Cours
Apprentissage automatique avec PySpark
4 h
29.7K
Ces projets d'apprentissage automatique pour débutants consistent à traiter des données structurées et tabulaires. Vous appliquerez vos compétences en matière de nettoyage, de traitement et de visualisation des données à des fins analytiques et utiliserez le framework scikit-learn pour former et valider des modèles d'apprentissage automatique.
Si vous souhaitez d'abord acquérir les concepts fondamentaux du machine learning, nous proposons un excellent cours sur le machine learning sans code. Si vous souhaitez améliorer vos compétences dans ce domaine, nous vous invitons à consulter certains de nos projets liés à l'intelligence artificielle.
Dans le cadre du projet « Predict Energy Consumption » (Prévision de la consommation énergétique), vous utiliserez des modèles de régression et d'apprentissage automatique pour prévoir la consommation électrique quotidienne en fonction de facteurs temporels tels que l'heure de la journée et la température. L'objectif est de mettre en évidence les modèles permettant d'optimiser la consommation d'énergie, d'améliorer l'efficacité et de réduire les coûts. Ceci est particulièrement important pour les services publics et les entreprises qui souhaitent réduire leurs dépenses opérationnelles, promouvoir les économies d'énergie et mieux gérer leurs ressources de manière plus durable.
Le projet « Predict Energy Consumption » (Prévoir la consommation d'énergie) est un projet guidé, mais vous pouvez reproduire les objectifs sur un autre ensemble de données, tel que « Seoul's Bike Sharing Demand » (Demande de vélos en libre-service à Séoul). Travailler sur un ensemble de données entièrement nouveau vous aidera à déboguer votre code et à améliorer vos compétences en matière de résolution de problèmes.
Dans le projet « Des données aux dollars - Prévision des frais d'assurance », vous endossez le rôle d'un scientifique des données au sein d'une compagnie d'assurance maladie. Vous développerez un modèle prédictif pour estimer les frais d'assurance en fonction des caractéristiques du client, telles que son âge et son état de santé. Ce projet propose une application pratique de l'apprentissage automatique dans le domaine des affaires, permettant ainsi d'élaborer des modèles de tarification plus précis et d'aider les entreprises à gérer les risques tout en proposant des stratégies de tarification personnalisées à leurs clients.
Le projet « Prévision des frais d'assurance » est un projet guidé. Vous pouvez reproduire le résultat sur un autre ensemble de données, tel que celui concernant la demande de réservations hôtelières. Vous pouvez l'utiliser pour prédire si un client annulera ou non sa réservation.
Dans le cadre du projet « Prédiction des approbations de cartes de crédit », vous développerez une application d'approbation automatique de cartes de crédit à l'aide de l'optimisation des hyperparamètres et de la régression logistique.
Vous appliquerez vos compétences en matière de gestion des valeurs manquantes, de traitement des caractéristiques catégorielles, de mise à l'échelle des caractéristiques, de traitement des données déséquilibrées et d'optimisation automatique des hyperparamètres à l'aide de GridCV. Ce projet vous permettra de sortir de votre zone de confort en matière de traitement de données simples et claires.

Image par l'auteur
La prédiction des approbations de cartes de crédit est un projet guidé. Vous pouvez reproduire le résultat sur un autre ensemble de données, tel que les données relatives aux prêts provenant de LendingClub.com. Vous pouvez l'utiliser pour créer un outil de prédiction automatique de l'approbation des prêts.
Vous pourriez mettre en place un projet de prédiction de la qualité du vin, en utilisant un ensemble de données sur les propriétés physico-chimiques du vin, telles que la teneur en alcool, l'acidité et le taux de sucre. En appliquant des modèles de classification, tels que la régression logistique dans scikit-learn, il est possible de classer les vins sur une échelle de 1 à 10.
Ce projet revêt une importance particulière pour les industries impliquées dans la production et le contrôle qualité du vin, car il leur permet de surveiller et de prévoir de manière cohérente la qualité du vin, garantissant ainsi l'excellence du produit.
Dans le projet de science des données sur la modélisation prédictive pour l'agriculture, vous développerez un système simple de recommandation de cultures à l'aide de l'apprentissage automatique supervisé et de la sélection de caractéristiques. Nous travaillons avec quatre attributs essentiels du sol : l'azote, le phosphore, le potassium et le pH. Vous serez confronté à une contrainte réaliste : l'agriculteur ne peut se permettre d'en mesurer qu'un seul. Votre tâche consiste à identifier la caractéristique unique qui permet le mieux de prédire la culture appropriée, puis à former un classificateur léger afin qu'il puisse formuler cette recommandation de manière fiable.
Vous mettrez en pratique des compétences telles que le traitement des valeurs manquantes, l'encodage des étiquettes, la mise à l'échelle des caractéristiques, l'évaluation des modèles et, surtout, l'application et la comparaison de deux techniques de sélection de caractéristiques pour classer les mesures du sol.
Store Sales est un concours Kaggle destiné aux débutants, dans lequel les participants entraînent divers modèles de séries chronologiques afin d'améliorer leur score au classement. Dans le cadre de ce projet, vous recevrez les données relatives aux ventes en magasin. Vous serez chargé de nettoyer ces données, d'effectuer une analyse approfondie des séries chronologiques, de procéder à la mise à l'échelle des caractéristiques et de former le modèle multivarié de séries chronologiques.
Afin d'améliorer votre score au classement, vous pouvez utiliser des méthodes d'ensembling telles que le bagging et les régresseurs de vote.
Image provenant de Kaggle
Store Sales est un projet basé sur Kaggle qui vous permet de consulter les carnets de notes des autres participants.
Afin d'approfondir votre compréhension des prévisions de séries chronologiques, nous vous invitons à appliquer vos compétences à l'ensemble de données de la Bourse et à utiliser Facebook Prophet pour former un modèle de prévision de séries chronologiques univariées.
Ces projets intermédiaires d'apprentissage automatique se concentrent sur le traitement des données et les modèles d'entraînement pour les ensembles de données structurés et non structurés. Apprenez à nettoyer, traiter et enrichir l'ensemble de données à l'aide de divers outils statistiques.
Le projet « Reveal Categories Found in Data » (Révéler les catégories trouvées dans les données) vous aide à analyser les commentaires des clients à l'aide du regroupement et du traitement du langage naturel (NLP). Vous organiserez les avis provenant du Google Play Store en différentes catégories à l'aide du clustering K-means. Il est essentiel pour les équipes de développement de produits de comprendre les thèmes récurrents dans les commentaires des clients afin de répondre aux préoccupations des utilisateurs, d'améliorer les fonctionnalités et d'accroître la satisfaction des utilisateurs grâce à des informations exploitables.
Veuillez essayer de reproduire le résultat sur un autre ensemble de données, tel que l'ensemble de données Netflix Movie.
Dans le projet « Fréquence des mots dans Moby Dick », vous allez extraire le texte de l'œuvre Moby Dick d'Herman Melville et analyser la fréquence des mots à l'aide de la bibliothèque nltk de Python. Ce projet présente les principales techniques de traitement du langage naturel (NLP) et aide à comprendre comment les mots fréquemment utilisés révèlent des schémas dans le texte. Il s'agit d'un projet remarquable pour les passionnés de littérature, les historiens ou les chercheurs intéressés par l'exploration de textes et l'analyse linguistique.
Dans le cadre du projet « Reconnaissance faciale avec apprentissage supervisé », vous développerez un modèle de reconnaissance faciale à l'aide de techniques d'apprentissage supervisé avec Python et scikit-learn. Le modèle distingue les images d'Arnold Schwarzenegger de celles d'autres personnes. Ce projet revêt une importance particulière dans le domaine en pleine expansion de la technologie de reconnaissance faciale, qui trouve de nombreuses applications dans les domaines de la sécurité, des systèmes d'authentification et même des plateformes de réseaux sociaux, où la détection faciale est couramment utilisée.
Construire un prédicteur de popularité des livres pour une librairie en ligne en convertissant des données mixtes, telles que du texte (par exemple, des titres et des descriptions de livres) et des données numériques (par exemple, des notes et des chiffres), en caractéristiques efficaces. Vous participerez à l'ensemble du processus d'apprentissage automatique, qui comprend l'analyse exploratoire rapide des données (EDA), la correction des types de données, la transformation des variables textuelles et numériques, ainsi que l'ajustement d'un modèle afin d'atteindre la plus grande précision possible.
Vous apprendrez à gérer des données complexes et multiformats, ainsi qu'à évaluer les résultats à l'aide d'un pipeline propre et réutilisable. À la fin de ce processus, vous serez en mesure d'appliquer les mêmes méthodes à n'importe quel catalogue, qu'il s'agisse de votre liste de lecture personnelle ou d'ensembles de données publics, afin de prédire les best-sellers potentiels et d'améliorer les systèmes de recommandation.
Dans le projet de regroupement des espèces de manchots de l'Antarctique, vous utilisez l'apprentissage non supervisé pour découvrir des groupes naturels de manchots sans étiquettes. Vous allez nettoyer un ensemble de données de type Palmer Penguins, traiter les valeurs manquantes, mettre à l'échelle les caractéristiques numériques telles que la longueur du bec, la profondeur du bec, la longueur des nageoires et la masse corporelle, et éventuellement encoder un contexte catégoriel simple tel que l'île ou le sexe avant d'exécuter K-means.mass. En option, veuillez encoder les variables catégorielles simples telles que l'île ou le sexe avant d'appliquer le regroupement par la méthode des K-moyennes.
Vous sélectionnez ensuite le nombre de clusters à l'aide des scores elbow et silhouette, visualisez la structure à l'aide de l'ACP et comparez les clusters aux espèces connues pour une vérification rapide.
Dans le projet d'optimisation des itinéraires de taxi avec apprentissage par renforcement, vous entraînez un agent d'apprentissage Q à résoudre l'environnement Taxi-v3 Gymnasium en apprenant des itinéraires efficaces pour prendre et déposer des passagers. Vous élaborerez un tableau de valeurs état-action, équilibrerez exploration et exploitation à l'aide d'une politique epsilon-greedy, et ajusterez les hyperparamètres fondamentaux tels que le taux d'apprentissage, le facteur d'actualisation et la décroissance epsilon afin d'accélérer la convergence.

Vous évaluez ensuite les performances à l'aide de la récompense moyenne par épisode et des étapes nécessaires à la réalisation, visualisez la courbe d'apprentissage et testez la politique formée sur des épisodes inédits.
Veuillez utiliser l'ensemble de données sur le cancer du sein dans le Wisconsin pour déterminer si une tumeur est maligne ou bénigne. L'ensemble de données comprend des informations détaillées sur les caractéristiques des tumeurs, telles que leur texture, leur périmètre et leur superficie. Votre objectif est de créer un modèle de classification qui prédit un diagnostic en fonction de ces caractéristiques.
Ce projet est essentiel dans le domaine des applications médicales, car il fournit des informations précieuses pour l'analyse des données médicales et le développement d'outils de diagnostic pouvant contribuer à la détection précoce du cancer.
Dans le cadre du projet « Reconnaissance des émotions dans le discours avec Librosa », vous traiterez des fichiers audio à l'aide de Librosa, de fichiers audio et de sklearn pour le MLPClassifier afin de reconnaître les émotions à partir de fichiers audio.
Vous allez charger et traiter des fichiers audio, effectuer l'extraction de caractéristiques et entraîner le modèle de classificateur Multi-Layer Perceptron. Ce projet vous permettra d'acquérir les bases du traitement audio afin que vous puissiez progresser dans la formation d'un modèle d'apprentissage profond pour obtenir une meilleure précision.
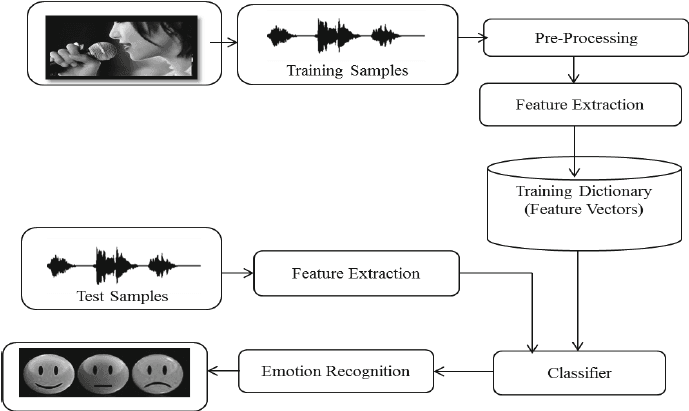
Image provenant de researchgate.net
Ces projets avancés d'apprentissage automatique se concentrent sur la création et la formation de modèles d'apprentissage profond et le traitement d'ensembles de données non structurés. Vous formerez des réseaux neuronaux convolutifs, des unités récurrentes à porte, affinerez de grands modèles linguistiques et des modèles d'apprentissage par renforcement.
Dans le projet de classification des tickets du service d'assistance à l'aide du deep learning, vous créez un classificateur de texte PyTorch qui achemine automatiquement les tickets entrants vers la bonne catégorie. Vous serez chargé de nettoyer et de tokeniser du texte, de créer des divisions d'entraînement et de validation, de convertir des tickets en représentations vectorielles et d'entraîner un modèle neuronal compact tout en ajustant la taille des lots, le taux d'apprentissage et la régularisation pour une convergence stable.
Vous évaluez ensuite avec précision et F1 pondéré, examinez une matrice de confusion pour repérer les catégories mal étiquetées ou qui se chevauchent, et appliquez des techniques pour corriger le déséquilibre des classes, telles que la perte pondérée.
Dans le cadre du projet « Création d'un bot Rick Sanchez à l'aide de Transformers », vous utiliserez DialoGPT et la bibliothèque Hugging Face Transformer pour créer votre chatbot alimenté par l'IA.
Vous serez chargé de traiter et de transformer vos données, ainsi que de développer et d'affiner le modèle de génération de réponses pré-entraîné à grande échelle de Microsoft (DialoGPT) sur l'ensemble de données de dialogues Rick et Morty. Vous pouvez également créer une application Gradio simple pour tester votre modèle en temps réel : Fête de quartier Rick et Morty.
Le projet « Création d'un modèle de classification de vêtements pour le commerce électronique avec Keras » se concentre sur la classification d'images dans le contexte du commerce électronique. Vous utiliserez Keras pour créer un modèle d'apprentissage automatique qui automatise la classification des vêtements à partir d'images. Ceci est pertinent pour améliorer l'expérience d'achat en aidant les clients à trouver plus rapidement les produits et en rationalisant la gestion des stocks. Une classification précise permet également de proposer des recommandations personnalisées, ce qui stimule l'engagement des clients et les ventes.
Dans le cadre du projet « Détection des panneaux de signalisation routière à l'aide du deep learning », vous utiliserez Keras pour développer un modèle de deep learning capable de détecter les panneaux de signalisation routière, tels que les panneaux « Stop » et les feux de signalisation. Cette technologie est essentielle pour les véhicules autonomes, où une reconnaissance rapide et précise des panneaux de signalisation est indispensable pour une navigation sécurisée. Ce projet jette les bases du développement de systèmes de conduite autonome plus avancés, plus sûrs et plus fiables.
Dans le projet « Élaboration d'un modèle de prévision de la demande »,, vous utiliserez PySpark pour prévoir la demande de produits e-commerce à grande échelle. Vous chargerez les données transactionnelles, concevrez des fonctionnalités basées sur le temps telles que les décalages et les moyennes mobiles, les diviserez par période pour une évaluation honnête, et formerez une base de référence parallèlement à un modèle d'apprentissage tel que Gradient-Boosted Trees ou Random Forest afin de saisir les tendances et la saisonnalité.
Vous évaluez ensuite à l'aide des indicateurs MAE, RMSE et MAPE, comparez avec la référence et analysez les erreurs par SKU et fenêtre temporelle afin d'identifier les biais et la volatilité.
Dans le projet « Prévision de la température à Londres »,, vous menez une expérience structurée d'apprentissage automatique afin de prévoir la température quotidienne moyenne à partir de données météorologiques historiques. Vous chargerez et nettoierez l'ensemble de données, créerez des divisions temporelles, développerez des fonctionnalités telles que les moyennes mobiles et les valeurs décalées, et entraînerez plusieurs modèles candidats à l'aide de scikit-learn.
Vous organisez ensuite le flux de travail à l'aide de fonctions réutilisables et effectuez un cursus complet dans MLflow, en enregistrant les paramètres, les métriques et les artefacts afin de comparer les exécutions.
Connect X est un concours de simulation organisé par Kaggle. Développez un agent RL (apprentissage par renforcement) pour rivaliser avec les autres participants au concours Kaggle.
Vous apprendrez d'abord comment fonctionne le jeu et créerez un agent fonctionnel fictif qui servira de référence. Par la suite, vous commencerez à expérimenter divers algorithmes RL et architectures de modèles. Vous pouvez envisager de développer un modèle basé sur l'apprentissage profond Q ou l'algorithme d'optimisation de politique proximale.
Le projet de fin d'études exige que vous consacriez un certain temps à l'élaboration d'une solution unique. Vous effectuerez des recherches sur plusieurs architectures de modèles, utiliserez divers cadres d'apprentissage automatique pour normaliser et enrichir les ensembles de données, comprendrez les mathématiques qui sous-tendent le processus et rédigerez une thèse basée sur vos résultats.
Dans le modèle ASR multilingue, vous affinerez le modèle Wave2Vec XLS-R à l'aide d'enregistrements audio et de transcriptions en turc afin de créer un système de reconnaissance vocale automatique.
Tout d'abord, vous allez acquérir une compréhension des fichiers audio et de l'ensemble de données textuelles, puis utiliser un tokeniseur de texte, extraire des caractéristiques et traiter les fichiers audio. Ensuite, vous créerez un entraîneur, une fonction WER, chargerez des modèles pré-entraînés, ajusterez les hyperparamètres, puis entraînerez et évaluerez le modèle.
Vous pouvez utiliser la plateforme Hugging Face pour stocker les poids du modèle et publier des applications web permettant de transcrire la parole en temps réel : Diffusion en continu de l'ourdou Asr.
Image provenant de huggingface.co
Dans le projet One Shot Face Stylization, vous avez la possibilité de modifier le modèle afin d'améliorer les résultats ou d'ajuster JoJoGAN sur un nouvel ensemble de données pour créer votre application de stylisation.
Il utilisera l'image originale pour générer une nouvelle image à l'aide de l'inversion GAN et du réglage fin d'un StyleGAN pré-entraîné. Vous acquerrez une compréhension approfondie des différentes architectures de réseaux antagonistes génératifs. Par la suite, vous commencerez à collecter un ensemble de données appariées afin de créer le style de votre choix.
Ensuite, à l'aide d'un exemple de solution de la version précédente de StyleGAN, vous expérimenterez la nouvelle architecture afin de produire des œuvres d'art réalistes.
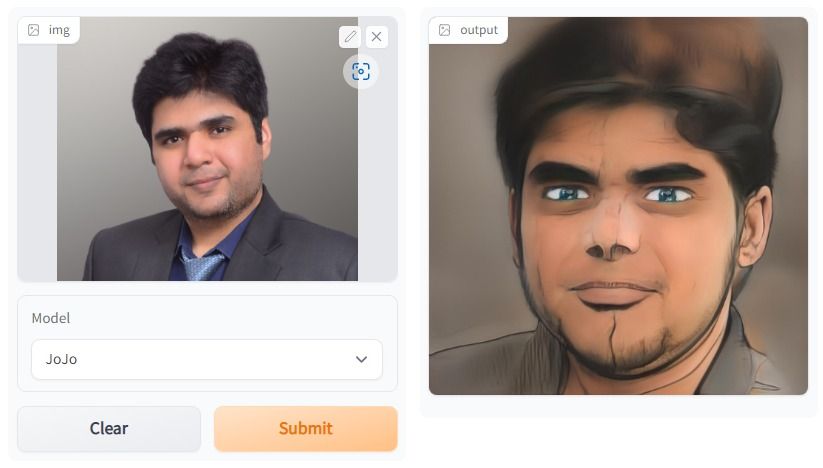
L'image a été créée à l'aide de JoJoGAN.
Dans le cadre du projet « Recommandations personnalisées de mode H&M », vous élaborerez des recommandations de produits en vous appuyant sur les transactions précédentes, les données clients et les métadonnées des produits.
Ce projet évaluera vos compétences en matière de traitement du langage naturel (NLP), de vision par ordinateur (CV) et d'apprentissage profond. Au cours des premières semaines, vous apprendrez à comprendre les données et à utiliser diverses fonctionnalités pour établir une base de référence.
Ensuite, veuillez créer un modèle simple qui utilise uniquement le texte et les caractéristiques catégorielles pour prédire les recommandations. Ensuite, passez à la combinaison du NLP et du CV afin d'améliorer votre score au classement. Vous pouvez également mieux comprendre le problème en consultant les discussions et le code de la communauté.

Image provenant de H&M EDA PREMIER APERÇU
Dans l'projet « Analyse des appels au service client »,, vous construisez un pipeline de bout en bout qui transforme les données audio brutes en informations exploitables. Vous serez chargé de transcrire des appels à l'aide d'un modèle de reconnaissance vocale automatique, de nettoyer et de segmenter le texte, d'effectuer des analyses de sentiments et d'extraire des entités telles que des produits, des plans, des lieux et des noms. Vous indexerez également les transcriptions avec des intégrations afin de permettre une recherche sémantique rapide dans les conversations.
Vous évaluez ensuite la qualité de la transcription et les performances du modèle, regroupez les thèmes pour mettre en évidence les facteurs communs à l'origine des appels et identifiez les points saillants tels que les pics de sentiments négatifs ou les mots-clés indiquant une escalade.
Dans le projet « Surveillance d'un modèle de détection des fraudes financières »,, vous agissez en tant que data scientist post-déploiement pour une banque britannique, en diagnostiquant les raisons pour lesquelles un modèle de fraude en direct est défaillant. Vous chargerez les prévisions et les résultats de production, suivrez le cursus d'indicateurs clés tels que la précision, le rappel, le PR-AUC et l'étalonnage, et visualiserez les performances au fil du temps afin de détecter toute dégradation. Vous pourrez également effectuer une analyse par canal, région et segment de clientèle afin d'identifier les zones où les faux positifs ou les faux négatifs sont concentrés.
Vous testez ensuite la dérive des données et des concepts à l'aide de contrôles de distribution et d'indices de stabilité, vous examinez les changements d'importance des caractéristiques et vous utilisez des outils d'explicabilité pour comparer le comportement actuel à celui de référence.
Dans le cadre du projet MuZero pour Atari 2600, vous serez amené à développer, former et valider l'agent d'apprentissage par renforcement à l'aide de l'algorithme MuZero pour les jeux Atari 2600. Veuillez consulter le tutoriel pour approfondir vos connaissances sur l'algorithme MuZero.
L'objectif est de créer une nouvelle architecture ou de modifier l'architecture existante afin d'améliorer le classement mondial. Il faudra plus de trois mois pour appréhender le fonctionnement de l'algorithme dans l'apprentissage par renforcement.
Ce projet comporte de nombreux calculs mathématiques et nécessite une expertise en Python. Vous pouvez trouver des solutions proposées, mais pour atteindre le sommet mondial, vous devez élaborer votre propre solution.
Le projet MLOps End-To-End Machine Learning est essentiel pour être recruté par les meilleures entreprises. Actuellement, les recruteurs recherchent des ingénieurs en apprentissage automatique capables de créer des systèmes de bout en bout à l'aide d'outils MLOps, d'orchestration de données et de cloud computing.
Dans le cadre de ce projet, vous allez créer et déployer un classificateur d'images de localisation à l'aide de TensorFlow, Streamlit, Docker, Kubernetes, Cloud Build, GitHub et Google Cloud. L'objectif principal est d'automatiser la création et le déploiement de modèles d'apprentissage automatique en production à l'aide de CI/CD. Pour obtenir des conseils, veuillez consulter le tutoriel sur l'apprentissage automatique, les pipelines, le déploiement et les MLOps.
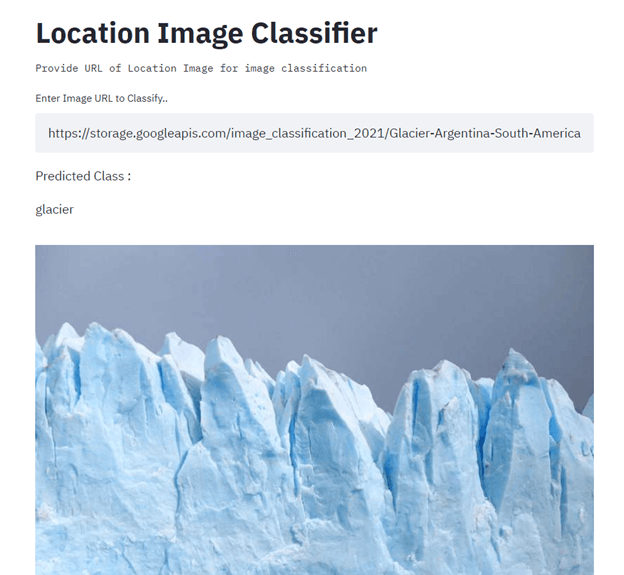
Image fournie par Senthil E
Pour constituer votre portfolio en apprentissage automatique, il est nécessaire de disposer de projets qui se démarquent. Veuillez démontrer au responsable du recrutement ou au recruteur que vous êtes capable de coder dans plusieurs langages, que vous comprenez divers cadres de machine learning, que vous pouvez résoudre des problèmes uniques à l'aide du machine learning et que vous comprenez l'écosystème du machine learning de bout en bout.
Dans le projet Fine-Tuning GPT-OSS , vous installerez les dépendances, chargerez le modèle et le tokenizer, définirez un style d'invite clair avec le package Harmony Python et exécuterez une inférence de base rapide pour confirmer que tout fonctionne de bout en bout.
Vous préparez ensuite un ensemble de données de questions-réponses médicales au format Harmony, configurez l'entraînement et affinez le modèle, puis procédez à une évaluation post-ajustement afin de mesurer les améliorations.
Dans le cadre de l'ajustement fin de MedGemma sur un ensemble de données d'IRM cérébr projet de réglage fin de MedGemma sur un ensemble de données d'IRM cérébrale, vous adaptez le modèle multimodal MedGemma 4B, l'encodeur d'images SigLIP, ainsi qu'un LLM adapté au domaine médical, afin de classer les IRM cérébrales. Vous configurerez l'environnement sur RunPod, installerez les paquets Python requis, chargerez et nettoierez un ensemble de données IRM, et préparerez les entrées avec un redimensionnement, une normalisation et un mappage des étiquettes cohérents avant d'exécuter une inférence rapide de vérification de cohérence.
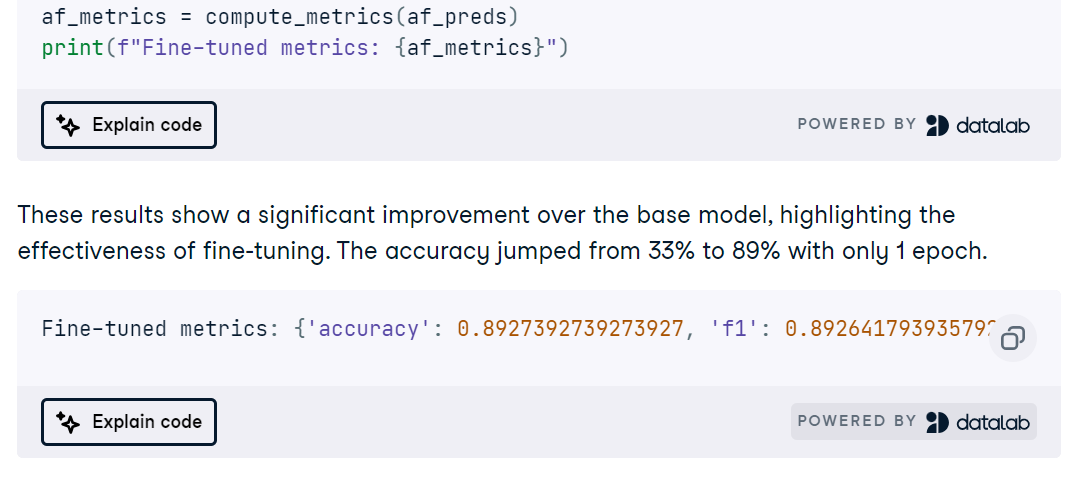
Vous procédez ensuite à l'ajustement de MedGemma pour la tâche IRM, suivez le cursus d'apprentissage et évaluez la précision, l'AUC ROC, la précision, le rappel et les matrices de confusion afin d'identifier les modes de défaillance.
Dans le cadre de l'ajustement de Stable Diffusion XL avec DreamBooth et LoRA projet « Fine-tuning Stable Diffusion XL with DreamBooth and LoRA »,, vous configurez SDXL en Python avec Diffusers, chargez le modèle de base FP16 et VAE sur un GPU CUDA, puis générez des images à partir de courtes invites. Vous pourrez explorer des améliorations rapides de la qualité grâce au raffineur SDXL, comparer les résultats et utiliser un utilitaire simple sous forme de grille pour examiner plusieurs générations côte à côte.
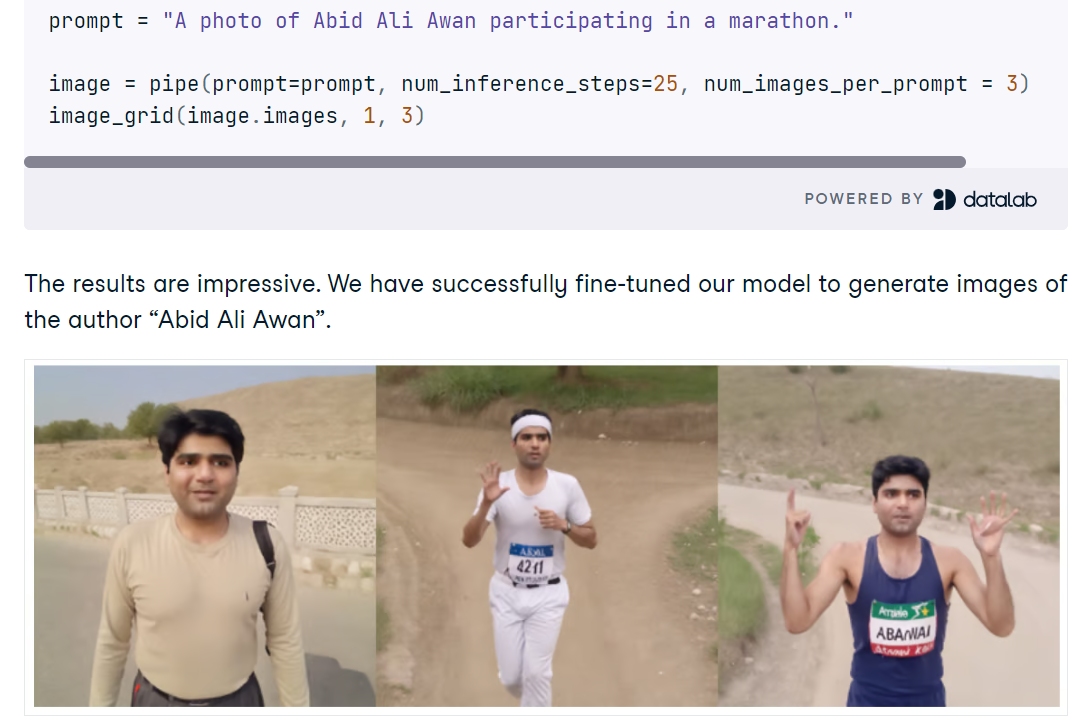
Vous affinez ensuite SDXL sur un petit ensemble de photos personnelles à l'aide d'AutoTrain Advanced avec DreamBooth, produisant un adaptateur LoRA compact au lieu d'un point de contrôle complet pour une inférence rapide et économe en mémoire. Après l'entraînement, vous associez les poids LoRA au pipeline de base, testez de nouvelles invites et évaluez si le raffineur contribue ou nuit à la fidélité de l'identité.
Dans la projet Song Generation with Latent Diffusion, vous avez mis en place un modèle musical open source de diffusion pour générer des chansons complètes à partir de suggestions de style textuel ou d'un extrait audio de référence. Vous devrez procéder à l'installation via Conda ou Docker, préparer l'environnement (chemins d'accès à espeak-ng et phonemizer sous Windows) et exécuter les scripts d'inférence fournis afin de créer des cursus avec les points de contrôle de base ou complets, ce qui permettra un décodage par morceaux lorsque la mémoire VRAM est insuffisante.
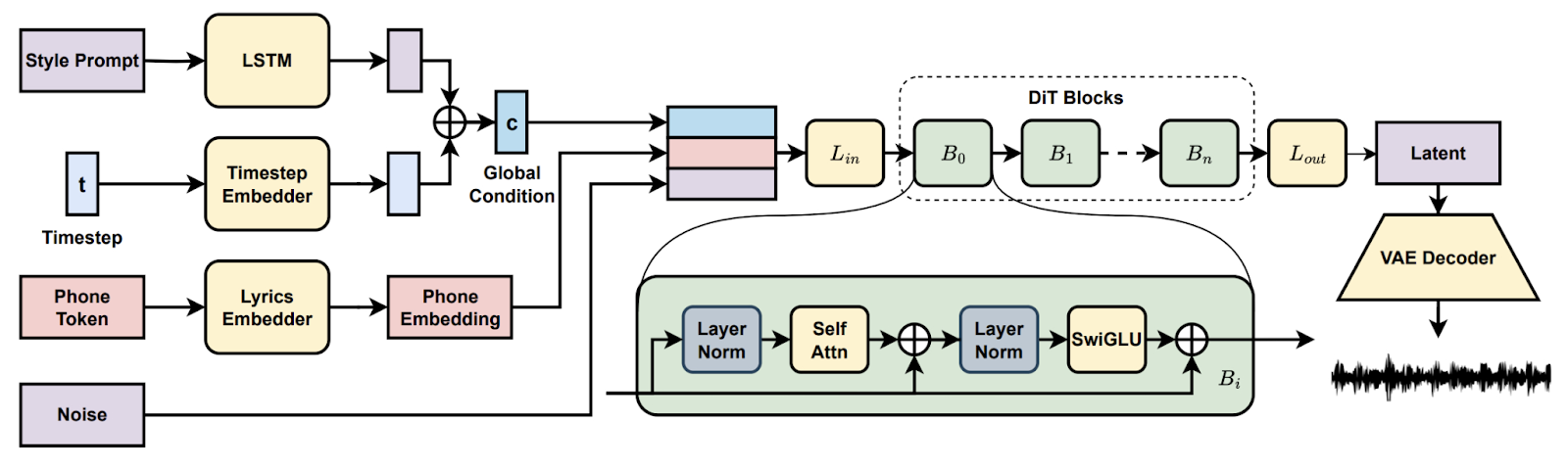
Vous explorez ensuite des fonctionnalités telles que la continuation et l'édition de morceaux, comparez les arrangements entre les invites et documentez les paramètres pour garantir la reproductibilité. À la fin, vous disposerez d'un pipeline pratique pour la création musicale de bout en bout.
Dans le projet Déploiement d'une application d'apprentissage automatique en production, vous construisez un pipeline ML entièrement automatisé avec GitHub Actions qui forme, évalue, versionne et déploie un modèle simple de classification des médicaments. Vous configurez la structure du dépôt et le Makefile, ajoutez la configuration de l'environnement, le linting, les tests unitaires et les vérifications de données, puis vous créez des scripts de formation et d'évaluation reproductibles qui enregistrent les métriques et les artefacts.
Vous configurez ensuite l'intégration continue pour qu'elle se déclenche lors des pull requests et des pushes principaux, publiez les artefacts du modèle avec CML et Hugging Face CLI, et passez le modèle validé au déploiement via des workflows de déploiement continu.
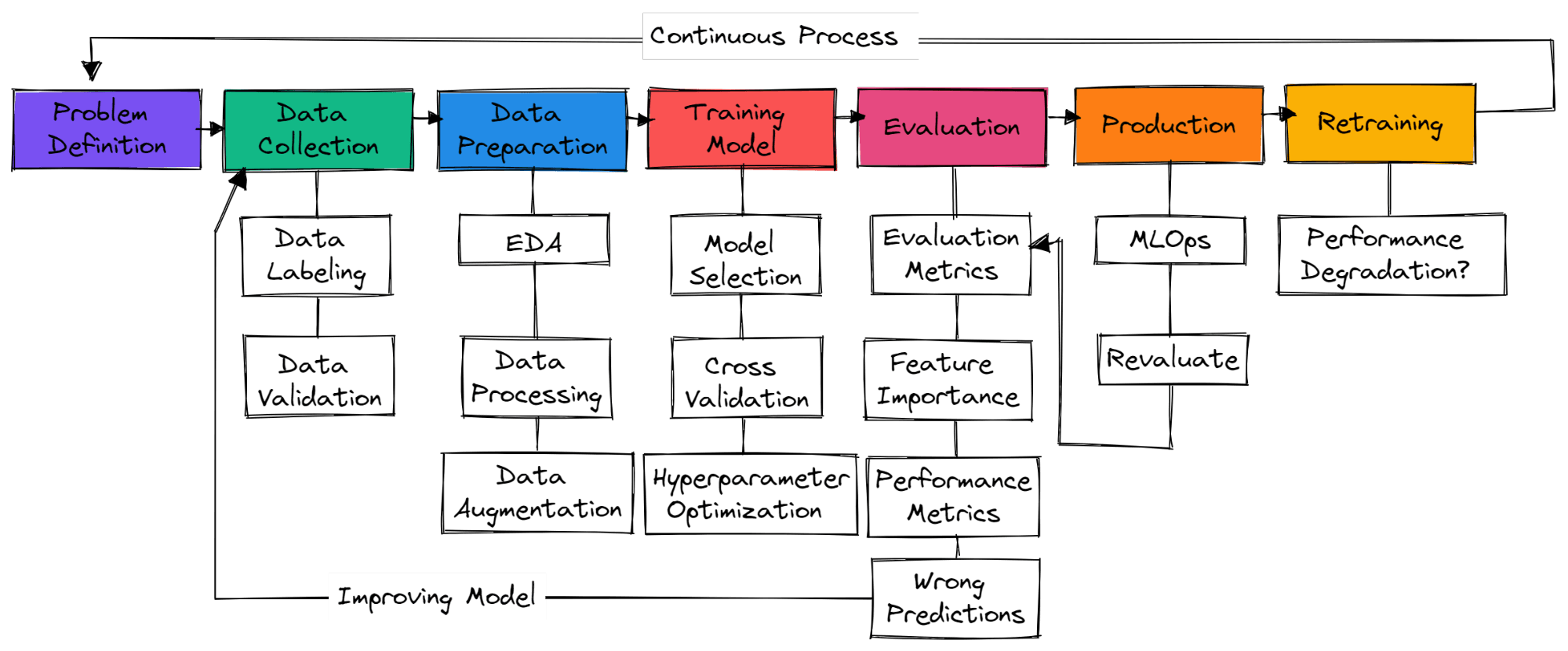
Image par l'auteur
Il n'existe pas d'étapes standard dans un projet typique d'apprentissage automatique. Il peut donc s'agir simplement de la collecte de données, de la préparation des données et de l'entraînement des modèles. Dans cette section, nous allons découvrir les étapes nécessaires à la création d'un projet d'apprentissage automatique prêt à être mis en production.
Il est nécessaire de bien comprendre le problème commercial et de concevoir une idée générale de la manière dont vous allez utiliser l'apprentissage automatique pour le résoudre. Recherchez des articles de recherche, des projets open source, des tutoriels et des applications similaires utilisés par d'autres entreprises. Veuillez vous assurer que votre solution est réaliste et que les données sont facilement accessibles.
Vous serez chargé de collecter des données provenant de diverses sources, de les nettoyer et de les étiqueter, ainsi que de créer des scripts pour la validation des données. Veuillez vous assurer que vos données ne sont pas biaisées et ne contiennent pas d'informations sensibles.
Veuillez compléter les valeurs manquantes, nettoyer et traiter les données en vue de leur analyse. Utilisez des outils de visualisation pour appréhender la distribution des données et découvrir comment exploiter les fonctionnalités afin d'améliorer les performances du modèle. Le redimensionnement des caractéristiques et l'augmentation des données sont utilisés pour transformer les données destinées à un modèle d'apprentissage automatique.
Sélectionner des réseaux neuronaux ou des algorithmes d'apprentissage automatique couramment utilisés pour des problèmes spécifiques. Modèle d'entraînement utilisant la validation croisée et diverses techniques d'optimisation des hyperparamètres afin d'obtenir des résultats optimaux.
Évaluation du modèle sur l'ensemble de données de test. Veuillez vous assurer que vous utilisez la métrique d'évaluation de modèle appropriée pour des problèmes spécifiques. La précision n'est pas un critère valable pour tous les types de problèmes. Veuillez vérifier le score F1 ou AUC pour la classification ou le RMSE pour la régression. Visualisez l'importance des caractéristiques du modèle afin d'éliminer celles qui ne sont pas pertinentes. Évaluer les indicateurs de performance tels que le temps d'entraînement et d'inférence du modèle.
Veuillez vous assurer que le modèle a dépassé le niveau de référence humain. Dans le cas contraire, veuillez reprendre la collecte de données de qualité et recommencer le processus. Il s'agit d'un processus itératif dans lequel vous continuerez à vous former à diverses techniques d'ingénierie des caractéristiques, architectures de mode et cadres d'apprentissage automatique afin d'améliorer les performances.
Après avoir obtenu des résultats de pointe, il est temps de déployer votre modèle d'apprentissage automatique en production/dans le cloud à l'aide des outils MLOps. Veuillez surveiller le modèle à l'aide de données en temps réel. La plupart des modèles échouent en production, il est donc recommandé de les déployer pour un petit sous-ensemble d'utilisateurs.
Si le modèle ne produit pas les résultats escomptés, il sera nécessaire de revoir la conception et de proposer une solution plus efficace. Même si vous obtenez d'excellents résultats, le modèle peut se dégrader avec le temps en raison de la dérive des données et de la dérive conceptuelle. La rééducation des nouvelles données permet également à votre modèle de s'adapter aux changements en temps réel.
Cours sur l'apprentissage automatique
Cours
Cours
Cours
blog
blog
Lynn Heidmann
blog
Nathaniel Taylor-Leach
8 min
Tutoriel

