Courses
Machine Learning với PySpark
4 giờ
29.8K
Những dự án machine learning cho người mới bắt đầu này chủ yếu làm việc với dữ liệu có cấu trúc, dạng bảng. Bạn sẽ áp dụng kỹ năng làm sạch, xử lý và trực quan hóa dữ liệu cho mục đích phân tích và sử dụng khung scikit-learn để huấn luyện và đánh giá mô hình machine learning.
Nếu bạn muốn học trước các khái niệm cơ bản của machine learning, chúng tôi có một khóa hiểu machine learning không cần viết mã. Bạn cũng có thể xem một số dự án AI nếu bạn muốn cải thiện kỹ năng trong mảng đó.
Trong dự án Predict Energy Consumption, bạn sẽ sử dụng hồi quy và các mô hình machine learning để dự đoán mức tiêu thụ điện hằng ngày dựa trên các yếu tố thời gian như thời điểm trong ngày và nhiệt độ. Mục tiêu là khám phá các mẫu có thể tối ưu hóa việc sử dụng năng lượng, nâng cao hiệu suất và giảm chi phí. Điều này đặc biệt quan trọng đối với các đơn vị cung cấp dịch vụ và doanh nghiệp muốn cắt giảm chi phí vận hành, thúc đẩy tiết kiệm năng lượng và quản lý tài nguyên bền vững hơn.
Predict Energy Consumption là dự án có hướng dẫn, nhưng bạn có thể tái lập mục tiêu trên bộ dữ liệu khác, chẳng hạn Nhu cầu chia sẻ xe đạp ở Seoul. Làm việc với một bộ dữ liệu hoàn toàn mới sẽ giúp bạn gỡ lỗi mã và cải thiện kỹ năng giải quyết vấn đề.
Trong dự án From Data to Dollars - Predicting Insurance Charges, bạn đóng vai trò Chuyên gia Khoa học Dữ liệu tại một công ty bảo hiểm y tế. Bạn sẽ xây dựng mô hình dự đoán chi phí bảo hiểm dựa trên thuộc tính của khách hàng, như tuổi tác và các yếu tố sức khỏe. Dự án này là một ứng dụng thực tiễn của machine learning trong kinh doanh, giúp xây dựng mô hình định giá chính xác hơn và hỗ trợ doanh nghiệp quản trị rủi ro đồng thời đưa ra chiến lược định giá cá nhân hóa cho khách hàng.
Predicting Insurance Charges là dự án có hướng dẫn. Bạn có thể tái lập kết quả trên bộ dữ liệu khác, chẳng hạn Nhu cầu đặt phòng khách sạn. Bạn có thể dùng nó để dự đoán khách hàng có hủy đặt phòng hay không.
Trong dự án Predicting Credit Card Approvals, bạn sẽ xây dựng ứng dụng tự động phê duyệt thẻ tín dụng bằng tối ưu siêu tham số và Logistic Regression.
Bạn sẽ áp dụng kỹ năng xử lý giá trị thiếu, xử lý thuộc tính phân loại, chuẩn hóa đặc trưng, xử lý dữ liệu mất cân bằng, và thực hiện tối ưu siêu tham số tự động bằng GridCV. Dự án này sẽ thử thách bạn vượt ra ngoài việc xử lý dữ liệu đơn giản và sạch.

Hình ảnh do Tác giả cung cấp
Predicting Credit Card Approvals là dự án có hướng dẫn. Bạn có thể tái lập kết quả trên bộ dữ liệu khác, như Dữ liệu khoản vay từ LendingClub.com. Bạn có thể dùng nó để xây dựng bộ dự đoán phê duyệt khoản vay tự động.
Bạn có thể xây dựng dự án dự đoán chất lượng rượu vang, sử dụng bộ dữ liệu các thuộc tính hóa lý của rượu vang, như nồng độ cồn, độ axit và lượng đường. Bằng cách áp dụng các mô hình phân loại, như logistic regression trong scikit-learn, bạn có thể phân loại rượu vang theo thang điểm 1-10.
Dự án này quan trọng đối với các ngành liên quan đến sản xuất và kiểm soát chất lượng rượu vang, vì nó cho phép giám sát và dự đoán chất lượng một cách nhất quán, đảm bảo sự vượt trội của sản phẩm.
Trong Predictive Modeling for Agriculture Data Science Project, bạn sẽ xây dựng hệ thống gợi ý cây trồng đơn giản bằng machine learning có giám sát và lựa chọn đặc trưng. Làm việc với bốn thuộc tính đất quan trọng: nitơ, phốt pho, kali và pH. Bạn sẽ đối mặt với ràng buộc thực tế: người nông dân chỉ có thể đo một thuộc tính. Nhiệm vụ của bạn là xác định đặc trưng đơn lẻ nào dự đoán tốt nhất loại cây trồng phù hợp và sau đó huấn luyện một bộ phân loại gọn nhẹ để đưa ra khuyến nghị một cách tin cậy.
Bạn sẽ luyện tập các kỹ năng thực tế như xử lý giá trị thiếu, mã hóa nhãn, chuẩn hóa đặc trưng, đánh giá mô hình, và quan trọng nhất là áp dụng và so sánh hai kỹ thuật chọn đặc trưng để xếp hạng các thước đo đất.
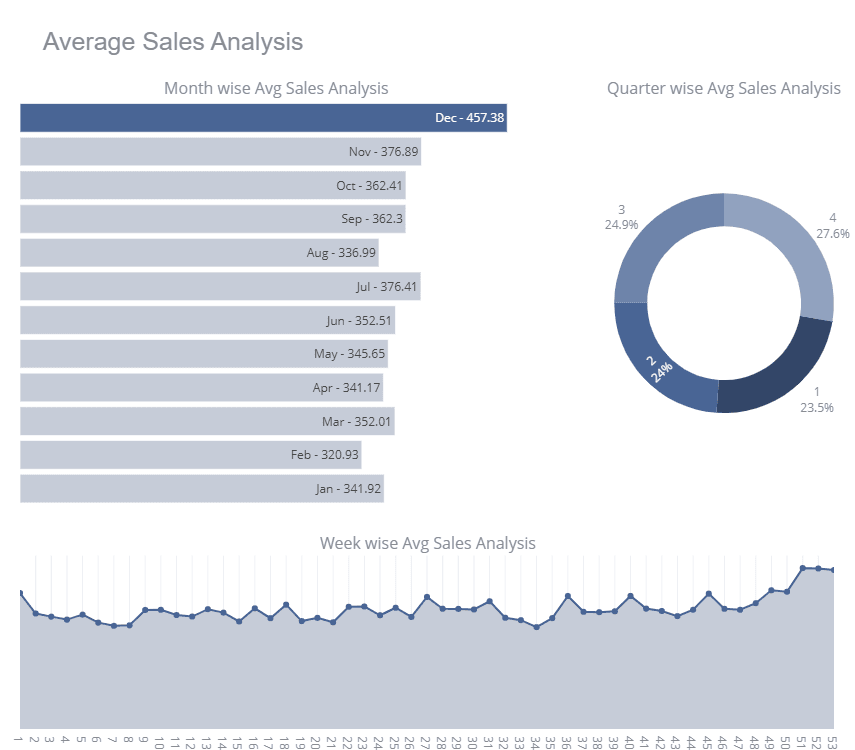
Store Sales là cuộc thi nhập môn trên Kaggle, nơi người tham gia huấn luyện nhiều mô hình chuỗi thời gian để cải thiện điểm trên bảng xếp hạng. Trong dự án, bạn sẽ được cung cấp dữ liệu doanh số cửa hàng, và bạn sẽ làm sạch dữ liệu, thực hiện phân tích chuỗi thời gian chuyên sâu, chuẩn hóa đặc trưng, và huấn luyện mô hình chuỗi thời gian đa biến.
Để cải thiện điểm số, bạn có thể dùng phương pháp tổ hợp như Bagging và Voting Regressors.
Hình ảnh từ Kaggle
Store Sales là dự án dựa trên Kaggle, nơi bạn có thể xem notebook của những người tham gia khác.
Để cải thiện hiểu biết về dự báo chuỗi thời gian, hãy thử áp dụng kỹ năng của bạn cho bộ dữ liệu Sở giao dịch chứng khoán và dùng Facebook Prophet để huấn luyện mô hình dự báo chuỗi thời gian đơn biến.
Những dự án machine learning trung cấp này tập trung vào xử lý dữ liệu và huấn luyện mô hình cho cả bộ dữ liệu có cấu trúc và không cấu trúc. Học cách làm sạch, xử lý và bổ sung dữ liệu bằng nhiều công cụ thống kê khác nhau.
Dự án Reveal Categories Found in Data giúp bạn khám phá phản hồi của khách hàng bằng phân cụm và xử lý ngôn ngữ tự nhiên (NLP). Bạn sẽ sắp xếp các đánh giá trên Google Play Store thành các nhóm riêng biệt bằng K-means. Hiểu các chủ đề chung từ phản hồi khách hàng rất quan trọng đối với đội ngũ phát triển sản phẩm để giải quyết điểm đau, cải thiện tính năng và nâng cao sự hài lòng của người dùng thông qua insight có thể hành động.
Hãy thử tái lập kết quả trên bộ dữ liệu khác, như bộ dữ liệu Phim Netflix.
Trong dự án Word Frequency in Moby Dick, bạn sẽ thu thập văn bản tiểu thuyết Moby Dick của Herman Melville và phân tích tần suất từ bằng thư viện nltk của Python. Dự án này giới thiệu các kỹ thuật NLP then chốt và giúp bạn hiểu cách những từ được sử dụng thường xuyên tiết lộ các mẫu trong văn bản. Đây là dự án tuyệt vời cho người yêu văn học, nhà sử học hoặc nhà nghiên cứu quan tâm đến khai phá văn bản và phân tích ngôn ngữ học.
Trong dự án Facial Recognition with Supervised Learning, bạn sẽ xây dựng mô hình nhận diện khuôn mặt bằng các kỹ thuật học có giám sát với Python và scikit-learn. Mô hình phân biệt ảnh của Arnold Schwarzenegger và những người khác. Dự án này quan trọng trong lĩnh vực công nghệ nhận diện khuôn mặt đang phát triển, có ứng dụng rộng rãi trong bảo mật, hệ thống xác thực, và thậm chí trên nền tảng mạng xã hội nơi nhận diện khuôn mặt được sử dụng phổ biến.
Xây dựng bộ dự đoán độ phổ biến sách cho một hiệu sách trực tuyến bằng cách chuyển đổi dữ liệu hỗn hợp, như văn bản (ví dụ: tiêu đề và mô tả sách) và dữ liệu số (ví dụ: xếp hạng và số lượt đánh giá), thành các đặc trưng hiệu quả. Bạn sẽ tham gia toàn bộ quy trình machine learning, bao gồm EDA nhanh, chỉnh kiểu dữ liệu, biến đổi cả biến văn bản lẫn số, và tinh chỉnh mô hình để đạt độ chính xác cao nhất có thể.
Bạn sẽ học cách quản lý dữ liệu lộn xộn, đa định dạng và đánh giá kết quả bằng một pipeline sạch, có thể tái sử dụng. Kết thúc quy trình, bạn có thể áp dụng cùng phương pháp cho bất kỳ danh mục nào, dù là danh sách đọc cá nhân hay bộ dữ liệu công khai, để dự đoán các tựa sách tiềm năng bán chạy và nâng cao hệ thống gợi ý.
Trong dự án Clustering Antarctic Penguin Species, bạn dùng học không giám sát để khám phá các nhóm tự nhiên của chim cánh cụt mà không cần nhãn. Bạn sẽ làm sạch bộ dữ liệu phong cách Palmer Penguins, xử lý giá trị thiếu, chuẩn hóa các đặc trưng số như chiều dài, độ sâu mỏ, chiều dài vây và khối lượng cơ thể, và tùy chọn mã hóa các biến phân loại đơn giản như đảo hoặc giới tính trước khi áp dụng phân cụm K-means.
Sau đó bạn chọn số cụm bằng tiêu chí khuỷu tay và điểm silhouette, trực quan hóa cấu trúc với PCA, và so sánh cụm với loài đã biết để kiểm tra nhanh tính hợp lý.
Trong dự án Taxi Route Optimization with Reinforcement Learning, bạn huấn luyện một tác tử Q-learning để giải bài toán môi trường Taxi-v3 của Gymnasium bằng cách học các lộ trình đón trả khách hiệu quả. Bạn sẽ xây dựng bảng giá trị trạng thái–hành động, cân bằng khám phá và khai thác với chính sách epsilon-greedy, và tinh chỉnh các siêu tham số cốt lõi như tốc độ học, hệ số chiết khấu, và tốc độ giảm epsilon để tăng tốc hội tụ.

Tiếp đó, bạn đánh giá hiệu suất bằng phần thưởng trung bình mỗi tập và số bước để hoàn thành, trực quan hóa đường cong học, và thử nghiệm chính sách đã huấn luyện trên các tập chưa thấy trước đó.
Sử dụng bộ dữ liệu Ung thư vú Wisconsin để dự đoán một khối u là ác tính hay lành tính. Bộ dữ liệu bao gồm các đặc trưng của khối u, như kết cấu, chu vi và diện tích, và mục tiêu của bạn là xây dựng mô hình phân loại dự đoán chẩn đoán dựa trên các đặc tính này.
Dự án này thiết yếu trong các ứng dụng y tế, cung cấp insight có giá trị cho phân tích dữ liệu y khoa và tiềm năng phát triển công cụ chẩn đoán hỗ trợ phát hiện sớm ung thư.
Trong dự án Speech Emotion Recognition with Librosa, bạn sẽ xử lý tệp âm thanh bằng Librosa, soundfile, và sklearn cho MLPClassifier để nhận diện cảm xúc từ tệp âm thanh.
Bạn sẽ tải và xử lý tệp âm thanh, trích xuất đặc trưng, và huấn luyện mô hình phân loại MLP nhiều lớp. Dự án sẽ dạy bạn những kiến thức cơ bản về xử lý âm thanh để bạn có thể tiến tới huấn luyện mô hình học sâu nhằm đạt độ chính xác tốt hơn.
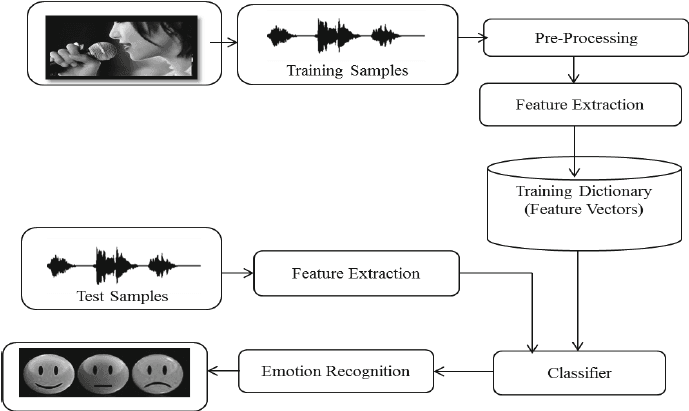
Hình ảnh từ researchgate.net
Những dự án machine learning nâng cao này tập trung vào xây dựng và huấn luyện mô hình học sâu và xử lý bộ dữ liệu không cấu trúc. Bạn sẽ huấn luyện mạng nơ-ron tích chập, GRU, tinh chỉnh các mô hình ngôn ngữ lớn và mô hình học tăng cường.
Trong dự án Service Desk Ticket Classification with Deep Learning, bạn xây dựng bộ phân loại văn bản bằng PyTorch để tự động chuyển hướng ticket đến đúng danh mục. Bạn sẽ làm sạch và tách token văn bản, tạo tập huấn luyện và xác thực, chuyển ticket thành biểu diễn vector, và huấn luyện mô hình nơ-ron gọn nhẹ đồng thời tinh chỉnh batch size, learning rate, và regularization để hội tụ ổn định.
Sau đó bạn đánh giá bằng accuracy và weighted F1, kiểm tra ma trận nhầm lẫn để phát hiện các danh mục gán nhãn sai hoặc chồng lấn, và áp dụng các kỹ thuật xử lý mất cân bằng như trọng số mất mát.
Trong dự án Build Rick Sanchez Bot Using Transformers, bạn sẽ sử dụng DialoGPT và thư viện Hugging Face Transformer để xây dựng chatbot chạy bằng AI.
Bạn sẽ xử lý và biến đổi dữ liệu, xây dựng và tinh chỉnh Mô hình Tạo phản hồi Tiền huấn luyện quy mô lớn của Microsoft (DialoGPT) trên bộ dữ liệu hội thoại Rick and Morty. Bạn cũng có thể tạo một ứng dụng Gradio đơn giản để kiểm thử mô hình theo thời gian thực: Rick & Morty Block Party.
Dự án Building an E-Commerce Clothing Classifier Model with Keras tập trung vào phân loại ảnh trong bối cảnh thương mại điện tử. Bạn sẽ dùng Keras để xây dựng mô hình machine learning tự động phân loại quần áo dựa trên hình ảnh. Điều này hữu ích để cải thiện trải nghiệm mua sắm bằng cách giúp khách hàng tìm sản phẩm nhanh hơn và tối ưu quản lý tồn kho. Phân loại chính xác cũng hỗ trợ gợi ý cá nhân hóa, thúc đẩy mức độ tương tác và doanh số.
Trong dự án Detect Traffic Signs with Deep Learning, bạn sẽ dùng Keras để phát triển mô hình học sâu có khả năng phát hiện các biển báo giao thông, như biển dừng và đèn tín hiệu. Công nghệ này rất quan trọng đối với xe tự hành, nơi việc nhận diện tín hiệu đường bộ nhanh và chính xác là thiết yếu để điều hướng an toàn. Dự án đặt nền tảng cho việc phát triển hệ thống xe tự lái tiên tiến, an toàn và đáng tin cậy hơn.
Trong dự án Building a Demand Forecasting Model, bạn sử dụng PySpark để dự đoán nhu cầu sản phẩm thương mại điện tử ở quy mô lớn. Bạn sẽ tải dữ liệu giao dịch, tạo đặc trưng theo thời gian như độ trễ và trung bình trượt, tách theo thời gian để đánh giá trung thực, và huấn luyện một mô hình cơ sở cùng mô hình học như Gradient-Boosted Trees hoặc Random Forest để nắm bắt xu hướng và tính thời vụ.
Sau đó bạn đánh giá bằng MAE, RMSE, và MAPE, so sánh với mô hình cơ sở, và phân tích lỗi theo SKU và theo cửa sổ thời gian để phát hiện thiên lệch và biến động.
Trong dự án Predicting Temperature in London, bạn chạy một thí nghiệm ML có cấu trúc để dự báo nhiệt độ trung bình hằng ngày từ dữ liệu thời tiết lịch sử. Bạn sẽ tải và làm sạch dữ liệu, tạo chia tách theo thời gian, kỹ sư đặc trưng như trung bình trượt và giá trị trễ, và huấn luyện một số mô hình ứng viên bằng scikit-learn.
Sau đó bạn điều phối quy trình bằng các hàm có thể tái sử dụng và theo dõi mọi thứ trong MLflow, ghi lại tham số, chỉ số và artifact để so sánh các lần chạy.
Connect X là cuộc thi mô phỏng của Kaggle. Xây dựng một tác tử RL (Reinforcement Learning) để thi đấu với những người tham gia khác trên Kaggle.
Trước tiên bạn sẽ tìm hiểu cách trò chơi hoạt động và tạo một tác tử đơn giản làm mốc cơ sở. Sau đó, bạn bắt đầu thử nghiệm với nhiều thuật toán RL và kiến trúc mô hình khác nhau. Bạn có thể thử xây dựng mô hình dựa trên Deep Q-learning hoặc thuật toán Proximal Policy Optimization.
Dự án năm cuối yêu cầu bạn dành thời gian nhất định để tạo ra một giải pháp độc đáo. Bạn sẽ nghiên cứu nhiều kiến trúc mô hình, sử dụng nhiều khung machine learning để chuẩn hóa và tăng cường dữ liệu, hiểu toán học phía sau quy trình, và viết luận văn dựa trên kết quả.
Trong mô hình Multi-Lingual ASR, bạn sẽ tinh chỉnh mô hình Wave2Vec XLS-R bằng âm thanh và bản chép tiếng Thổ Nhĩ Kỳ để xây dựng hệ thống nhận dạng giọng nói tự động.
Đầu tiên, bạn sẽ hiểu bộ dữ liệu âm thanh và văn bản, sau đó dùng bộ tokenizer văn bản, trích xuất đặc trưng, và xử lý tệp âm thanh. Tiếp theo, bạn sẽ tạo trainer, hàm WER, tải mô hình tiền huấn luyện, tinh chỉnh siêu tham số, và huấn luyện cũng như đánh giá mô hình.
Bạn có thể dùng nền tảng Hugging Face để lưu trọng số mô hình và xuất bản ứng dụng web chép lời theo thời gian thực: Streaming Urdu Asr.
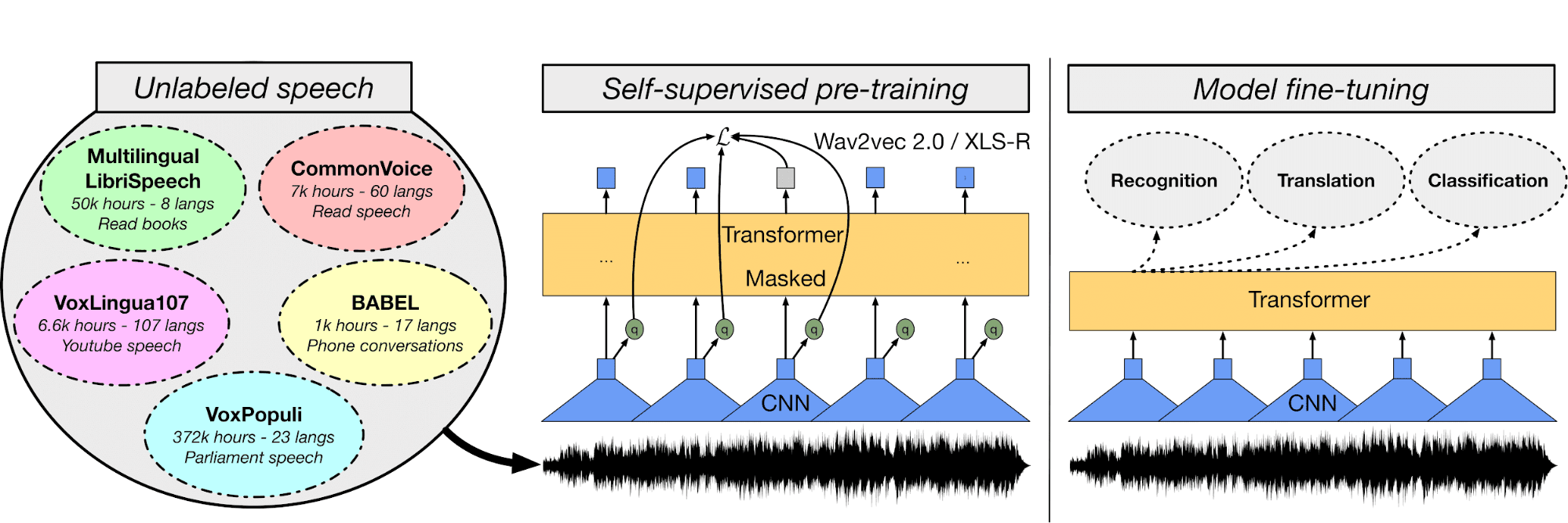
Hình ảnh từ huggingface.co
Trong dự án One Shot Face Stylization, bạn có thể hoặc chỉnh sửa mô hình để cải thiện kết quả, hoặc tinh chỉnh JoJoGAN trên bộ dữ liệu mới để tạo ứng dụng phong cách hóa của riêng bạn.
Dự án sẽ dùng ảnh gốc để tạo ảnh mới bằng đảo chiều GAN và tinh chỉnh StyleGAN đã tiền huấn luyện. Bạn sẽ hiểu nhiều kiến trúc mạng GAN khác nhau. Sau đó, bạn bắt đầu thu thập bộ dữ liệu ghép cặp để tạo phong cách theo ý muốn.
Tiếp đó, với sự hỗ trợ từ lời giải mẫu của phiên bản StyleGAN trước, bạn sẽ thử nghiệm kiến trúc mới để tạo tác phẩm nghệ thuật chân thực.
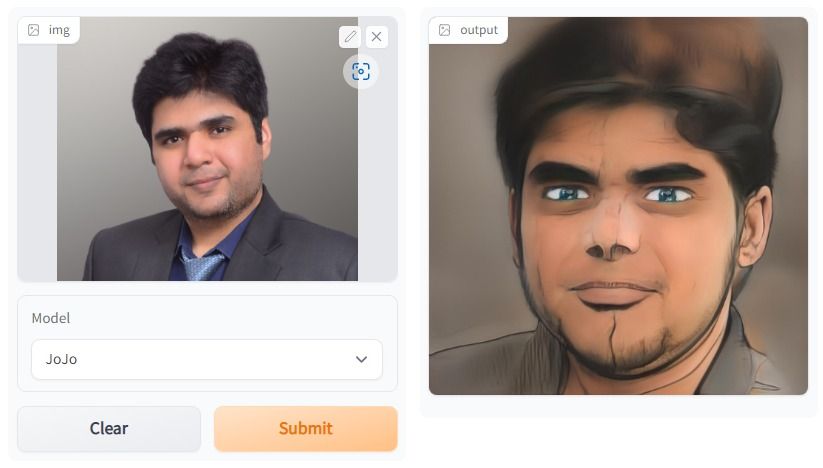
Hình ảnh được tạo bằng JoJoGAN
Trong dự án H&M Personalized Fashion Recommendations, bạn sẽ xây dựng gợi ý sản phẩm dựa trên giao dịch trước đó, dữ liệu khách hàng và siêu dữ liệu sản phẩm.
Dự án sẽ kiểm tra kỹ năng NLP, CV (Computer Vision), và học sâu của bạn. Trong vài tuần đầu, bạn sẽ hiểu dữ liệu và cách dùng các đặc trưng khác nhau để xây dựng mốc cơ sở.
Sau đó, tạo mô hình đơn giản chỉ dùng văn bản và thuộc tính phân loại để dự đoán gợi ý. Tiếp theo, kết hợp NLP và CV để cải thiện điểm số trên bảng xếp hạng. Bạn cũng có thể hiểu vấn đề tốt hơn bằng cách xem thảo luận và mã từ cộng đồng.

Hình ảnh từ H&M EDA FIRST LOOK
Trong dự án Analyzing Customer Support Calls, bạn xây dựng pipeline đầu-cuối biến âm thanh thô thành insight. Bạn sẽ chép lời cuộc gọi bằng mô hình nhận dạng giọng nói tự động, làm sạch và phân đoạn văn bản, chạy phân tích cảm xúc, và trích xuất thực thể như sản phẩm, gói dịch vụ, địa điểm, và tên riêng. Bạn cũng sẽ đánh chỉ mục bản chép bằng embedding để hỗ trợ tìm kiếm ngữ nghĩa nhanh trên các cuộc hội thoại.
Sau đó bạn đánh giá chất lượng chép lời và hiệu suất mô hình, phân cụm chủ đề để lộ ra các nguyên nhân gọi phổ biến, và làm nổi bật các điểm như đỉnh cảm xúc tiêu cực hoặc từ khóa leo thang.
Trong dự án Monitoring A Financial Fraud Detection Model, bạn đóng vai trò nhà khoa học dữ liệu hậu triển khai cho một ngân hàng tại Vương quốc Anh, chẩn đoán vì sao mô hình phát hiện gian lận đang hoạt động bị tụt hiệu suất. Bạn sẽ tải dự đoán và kết quả thực tế trong môi trường sản xuất, theo dõi các chỉ số cốt lõi như precision, recall, PR-AUC và hiệu chỉnh, và trực quan hóa hiệu suất theo thời gian để phát hiện suy giảm. Bạn cũng sẽ chia theo kênh, khu vực và phân khúc khách hàng để tìm nơi tập trung của dương tính giả hoặc âm tính giả.
Sau đó bạn kiểm tra trôi dữ liệu và trôi khái niệm bằng các phép kiểm tra phân phối và chỉ số ổn định, xem xét dịch chuyển tầm quan trọng đặc trưng, và dùng công cụ giải thích để so sánh hành vi hiện tại với mốc cơ sở.
Trong dự án MuZero for Atari 2600, bạn sẽ xây dựng, huấn luyện, và đánh giá tác tử học tăng cường bằng thuật toán MuZero cho các trò chơi Atari 2600. Đọc hướng dẫn để hiểu thêm về thuật toán MuZero.
Mục tiêu là xây dựng kiến trúc mới hoặc chỉnh sửa kiến trúc hiện có để cải thiện điểm số trên bảng xếp hạng toàn cầu. Sẽ mất hơn ba tháng để hiểu cách thuật toán hoạt động trong học tăng cường.
Dự án này đòi hỏi nhiều toán học và yêu cầu bạn thành thạo Python. Bạn có thể tìm các lời giải đề xuất, nhưng để đạt thứ hạng cao, bạn phải tự xây dựng lời giải của mình.
Dự án MLOps End-To-End Machine Learning là cần thiết để bạn được tuyển bởi các công ty hàng đầu. Ngày nay, nhà tuyển dụng tìm kiếm kỹ sư ML có thể tạo hệ thống đầu-cuối bằng công cụ MLOps, điều phối dữ liệu và điện toán đám mây.
Trong dự án này, bạn sẽ xây dựng và triển khai bộ phân loại hình ảnh địa điểm bằng TensorFlow, Streamlit, Docker, Kubernetes, cloudbuild, GitHub và Google Cloud. Mục tiêu chính là tự động hóa việc xây dựng và triển khai mô hình machine learning vào sản xuất bằng CI/CD. Để được hướng dẫn, hãy đọc hướng dẫn Machine Learning, Pipelines, Deployment, and MLOps.
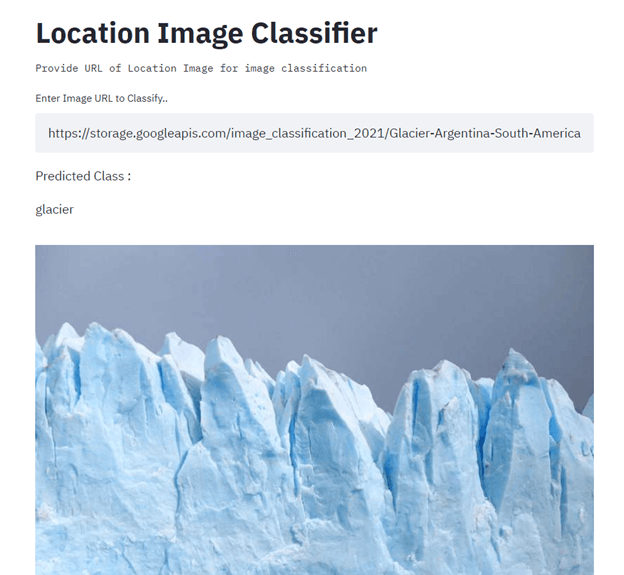
Hình ảnh từ Senthil E
Để xây dựng hồ sơ machine learning, bạn cần những dự án nổi bật. Hãy cho nhà tuyển dụng thấy bạn có thể viết mã bằng nhiều ngôn ngữ, hiểu các khung machine learning khác nhau, giải các bài toán độc đáo bằng machine learning, và nắm hệ sinh thái machine learning đầu-cuối.
Trong dự án Fine-Tuning GPT-OSS, bạn sẽ cài đặt phụ thuộc, tải mô hình và tokenizer, định nghĩa phong cách prompt rõ ràng với gói Harmony cho Python, và chạy suy luận cơ sở nhanh để xác nhận mọi thứ hoạt động đầu-cuối.
Sau đó bạn chuẩn bị bộ dữ liệu Hỏi & Đáp y khoa với định dạng Harmony, cấu hình huấn luyện và tinh chỉnh mô hình, tiếp theo là đánh giá sau tinh chỉnh để đo lường cải thiện.
Trong dự án Fine-Tuning MedGemma on a Brain MRI Dataset, bạn điều chỉnh mô hình đa phương thức MedGemma 4B, bộ mã hóa ảnh SigLIP, cộng với LLM tinh chỉnh cho y khoa, để phân loại ảnh MRI não. Bạn sẽ thiết lập môi trường trên RunPod, cài đặt các gói Python cần thiết, tải và làm sạch bộ dữ liệu MRI, và chuẩn bị đầu vào với kích thước đồng nhất, chuẩn hóa và ánh xạ nhãn trước khi chạy suy luận kiểm tra nhanh.
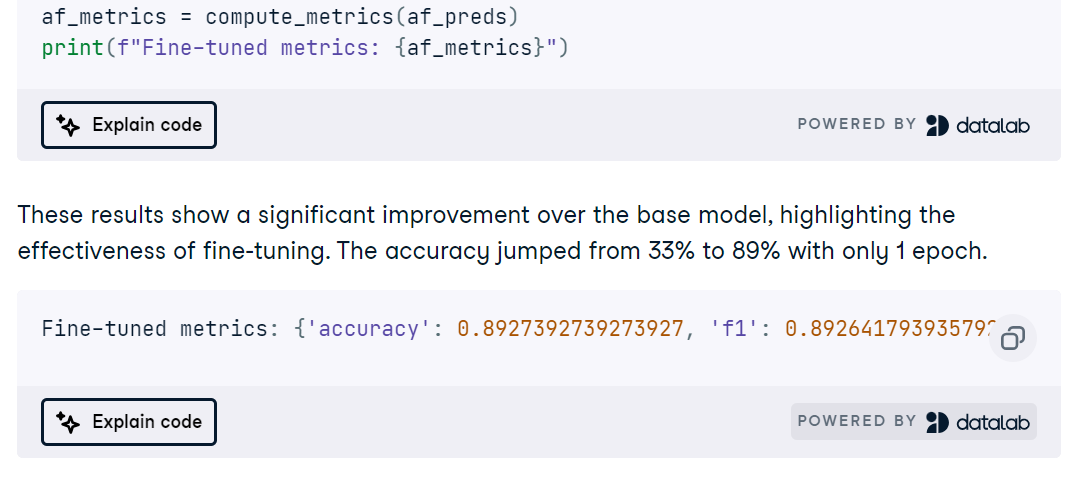
Tiếp đó bạn tinh chỉnh MedGemma cho tác vụ MRI, theo dõi đường cong huấn luyện, và đánh giá bằng accuracy, ROC AUC, precision, recall, và ma trận nhầm lẫn để phát hiện chế độ lỗi.
Trong dự án Fine-tuning Stable Diffusion XL with DreamBooth and LoRA, bạn thiết lập SDXL trong Python với Diffusers, tải mô hình base FP16 và VAE trên GPU CUDA, và tạo ảnh từ prompt ngắn. Bạn sẽ khám phá cách tăng chất lượng nhanh với SDXL refiner, so sánh đầu ra, và dùng tiện ích lưới đơn giản để xem nhiều ảnh sinh song song.
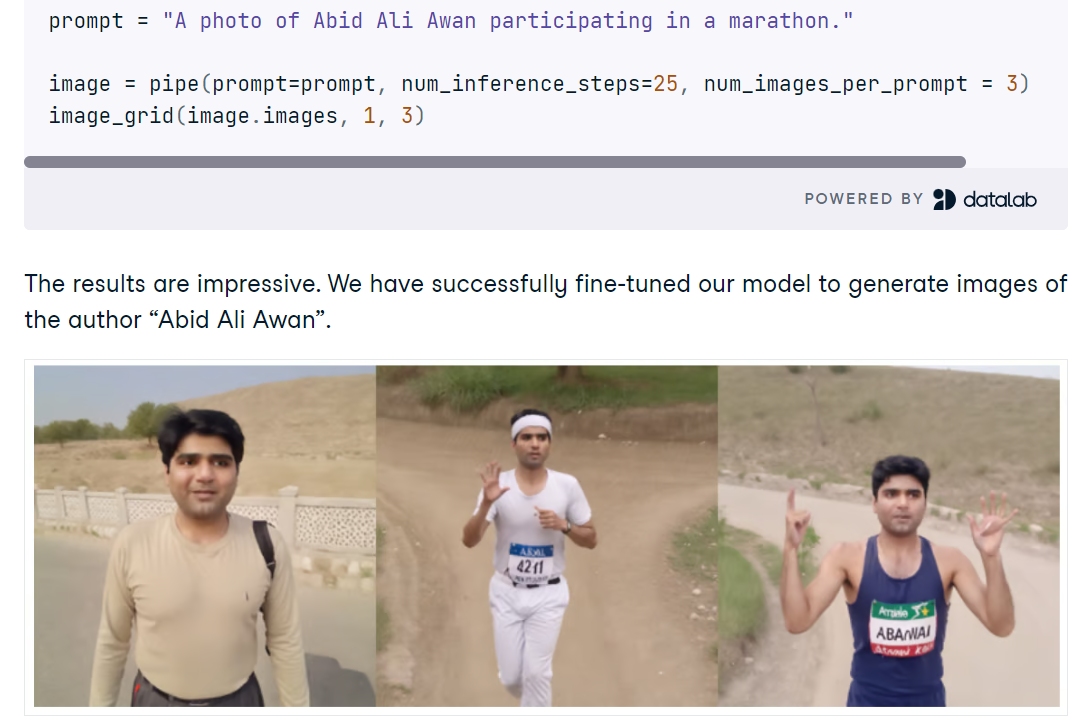
Tiếp theo bạn tinh chỉnh SDXL trên một tập nhỏ ảnh cá nhân bằng AutoTrain Advanced với DreamBooth, tạo ra bộ thích ứng LoRA gọn nhẹ thay vì checkpoint đầy đủ để suy luận nhanh và tiết kiệm bộ nhớ. Sau huấn luyện, bạn gắn trọng số LoRA vào pipeline base, thử prompt mới, và đánh giá khi nào refiner giúp hoặc làm giảm độ trung thực nhận dạng.
Trong dự án Song Generation with Latent Diffusion, bạn thiết lập mô hình tạo nhạc khuếch tán mã nguồn mở để tạo các bài hát hoàn chỉnh từ prompt phong cách bằng văn bản hoặc một đoạn âm thanh tham chiếu. Bạn sẽ cài đặt qua Conda hoặc Docker, chuẩn bị môi trường (đường dẫn espeak-ng, phonemizer trên Windows), và chạy các script suy luận đi kèm để tạo bản nhạc với checkpoint base hoặc đầy đủ, bật giải mã theo khối khi VRAM hạn chế.
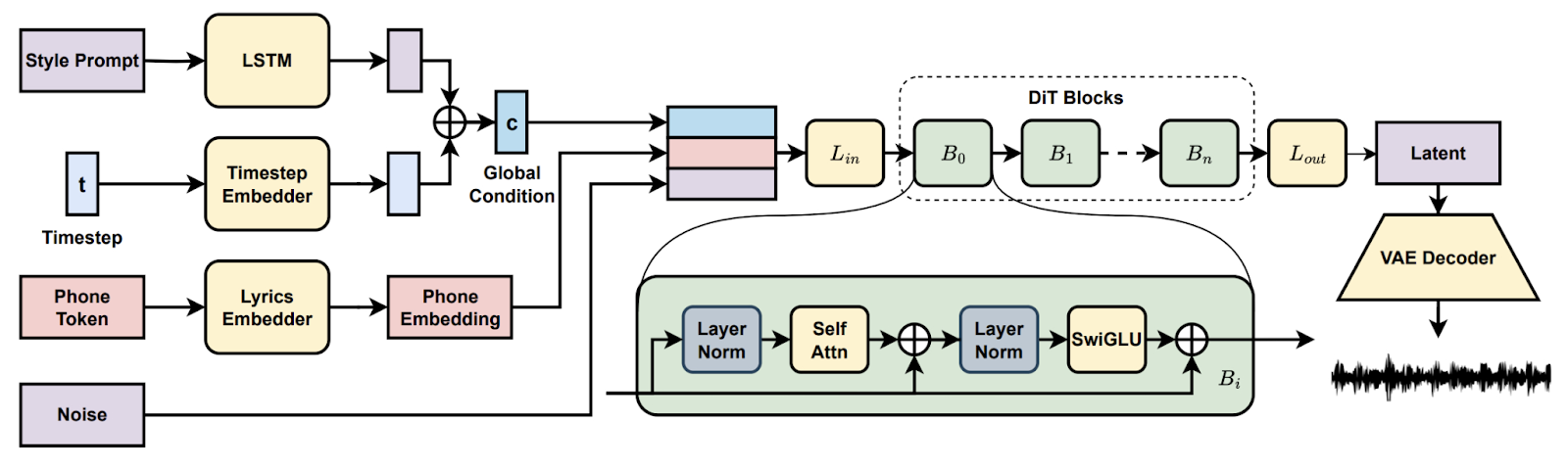
Sau đó bạn khám phá các tính năng như tiếp tục bài hát và chỉnh sửa, so sánh phối khí theo từng prompt, và ghi lại thiết lập để tái lập. Cuối cùng, bạn có một pipeline thực tế cho quy trình sáng tạo âm nhạc đầu-cuối.
Trong dự án Deploying a Machine Learning Application to Production, bạn xây dựng pipeline ML tự động hoàn toàn với GitHub Actions để huấn luyện, đánh giá, quản lý phiên bản và triển khai một mô hình phân loại thuốc đơn giản. Bạn thiết lập cấu trúc repo và Makefile, thêm thiết lập môi trường, linting, unit test, và kiểm tra dữ liệu, sau đó viết script cho các lần huấn luyện và đánh giá có thể tái lập, ghi lại chỉ số và artifact.
Tiếp đó bạn nối quy trình tích hợp liên tục để kích hoạt khi có pull request và đẩy lên nhánh chính, xuất bản artifact mô hình với CML và Hugging Face CLI, và đưa mô hình đã qua kiểm duyệt vào triển khai thông qua workflow triển khai liên tục.
Hình ảnh do Tác giả cung cấp
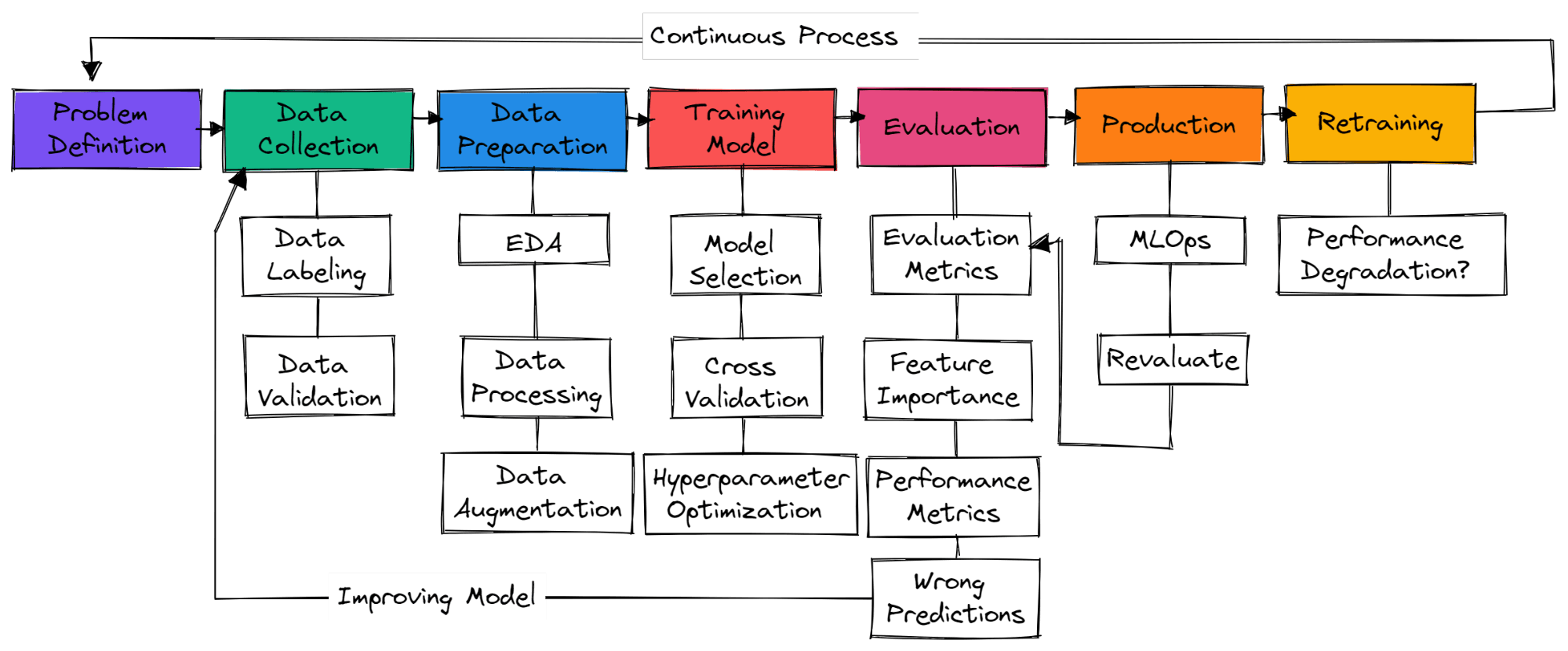
Không có các bước tiêu chuẩn cố định trong một dự án machine learning điển hình. Vì vậy, đôi khi chỉ là thu thập dữ liệu, chuẩn bị dữ liệu và huấn luyện mô hình. Trong phần này, chúng ta sẽ tìm hiểu các bước cần thiết để xây dựng dự án machine learning sẵn sàng cho sản xuất.
Bạn cần hiểu bài toán kinh doanh và nảy ra ý tưởng sơ bộ về cách bạn sẽ dùng machine learning để giải quyết. Tìm kiếm bài báo nghiên cứu, dự án nguồn mở, hướng dẫn, và ứng dụng tương tự được các công ty khác sử dụng. Hãy đảm bảo giải pháp của bạn thực tế và dữ liệu có thể dễ dàng thu thập.
Bạn sẽ thu thập dữ liệu từ nhiều nguồn, làm sạch và gán nhãn, và tạo script để kiểm định dữ liệu. Hãy đảm bảo dữ liệu của bạn không thiên lệch hoặc chứa thông tin nhạy cảm.
Điền giá trị thiếu, làm sạch và xử lý dữ liệu phục vụ phân tích. Dùng công cụ trực quan hóa để hiểu phân phối dữ liệu và cách bạn có thể dùng các đặc trưng để cải thiện hiệu suất mô hình. Chuẩn hóa đặc trưng và tăng cường dữ liệu được dùng để biến đổi dữ liệu cho mô hình machine learning.
lựa chọn mạng nơ-ron hoặc thuật toán machine learning thường dùng cho các bài toán cụ thể. Huấn luyện mô hình bằng cross-validation và sử dụng nhiều kỹ thuật tối ưu siêu tham số để đạt kết quả tối ưu.
Đánh giá mô hình trên tập kiểm thử. Đảm bảo bạn dùng đúng thước đo đánh giá cho bài toán cụ thể. Accuracy không phải là thước đo phù hợp cho mọi bài toán. Kiểm tra điểm F1 hoặc AUC cho phân loại, hoặc RMSE cho hồi quy. Trực quan hóa độ quan trọng đặc trưng để loại bỏ các đặc trưng không quan trọng. Đánh giá các chỉ số hiệu năng như thời gian huấn luyện và suy luận của mô hình.
Đảm bảo mô hình đã vượt mốc cơ sở của con người. Nếu chưa, quay lại thu thập thêm dữ liệu chất lượng và bắt đầu lại quy trình. Đây là một quá trình lặp, nơi bạn sẽ tiếp tục huấn luyện với nhiều kỹ thuật tạo đặc trưng, kiến trúc mô hình và khung machine learning để cải thiện hiệu suất.
Sau khi đạt kết quả tối ưu, đã đến lúc triển khai mô hình machine learning của bạn lên môi trường sản xuất/đám mây bằng các công cụ MLOps. Giám sát mô hình trên dữ liệu thời gian thực. Hầu hết mô hình thất bại trong sản xuất, vì vậy nên triển khai cho một nhóm người dùng nhỏ trước.
Nếu mô hình không đạt kết quả mong muốn, bạn sẽ quay lại bước khởi đầu và đưa ra giải pháp tốt hơn. Ngay cả khi đạt kết quả tốt, mô hình có thể suy giảm theo thời gian do trôi dữ liệu và trôi khái niệm. Tái huấn luyện với dữ liệu mới cũng giúp mô hình thích ứng với thay đổi theo thời gian thực.
Khóa học về Machine learning
Courses
Courses
Courses