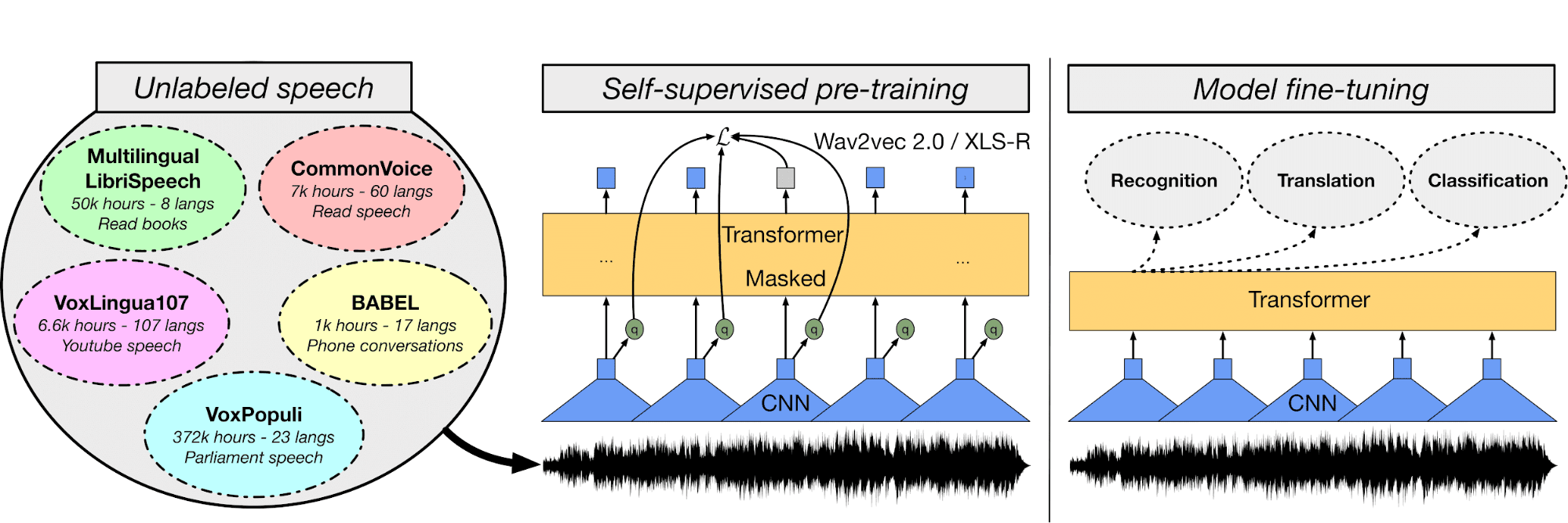
Afbeelding van huggingface.co
In het One Shot Face Stylization-project kun je het model aanpassen om de resultaten te verbeteren of JoJoGAN finetunen op een nieuwe dataset om je eigen stylisatie-app te maken.
Het gebruikt de oorspronkelijke afbeelding om een nieuw beeld te genereren via GAN-inversie en het finetunen van een voorgetrainde StyleGAN. Je verdiept je in verschillende generative adversarial network-architecturen. Daarna begin je met het verzamelen van een gepaard dataset om een stijl naar keuze te creëren.
Vervolgens experimenteer je met de nieuwe architectuur, met hulp van een voorbeeldoplossing van de vorige versie van StyleGAN, om realistische kunst te produceren.
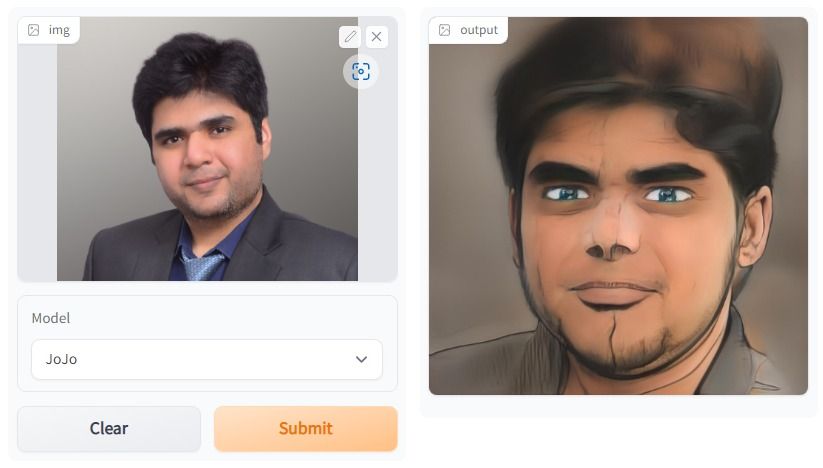
Afbeelding gemaakt met JoJoGAN
In het H&M Personalized Fashion Recommendations-project bouw je productaanbevelingen op basis van eerdere transacties, klantgegevens en productmetadata.
Het project test je NLP-, CV- (computer vision) en deep-learningskills. In de eerste weken verken je de data en hoe je verschillende features kunt gebruiken om tot een baseline te komen.
Bouw daarna een eenvoudig model dat alleen de tekst- en categorische features gebruikt om aanbevelingen te voorspellen. Ga vervolgens verder met het combineren van NLP en CV om je score op het leaderboard te verbeteren. Je kunt je begrip van het probleem ook vergroten door communitydiscussies en code te bestuderen.

Afbeelding van H&M EDA FIRST LOOK
In het Analyzing Customer Support Calls-project bouw je een end-to-endpipeline die ruwe audio omzet in inzichten. Je transcribeert gesprekken met een ASR-model, maakt tekst schoon en segmenteert, voert sentimentanalyse uit en extraheert entiteiten zoals producten, abonnementen, locaties en namen. Je indexeert transcripties ook met embeddings om snelle semantische zoekopdrachten mogelijk te maken.
Daarna evalueer je de transcriptiekwaliteit en modelperformance, cluster je thema’s om veelvoorkomende aanleidingen te onthullen en licht je zaken uit zoals pieken in negatief sentiment of escalatiezoekwoorden.
In het Monitoring A Financial Fraud Detection Model-project werk je als post-deployment data scientist voor een Britse bank en diagnoseer je waarom een live fraudemodel achteruitgaat. Je laadt productievoorspellingen en -uitkomsten, trackt kernmetrics zoals precision, recall, PR-AUC en calibratie en visualiseert performance door de tijd om degradatie te spotten. Je segmenteert ook naar kanaal, regio en klantsegment om te vinden waar false positives of false negatives geconcentreerd zijn.
Vervolgens test je op data- en conceptdrift met distributiechecks en stabiliteitsindices, inspecteer je verschuivingen in feature-importance en gebruik je explainabilitytools om huidig versus baselinegedrag te vergelijken.
In het MuZero for Atari 2600-project bouw, train en valideer je een reinforcement-learningagent met het MuZero-algoritme voor Atari 2600-games. Lees de tutorial om het MuZero-algoritme beter te begrijpen.
Het doel is om een nieuwe of aangepaste architectuur te bouwen die de score op een wereldwijde ranglijst verbetert. Het kost meer dan drie maanden om te begrijpen hoe het algoritme werkt in reinforcement learning.
Dit project is wiskunde-intensief en vereist Pythonexpertise. Je kunt voorgestelde oplossingen vinden, maar om de top te halen moet je je eigen oplossing bouwen.
Het MLOps End-To-End Machine Learning-project is belangrijk om bij topbedrijven aan de slag te gaan. Recruiters zoeken tegenwoordig ML-engineers die end-to-endsystemen kunnen bouwen met MLOps-tools, data-orchestratie en cloud computing.
In dit project bouw en deploy je een locatie-beeldclassifier met TensorFlow, Streamlit, Docker, Kubernetes, Cloud Build, GitHub en Google Cloud. Het hoofddoel is het automatiseren van het bouwen en deployen van machine-learningmodellen naar productie met CI/CD. Lees ter begeleiding de tutorial Machine Learning, Pipelines, Deployment en MLOps.
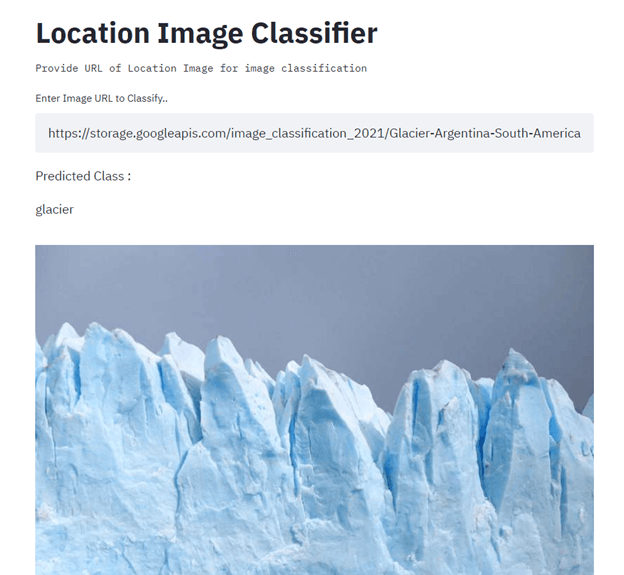
Afbeelding van Senthil E
Om je machine-learningportfolio te bouwen, heb je projecten nodig die opvallen. Laat een hiring manager of recruiter zien dat je in meerdere talen kunt coderen, verschillende ML-frameworks begrijpt, unieke problemen met ML kunt oplossen en het end-to-end-ecosysteem beheerst.
In het Fine-Tuning GPT-OSS-project installeer je dependencies, laad je het model en de tokenizer, definieer je een duidelijke promptstijl met het Harmony Python-pakket en voer je een snelle baseline-inference uit om te checken of alles end-to-end werkt.
Daarna bereid je een medische Q&A-dataset voor met Harmony-opmaak, configureer je training en finetune je het model, gevolgd door een evaluatie na het finetunen om verbeteringen te meten.
In het Fine-Tuning MedGemma on a Brain MRI Dataset-project pas je het MedGemma 4B-multimodale model aan, plus de SigLIP-encoder en een medisch getunede LLM, om MRI-scans van de hersenen te classificeren. Je richt de omgeving in op RunPod, installeert de vereiste Pythonpakketten, laadt en maakt een MRI-dataset schoon en bereidt inputs voor met consistente resizing, normalisatie en labelmapping, gevolgd door een snelle sanitycheck-inference.
Vervolgens finetune je MedGemma op de MRI-taak, track je leercurves en evalueer je met accuracy, ROC AUC, precision, recall en confusion matrices om faalpatronen te herkennen.
In het Fine-tuning Stable Diffusion XL with DreamBooth and LoRA-project zet je SDXL op in Python met Diffusers, laad je het FP16-basismodel en de VAE op een CUDA-GPU en genereer je beelden vanuit korte prompts. Je verkent snelle kwaliteitsboosts met de SDXL-refiner, vergelijkt outputs en gebruikt een eenvoudige rastertool om meerdere generaties naast elkaar te beoordelen.
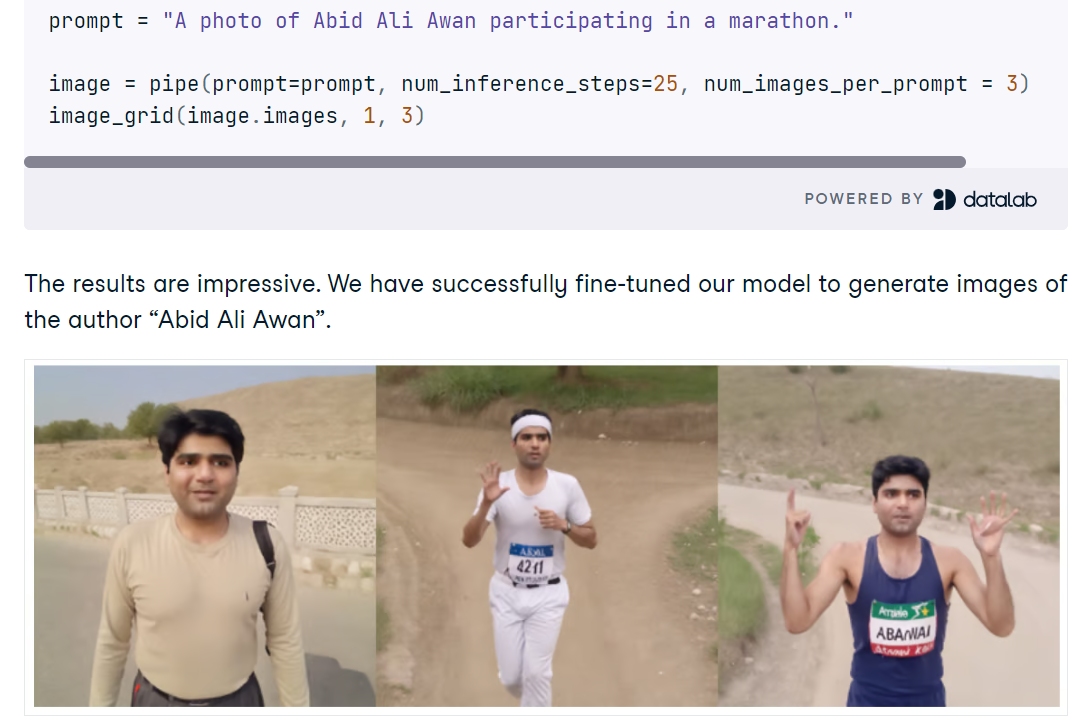
Daarna finetune je SDXL op een kleine set persoonlijke foto’s met AutoTrain Advanced en DreamBooth, waarbij je een compacte LoRA-adapter produceert in plaats van een volledige checkpoint voor snelle, geheugenefficiënte inference. Na het trainen koppel je de LoRA-gewichten aan de basismodule, test je nieuwe prompts en evalueer je wanneer de refiner de identiteitsgetrouwheid helpt of schaadt.
In het Song Generation with Latent Diffusion-project zet je een open-source diffusiemuziekmodel op om complete songs te genereren vanuit tekstprompts of een referentieaudioclip. Je installeert via Conda of Docker, richt de omgeving in (espeak-ng, phonemizerpaden op Windows) en draait de meegeleverde inferencescripts om tracks te maken met de base- of full-checkpoints, met chunked decoding wanneer VRAM krap is.
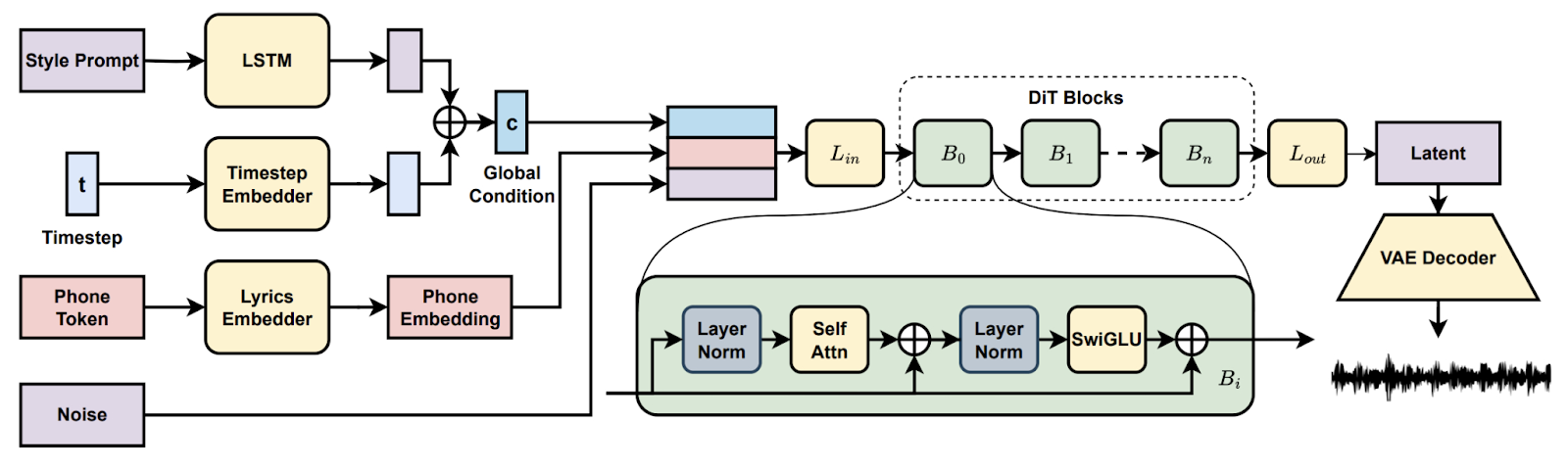
Vervolgens verken je features zoals songcontinuatie en -bewerking, vergelijk je arrangementen over prompts en documenteer je instellingen voor reproduceerbaarheid. Aan het eind heb je een praktische pipeline voor end-to-end muziekcreatie.
In het Deploying a Machine Learning Application to Production-project bouw je een volledig geautomatiseerde ML-pipeline met GitHub Actions die een eenvoudig geneesmiddelenclassificatiemodel traint, evalueert, versieert en deployt. Je zet de repo-structuur en Makefile op, voegt omgevingssetup, linting, unittests en datachecks toe en script reproduceerbare trainings- en evaluatieruns die metrics en artifacts loggen.
Daarna koppel je continuous integration aan pull requests en pushes naar main, publiceer je modelartifacts met CML en de Hugging Face CLI en promoveer je een geslaagd model naar deployment via continuous-deploymentworkflows.
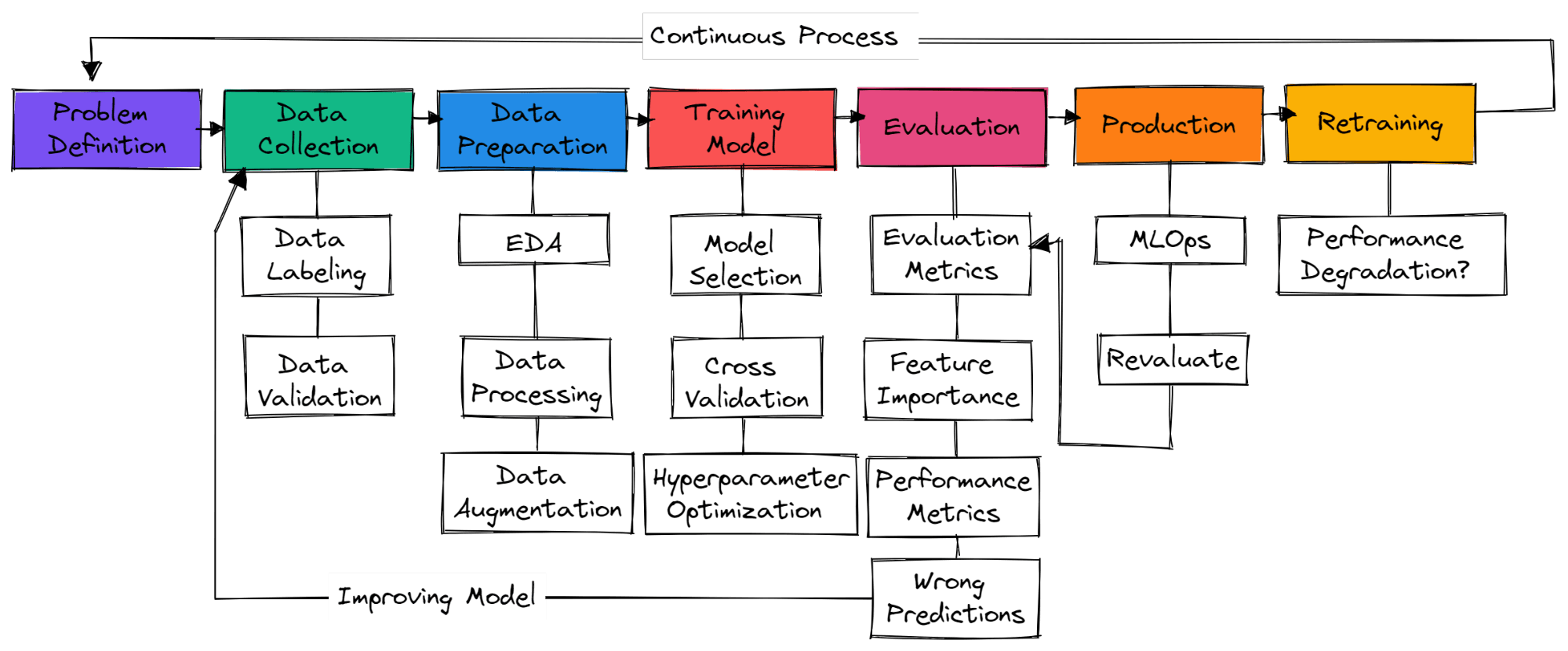
Afbeelding door auteur
Er zijn geen standaardstappen in een typisch ML-project. Soms volstaan dataverzameling, datapreparatie en modeltraining. In deze sectie bekijken we de stappen die nodig zijn om een productieklare machine-learningoplossing te bouwen.
Begrijp het businessprobleem en bedenk globaal hoe je machine learning gaat inzetten voor de oplossing. Zoek naar papers, open-sourceprojecten, tutorials en vergelijkbare toepassingen bij andere bedrijven. Zorg dat je oplossing realistisch is en data gemakkelijk beschikbaar is.
Je verzamelt data uit verschillende bronnen, maakt die schoon en labelt ze, en schrijft scripts voor datavalidatie. Zorg dat je data niet bevooroordeeld is en geen gevoelige informatie bevat.
Vul missende waarden aan, maak data schoon en verwerk deze voor analyse. Gebruik visualisatietools om de verdeling te begrijpen en hoe features de modelprestatie kunnen verbeteren. Feature scaling en data-augmentatie worden gebruikt om data te transformeren voor een ML-model.
kies neurale netwerken of ML-algoritmen die vaak worden gebruikt voor specifieke problemen. Train het model met kruisvalidatie en pas verschillende technieken voor hyperparameteroptimalisatie toe voor optimale resultaten.
Evalueer het model op de testdataset. Zorg dat je de juiste evaluatiemetric gebruikt voor het specifieke probleem. Accuracy is niet altijd een geldige metric. Kijk naar F1- of AUC-score voor classificatie of RMSE voor regressie. Visualiseer feature-importance om onbelangrijke features te schrappen. Evalueer ook trainingstijd en inferentietijd.
Zorg dat het model de menselijke baseline overtreft. Zo niet, verzamel meer kwalitatieve data en begin opnieuw. Het is een iteratief proces waarin je blijft trainen met verschillende feature-engineeringtechnieken, modelarchitecturen en ML-frameworks om de performance te verbeteren.
Na state-of-the-art resultaten is het tijd om je ML-model in productie/cloud te deployen met MLOps-tools. Monitor het model op realtime data. De meeste modellen falen in productie, dus het is verstandig om eerst naar een kleine subset gebruikers te deployen.
Als het model geen goede resultaten behaalt, ga je terug naar de tekentafel en bedenk je een betere oplossing. Zelfs als je goede resultaten behaalt, kan het model in de tijd verslechteren door datadrift en conceptdrift. Hertraining met nieuwe data zorgt dat je model zich aanpast aan realtime veranderingen.
Cursussen voor machine learning
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
