Kursus
Machine Learning dengan PySpark
4 Hr
29.8K
Proyek machine learning tingkat pemula ini berfokus pada data terstruktur berbentuk tabel. Anda akan menerapkan keterampilan pembersihan, pemrosesan, dan visualisasi data untuk tujuan analitis serta menggunakan kerangka kerja scikit-learn untuk melatih dan memvalidasi model machine learning.
Jika Anda ingin mempelajari konsep dasar machine learning terlebih dahulu, kami memiliki kursus memahami machine learning tanpa kode. Anda juga dapat melihat beberapa proyek AI kami jika Anda ingin meningkatkan keterampilan di area tersebut.
Dalam proyek Predict Energy Consumption, Anda akan menggunakan regresi dan model machine learning untuk memprediksi konsumsi daya harian berdasarkan faktor temporal seperti waktu dalam sehari dan suhu. Tujuannya adalah menemukan pola yang dapat mengoptimalkan penggunaan energi, meningkatkan efisiensi, dan menurunkan biaya. Hal ini sangat penting bagi utilitas dan bisnis yang ingin menekan biaya operasional, mendorong konservasi energi, dan mengelola sumber daya secara lebih berkelanjutan.
Proyek Predict Energy Consumption adalah proyek terpandu, tetapi Anda dapat mereplikasi tujuannya pada dataset lain, seperti Seoul's Bike Sharing Demand. Mengerjakan dataset yang benar-benar baru akan membantu Anda dalam debugging kode dan meningkatkan kemampuan pemecahan masalah.
Dalam proyek From Data to Dollars - Predicting Insurance Charges, Anda berperan sebagai Data Scientist di perusahaan asuransi kesehatan. Anda akan membangun model prediktif untuk memperkirakan biaya asuransi berdasarkan atribut klien, seperti usia dan faktor kesehatan. Proyek ini menawarkan penerapan machine learning secara praktis dalam bisnis, memungkinkan model harga yang lebih akurat dan membantu perusahaan mengelola risiko sambil memberikan strategi harga yang dipersonalisasi kepada klien.
Predicting Insurance Charges adalah proyek terpandu. Anda dapat mereplikasi hasilnya pada dataset lain, seperti Hotel Booking Demand. Anda bisa menggunakannya untuk memprediksi apakah pelanggan akan membatalkan pemesanan atau tidak.
Dalam proyek Predicting Credit Card Approvals, Anda akan membangun aplikasi persetujuan kartu kredit otomatis menggunakan optimisasi hiperparameter dan Logistic Regression.
Anda akan menerapkan keterampilan menangani nilai yang hilang, memproses fitur kategorikal, penskalaan fitur, menangani data tidak seimbang, dan melakukan optimisasi hiperparameter otomatis menggunakan GridCV. Proyek ini akan menantang Anda melampaui penanganan data yang sederhana dan bersih.

Gambar oleh Penulis
Predicting Credit Card Approvals adalah proyek terpandu. Anda dapat mereplikasi hasilnya pada dataset lain, seperti Loan Data dari LendingClub.com. Anda bisa menggunakannya untuk membangun prediktor persetujuan pinjaman otomatis.
Anda dapat menyusun proyek prediksi kualitas anggur menggunakan dataset sifat fisikokimia anggur, seperti kadar alkohol, keasaman, dan kadar gula. Dengan menerapkan model klasifikasi seperti logistic regression di scikit-learn, Anda dapat mengklasifikasikan anggur pada skala 1–10.
Proyek ini penting bagi industri yang terlibat dalam produksi dan kontrol kualitas anggur, karena memungkinkan pemantauan dan prediksi kualitas anggur secara konsisten untuk memastikan keunggulan produk.
Dalam Predictive Modeling for Agriculture Data Science Project, Anda akan membangun sistem rekomendasi tanaman sederhana menggunakan supervised machine learning dan feature selection. Bekerja dengan empat atribut tanah penting: nitrogen, fosfor, kalium, dan pH. Anda akan menghadapi kendala realistis: petani hanya mampu mengukur satu atribut. Tugas Anda adalah mengidentifikasi fitur tunggal mana yang paling baik memprediksi tanaman yang tepat dan kemudian melatih pengklasifikasi ringan untuk memberikan rekomendasi tersebut secara andal.
Anda akan mempraktikkan keterampilan seperti menangani nilai hilang, encoding label, penskalaan fitur, evaluasi model, dan yang terpenting menerapkan serta membandingkan dua teknik feature selection untuk memberi peringkat ukuran tanah.
Store Sales adalah kompetisi pemula di Kaggle tempat peserta melatih berbagai model deret waktu untuk meningkatkan skor di papan peringkat. Dalam proyek ini, Anda akan diberikan data penjualan toko, lalu Anda akan membersihkan data, melakukan analisis deret waktu ekstensif, penskalaan fitur, dan melatih model deret waktu multivariat.
Untuk meningkatkan skor di papan peringkat, Anda dapat menggunakan ensembling seperti Bagging dan Voting Regressor.
Gambar dari Kaggle
Store Sales adalah proyek berbasis Kaggle di mana Anda dapat melihat notebook peserta lain.
Untuk meningkatkan pemahaman Anda tentang peramalan deret waktu, coba terapkan keterampilan Anda pada dataset Stock Exchange dan gunakan Facebook Prophet untuk melatih model peramalan deret waktu univariat.
Proyek machine learning tingkat menengah ini berfokus pada pemrosesan data dan pelatihan model untuk dataset terstruktur dan tidak terstruktur. Pelajari cara membersihkan, memproses, dan mengaugmentasi dataset menggunakan berbagai alat statistik.
Proyek Reveal Categories Found in Data membantu Anda mengeksplorasi umpan balik pelanggan menggunakan clustering dan natural language processing (NLP). Anda akan mengelompokkan ulasan dari Google Play Store ke dalam kategori berbeda menggunakan K-means clustering. Memahami tema umum dari umpan balik pelanggan sangat penting bagi tim pengembangan produk untuk mengatasi titik nyeri pengguna, meningkatkan fitur, dan meningkatkan kepuasan pengguna melalui wawasan yang dapat ditindaklanjuti.
Cobalah mereplikasi hasil pada dataset lain, seperti dataset Netflix Movie.
Dalam proyek Word Frequency in Moby Dick, Anda akan mengambil (scrape) teks Moby Dick karya Herman Melville dan menganalisis frekuensi kata menggunakan pustaka nltk Python. Proyek ini memperkenalkan teknik NLP kunci dan membantu memahami bagaimana kata-kata yang sering digunakan mengungkap pola dalam teks. Proyek ini sangat baik bagi pemerhati sastra, sejarawan, atau peneliti yang tertarik pada penambangan teks dan analisis linguistik.
Dalam proyek Facial Recognition with Supervised Learning, Anda akan membangun model pengenalan wajah menggunakan teknik supervised learning dengan Python dan scikit-learn. Model membedakan antara gambar Arnold Schwarzenegger dan orang lain. Proyek ini penting dalam bidang teknologi pengenalan wajah yang terus berkembang, dengan aplikasi luas pada keamanan, sistem autentikasi, dan bahkan platform media sosial yang umum menggunakan deteksi wajah.
Bangun prediktor popularitas buku untuk toko buku online dengan mengonversi data campuran, seperti teks (mis. judul dan deskripsi buku) dan data numerik (mis. rating dan jumlah), menjadi fitur yang efektif. Anda akan menjalani alur kerja machine learning lengkap, yang mencakup EDA (exploratory data analysis) cepat, memperbaiki tipe data, mentransformasikan variabel teks dan numerik, serta menyetel model untuk mencapai akurasi setinggi mungkin.
Anda akan belajar mengelola data yang berantakan dan multi-format serta mengevaluasi hasil menggunakan pipeline yang rapi dan dapat digunakan kembali. Pada akhirnya, Anda dapat menerapkan metode yang sama pada katalog apa pun, baik daftar bacaan pribadi maupun dataset publik, untuk memprediksi calon bestseller dan meningkatkan sistem rekomendasi.
Dalam proyek Clustering Antarctic Penguin Species, Anda menggunakan unsupervised learning untuk menemukan kelompok alami penguin tanpa label. Anda akan membersihkan dataset bergaya Palmer Penguins, menangani nilai hilang, menskalakan fitur numerik seperti panjang paruh, kedalaman paruh, panjang sirip, dan massa tubuh, serta secara opsional melakukan encoding variabel kategorikal sederhana seperti pulau atau jenis kelamin sebelum menerapkan K-means clustering.
Kemudian Anda memilih jumlah cluster dengan skor elbow dan silhouette, memvisualisasikan struktur dengan PCA, dan membandingkan cluster dengan spesies yang dikenal untuk sanity check cepat.
Dalam proyek Taxi Route Optimization with Reinforcement Learning, Anda melatih agen Q-learning untuk menyelesaikan lingkungan Taxi-v3 Gymnasium dengan mempelajari rute penjemputan dan pengantaran yang efisien. Anda akan membangun tabel nilai state–action, menyeimbangkan eksplorasi dan eksploitasi dengan kebijakan epsilon-greedy, serta menyetel hiperparameter inti seperti learning rate, discount factor, dan peluruhan epsilon untuk mempercepat konvergensi.

Kemudian Anda mengevaluasi kinerja dengan rata-rata reward per episode dan jumlah langkah hingga selesai, memvisualisasikan kurva pembelajaran, dan menguji kebijakan terlatih pada episode yang belum terlihat.
Gunakan Wisconsin Breast Cancer dataset untuk memprediksi apakah tumor bersifat ganas atau jinak. Dataset mencakup detail fitur tumor, seperti tekstur, keliling, dan area, dan tujuan Anda adalah membangun model klasifikasi yang memprediksi diagnosis berdasarkan karakteristik tersebut.
Proyek ini sangat penting dalam aplikasi kesehatan, memberikan wawasan berharga dalam analisis data medis dan potensi pengembangan alat diagnostik yang dapat membantu deteksi dini kanker.
Dalam proyekSpeech Emotion Recognition with Librosa, Anda akan memproses berkas suara menggunakan Librosa, soundfile, dan sklearn untuk MLPClassifier guna mengenali emosi dari berkas suara.
Anda akan memuat dan memproses berkas suara, melakukan ekstraksi fitur, serta melatih model pengklasifikasi Multi-Layer Perceptron. Proyek ini akan mengajarkan dasar-dasar pemrosesan audio sehingga Anda dapat lanjut melatih model deep learning untuk mencapai akurasi yang lebih baik.
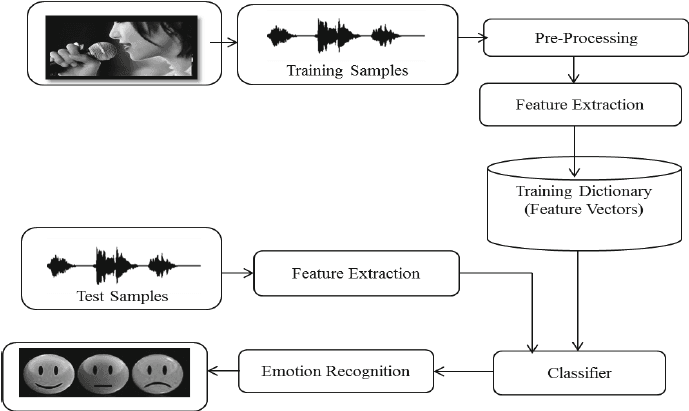
Gambar dari researchgate.net
Proyek machine learning tingkat lanjut ini berfokus pada pembangunan dan pelatihan model deep learning serta pemrosesan dataset tidak terstruktur. Anda akan melatih convolutional neural networks, gated recurrent units, menyetel lanjutan model bahasa besar, dan model reinforcement learning.
Dalam proyek Service Desk Ticket Classification with Deep Learning, Anda membangun pengklasifikasi teks PyTorch yang secara otomatis mengarahkan tiket masuk ke kategori yang tepat. Anda akan membersihkan dan tokenisasi teks, membuat pembagian train dan validasi, mengubah tiket menjadi representasi vektor, dan melatih model neural ringkas sambil menyetel ukuran batch, learning rate, dan regularisasi untuk konvergensi yang stabil.
Kemudian Anda mengevaluasi dengan akurasi dan F1 tertimbang, memeriksa confusion matrix untuk menemukan kategori yang salah label atau tumpang tindih, serta menerapkan teknik untuk ketidakseimbangan kelas seperti weighted loss.
Dalam proyek Build Rick Sanchez Bot Using Transformers, Anda akan menggunakan DialoGPT dan pustaka Hugging Face Transformer untuk membangun chatbot bertenaga AI.
Anda akan memproses dan mentransformasikan data, membangun dan menyetel model Microsoft’s Large-scale Pretrained Response Generation (DialoGPT) pada dataset dialog Rick and Morty. Anda juga dapat membuat aplikasi Gradio sederhana untuk menguji model secara real-time: Rick & Morty Block Party.
Proyek Building an E-Commerce Clothing Classifier Model with Keras berfokus pada klasifikasi gambar dalam konteks e-commerce. Anda akan menggunakan Keras untuk membangun model machine learning yang mengotomatisasi klasifikasi pakaian berdasarkan gambar. Ini relevan untuk meningkatkan pengalaman berbelanja dengan membantu pelanggan menemukan produk lebih cepat dan merampingkan manajemen inventaris. Klasifikasi yang akurat juga mendukung rekomendasi yang dipersonalisasi, sehingga meningkatkan keterlibatan pelanggan dan penjualan.
Dalam proyek Detect Traffic Signs with Deep Learning, Anda akan menggunakan Keras untuk mengembangkan model deep learning yang mampu mendeteksi rambu lalu lintas, seperti rambu berhenti dan lampu lalu lintas. Teknologi ini krusial bagi kendaraan otonom, di mana pengenalan sinyal jalan yang cepat dan akurat sangat penting untuk navigasi yang aman. Proyek ini menjadi landasan untuk mengembangkan sistem kendaraan swakemudi yang lebih maju, aman, dan andal.
Dalam proyek Building a Demand Forecasting Model, Anda menggunakan PySpark untuk memprediksi permintaan produk e-commerce dalam skala besar. Anda akan memuat data transaksional, merekayasa fitur berbasis waktu seperti lag dan rolling mean, membagi berdasarkan waktu untuk evaluasi yang jujur, dan melatih baseline bersamaan dengan model pembelajaran seperti Gradient-Boosted Trees atau Random Forest untuk menangkap tren dan musiman.
Kemudian Anda mengevaluasi dengan MAE, RMSE, dan MAPE, membandingkan dengan baseline, serta menganalisis error per SKU dan jendela waktu untuk melihat bias dan volatilitas.
Dalam proyek Predicting Temperature in London, Anda menjalankan eksperimen ML terstruktur untuk meramalkan suhu rata-rata harian dari data cuaca historis. Anda akan memuat dan membersihkan dataset, membuat pembagian peka waktu, merekayasa fitur seperti rolling mean dan nilai lag, serta melatih beberapa model kandidat menggunakan scikit-learn.
Kemudian Anda mengorkestrasi alur kerja dengan fungsi yang dapat digunakan ulang dan melacak semuanya di MLflow, mencatat parameter, metrik, dan artefak untuk membandingkan run.
Connect X adalah kompetisi simulasi oleh Kaggle. Bangun agen RL (Reinforcement Learning) untuk bersaing dengan peserta kompetisi Kaggle lainnya.
Pertama, Anda akan mempelajari cara kerja gim dan membuat agen fungsional sederhana sebagai baseline. Setelah itu, Anda akan mulai bereksperimen dengan berbagai algoritma RL dan arsitektur model. Anda dapat mencoba membangun model dengan algoritma Deep Q-learning atau Proximal Policy Optimization.
Proyek tingkat akhir mengharuskan Anda meluangkan waktu untuk menghasilkan solusi yang unik. Anda akan meneliti beberapa arsitektur model, menggunakan berbagai kerangka kerja machine learning untuk menormalkan dan mengaugmentasi dataset, memahami matematika di balik prosesnya, dan menulis tesis berdasarkan hasil Anda.
Dalam model Multi-Lingual ASR, Anda akan menyetel lanjut model Wave2Vec XLS-R menggunakan audio dan transkripsi bahasa Turki untuk membangun sistem pengenalan ucapan otomatis.
Pertama, Anda akan memahami berkas audio dan dataset teks, lalu menggunakan tokenizer teks, mengekstrak fitur, dan memproses berkas audio. Setelah itu, Anda akan membuat trainer, fungsi WER, memuat model pralatih, menyetel hiperparameter, serta melatih dan mengevaluasi model.
Anda dapat menggunakan platform Hugging Face untuk menyimpan bobot model dan menerbitkan aplikasi web untuk mentranskripsi ucapan secara real-time: Streaming Urdu Asr.
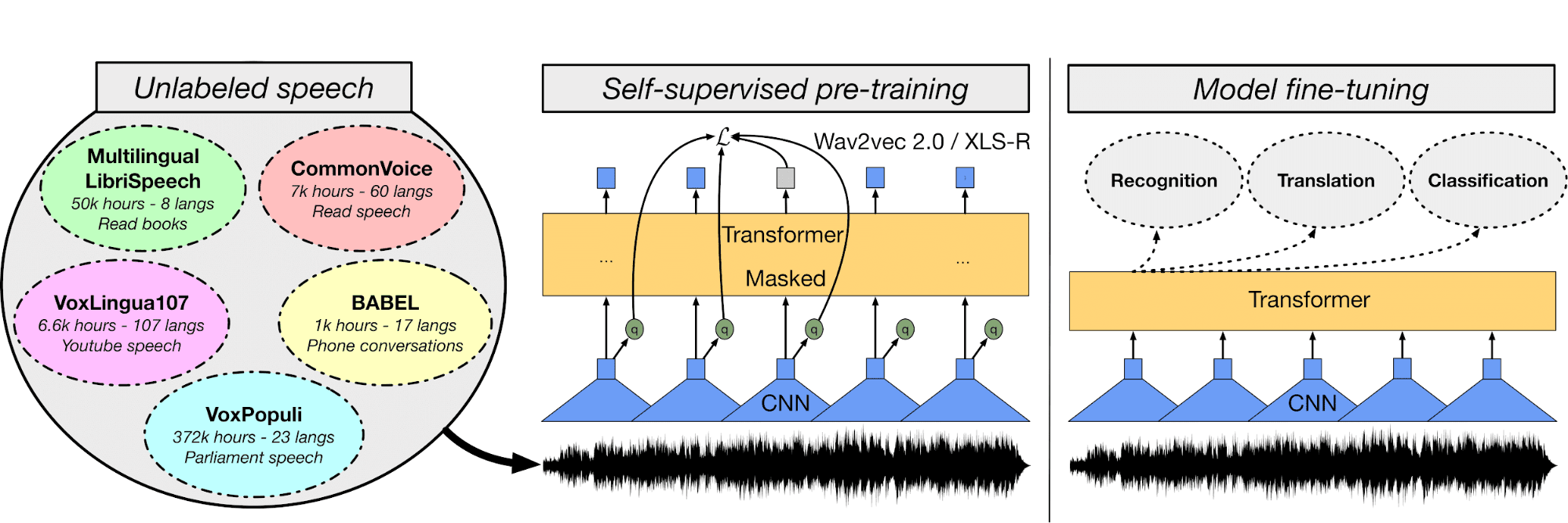
Gambar dari huggingface.co
Dalam proyek One Shot Face Stylization, Anda dapat memodifikasi model untuk meningkatkan hasil atau menyetel lanjut JoJoGAN pada dataset baru untuk membuat aplikasi stilisasi Anda.
Proyek ini akan menggunakan gambar asli untuk menghasilkan gambar baru menggunakan inversi GAN dan fine-tuning StyleGAN pralatih. Anda akan memahami berbagai arsitektur generative adversarial network. Setelah itu, Anda akan mulai mengumpulkan dataset berpasangan untuk membuat gaya pilihan Anda.
Kemudian, dengan bantuan solusi contoh dari versi StyleGAN sebelumnya, Anda akan bereksperimen dengan arsitektur baru untuk menghasilkan karya seni yang realistis.
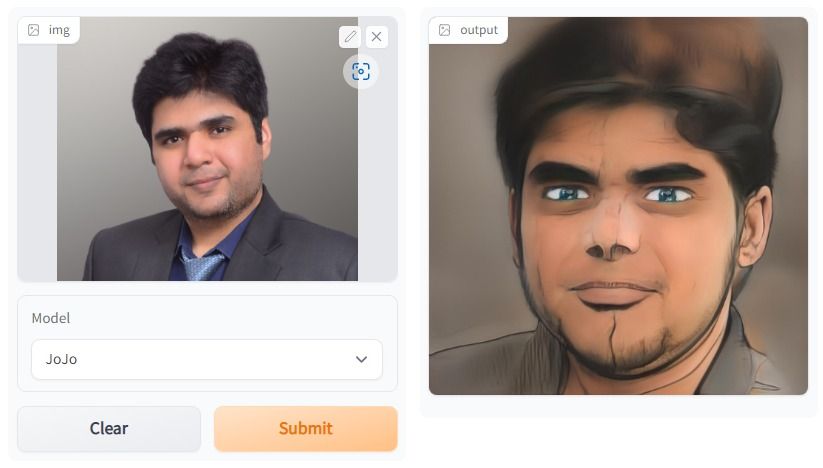
Gambar dibuat menggunakan JoJoGAN
Dalam proyek H&M Personalized Fashion Recommendations, Anda akan membangun rekomendasi produk berdasarkan transaksi sebelumnya, data pelanggan, dan metadata produk.
Proyek ini akan menguji keterampilan NLP, CV (Computer Vision), dan deep learning Anda. Pada beberapa minggu pertama, Anda akan memahami data dan bagaimana Anda dapat menggunakan berbagai fitur untuk membuat baseline.
Kemudian, buat model sederhana yang hanya menggunakan fitur teks dan kategorikal untuk memprediksi rekomendasi. Setelah itu, gabungkan NLP dan CV untuk meningkatkan skor Anda di papan peringkat. Anda juga dapat memperdalam pemahaman masalah dengan meninjau diskusi dan kode komunitas.

Gambar dari H&M EDA FIRST LOOK
Dalam proyek Analyzing Customer Support Calls, Anda membangun pipeline ujung-ke-ujung yang mengubah audio mentah menjadi insight. Anda akan mentranskripsi panggilan dengan model pengenalan ucapan otomatis, membersihkan dan memotong teks, menjalankan analisis sentimen, serta mengekstrak entitas seperti produk, paket, lokasi, dan nama. Anda juga akan melakukan pengindeksan transkrip dengan embedding untuk memungkinkan pencarian semantik cepat di seluruh percakapan.
Kemudian Anda mengevaluasi kualitas transkripsi dan kinerja model, mengelompokkan tema untuk mengungkap penyebab umum panggilan, serta menyoroti lonjakan sentimen negatif atau kata kunci eskalasi.
Dalam proyek Monitoring A Financial Fraud Detection Model, Anda berperan sebagai data scientist pasca-deployment untuk sebuah bank di Inggris, mendiagnosis mengapa model penipuan yang aktif mengalami penurunan. Anda akan memuat prediksi dan outcome produksi, melacak metrik inti seperti precision, recall, PR-AUC, dan kalibrasi, serta memvisualisasikan kinerja dari waktu ke waktu untuk mendeteksi degradasi. Anda juga akan melakukan slicing berdasarkan kanal, wilayah, dan segmen pelanggan untuk menemukan di mana false positive atau false negative terkonsentrasi.
Kemudian Anda menguji data dan concept drift menggunakan pemeriksaan distribusi dan stability index, memeriksa pergeseran feature importance, dan menggunakan alat explainability untuk membandingkan perilaku saat ini vs baseline.
Dalam proyek MuZero for Atari 2600, Anda akan membangun, melatih, dan memvalidasi agen reinforcement learning menggunakan algoritma MuZero untuk gim Atari 2600. Baca tutorial untuk memahami lebih lanjut tentang algoritma MuZero.
Tujuannya adalah membangun arsitektur baru atau memodifikasi arsitektur yang ada untuk meningkatkan skor pada papan peringkat global. Akan membutuhkan waktu lebih dari tiga bulan untuk memahami cara kerja algoritma dalam reinforcement learning.
Proyek ini sarat matematika dan mengharuskan Anda memiliki keahlian Python. Anda dapat menemukan solusi yang diusulkan, tetapi untuk mencapai peringkat teratas dunia, Anda harus membangun solusi sendiri.
Proyek MLOps End-To-End Machine Learning diperlukan agar Anda dilirik perusahaan top. Saat ini, perekrut mencari insinyur ML yang dapat membuat sistem ujung-ke-ujung menggunakan alat MLOps, orkestrasi data, dan komputasi awan.
Dalam proyek ini, Anda akan membangun dan melakukan deployment pengklasifikasi gambar lokasi menggunakan TensorFlow, Streamlit, Docker, Kubernetes, cloudbuild, GitHub, dan Google Cloud. Tujuan utamanya adalah mengotomatisasi pembangunan dan deployment model machine learning ke produksi menggunakan CI/CD. Untuk panduan, baca tutorial Machine Learning, Pipelines, Deployment, and MLOps.
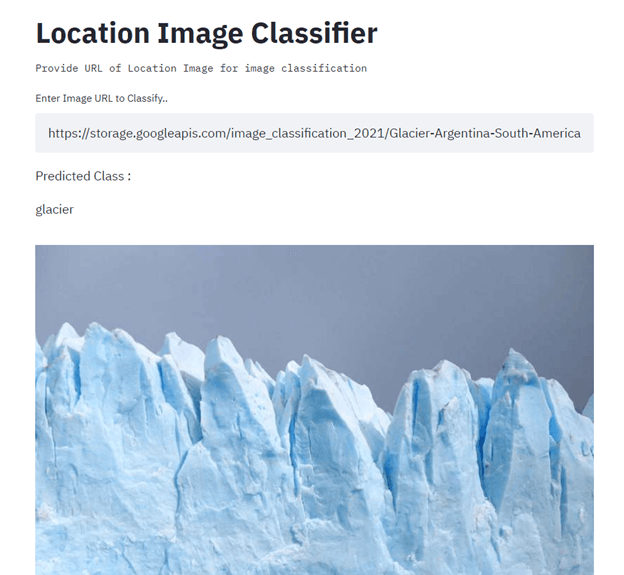
Gambar dari Senthil E
Untuk membangun portofolio machine learning, Anda membutuhkan proyek yang menonjol. Tunjukkan kepada manajer perekrutan atau perekrut bahwa Anda dapat menulis kode dalam berbagai bahasa, memahami berbagai kerangka kerja machine learning, menyelesaikan masalah unik menggunakan machine learning, dan memahami ekosistem machine learning ujung-ke-ujung.
Dalam proyek Fine-Tuning GPT-OSS, Anda akan memasang dependensi, memuat model dan tokenizer, mendefinisikan gaya prompt yang jelas dengan paket Harmony Python, dan menjalankan inferensi baseline cepat untuk memastikan semuanya berfungsi ujung-ke-ujung.
Kemudian Anda menyiapkan dataset tanya jawab medis dengan format Harmony, mengonfigurasi pelatihan, dan menyetel lanjut model, diikuti evaluasi pascapenyetelan untuk mengukur peningkatan.
Dalam proyek Fine-Tuning MedGemma on a Brain MRI Dataset, Anda mengadaptasi model multimodal MedGemma 4B, encoder gambar SigLIP, serta LLM yang disetel untuk medis, untuk mengklasifikasikan pemindaian MRI otak. Anda akan menyiapkan lingkungan di RunPod, memasang paket Python yang diperlukan, memuat dan membersihkan dataset MRI, serta menyiapkan input dengan penyeragaman ukuran, normalisasi, dan pemetaan label yang konsisten sebelum menjalankan inferensi sanity-check cepat.
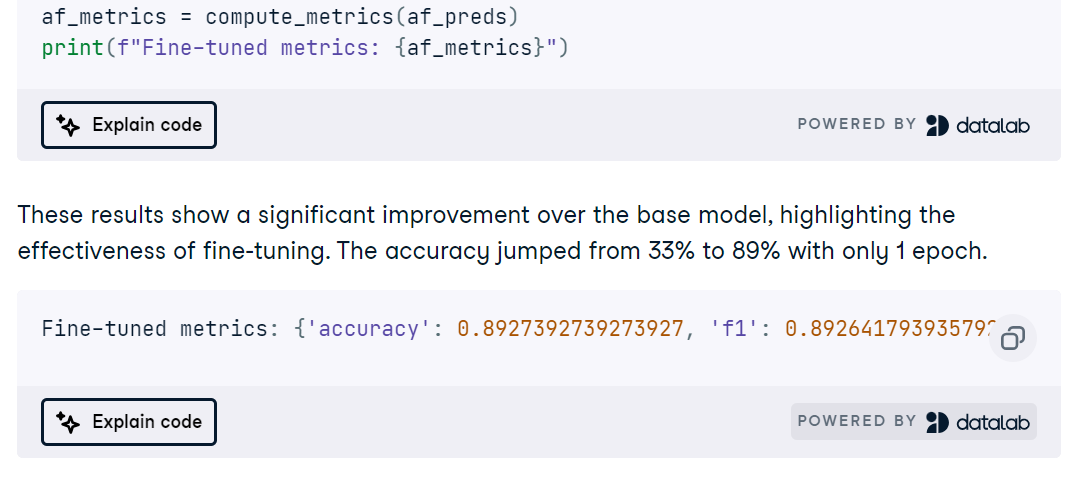
Kemudian Anda menyetel lanjut MedGemma pada tugas MRI, melacak kurva pelatihan, dan mengevaluasi dengan akurasi, ROC AUC, precision, recall, serta confusion matrix untuk mengidentifikasi mode kegagalan.
Dalam proyek Fine-tuning Stable Diffusion XL with DreamBooth and LoRA, Anda menyiapkan SDXL di Python dengan Diffusers, memuat model dasar FP16 dan VAE pada GPU CUDA, serta menghasilkan gambar dari prompt pendek. Anda akan mengeksplorasi peningkatan kualitas cepat dengan SDXL refiner, membandingkan output, dan menggunakan utilitas grid sederhana untuk meninjau beberapa hasil generasi secara berdampingan.
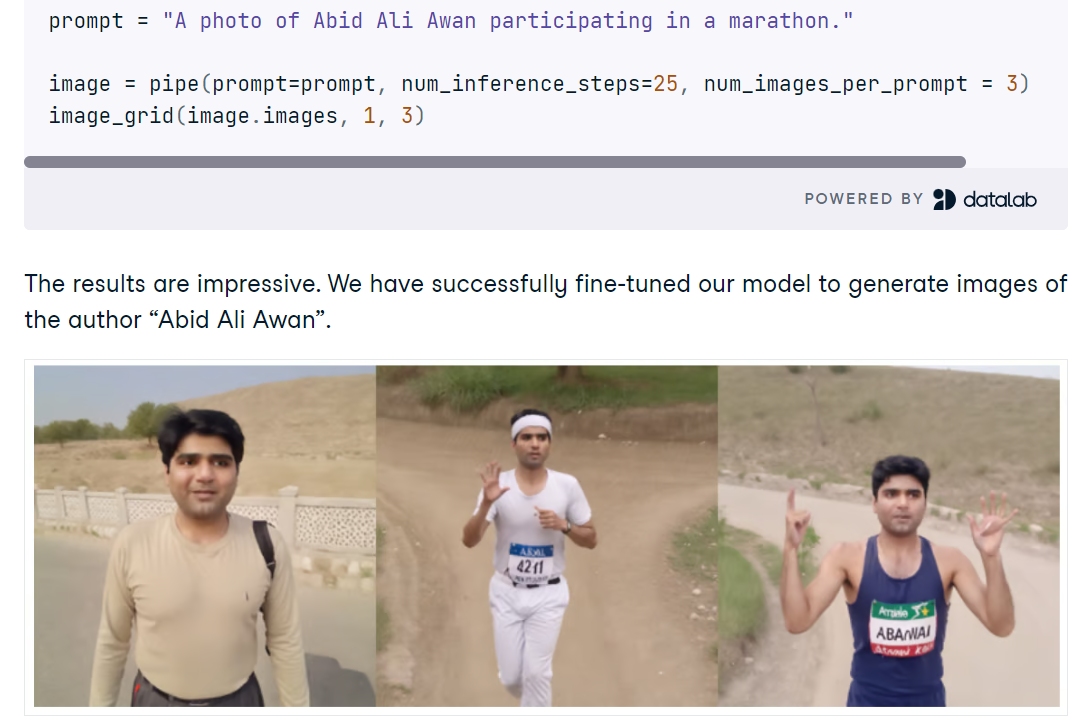
Kemudian Anda menyetel lanjut SDXL pada sekumpulan kecil foto pribadi menggunakan AutoTrain Advanced dengan DreamBooth, menghasilkan adapter LoRA yang ringkas alih-alih checkpoint penuh untuk inferensi yang cepat dan hemat memori. Setelah pelatihan, Anda menautkan bobot LoRA ke pipeline dasar, menguji prompt baru, dan mengevaluasi kapan refiner membantu atau merusak kesetiaan identitas.
Dalam proyek Song Generation with Latent Diffusion, Anda menyiapkan model musik difusi open-source untuk menghasilkan lagu lengkap dari prompt gaya teks atau klip audio referensi. Anda akan memasang melalui Conda atau Docker, menyiapkan lingkungan (jalur espeak-ng, phonemizer pada Windows), dan menjalankan skrip inferensi yang disediakan untuk membuat trek dengan checkpoint dasar atau penuh, mengaktifkan decoding bertahap saat VRAM terbatas.
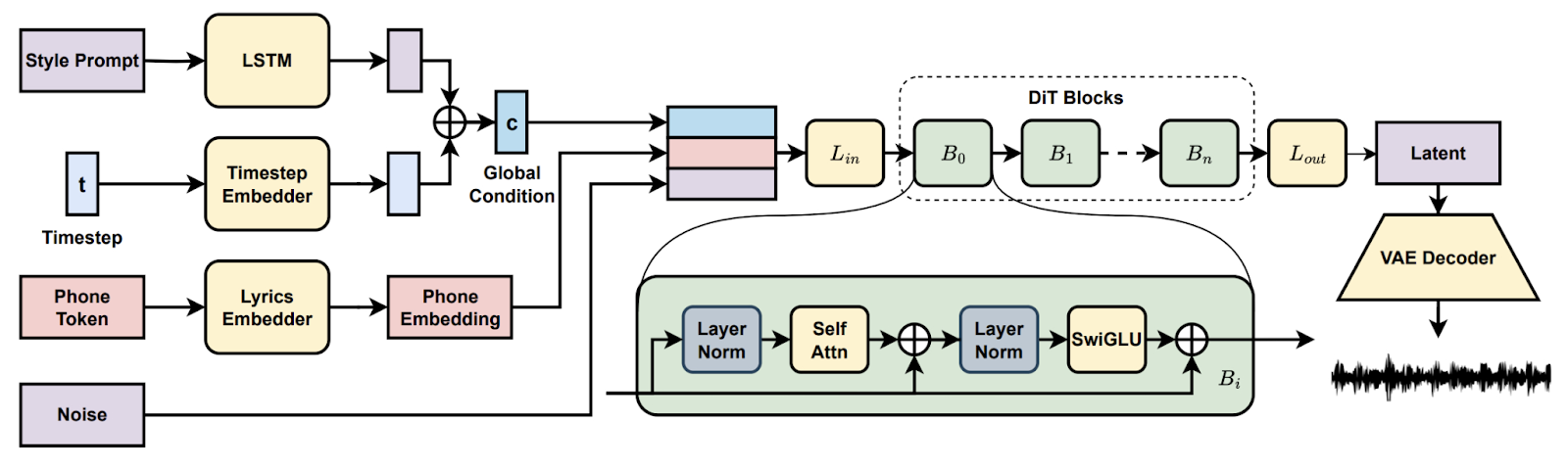
Kemudian Anda mengeksplorasi fitur seperti kelanjutan dan pengeditan lagu, membandingkan aransemen di berbagai prompt, serta mendokumentasikan pengaturan untuk reprodusibilitas. Pada akhirnya, Anda memiliki pipeline praktis untuk pembuatan musik ujung-ke-ujung.
Dalam proyek Deploying a Machine Learning Application to Production, Anda membangun pipeline ML yang sepenuhnya otomatis dengan GitHub Actions yang melatih, mengevaluasi, memberi versi, dan mendeploy model klasifikasi obat sederhana. Anda menyiapkan struktur repo dan Makefile, menambahkan penyiapan lingkungan, linting, unit test, dan pemeriksaan data, lalu membuat skrip pelatihan dan evaluasi yang dapat direproduksi yang mencatat metrik dan artefak.
Kemudian Anda menyambungkan continuous integration agar dipicu pada pull request dan push ke main, menerbitkan artefak model dengan CML dan Hugging Face CLI, serta mempromosikan model yang lolos ke deployment melalui workflow continuous deployment.
Gambar oleh Penulis
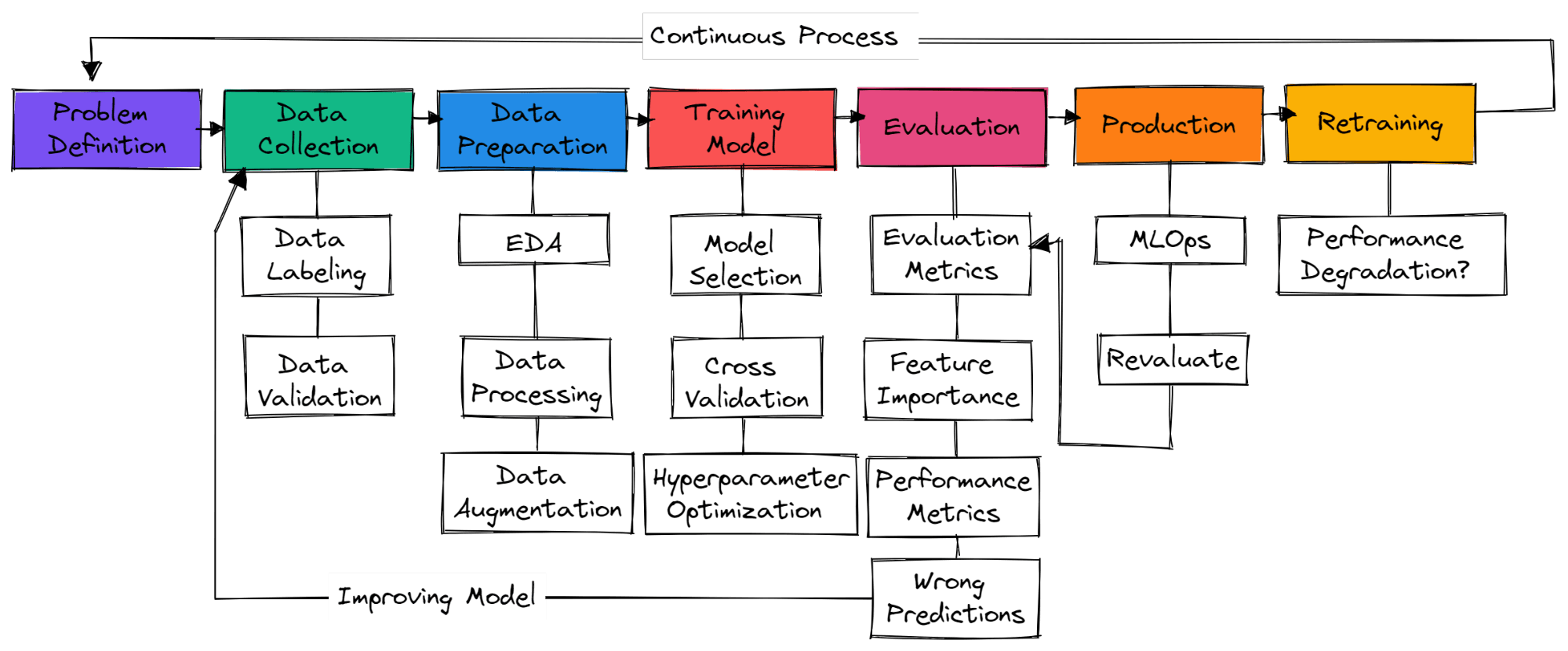
Tidak ada langkah baku dalam proyek machine learning tipikal. Jadi, bisa saja hanya pengumpulan data, penyiapan data, dan pelatihan model. Pada bagian ini, kita akan mempelajari langkah-langkah yang diperlukan untuk membangun proyek machine learning yang siap produksi.
Anda perlu memahami masalah bisnis dan membuat gambaran kasar bagaimana Anda akan menggunakan machine learning untuk menyelesaikannya. Cari makalah riset, proyek open source, tutorial, dan aplikasi serupa yang digunakan perusahaan lain. Pastikan solusi Anda realistis dan data mudah tersedia.
Anda akan mengumpulkan data dari berbagai sumber, membersihkan dan memberi label, serta membuat skrip untuk validasi data. Pastikan data Anda tidak bias atau berisi informasi sensitif.
Isi nilai yang hilang, bersihkan, dan proses data untuk analisis data. Gunakan alat visualisasi untuk memahami distribusi data dan bagaimana Anda dapat memanfaatkan fitur untuk meningkatkan kinerja model. Penskalaan fitur dan augmentasi data digunakan untuk mentransformasikan data bagi model machine learning.
memilih jaringan saraf atau algoritma machine learning yang umum digunakan untuk masalah tertentu. Melatih model menggunakan cross-validation dan berbagai teknik optimisasi hiperparameter untuk mendapatkan hasil optimal.
Mengevaluasi model pada dataset uji. Pastikan Anda menggunakan metrik evaluasi model yang tepat untuk masalah spesifik. Akurasi bukan metrik yang valid untuk semua jenis masalah. Periksa skor F1 atau AUC untuk klasifikasi atau RMSE untuk regresi. Visualisasikan feature importance model untuk menghapus fitur yang tidak penting. Evaluasi metrik kinerja seperti waktu pelatihan model dan inferensi.
Pastikan model melampaui baseline manusia. Jika belum, kembali kumpulkan data berkualitas lebih baik dan mulai proses lagi. Ini adalah proses iteratif di mana Anda akan terus melatih dengan berbagai teknik rekayasa fitur, arsitektur model, dan kerangka kerja machine learning untuk meningkatkan kinerja.
Setelah mencapai hasil state-of-the-art saatnya mendeploy model machine learning Anda ke produksi/cloud menggunakan alat MLOps. Pantau model pada data real-time. Sebagian besar model gagal di produksi, jadi sebaiknya deploy untuk sebagian kecil pengguna terlebih dahulu.
Jika model gagal mencapai hasil, Anda akan kembali ke tahap awal dan merancang solusi yang lebih baik. Bahkan jika Anda mencapai hasil yang baik, model dapat menurun seiring waktu karena data drift dan concept drift. Melatih ulang dengan data baru juga membuat model Anda beradaptasi dengan perubahan real-time.
Kursus untuk Machine learning
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
