Kurs
Maschinelles Lernen mit PySpark
4 Std.
29.7K
Diese Machine-Learning-Projekte für Anfänger drehen sich um strukturierte, tabellarische Daten. Du wirst die Fähigkeiten der Datenbereinigung, -verarbeitung und -visualisierung für Analysezwecke anwenden und das scikit-learn-Framework nutzen, um Modelle für maschinelles Lernen zu trainieren und zu validieren.
Wenn du zuerst die grundlegenden Konzepte des maschinellen Lernens lernen möchtest, haben wir einen super Kurs zum Thema maschinelles Lernen, der ganz ohne Programmierkenntnisse auskommt. Wenn du deine Fähigkeiten in diesem Bereich verbessern willst, kannst du dir auch einige unserer KI-Projekte anschauen.
Im Projekt „Predict Energy Consumption“ (Energieverbrauch vorhersagen) wirst du Regressions- und Machine-Learning-Modelle nutzen, um den täglichen Stromverbrauch anhand von zeitlichen Faktoren wie Tageszeit und Temperatur vorherzusagen. Das Ziel ist, Muster zu finden, die den Energieverbrauch optimieren, die Effizienz steigern und die Kosten senken können. Das ist besonders wichtig für Versorgungsunternehmen und Firmen, die ihre Betriebskosten senken, Energie sparen und ihre Ressourcen nachhaltiger verwalten wollen.
Das Projekt „Predict Energy Consumption“ ist ein geführtes Projekt, aber du kannst die Ziele auf einen anderen Datensatz übertragen, wie zum Beispiel die Nachfrage nach Fahrradverleihsystemen in Seoul. Wenn du mit einem komplett neuen Datensatz arbeitest, kannst du deinen Code besser debuggen und deine Fähigkeiten zum Lösen von Problemen verbessern.
Im Projekt „Von Daten zu Dollars – Vorhersage von Versicherungsbeiträgen “ schlüpfst du in die Rolle eines Datenwissenschaftlers bei einer Krankenkasse. Du wirst ein Vorhersagemodell erstellen, um die Versicherungsgebühren anhand der Eigenschaften eines Kunden, wie Alter und Gesundheitsfaktoren, zu schätzen. Dieses Projekt zeigt, wie man maschinelles Lernen in der Wirtschaft praktisch nutzen kann. Es hilft dabei, genauere Preismodelle zu entwickeln und Unternehmen dabei zu unterstützen, Risiken zu managen, während sie ihren Kunden personalisierte Preisstrategien anbieten.
Das Projekt „Vorhersage von Versicherungsgebühren“ ist ein geführtes Projekt. Du kannst das Ergebnis auf einen anderen Datensatz übertragen, zum Beispiel auf den Datensatz „Hotelbuchungsnachfrage “. Du kannst damit vorhersagen, ob ein Kunde die Buchung stornieren wird oder nicht.
Im Projekt „Vorhersage von Kreditkartenbewilligungen ” entwickelst du eine automatische Anwendung zur Kreditkartenbewilligung mithilfe von Hyperparameteroptimierung und logistischer Regression.
Du wirst lernen, wie man mit fehlenden Werten umgeht, kategoriale Merkmale verarbeitet, Merkmale skaliert, mit unausgewogenen Daten arbeitet und mit GridCV eine automatische Hyperparameteroptimierung durchführt. Dieses Projekt wird dich aus deiner Komfortzone herausholen, in der du mit einfachen und sauberen Daten arbeitest.

Bild vom Autor
Die Vorhersage von Kreditkartenbewilligungen ist ein geführtes Projekt. Du kannst das Ergebnis auf einen anderen Datensatz übertragen, zum Beispiel auf die Kreditdaten von LendingClub.com. Du kannst es nutzen, um einen automatischen Kreditgenehmigungsprädiktor zu erstellen.
Du könntest ein Projekt zur Vorhersage der Weinqualität auf die Beine stellen, indem du einen Datensatz mit den physikalisch-chemischen Eigenschaften von Wein wie Alkoholgehalt, Säuregehalt und Zuckergehalt nutzt. Mit Klassifizierungsmodellen, wie der logistischen Regression in scikit-learn, kannst du Weine auf einer Skala von 1 bis 10 einstufen.
Dieses Projekt ist wichtig für die Weinindustrie und die Qualitätskontrolle, weil es ihnen hilft, die Weinqualität immer im Blick zu behalten und vorherzusagen, um so die Qualität der Produkte zu sichern.
Im Projekt „Prädiktive Modellierung für die Landwirtschaft – Datenwissenschaft“baust du ein einfaches System zur Empfehlung von Nutzpflanzen, indem du überwachtes maschinelles Lernen und Merkmalsauswahl einsetzt. Wir arbeiten mit vier wichtigen Bodenattributen: Stickstoff, Phosphor, Kalium und pH-Wert. Du wirst mit einer realistischen Einschränkung konfrontiert: Der Bauer kann sich nur eine Messung leisten. Deine Aufgabe ist es, herauszufinden, welches einzelne Merkmal die richtige Ernte am besten vorhersagt, und dann einen einfachen Klassifikator zu trainieren, damit er diese Empfehlung zuverlässig abgeben kann.
Du wirst praktische Fähigkeiten trainieren, wie zum Beispiel den Umgang mit fehlenden Werten, die Kodierung von Labels, die Skalierung von Merkmalen, die Bewertung von Modellen und vor allem die Anwendung und den Vergleich von zwei Techniken zur Merkmalsauswahl, um Bodenmessungen zu bewerten.
Store Sales ist ein Kaggle-Wettbewerb für Einsteiger, bei dem die Teilnehmer verschiedene Zeitreihenmodelle trainieren, um ihre Punktzahl in der Rangliste zu verbessern. Im Projekt kriegst du die Verkaufsdaten der Geschäfte und musst die Daten bereinigen, eine umfassende Zeitreihenanalyse durchführen, die Merkmale skalieren und das multivariate Zeitreihenmodell trainieren.
Um deine Punktzahl in der Rangliste zu verbessern, kannst du Ensembles wie Bagging und Voting Regressors nutzen.
Bild von Kaggle
Store Sales ist ein Kaggle-basiertes Projekt, bei dem du dir die Notizbücher der anderen Teilnehmer anschauen kannst.
Um dein Verständnis von Zeitreihenprognosen zu verbessern, probier doch mal, deine Kenntnisse auf den Börsendatensatz anzuwenden und mit Facebook Prophet ein univariates Zeitreihenprognosemodell zu trainieren.
Diese Projekte zum maschinellen Lernen für Fortgeschrittene drehen sich um Datenverarbeitung und Trainingsmodelle für strukturierte und unstrukturierte Datensätze. Lerne, wie du den Datensatz mit verschiedenen Statistik-Tools bereinigen, verarbeiten und erweitern kannst.
Mit dem Projekt „Reveal Categories Found in Data” kannst du Kundenfeedback mithilfe von Clustering und natürlicher Sprachverarbeitung (NLP) analysieren. Du ordnest Bewertungen aus dem Google Play Store mithilfe von K-Means-Clustering in verschiedene Kategorien ein. Es ist echt wichtig, die gemeinsamen Themen aus dem Kundenfeedback zu verstehen, damit die Produktentwicklungsteams die Probleme der Nutzer angehen, die Funktionen verbessern und die Zufriedenheit der Nutzer durch umsetzbare Erkenntnisse steigern können.
Versuch mal, das Ergebnis mit einem anderen Datensatz zu wiederholen, zum Beispiel mit dem Netflix-Filmdatensatz.
Im Projekt „Wortfrequenz in Moby Dick” wirst du den Text von Herman Melvilles Moby Dick scrapen und die Wortfrequenz mit der Python-Bibliothek nltk analysieren. Dieses Projekt zeigt wichtige Techniken der natürlichen Sprachverarbeitung (NLP) und hilft zu verstehen, wie häufig verwendete Wörter Muster im Text zeigen. Das ist ein super Projekt für Literaturfans, Historiker oder Forscher, die sich für Text Mining und Sprachanalyse interessieren.
Im Projekt „Gesichtserkennung mit überwachtem Lernen ” baust du ein Gesichtserkennungsmodell mit Python und scikit-learn, indem du Techniken des überwachten Lernens nutzt. Das Modell kann zwischen Bildern von Arnold Schwarzenegger und anderen Leuten unterscheiden. Dieses Projekt ist echt wichtig im wachsenden Bereich der Gesichtserkennungstechnologie, die man überall einsetzen kann, zum Beispiel in der Sicherheit, bei Authentifizierungssystemen und sogar auf Social-Media-Plattformen, wo die Gesichtserkennung oft genutzt wird.
Erstelle einen Prognosemodell für die Beliebtheit von Büchern für einen Online-Buchladen, indem du verschiedene Daten wie Text (z. B. Buchtitel und Beschreibungen) und Zahlen (z. B. Bewertungen und Verkaufszahlen) in nützliche Merkmale umwandelst. Du wirst dich mit dem kompletten Workflow des maschinellen Lernens beschäftigen, der eine schnelle explorative Datenanalyse (EDA), die Korrektur von Datentypen, die Transformation von Text- und numerischen Variablen sowie die Feinabstimmung eines Modells umfasst, um die höchstmögliche Genauigkeit zu erreichen.
Du lernst, wie du mit unübersichtlichen Daten in verschiedenen Formaten umgehst und die Ergebnisse mit einer übersichtlichen, wiederverwendbaren Pipeline auswertest. Am Ende dieses Prozesses kannst du die gleichen Methoden auf jeden Katalog anwenden, egal ob es sich um deine persönliche Leseliste oder öffentliche Datensätze handelt, um potenzielle Bestseller vorherzusagen und Empfehlungssysteme zu verbessern.
In der Projekt „Clustering Antarctic Penguin Species” nutzt man unüberwachtes Lernen, um natürliche Gruppen von Pinguinen ohne Beschriftungen zu finden. Du wirst einen Datensatz im Stil von Palmer Penguins bereinigen, fehlende Werte bearbeiten, numerische Merkmale wie Schnabelänge, Schnabelbreite, Flossenlänge und Körpermasse skalieren und optional einfache kategoriale Kontexte wie Insel oder Geschlecht kodieren, bevor du K-means.mass ausführst. Wenn du willst, kannst du einfache kategoriale Variablen wie Insel oder Geschlecht kodieren, bevor du das K-Means-Clustering machst.
Dann wählst du die Anzahl der Cluster anhand von Elbow- und Silhouette-Werten aus, visualisierst die Struktur mit PCA und vergleichst die Cluster mit bekannten Arten, um schnell zu checken, ob alles stimmt.
In der Projekt „Taxi-Routenoptimierung mit verstärktem Lernen” trainierst du einen Q-Learning-Agenten, um die Taxi-v3-Gymnasium-Umgebung zu meistern, indem er effiziente Abhol- und Zielrouten lernt. Du erstellst eine Zustands-Aktions-Wertetabelle, bringst Exploration und Ausnutzung mit einer Epsilon-Greedy-Strategie in Einklang und optimierst wichtige Hyperparameter wie Lernrate, Diskontfaktor und Epsilon-Abklingzeit, um die Konvergenz zu beschleunigen.

Dann schaust du dir die Leistung mit der durchschnittlichen Belohnung pro Episode und den Schritten bis zum Abschluss an, machst dir die Lernkurve klar und testest die trainierte Strategie an Episoden, die du noch nicht gesehen hast.
Nutze den Wisconsin-Brustkrebs-Datensatz, um vorherzusagen, ob ein Tumor bösartig oder gutartig ist. Der Datensatz enthält Infos zu den Merkmalen des Tumors, wie Textur, Umfang und Fläche. Deine Aufgabe ist es, ein Klassifizierungsmodell zu entwickeln, das anhand dieser Merkmale eine Diagnose vorhersagt.
Dieses Projekt ist super wichtig für Anwendungen im Gesundheitswesen, weil es echt wertvolle Einblicke in die Analyse medizinischer Daten und das Potenzial für die Entwicklung von Diagnosetools gibt, die bei der Früherkennung von Krebs helfen können.
Im Projekt „Sprach-Emotionserkennung mit Librosa ” bearbeitest du Audiodateien mit Librosa, Audiodateien und sklearn für den MLPClassifier, um Emotionen aus Audiodateien zu erkennen.
Du wirst Audiodateien laden und bearbeiten, Merkmalsextraktion durchführen und das Multi-Layer-Perceptron-Klassifikationsmodell trainieren. In diesem Projekt lernst du die Grundlagen der Audioverarbeitung kennen, damit du ein Deep-Learning-Modell trainieren kannst, um eine höhere Genauigkeit zu erreichen.
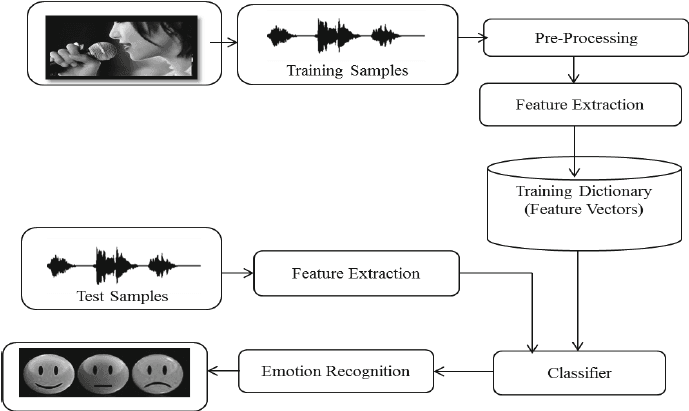
Bild von researchgate.net
Diese fortgeschrittenen Projekte im Bereich maschinelles Lernen drehen sich um die Entwicklung und das Training von Deep-Learning-Modellen und die Verarbeitung unstrukturierter Datensätze. Du wirst Faltungsneuronale Netze und Gated Recurrent Units trainieren, große Sprachmodelle feinabstimmen und Modelle für verstärktes Lernen entwickeln.
Im Projekt „Service Desk Ticket Classification with Deep Learning” baust du einen PyTorch-Textklassifikator, der eingehende Tickets automatisch der richtigen Kategorie zuordnet. Du wirst Text bereinigen und tokenisieren, Trainings- und Validierungssplits erstellen, Tickets in Vektordarstellungen umwandeln und ein kompaktes neuronales Modell trainieren, während du die Batchgröße, die Lernrate und die Regularisierung für eine stabile Konvergenz anpasst.
Dann bewertest du mit Genauigkeit und gewichtetem F1, schaust dir eine Verwechslungsmatrix an, um falsch beschriftete oder überlappende Kategorien zu finden, und wendest Techniken für Klassenungleichgewichte wie gewichteten Verlust an.
Im Projekt „Build Rick Sanchez Bot Using Transformers” wirst du DialoGPT und die Hugging Face Transformer-Bibliothek nutzen, um deinen KI-gestützten Chatbot zu erstellen.
Du wirst deine Daten bearbeiten und umwandeln, das groß angelegte, vorab trainierte Antwortgenerierungsmodell (DialoGPT) von Microsoft aufbauen und anhand des Dialogdatensatzes von Rick and Morty optimieren. Du kannst auch eine einfache Gradio-App erstellen, um dein Modell in Echtzeit zu testen: Rick & Morty Blockparty.
Das Projekt „Erstellen eines E-Commerce-Klassifizierungsmodells für Bekleidung mit Keras” beschäftigt sich mit der Bildklassifizierung im E-Commerce. Du wirst Keras nutzen, um ein Machine-Learning-Modell zu erstellen, das die Klassifizierung von Kleidung anhand von Bildern automatisch macht. Das ist wichtig, um das Einkaufserlebnis zu verbessern, indem Kunden Produkte schneller finden können und die Lagerverwaltung optimiert wird. Eine genaue Klassifizierung hilft auch bei personalisierten Empfehlungen, was die Kundenbindung und den Umsatz steigert.
Im Projekt „Verkehrszeichen mit Deep Learning erkennen “ wirst du mit Keras ein Deep-Learning-Modell entwickeln, das Verkehrszeichen wie Stoppschilder und Ampeln erkennen kann. Diese Technologie ist super wichtig für selbstfahrende Autos, wo man Verkehrszeichen schnell und genau erkennen muss, damit man sicher unterwegs ist. Dieses Projekt macht den Weg frei für die Entwicklung von noch fortschrittlicheren, sichereren und zuverlässigeren Systemen für selbstfahrende Autos.
Im Projekt „Erstellen eines Bedarfsprognosemodells” benutzt man PySpark, um die Nachfrage nach E-Commerce-Produkten in großem Maßstab vorherzusagen. Du lädst Transaktionsdaten, entwickelst zeitbasierte Funktionen wie Verzögerungen und gleitende Durchschnitte, teilst sie zur ehrlichen Bewertung nach Zeit auf und trainierst eine Baseline zusammen mit einem Lernmodell wie Gradient-Boosted Trees oder Random Forest, um Trends und Saisonalitäten zu erfassen.
Dann bewertest du mit MAE, RMSE und MAPE, vergleichst mit der Basislinie und analysierst Fehler nach SKU und Zeitfenster, um Verzerrungen und Schwankungen zu erkennen.
In der Projekt „Vorhersage der Temperatur in London“ führst du ein strukturiertes ML-Experiment durch, um die durchschnittliche Tagestemperatur anhand von historischen Wetterdaten vorherzusagen. Du wirst den Datensatz laden und bereinigen, zeitbezogene Aufteilungen erstellen, Funktionen wie gleitende Mittelwerte und verzögerte Werte entwickeln und mehrere Kandidatenmodelle mit scikit-learn trainieren.
Dann organisierst du den Workflow mit wiederverwendbaren Funktionen und behältst in MLflow den Überblick über alles, indem du Parameter, Metriken und Artefakte protokollierst, um die Durchläufe zu vergleichen.
Connect X ist ein Simulationswettbewerb von Kaggle. Entwickle einen RL-Agenten (Reinforcement Learning), um gegen andere Teilnehmer des Kaggle-Wettbewerbs anzutreten.
Du lernst zuerst, wie das Spiel läuft, und machst einen Dummy-Agenten, der funktioniert, als Ausgangspunkt. Danach wirst du anfangen, mit verschiedenen RL-Algorithmen und Modellarchitekturen rumzuexperimentieren. Du kannst versuchen, ein Modell auf Basis des Deep-Q-Learning- oder des Proximal-Policy-Optimization-Algorithmus zu erstellen.
Für das Abschlussprojekt musst du eine gewisse Zeit damit verbringen, eine einzigartige Lösung zu entwickeln. Du wirst verschiedene Modellarchitekturen untersuchen, verschiedene Frameworks für maschinelles Lernen nutzen, um die Datensätze zu normalisieren und zu erweitern, die Mathematik hinter dem Prozess verstehen und eine Abschlussarbeit auf Basis deiner Ergebnisse schreiben.
Im mehrsprachigen ASR-Modell feinjustierst du das Wave2Vec XLS-R-Modell mit türkischen Audioaufnahmen und Transkriptionen, um ein automatisches Spracherkennungssystem zu entwickeln.
Zuerst schaust du dir die Audiodateien und den Textdatensatz an, dann nimmst du einen Text-Tokenizer, extrahierst Features und bearbeitest die Audiodateien. Danach machst du einen Trainer, eine WER-Funktion, lädst vortrainierte Modelle, optimierst Hyperparameter und trainierst und bewertest das Modell.
Du kannst die Plattform Hugging Face nutzen, um die Modellgewichte zu speichern und Web-Apps zu veröffentlichen, die Sprache in Echtzeit transkribieren: Urdu Asr streamen.
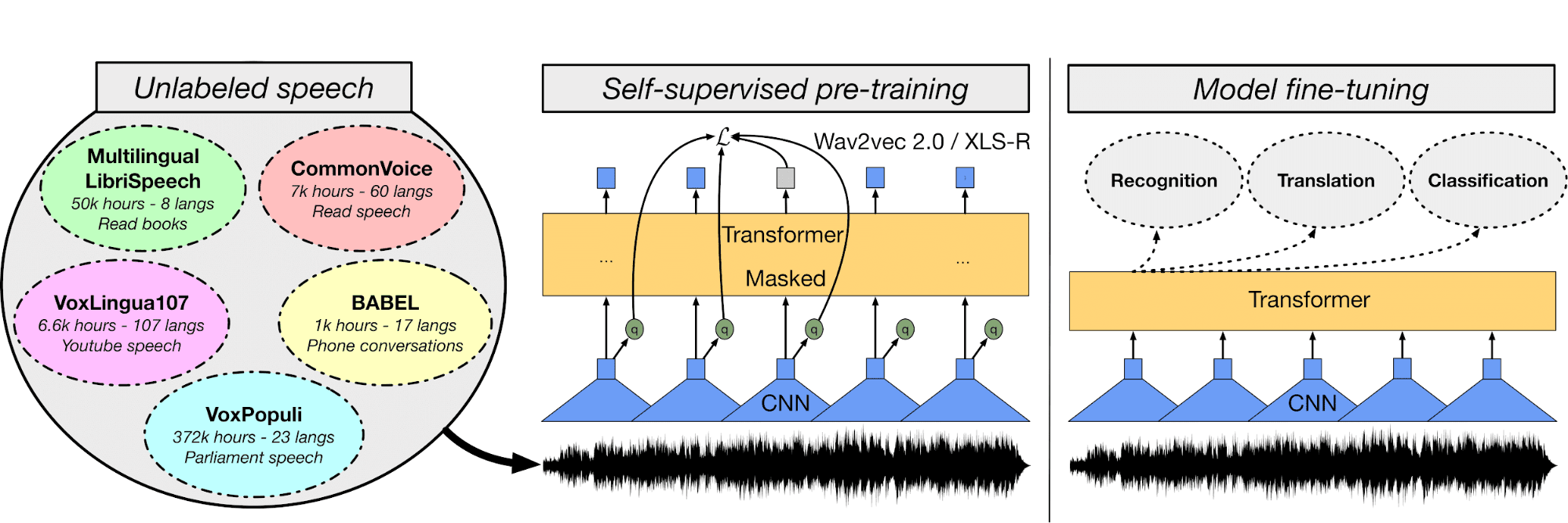
Bild von huggingface.co
Im Projekt „One Shot Face Stylization“ kannst du entweder das Modell anpassen, um die Ergebnisse zu verbessern, oder JoJoGAN anhand eines neuen Datensatzes optimieren, um deine eigene Stilisierungsanwendung zu erstellen.
Es wird das Originalbild nehmen, um mit GAN-Inversion und der Feinabstimmung eines vortrainierten StyleGAN ein neues Bild zu machen. Du wirst verschiedene Architekturen generativer gegnerischer Netzwerke verstehen. Danach fängst du an, einen gepaarten Datensatz zu sammeln, um einen Stil deiner Wahl zu erstellen.
Dann probierst du mit Hilfe einer Beispiel-Lösung der vorherigen Version von StyleGAN die neue Architektur aus, um realistische Kunstwerke zu erstellen.
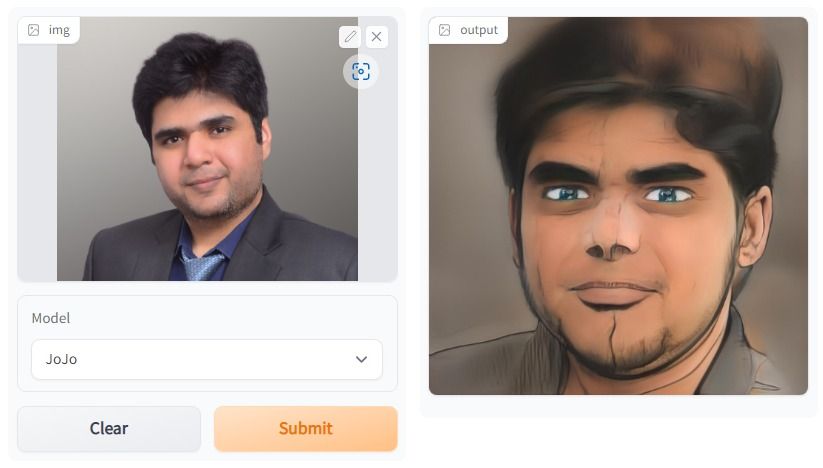
Das Bild wurde mit JoJoGAN erstellt.
Im Projekt „H&M Personalized Fashion Recommendations” entwickelst du Produktempfehlungen auf der Grundlage früherer Transaktionen, Kundendaten und Produktmetadaten.
Das Projekt wird deine NLP-, CV- (Computer Vision) und Deep-Learning-Fähigkeiten auf die Probe stellen. In den ersten Wochen lernst du die Daten kennen und wie du verschiedene Funktionen nutzen kannst, um eine Ausgangsbasis zu schaffen.
Dann mach ein einfaches Modell, das nur den Text und die kategorialen Merkmale nutzt, um Empfehlungen vorherzusagen. Dann versuch mal, NLP und CV zu kombinieren, um deine Punktzahl in der Rangliste zu verbessern. Du kannst das Problem auch besser verstehen, indem du dir Community-Diskussionen und den Code anschaust.

Bild von H&M EDA FIRST LOOK
In der Projekt „Analyse von Kundensupport-Anrufen“ baust du eine durchgängige Pipeline, die aus rohen Audioaufzeichnungen Erkenntnisse macht. Du wirst Anrufe mit einem automatischen Spracherkennungsmodell transkribieren, Texte bereinigen und segmentieren, Stimmungsanalysen durchführen und Entitäten wie Produkte, Pläne, Standorte und Namen extrahieren. Du wirst auch Transkripte mit Einbettungen indexieren, um eine schnelle semantische Suche über Gespräche hinweg zu ermöglichen.
Dann schaust du dir die Qualität der Transkription und die Leistung des Modells an, gruppierst Themen, um gemeinsame Anrufauslöser zu erkennen, und suchst nach Highlights wie negativen Stimmungsausbrüchen oder Eskalations-Schlagwörtern.
In der Projekt „Überwachung eines Modells zur Erkennung von Finanzbetrug” fungieren Sie als Datenwissenschaftler nach der Bereitstellung für eine britische Bank und diagnostizieren, warum ein Live-Betrugsmodell versagt. Du lädst Produktionsprognosen und -ergebnisse hoch, verfolgst wichtige Kennzahlen wie Präzision, Recall, PR-AUC und Kalibrierung und visualisierst die Leistung im Zeitverlauf, um Verschlechterungen zu erkennen. Du kannst auch nach Kanal, Region und Kundensegment filtern, um herauszufinden, wo sich falsch-positive oder falsch-negative Ergebnisse häufen.
Dann checkst du mit Hilfe von Verteilungskontrollen und Stabilitätsindizes, ob es zu Daten- und Konzeptdrift kommt, schaust dir Verschiebungen bei der Merkmalsbedeutung an und vergleichst mit Hilfe von Erklärungswerkzeugen das aktuelle Verhalten mit dem Basisverhalten.
Im Projekt „MuZero für Atari 2600” wirst du den Agenten für verstärktes Lernen mit dem MuZero-Algorithmus für Atari-2600-Spiele erstellen, trainieren und validieren. Schau dir das Tutorial an, um mehr über den MuZero-Algorithmus zu erfahren.
Das Ziel ist, eine neue Architektur zu entwickeln oder die bestehende zu ändern, um die Punktzahl in der globalen Rangliste zu verbessern. Es wird mehr als drei Monate dauern, bis ich kapiert habe, wie der Algorithmus beim Reinforcement Learning funktioniert.
Dieses Projekt ist ziemlich mathematisch und du solltest Python gut beherrschen. Du kannst vorgeschlagene Lösungen finden, aber um weltweit ganz oben zu sein, musst du deine eigene Lösung entwickeln.
Das MLOps End-to-End-Machine-Learning -Projekt ist wichtig, damit du bei Top-Firmen einen Job bekommst. Heutzutage suchen Personalvermittler nach ML-Ingenieuren, die mit MLOps-Tools, Datenorchestrierung und Cloud komplette Systeme auf die Beine stellen können.
In diesem Projekt baust du einen Standortbildklassifikator mit TensorFlow, Streamlit, Docker, Kubernetes, Cloudbuild, GitHub und Google Cloud und setzt ihn ein. Das Hauptziel ist, die Erstellung und Bereitstellung von Machine-Learning-Modellen in der Produktion mithilfe von CI/CD zu automatisieren. Schau dir zur Orientierung das Tutorial zu maschinellem Lernen, Pipelines, Bereitstellung und MLOps an.
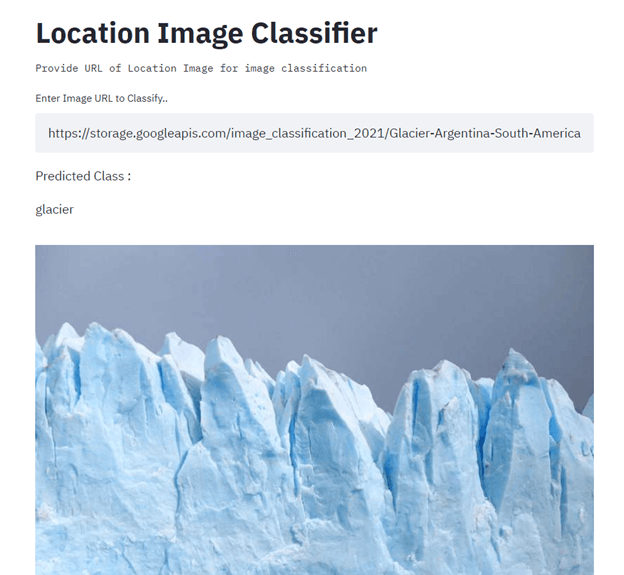
Bild von Senthil E
Um dein Portfolio im Bereich maschinelles Lernen aufzubauen, brauchst du Projekte, die echt was hermachen. Zeig dem Personalchef oder Recruiter, dass du in mehreren Sprachen programmieren kannst, verschiedene Frameworks für maschinelles Lernen verstehst, einzigartige Probleme mithilfe von maschinellem Lernen lösen kannst und das gesamte Ökosystem des maschinellen Lernens verstehst.
In der Projekt „Fine-Tuning GPT-OSS” installierst du Abhängigkeiten, lädst das Modell und den Tokenizer, legst mit dem Harmony Python-Paket einen klaren Prompt-Stil fest und führst eine schnelle Basis-Inferenz durch, um zu checken, ob alles von Anfang bis Ende funktioniert.
Dann machst du einen medizinischen Q&A-Datensatz mit Harmony-Formatierung, richtest das Training ein und optimierst das Modell. Danach kommt eine Bewertung nach der Optimierung, um die Verbesserungen zu messen.
In der Projekt „Fine-Tuning MedGemma on a Brain MRI Dataset” passt du das multimodale Modell MedGemma 4B, den SigLIP-Bild-Encoder und ein medizinisch abgestimmtes LLM an, um MRT-Scans des Gehirns zu klassifizieren. Du richtest die Umgebung auf RunPod ein, installierst die erforderlichen Python-Pakete, lädst und bereinigst einen MRT-Datensatz und bereitest die Eingaben mit einheitlicher Größenanpassung, Normalisierung und Label-Zuordnung vor, bevor du eine schnelle Plausibilitätsprüfung durchführst.
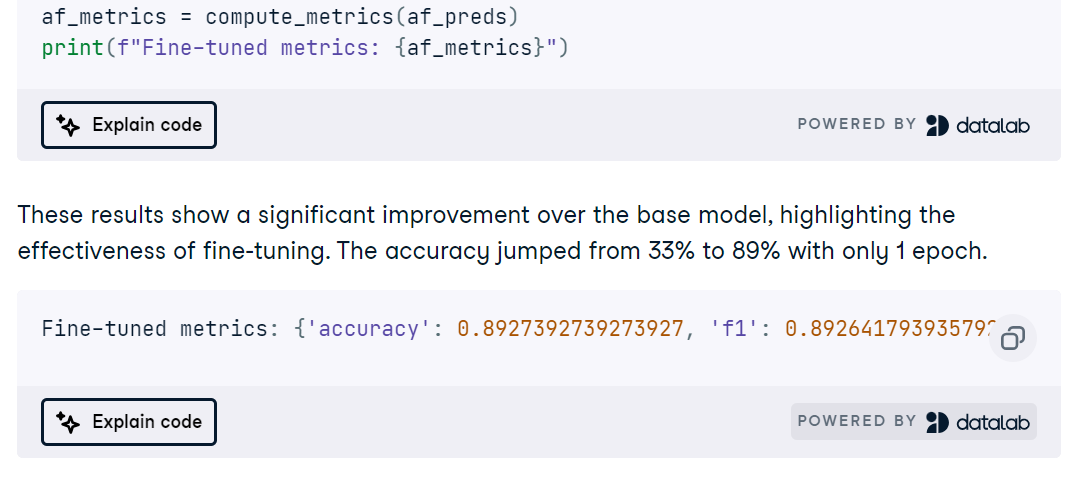
Dann optimierst du MedGemma für die MRT-Aufgabe, verfolgst die Lernpfade und bewertest die Genauigkeit, ROC-AUC, Präzision, Recall und Verwechslungsmatrizen, um Fehlermodi zu erkennen.
In der Projekt „Fine-tuning Stable Diffusion XL with DreamBooth and LoRA” richtest du SDXL in Python mit Diffusoren ein, lädst das FP16-Basismodell und VAE auf eine CUDA-GPU und machst Bilder aus kurzen Eingaben. Du kannst mit dem SDXL-Verfeiner schnelle Qualitätsverbesserungen entdecken, Ergebnisse vergleichen und mit einem einfachen Raster-Tool mehrere Generierungen nebeneinander anschauen.
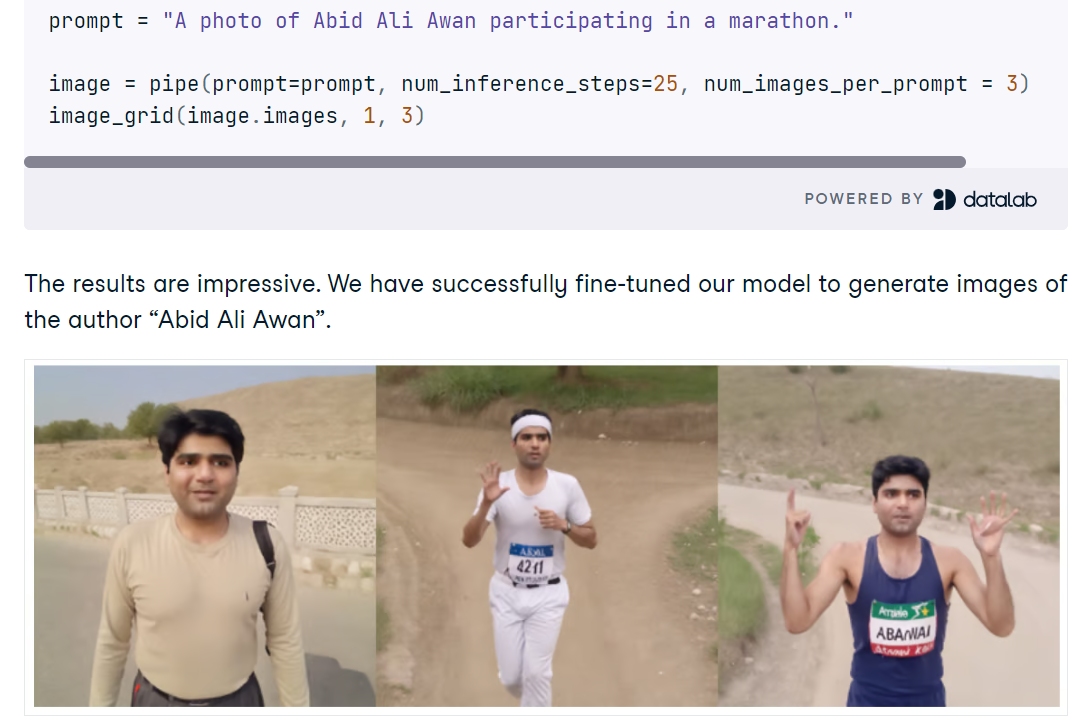
Dann optimierst du SDXL mit AutoTrain Advanced und DreamBooth anhand einer kleinen Auswahl persönlicher Fotos und erstellst einen kompakten LoRA-Adapter anstelle eines vollständigen Checkpoints für schnelle, speichereffiziente Schlussfolgerungen. Nach dem Training hängst du die LoRA-Gewichte an die Basis-Pipeline an, testest neue Eingabeaufforderungen und schaust, ob der Refiner die Identitätsgenauigkeit verbessert oder verschlechtert.
In der Projekt „Song Generation with Latent Diffusion” hast du ein Open-Source-Diffusionsmusikmodell eingerichtet, um komplette Songs entweder aus Textstil-Eingaben oder einem Referenz-Audioclip zu generieren. Du installierst über Conda oder Docker, richtest die Umgebung ein (espeak-ng, phonemizer-Pfade unter Windows) und führst die mitgelieferten Inferenzskripte aus, um Lernpfade mit den Basis- oder vollständigen Checkpoints zu erstellen, was eine chunkweise Dekodierung ermöglicht, wenn der VRAM knapp ist.
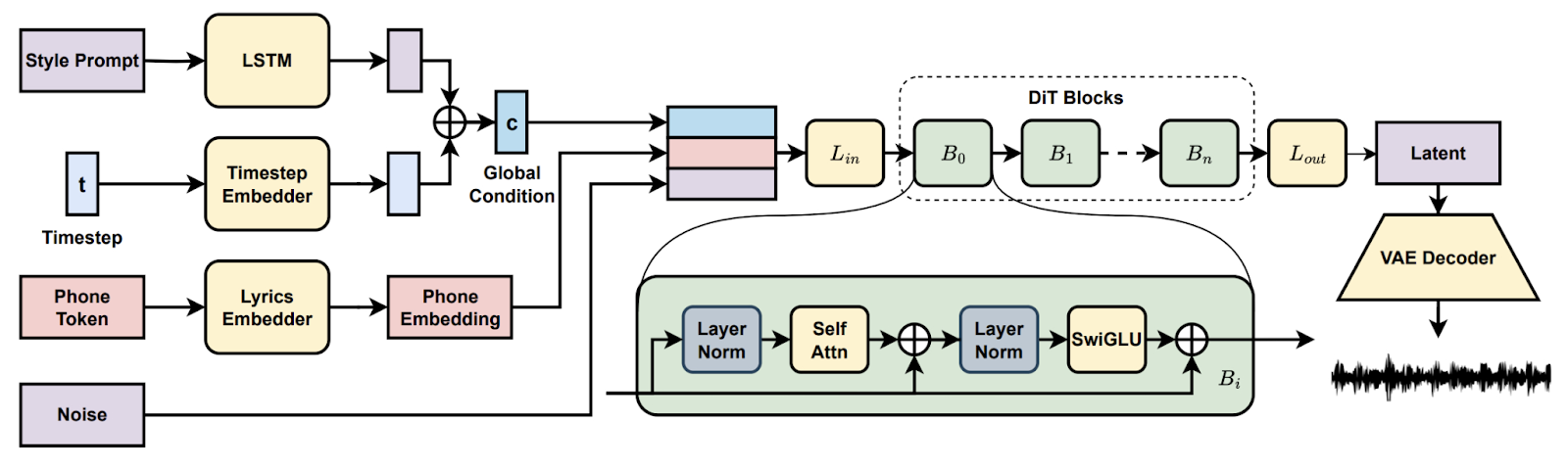
Dann probierst du Funktionen wie Songfortsetzung und -bearbeitung aus, vergleichst Arrangements über verschiedene Eingabeaufforderungen hinweg und dokumentierst Einstellungen, damit du sie später wiederholen kannst. Am Ende hast du eine praktische Pipeline für die komplette Musikproduktion.
Im Projekt „Bereitstellung einer Machine-Learning-Anwendung in der Produktion“ baust du mit GitHub Actions eine komplett automatisierte ML-Pipeline, die ein einfaches Modell zur Klassifizierung von Medikamenten trainiert, bewertet, versioniert und bereitstellt. Du richtest die Repo-Struktur und die Makefile ein, fügst die Umgebungseinrichtung, Linting, Unit-Tests und Datenprüfungen hinzu und skriptest dann reproduzierbare Trainings- und Evaluierungsläufe, die Metriken und Artefakte protokollieren.
Dann richtest du eine kontinuierliche Integration ein, die bei Pull-Anfragen und Main-Pushes ausgelöst wird, veröffentlichst Modellartefakte mit CML und Hugging Face CLI und bringst ein erfolgreiches Modell über kontinuierliche Bereitstellungs-Workflows zur Bereitstellung.
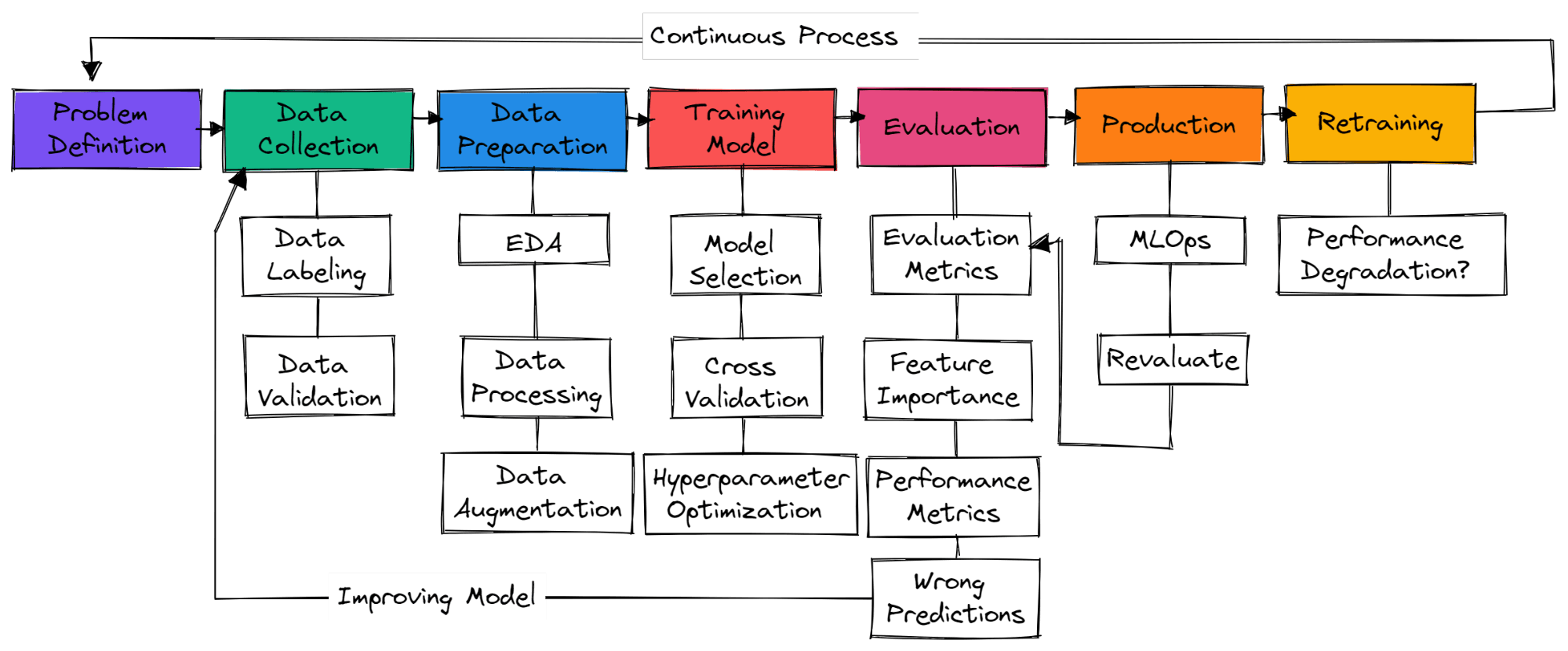
Bild vom Autor
Bei einem typischen Machine-Learning-Projekt gibt's keine Standard-Schritte. Also, es kann einfach nur um Datenerfassung, Datenaufbereitung und Modelltraining gehen. In diesem Abschnitt lernst du die Schritte kennen, die nötig sind, um ein produktionsreifes Machine-Learning-Projekt zu erstellen.
Du musst das geschäftliche Problem verstehen und dir eine grobe Vorstellung davon machen, wie du maschinelles Lernen einsetzen willst, um es zu lösen. Such nach Forschungsarbeiten, Open-Source-Projekten, Tutorials und ähnlichen Anwendungen, die von anderen Firmen genutzt werden. Stell sicher, dass deine Lösung realistisch ist und die Daten leicht verfügbar sind.
Du wirst Daten aus verschiedenen Quellen sammeln, bereinigen und kennzeichnen und Skripte für die Datenvalidierung erstellen. Stell sicher, dass deine Daten nicht voreingenommen sind oder sensible Infos enthalten.
Füll fehlende Werte, bereinige und verarbeite die Daten für die Datenanalyse. Nutze Visualisierungstools, um die Verteilung der Daten zu verstehen und zu sehen, wie du Funktionen nutzen kannst, um die Modellleistung zu verbessern. Feature-Skalierung und Datenvergrößerung werden benutzt, um Daten für ein maschinelles Lernmodell umzuwandeln.
Auswahl von neuronalen Netzen oder Algorithmen für maschinelles Lernen, die häufig für bestimmte Probleme verwendet werden. Trainingsmodell mit Kreuzvalidierung und verschiedenen Hyperparameter-Optimierungstechniken, um die besten Ergebnisse zu kriegen.
Das Modell anhand des Testdatensatzes bewerten. Stell sicher, dass du die richtige Metrik zur Modellbewertung für bestimmte Probleme verwendest. Genauigkeit ist nicht für alle Probleme ein guter Maßstab. Schau dir den F1- oder AUC-Wert für die Klassifizierung oder den RMSE-Wert für die Regression an. Visualisiere die Wichtigkeit der Modellmerkmale, um unwichtige Merkmale wegzulassen. Schau dir Leistungskennzahlen wie die Trainings- und Inferenzzeit von Modellen an.
Stell sicher, dass das Modell die menschliche Basislinie übertroffen hat. Wenn nicht, sammle einfach noch mehr gute Daten und fang von vorne an. Es ist ein wiederholter Prozess, bei dem du immer wieder mit verschiedenen Feature-Engineering-Techniken, Modusarchitekten und Frameworks für maschinelles Lernen trainierst, um die Leistung zu verbessern.
Nachdem du top Ergebnisse erzielt hast, ist es Zeit, dein Machine-Learning-Modell mit MLOps-Tools in der Produktion/Cloud einzusetzen. Beobachte das Modell anhand von Echtzeitdaten. Die meisten Modelle klappen in der Produktion nicht, deshalb ist es besser, sie erst mal nur für eine kleine Gruppe von Nutzern einzusetzen.
Wenn das Modell nicht die gewünschten Ergebnisse bringt, fängst du einfach von vorne an und suchst nach einer besseren Lösung. Auch wenn du super Ergebnisse erzielst, kann sich das Modell mit der Zeit wegen Daten- und Konzeptdrift verschlechtern. Durch das erneute Trainieren neuer Daten passt sich dein Modell auch an Echtzeitänderungen an.
Kurse für maschinelles Lernen
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Matt Crabtree