Corso
Machine Learning con PySpark
4 h
29.8K
Questi progetti di machine learning per principianti riguardano dati strutturati e tabellari. Metterai in pratica competenze di pulizia, elaborazione e visualizzazione dei dati a fini analitici e utilizzerai il framework scikit-learn per addestrare e convalidare modelli di machine learning.
Se vuoi prima imparare i concetti di base del machine learning, abbiamo un corso no-code di introduzione al machine learning. Puoi anche dare un’occhiata ad alcuni dei nostri progetti di IA se vuoi migliorare le tue competenze in quell’area.
Nel progetto Predict Energy Consumption userai modelli di regressione e machine learning per prevedere il consumo giornaliero di elettricità in base a fattori temporali come l’orario e la temperatura. L’obiettivo è scoprire pattern che possano ottimizzare l’uso dell’energia, migliorando l’efficienza e riducendo i costi. Ciò è particolarmente importante per le utility e le aziende che puntano a ridurre le spese operative, promuovere la conservazione dell’energia e gestire meglio le risorse in modo più sostenibile.
Predict Energy Consumption è un progetto guidato, ma puoi replicarne gli obiettivi su un dataset diverso, come la domanda di bike sharing a Seul. Lavorare su un dataset completamente nuovo ti aiuterà nel debug del codice e a migliorare le capacità di problem solving.
Nel progetto From Data to Dollars - Predicting Insurance Charges vestirai i panni di un Data Scientist in una compagnia di assicurazioni sanitarie. Costruirai un modello predittivo per stimare i costi assicurativi in base agli attributi di un cliente, come età e fattori di salute. Questo progetto offre un’applicazione pratica del machine learning in ambito business, consentendo modelli di pricing più accurati e aiutando le aziende a gestire il rischio offrendo strategie di prezzo personalizzate ai clienti.
Predicting Insurance Charges è un progetto guidato. Puoi replicarne i risultati su un dataset diverso, come quello di Hotel Booking Demand. Puoi usarlo per prevedere se un cliente cancellerà o meno la prenotazione.
Nel progetto Predicting Credit Card Approvals costruirai un’applicazione per l’approvazione automatica delle carte di credito utilizzando l’ottimizzazione degli iperparametri e la Regressione Logistica.
Applicherai competenze come gestione dei valori mancanti, elaborazione di variabili categoriche, scaling delle feature, gestione di dati sbilanciati ed esecuzione dell’ottimizzazione automatica degli iperparametri con GridCV. Questo progetto ti metterà alla prova oltre la gestione di dati semplici e puliti.

Immagine dell’autore
Predicting Credit Card Approvals è un progetto guidato. Puoi replicarne i risultati su un dataset diverso, come i dati sui prestiti di LendingClub.com. Puoi usarlo per costruire un sistema di approvazione automatica dei prestiti.
Puoi impostare un progetto di predizione della qualità del vino utilizzando un dataset di proprietà fisico-chimiche del vino, come contenuto alcolico, acidità e livelli di zucchero. Applicando modelli di classificazione, come la regressione logistica in scikit-learn, puoi classificare i vini su una scala da 1 a 10.
Questo progetto è importante per le industrie coinvolte nella produzione e nel controllo qualità del vino, perché consente di monitorare e prevedere in modo coerente la qualità, garantendo l’eccellenza del prodotto.
Nel Predictive Modeling for Agriculture Data Science Project costruirai un semplice sistema di raccomandazione delle colture usando machine learning supervisionato e selezione delle feature. Lavorerai con quattro attributi essenziali del suolo: azoto, fosforo, potassio e pH. Affronterai un vincolo realistico: l’agricoltore può permettersi di misurarne solo uno. Il tuo compito è identificare quale singola caratteristica predice meglio la coltura giusta e addestrare un classificatore leggero per fornire quella raccomandazione in modo affidabile.
Allenerai competenze pratiche come gestione dei valori mancanti, encoding delle etichette, scaling delle feature, valutazione dei modelli e, soprattutto, applicazione e confronto di due tecniche di selezione delle feature per classificare le misure del suolo.
Store Sales è una competizione introduttiva su Kaggle dove i partecipanti addestrano vari modelli di serie temporali per migliorare il punteggio in classifica. Nel progetto ti verranno forniti i dati di vendita dei negozi e ti occuperai di pulizia dei dati, analisi approfondita di serie temporali, feature scaling e addestramento di un modello multivariato per serie temporali.
Per migliorare il tuo punteggio in classifica, puoi usare tecniche di ensembling come Bagging e Voting Regressor.
Immagine da Kaggle
Store Sales è un progetto basato su Kaggle in cui puoi consultare i notebook degli altri partecipanti.
Per approfondire la previsione di serie temporali, prova ad applicare le tue competenze al dataset Stock Exchange e usa Facebook Prophet per addestrare un modello univariato di forecasting.
Questi progetti intermedi di machine learning si concentrano sull’elaborazione dei dati e sull’addestramento di modelli per dataset strutturati e non strutturati. Impara a pulire, elaborare e aumentare il dataset utilizzando vari strumenti statistici.
Il progetto Reveal Categories Found in Data ti aiuta a esplorare i feedback dei clienti utilizzando clustering e natural language processing (NLP). Organizzerai le recensioni del Google Play Store in categorie distinte con il clustering K-means. Comprendere i temi ricorrenti nei feedback è essenziale per i team di prodotto per affrontare i pain point degli utenti, migliorare le funzionalità e aumentare la soddisfazione grazie a insight azionabili.
Prova a replicare il risultato su un dataset diverso, come il dataset Netflix Movie.
Nel progetto Word Frequency in Moby Dick effettuerai lo scraping del testo di Moby Dick di Herman Melville e analizzerai la frequenza delle parole usando la libreria nltk di Python. Questo progetto introduce tecniche chiave di NLP e aiuta a comprendere come le parole più usate rivelino pattern nel testo. È un ottimo progetto per appassionati di letteratura, storici o ricercatori interessati al text mining e all’analisi linguistica.
Nel progetto Facial Recognition with Supervised Learning costruirai un modello di riconoscimento facciale utilizzando tecniche supervisionate con Python e scikit-learn. Il modello distingue tra immagini di Arnold Schwarzenegger e altre persone. Questo progetto è importante nel crescente campo del riconoscimento facciale, con ampie applicazioni in sicurezza, sistemi di autenticazione e persino piattaforme social dove il rilevamento dei volti è comune.
Crea un predittore di popolarità dei libri per una libreria online convertendo dati eterogenei, come testo (ad es. titoli e descrizioni) e dati numerici (ad es. valutazioni e conteggi), in feature efficaci. Seguirai l’intero flusso di lavoro di machine learning, che include una rapida EDA (analisi esplorativa dei dati), la correzione dei tipi di dato, la trasformazione di variabili testuali e numeriche e il fine-tuning di un modello per ottenere la massima accuratezza possibile.
Imparerai a gestire dati disordinati e multi-formato e a valutare i risultati usando una pipeline pulita e riutilizzabile. Al termine, saprai applicare gli stessi metodi a qualsiasi catalogo, che sia la tua lista di lettura personale o dataset pubblici, per prevedere potenziali bestseller e migliorare i sistemi di raccomandazione.
Nel progetto Clustering Antarctic Penguin Species userai l’apprendimento non supervisionato per scoprire gruppi naturali di pinguini senza etichette. Pulirai un dataset in stile Palmer Penguins, gestirai i valori mancanti, scalerai feature numeriche come lunghezza e profondità del becco, lunghezza delle pinne e massa corporea e, opzionalmente, effettuerai l’encoding di semplici variabili categoriche come isola o sesso prima di applicare il clustering K-means.
Selezionerai poi il numero di cluster con elbow e silhouette score, visualizzerai la struttura con PCA e confronterai i cluster con le specie note per un rapido controllo di coerenza.
Nel progetto Taxi Route Optimization with Reinforcement Learning allenerai un agente di Q-learning per risolvere l’ambiente Taxi-v3 di Gymnasium imparando percorsi efficienti di pickup e drop-off. Costruirai una tabella stato–azione, bilancerai esplorazione ed exploit con una politica epsilon-greedy e regolerai iperparametri chiave come learning rate, fattore di sconto e decadimento di epsilon per velocizzare la convergenza.

Valuterai poi le performance con la ricompensa media per episodio e i passi al completamento, visualizzerai la curva di apprendimento e testerai la politica addestrata su episodi mai visti.
Usa il dataset Wisconsin Breast Cancer per prevedere se un tumore è maligno o benigno. Il dataset include dettagli sulle caratteristiche del tumore, come texture, perimetro e area; il tuo obiettivo è costruire un modello di classificazione che predica la diagnosi in base a queste caratteristiche.
Questo progetto è fondamentale nelle applicazioni sanitarie, fornendo preziose indicazioni per l’analisi dei dati medici e il potenziale sviluppo di strumenti diagnostici in grado di supportare la rilevazione precoce del cancro.
Nel progetto Speech Emotion Recognition with Librosa elaborerai file audio utilizzando Librosa, soundfile e sklearn per l’MLPClassifier, allo scopo di riconoscere l’emozione dai file audio.
Caricherai ed elaborerai i file audio, eseguirai l’estrazione delle feature e addestrerai il modello classificatore Multi-Layer Perceptron. Il progetto ti insegnerà le basi dell’elaborazione audio, così da poter passare all’addestramento di un modello di deep learning per ottenere una migliore accuratezza.
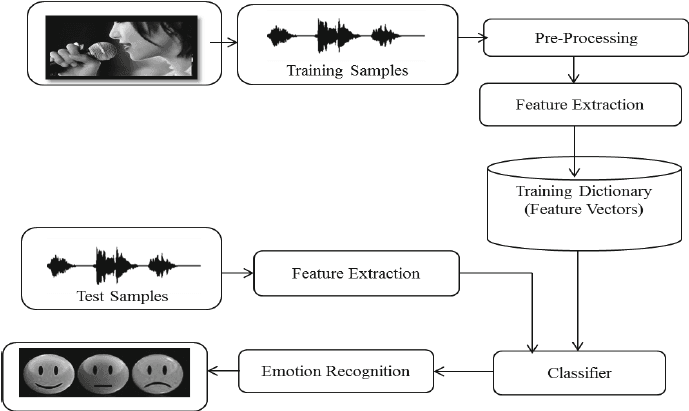
Immagine da researchgate.net
Questi progetti avanzati di machine learning si concentrano sulla costruzione e l’addestramento di modelli di deep learning e sull’elaborazione di dataset non strutturati. Allenerai reti neurali convoluzionali, unità ricorrenti con gate, farai il fine-tuning di large language model e modelli di reinforcement learning.
Nel progetto Service Desk Ticket Classification with Deep Learning costruirai un classificatore di testo in PyTorch che instrada automaticamente i ticket in arrivo nella categoria corretta. Pulirai e tokenizzerai il testo, creerai suddivisioni di train e validation, convertirai i ticket in rappresentazioni vettoriali e addestrerai un modello neurale compatto, regolando batch size, learning rate e regolarizzazione per una convergenza stabile.
Valuterai poi con accuratezza e F1 pesato, ispezionerai una matrice di confusione per individuare categorie etichettate male o sovrapposte e applicherai tecniche per lo sbilanciamento come la loss pesata.
Nel progetto Build Rick Sanchez Bot Using Transformers userai DialoGPT e la libreria Transformers di Hugging Face per creare il tuo chatbot AI.
Elaborerai e trasformerai i tuoi dati, costruirai e farai il fine-tuning del Large-scale Pretrained Response Generation Model (DialoGPT) di Microsoft sul dataset di dialoghi di Rick and Morty. Puoi anche creare una semplice app Gradio per testare il modello in tempo reale: Rick & Morty Block Party.
Il progetto Building an E-Commerce Clothing Classifier Model with Keras si concentra sulla classificazione di immagini nel contesto dell’e-commerce. Userai Keras per costruire un modello di machine learning che automatizza la classificazione dei capi in base alle immagini. È rilevante per migliorare l’esperienza d’acquisto aiutando i clienti a trovare più rapidamente i prodotti e snellendo la gestione dell’inventario. Una classificazione accurata supporta anche raccomandazioni personalizzate, aumentando engagement e vendite.
Nel progetto Detect Traffic Signs with Deep Learning userai Keras per sviluppare un modello di deep learning in grado di rilevare segnali stradali, come stop e semafori. Questa tecnologia è fondamentale per i veicoli a guida autonoma, dove il riconoscimento rapido e accurato dei segnali è essenziale per una navigazione sicura. Questo progetto pone le basi per sviluppare sistemi di guida autonoma più avanzati, sicuri e affidabili.
Nel progetto Building a Demand Forecasting Model userai PySpark per prevedere su larga scala la domanda di prodotti e-commerce. Caricherai dati transazionali, costruirai feature temporali come ritardi e medie mobili, effettuerai split temporali per una valutazione onesta e addestrerai un modello base insieme a un modello di apprendimento come Gradient-Boosted Trees o Random Forest per catturare trend e stagionalità.
Valuterai poi con MAE, RMSE e MAPE, confronterai con il baseline e analizzerai gli errori per SKU e finestra temporale per individuare bias e volatilità.
Nel progetto Predicting Temperature in London eseguirai un esperimento ML strutturato per prevedere la temperatura media giornaliera a partire da dati meteorologici storici. Caricherai e pulirai il dataset, creerai split sensibili al tempo, costruirai feature come medie mobili e valori ritardati e addestrerai diversi modelli candidati usando scikit-learn.
Coordinerai poi il flusso di lavoro con funzioni riutilizzabili e traccerai tutto in MLflow, registrando parametri, metriche e artifact per confrontare le esecuzioni.
Connect X è una competizione di simulazione su Kaggle. Costruisci un agente di RL (Reinforcement Learning) per competere contro altri partecipanti alla competizione di Kaggle.
Per prima cosa imparerai come funziona il gioco e creerai un agente funzionale di base come riferimento. Successivamente, inizierai a sperimentare vari algoritmi di RL e architetture di modello. Puoi provare a costruire un modello con Deep Q-learning o con l’algoritmo Proximal Policy Optimization.
Il progetto di fine corso richiede di dedicare un certo tempo a produrre una soluzione unica. Farai ricerca su più architetture di modello, userai vari framework di machine learning per normalizzare e aumentare i dataset, comprenderai la matematica alla base del processo e scriverai una tesi basata sui risultati.
Nel modello Multi-Lingual ASR farai il fine-tuning del modello Wave2Vec XLS-R utilizzando audio e trascrizioni in turco per costruire un sistema di riconoscimento automatico del parlato.
Per prima cosa comprenderai i file audio e il dataset testuale, poi userai un tokenizer di testo, estrarrai feature ed elaborerai i file audio. Successivamente, creerai un trainer, la funzione WER, caricherai modelli preaddestrati, regolerai gli iperparametri e addestrerai e valuterai il modello.
Puoi usare la piattaforma Hugging Face per archiviare i pesi del modello e pubblicare app web per trascrivere il parlato in tempo reale: Streaming Urdu Asr.
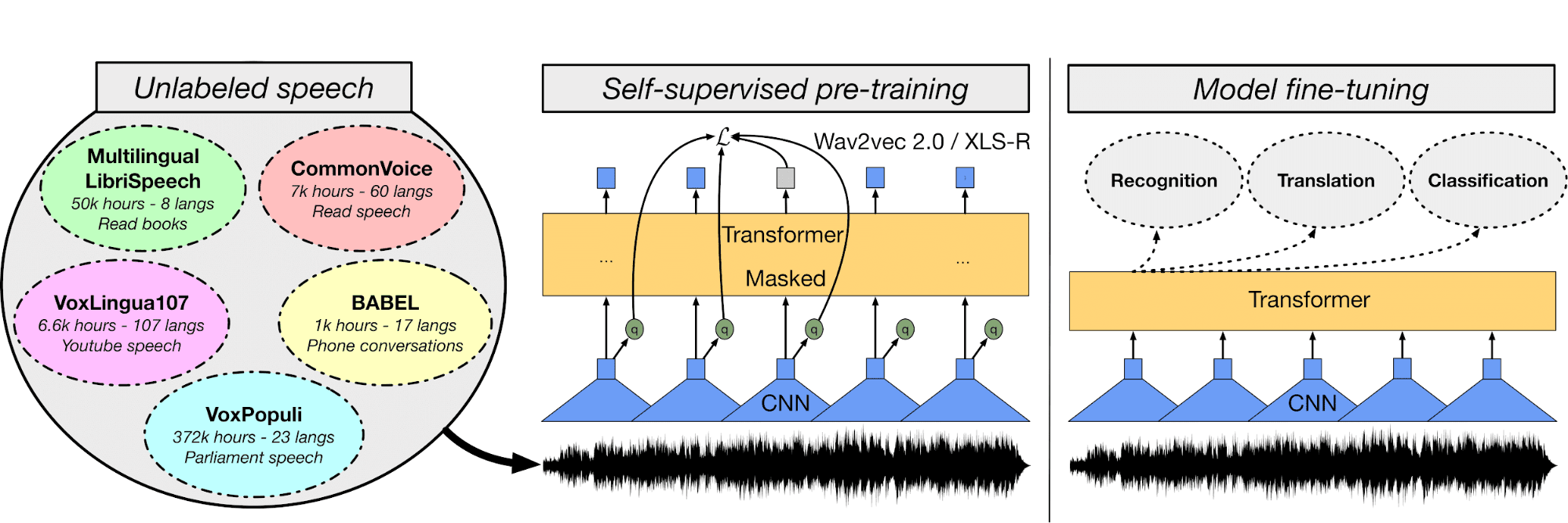
Immagine da huggingface.co
Nel progetto One Shot Face Stylization puoi modificare il modello per migliorare i risultati oppure fare il fine-tuning di JoJoGAN su un nuovo dataset per creare la tua applicazione di stilizzazione.
Utilizzerà l’immagine originale per generare una nuova immagine tramite inversione GAN e fine-tuning di uno StyleGAN preaddestrato. Comprenderai varie architetture di generative adversarial network. Successivamente, inizierai a raccogliere un dataset appaiato per creare uno stile a tua scelta.
Poi, con l’aiuto di una soluzione di esempio della versione precedente di StyleGAN, sperimenterai la nuova architettura per produrre arte realistica.
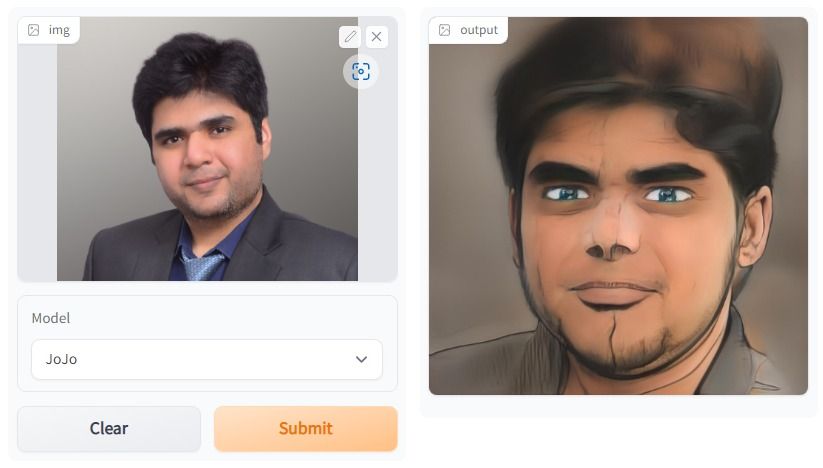
Immagine creata con JoJoGAN
Nel progetto H&M Personalized Fashion Recommendations costruirai raccomandazioni di prodotto basate su transazioni precedenti, dati dei clienti e metadati dei prodotti.
Il progetto metterà alla prova le tue competenze di NLP, CV (Computer Vision) e deep learning. Nelle prime settimane comprenderai i dati e come usare varie feature per ottenere un baseline.
Poi crea un modello semplice che utilizzi solo le feature testuali e categoriche per prevedere raccomandazioni. Successivamente, passa a combinare NLP e CV per migliorare il punteggio in classifica. Puoi anche comprendere meglio il problema consultando discussioni e codice della community.

Immagine da H&M EDA FIRST LOOK
Nel progetto Analyzing Customer Support Calls costruirai una pipeline end-to-end che trasforma audio grezzo in insight. Trascriverai le chiamate con un modello di riconoscimento del parlato, pulirai e segmenterai il testo, eseguirai l’analisi del sentiment ed estrarrai entità come prodotti, piani, località e nomi. Indicerai inoltre le trascrizioni con embedding per abilitare una ricerca semantica veloce tra le conversazioni.
Valuterai poi la qualità delle trascrizioni e le performance del modello, raggrupperai i temi per rivelare i driver più comuni delle chiamate ed evidenzierai aspetti come picchi di sentiment negativo o keyword di escalation.
Nel progetto Monitoring A Financial Fraud Detection Model agirai come data scientist post-deployment per una banca del Regno Unito, diagnosticando perché un modello antifrode in produzione sta peggiorando. Caricherai predizioni e outcome di produzione, traccerai metriche chiave come precision, recall, PR-AUC e calibrazione e visualizzerai le performance nel tempo per individuare il degrado. Effettuerai anche analisi per canale, regione e segmento di clientela per trovare dove si concentrano i falsi positivi o falsi negativi.
Testerai poi data drift e concept drift con controlli di distribuzione e indici di stabilità, ispezionerai gli spostamenti di feature importance e userai strumenti di explainability per confrontare il comportamento attuale con il baseline.
Nel progetto MuZero for Atari 2600 costruirai, allenerai e convaliderai un agente di reinforcement learning utilizzando l’algoritmo MuZero per giochi Atari 2600. Leggi il tutorial per capire meglio l’algoritmo MuZero.
L’obiettivo è costruire una nuova architettura o modificarne una esistente per migliorare il punteggio in una classifica globale. Serviranno più di tre mesi per comprendere come funziona l’algoritmo nel reinforcement learning.
Questo progetto è molto denso di matematica e richiede esperienza in Python. Puoi trovare soluzioni proposte, ma per raggiungere le prime posizioni al mondo dovrai costruire la tua soluzione.
Il progetto MLOps End-To-End Machine Learning è fondamentale per essere assunti nelle migliori aziende. Oggi i recruiter cercano ML engineer in grado di creare sistemi end-to-end usando strumenti MLOps, orchestrazione dei dati e cloud computing.
In questo progetto costruirai e distribuirai un classificatore di immagini di località usando TensorFlow, Streamlit, Docker, Kubernetes, cloudbuild, GitHub e Google Cloud. L’obiettivo principale è automatizzare la costruzione e la distribuzione di modelli di machine learning in produzione tramite CI/CD. Per una guida, leggi il tutorial Machine Learning, Pipelines, Deployment, and MLOps.
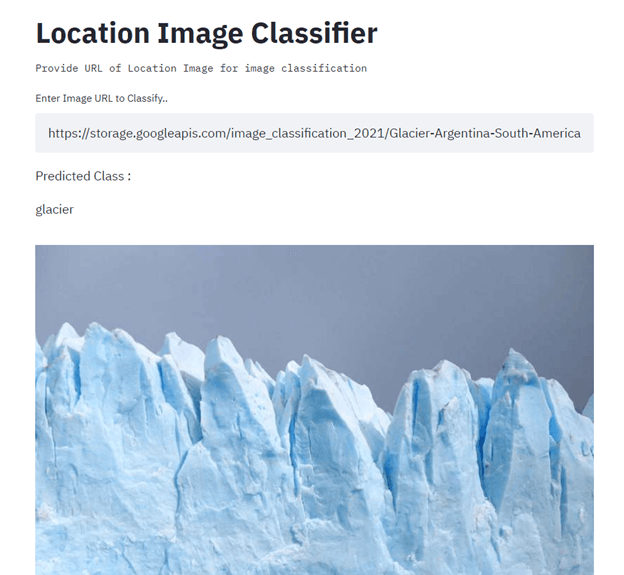
Immagine di Senthil E
Per costruire il tuo portfolio di machine learning, ti servono progetti che si distinguano. Dimostra al responsabile delle assunzioni o al recruiter che sai scrivere codice in più linguaggi, comprendere vari framework di machine learning, risolvere problemi unici con il machine learning e conoscere l’ecosistema end-to-end del machine learning.
Nel progetto Fine-Tuning GPT-OSS installerai le dipendenze, caricherai il modello e il tokenizer, definirai uno stile di prompt chiaro con il pacchetto Harmony per Python ed eseguirai un’inferenza di base rapida per verificare che tutto funzioni end-to-end.
Preparerai poi un dataset di Q&A medico con formattazione Harmony, configurerai l’addestramento e farai il fine-tuning del modello, seguito da una valutazione post-tuning per misurare i miglioramenti.
Nel progetto Fine-Tuning MedGemma on a Brain MRI Dataset adatterai il modello multimodale MedGemma 4B, l’encoder di immagini SigLIP e un LLM ottimizzato per il dominio medico per classificare scansioni MRI cerebrali. Imposterai l’ambiente su RunPod, installerai i pacchetti Python necessari, caricherai e pulirai un dataset di MRI e preparerai gli input con ridimensionamento coerente, normalizzazione e mapping delle etichette prima di eseguire un’inferenza di controllo rapido.
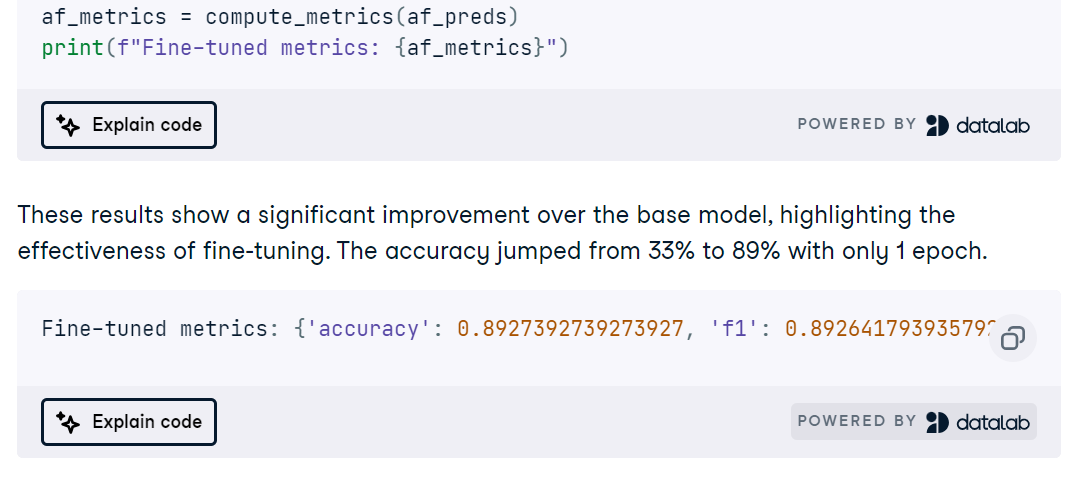
Farai poi il fine-tuning di MedGemma sul task MRI, traccerai le curve di addestramento e valuterai con accuratezza, ROC AUC, precision, recall e matrici di confusione per individuare i failure mode.
Nel progetto Fine-tuning Stable Diffusion XL with DreamBooth and LoRA configurerai SDXL in Python con Diffusers, caricherai il modello base FP16 e la VAE su una GPU CUDA e genererai immagini da prompt brevi. Esplorerai potenziamenti rapidi della qualità con il refiner di SDXL, confronterai gli output e userai un’utility a griglia semplice per rivedere affiancate più generazioni.
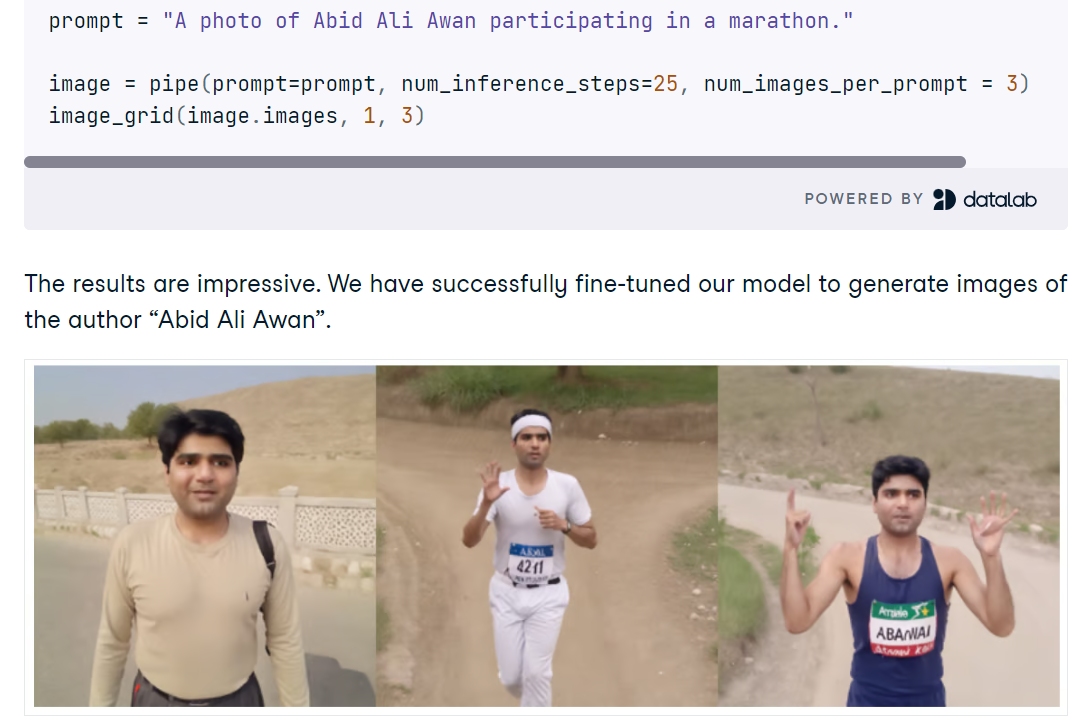
Farai poi il fine-tuning di SDXL su un piccolo set di foto personali utilizzando AutoTrain Advanced con DreamBooth, producendo un adapter LoRA compatto invece di un checkpoint completo per un’inferenza rapida ed efficiente in memoria. Dopo l’addestramento, collegherai i pesi LoRA alla pipeline di base, testerai nuovi prompt e valuterai quando il refiner aiuta o danneggia la fedeltà dell’identità.
Nel progetto Song Generation with Latent Diffusion configurerai un modello open-source di diffusione per la musica per generare canzoni complete da prompt testuali di stile o da una clip audio di riferimento. Installerai via Conda o Docker, preparerai l’ambiente (espeak-ng, percorsi phonemizer su Windows) ed eseguirai gli script di inferenza forniti per creare tracce con i checkpoint base o full, abilitando il decoding a chunk quando la VRAM è limitata.
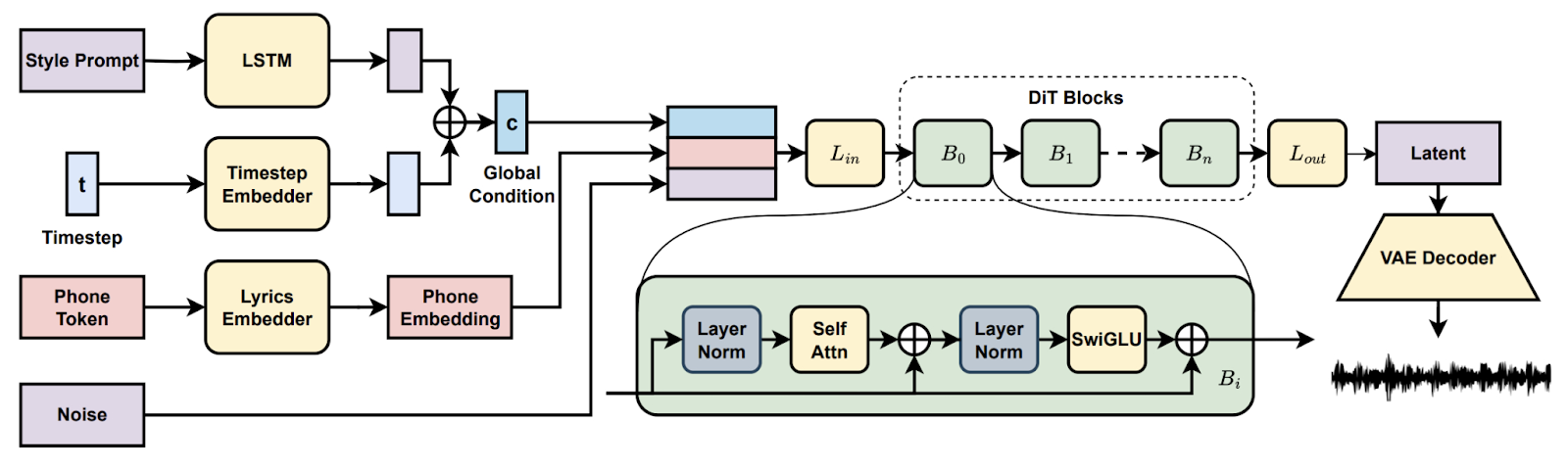
Esplorerai poi funzionalità come continuazione ed editing dei brani, confronterai arrangiamenti tra prompt e documenterai le impostazioni per la riproducibilità. Alla fine avrai una pipeline pratica per la creazione musicale end-to-end.
Nel progetto Deploying a Machine Learning Application to Production costruirai una pipeline ML completamente automatizzata con GitHub Actions che addestra, valuta, versiona e distribuisce un semplice modello di classificazione di farmaci. Imposterai la struttura del repository e il Makefile, aggiungerai setup dell’ambiente, linting, unit test e controlli sui dati, quindi creerai script per esecuzioni di training e valutazione riproducibili che registrano metriche e artifact.
Collegherai poi l’integrazione continua per attivarsi su pull request e push su main, pubblicherai gli artifact del modello con CML e Hugging Face CLI e promuoverai un modello valido alla distribuzione tramite workflow di continuous deployment.
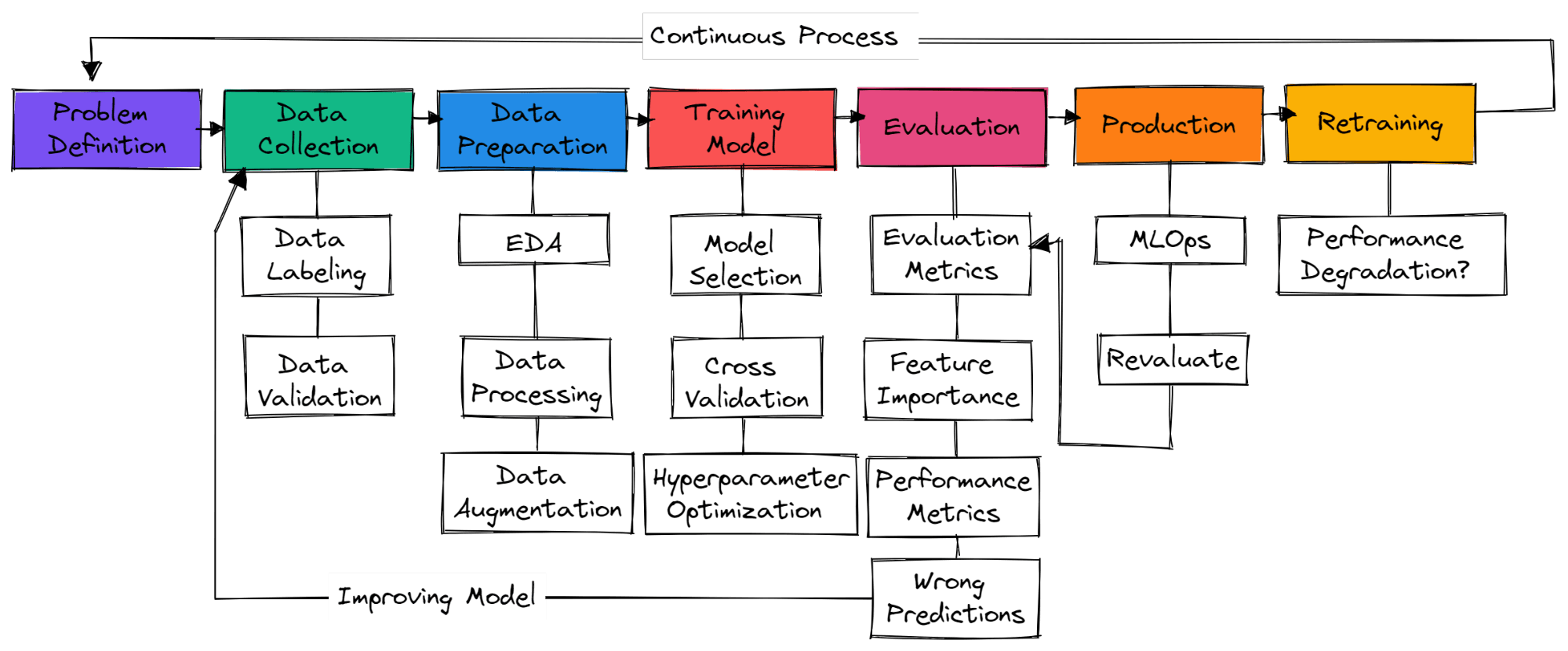
Immagine dell’autore
Non esistono passaggi standard in un tipico progetto di machine learning. Può trattarsi semplicemente di raccolta dati, preparazione dei dati e addestramento del modello. In questa sezione vedremo i passaggi necessari per costruire un progetto di machine learning pronto per la produzione.
Devi comprendere il problema di business e farti un’idea di come userai il machine learning per risolverlo. Cerca paper accademici, progetti open source, tutorial e applicazioni simili usate da altre aziende. Assicurati che la tua soluzione sia realistica e che i dati siano facilmente disponibili.
Raccoglierai dati da varie fonti, li pulirai e annoterai e creerai script per le validazioni dei dati. Assicurati che i tuoi dati non siano faziosi e non contengano informazioni sensibili.
Compila i valori mancanti, pulisci ed elabora i dati per l’analisi. Usa strumenti di visualizzazione per comprendere la distribuzione dei dati e come sfruttare le feature per migliorare le prestazioni del modello. Feature scaling e data augmentation servono a trasformare i dati per un modello di machine learning.
Seleziona reti neurali o algoritmi di machine learning comunemente usati per problemi specifici. Addestra il modello usando la cross-validation e varie tecniche di ottimizzazione degli iperparametri per ottenere risultati ottimali.
Valuta il modello sul dataset di test. Assicurati di usare la metrica di valutazione corretta per il problema specifico. L’accuratezza non è valida per tutti i tipi di problemi. Controlla F1 o AUC per la classificazione o RMSE per la regressione. Visualizza la feature importance del modello per eliminare le feature non importanti. Valuta metriche di performance come tempo di training e di inferenza.
Assicurati che il modello superi il baseline umano. In caso contrario, torna a raccogliere dati di qualità e ricomincia il processo. È un processo iterativo in cui continuerai ad addestrare con varie tecniche di feature engineering, architetture di modello e framework di machine learning per migliorare le prestazioni.
Dopo aver raggiunto risultati all’avanguardia è il momento di distribuire il tuo modello di machine learning in produzione/cloud usando strumenti MLOps. Monitora il modello su dati in tempo reale. Molti modelli falliscono in produzione, quindi è una buona idea distribuirli a un piccolo sottoinsieme di utenti.
Se il modello non raggiunge i risultati, tornerai al tavolo da disegno per trovare una soluzione migliore. Anche se ottieni ottimi risultati, il modello può degradarsi nel tempo a causa di data drift e concept drift. Eseguire nuovamente il training con nuovi dati consente al modello di adattarsi ai cambiamenti in tempo reale.
Corsi di Machine Learning
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

