Curso
Machine learning com PySpark
4 h
29.7K
Esses projetos de machine learning para iniciantes consistem em lidar com dados estruturados e tabulares. Você vai usar as habilidades de limpeza, processamento e visualização de dados para fins analíticos e usar a estrutura scikit-learn para treinar e validar modelos de machine learning.
Se você quer aprender primeiro os conceitos básicos de machine learning, a gente tem um curso incrível sobre machine learning sem código. Você também pode conferir alguns dos nossos projetos de IA se quiser melhorar suas habilidades nessa área.
No projeto Predict Energy Consumption, você vai usar modelos de regressão e machine learning para prever o consumo diário de energia com base em fatores temporais, como hora do dia e temperatura. O objetivo é descobrir padrões que possam otimizar o uso de energia, melhorando a eficiência e reduzindo custos. Isso é super importante para empresas de serviços públicos e outras que querem reduzir despesas operacionais, promover a conservação de energia e gerenciar melhor seus recursos de um jeito mais sustentável.
O projeto Predict Energy Consumption é um projeto guiado, mas você pode replicar os objetivos em um conjunto de dados diferente, como a demanda por compartilhamento de bicicletas em Seul. Trabalhar com um conjunto de dados totalmente novo vai te ajudar a depurar o código e melhorar suas habilidades de resolução de problemas.
No projeto “De dados a dólares - Prevendo custos de seguros ”, você assume o papel de um cientista de dados em uma empresa de seguros de saúde. Você vai criar um modelo preditivo para estimar os custos do seguro com base nos atributos do cliente, como idade e fatores de saúde. Esse projeto mostra como usar machine learning nos negócios, criando modelos de preços mais precisos e ajudando as empresas a lidar com riscos, ao mesmo tempo que oferece estratégias de preços personalizadas para os clientes.
O projeto “Previsão de Encargos de Seguro” é um projeto guiado. Você pode replicar o resultado em um conjunto de dados diferente, como o de demanda de reservas de hotéis. Você pode usar isso pra prever se um cliente vai cancelar a reserva ou não.
No projeto Previsão de aprovações de cartão de crédito, você vai criar um aplicativo automático de aprovação de cartão de crédito usando otimização de hiperparâmetros e regressão logística.
Você vai usar a habilidade de lidar com valores ausentes, processar características categóricas, dimensionar características, lidar com dados desequilibrados e fazer a otimização automática de hiperparâmetros usando GridCV. Esse projeto vai te tirar da zona de conforto de lidar com dados simples e organizados.

Imagem do autor
Prever aprovações de cartão de crédito é um projeto guiado. Você pode replicar o resultado em um conjunto de dados diferente, como os dados de empréstimos do LendingClub.com. Você pode usar isso pra criar um preditor automático de aprovação de empréstimos.
Você poderia montar um projeto de previsão da qualidade do vinho, usando um conjunto de dados das propriedades físico-químicas do vinho, como teor alcoólico, acidez e níveis de açúcar. Usando modelos de classificação, tipo regressão logística no scikit-learn, dá pra classificar vinhos numa escala de 1 a 10.
Esse projeto é importante para as indústrias que trabalham com produção e controle de qualidade de vinhos, porque permite que elas monitorem e prevejam a qualidade do vinho de forma consistente, garantindo a excelência do produto.
No Projeto de Ciência de Dados para Modelagem Preditiva na Agricultura, você vai criar um sistema simples de recomendação de culturas usando machine learning supervisionado e seleção de recursos. Trabalhando com quatro atributos essenciais do solo: nitrogênio, fósforo, potássio e pH. Você vai ter uma limitação realista: o agricultor só pode pagar para medir um. Sua tarefa é descobrir qual característica isolada melhor prevê a cultura certa e, em seguida, treinar um classificador leve para fazer essa recomendação de forma confiável.
Você vai praticar habilidades práticas, como lidar com valores ausentes, codificar rótulos, dimensionar recursos, avaliar modelos e, o mais importante, aplicar e comparar duas técnicas de seleção de recursos para classificar medidas de solo.
Store Sales é uma competição do Kaggle para iniciantes, na qual os participantes treinam vários modelos de séries temporais para melhorar sua pontuação no quadro de líderes. No projeto, você vai receber os dados de vendas da loja e vai limpar os dados, fazer uma análise detalhada de séries temporais, escalonamento de características e treinar o modelo multivariado de séries temporais.
Pra melhorar sua pontuação no quadro de líderes, você pode usar ensamblagens como Bagging e Regressores de Votação.
Imagem do Kaggle
Store Sales é um projeto baseado no Kaggle onde você pode ver os cadernos dos outros participantes.
Para entender melhor a previsão de séries temporais, tente usar suas habilidades no conjunto de dados da Bolsa de Valores e use o Facebook Prophet para treinar um modelo de previsão de séries temporais univariadas.
Esses projetos intermediários de machine learning focam no processamento de dados e modelos de treinamento para conjuntos de dados estruturados e não estruturados. Aprenda a limpar, processar e aumentar o conjunto de dados usando várias ferramentas estatísticas.
O projeto Revelar categorias encontradas nos dados ajuda você a explorar o feedback dos clientes usando agrupamento e processamento de linguagem natural (NLP). Você vai organizar as avaliações da Google Play Store em categorias diferentes usando o agrupamento K-means. Entender os temas comuns dos comentários dos clientes é essencial para que as equipes de desenvolvimento de produtos resolvam os pontos fracos dos usuários, melhorem os recursos e aumentem a satisfação dos usuários por meio de insights úteis.
Tenta replicar o resultado em um conjunto de dados diferente, como o conjunto de dados Netflix Movie.
No projeto Frequência de palavras em Moby Dick, você vai extrair o texto do livro Moby Dick, de Herman Melville, e analisar a frequência das palavras usando a biblioteca nltk do Python. Esse projeto apresenta as principais técnicas de processamento de linguagem natural (NLP) e ajuda a entender como as palavras mais usadas mostram padrões no texto. É um projeto incrível para quem curte literatura, história ou pesquisa em mineração de texto e análise linguística.
No projeto Reconhecimento facial com aprendizado supervisionado, você vai criar um modelo de reconhecimento facial usando técnicas de aprendizado supervisionado com Python e scikit-learn. O modelo consegue diferenciar entre imagens do Arnold Schwarzenegger e de outras pessoas. Esse projeto é importante no campo crescente da tecnologia de reconhecimento facial, com várias aplicações em segurança, sistemas de autenticação e até mesmo plataformas de mídia social, onde a detecção facial é bem comum.
Crie um previsor de popularidade de livros para uma livraria online, transformando dados mistos, como texto (por exemplo, títulos e descrições de livros) e dados numéricos (por exemplo, classificações e contagens), em recursos eficazes. Você vai participar de todo o fluxo de trabalho de machine learning, que inclui análise exploratória rápida de dados (EDA), correção de tipos de dados, transformação de variáveis numéricas e de texto e ajuste fino de um modelo para conseguir a maior precisão possível.
Você vai aprender a lidar com dados bagunçados e em vários formatos e avaliar os resultados usando um pipeline limpo e reutilizável. No final desse processo, você vai conseguir aplicar os mesmos métodos a qualquer catálogo, seja sua lista de leitura pessoal ou conjuntos de dados públicos, para prever potenciais best-sellers e melhorar os sistemas de recomendação.
No projeto Clustering Antarctic Penguin Species, você usa o aprendizado não supervisionado para descobrir grupos naturais de pinguins sem rótulos. Você vai limpar um conjunto de dados no estilo Palmer Penguins, lidar com valores ausentes, dimensionar características numéricas como comprimento do bico, profundidade do bico, comprimento da nadadeira e massa corporal e, se quiser, codificar um contexto categórico simples, como ilha ou sexo, antes de rodar o K-means.mass. Se quiser, codifique variáveis categóricas simples, como ilha ou sexo, antes de aplicar o agrupamento K-means.
Depois, você escolhe o número de clusters com pontuações de cotovelo e silhueta, visualiza a estrutura com PCA e compara os clusters com espécies conhecidas para uma rápida verificação de sanidade.
Na projeto Otimização de Rotas de Táxi com Aprendizado por Reforço, você treina um agente de aprendizagem Q para resolver o ambiente Taxi-v3 Gymnasium, aprendendo rotas eficientes de embarque e desembarque. Você vai criar uma tabela de valores de estado-ação, equilibrar exploração e exploração com uma política epsilon-greedy e ajustar hiperparâmetros essenciais, como taxa de aprendizagem, fator de desconto e decaimento epsilon, para acelerar a convergência.

Depois, você avalia o desempenho com a recompensa média por episódio e as etapas até a conclusão, visualiza a curva de aprendizado e testa a política treinada em episódios não vistos.
Use o conjunto de dados sobre câncer de mama de Wisconsin para prever se um tumor é maligno ou benigno. O conjunto de dados inclui detalhes sobre as características do tumor, como textura, perímetro e área, e seu objetivo é criar um modelo de classificação que preveja um diagnóstico com base nessas características.
Esse projeto é super importante nas aplicações de saúde, oferecendo informações valiosas sobre a análise de dados médicos e o potencial para desenvolver ferramentas de diagnóstico que podem ajudar na detecção precoce do câncer.
No projeto Reconhecimento de emoções na fala com Librosa, você vai processar arquivos de som usando Librosa, arquivos de som e sklearn para o MLPClassifier reconhecer emoções a partir de arquivos de som.
Você vai carregar e processar arquivos de som, extrair características e treinar o modelo classificador Multi-Layer Perceptron. O projeto vai te ensinar o básico sobre processamento de áudio pra você poder avançar no treinamento de um modelo de aprendizado profundo e conseguir uma precisão melhor.
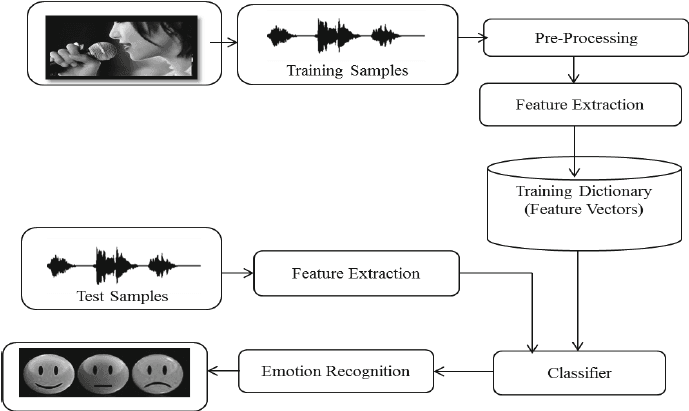
Imagem retirada de researchgate.net
Esses projetos avançados de machine learning focam na criação e no treinamento de modelos de machine learning profundo e no processamento de conjuntos de dados não estruturados. Você vai treinar redes neurais convolucionais, unidades recorrentes com porta, ajustar modelos de linguagem grandes e modelos de aprendizagem por reforço.
Na projeto Classificação de Tickets do Service Desk com Deep Learning, você cria um classificador de texto PyTorch que encaminha automaticamente os tickets recebidos para a categoria certa. Você vai limpar e tokenizar textos, criar divisões de treinamento e validação, transformar tickets em representações vetoriais e treinar um modelo neural compacto enquanto ajusta o tamanho do lote, a taxa de aprendizagem e a regularização para uma convergência estável.
Depois, você avalia com precisão e F1 ponderado, dá uma olhada na matriz de confusão para ver se tem categorias erradas ou sobrepostas e usa técnicas para desequilíbrio de classes, como perda ponderada.
No projeto “Criar o bot Rick Sanchez usando Transformers”, você vai usar o DialoGPT e a biblioteca Hugging Face Transformer para criar seu chatbot com inteligência artificial.
Você vai processar e transformar seus dados, construir e ajustar o Modelo de Geração de Respostas Pré-treinado em Grande Escala da Microsoft (DialoGPT) no conjunto de dados de diálogos de Rick e Morty. Você também pode criar um aplicativo Gradio simples para testar seu modelo em tempo real: Festa do bairro Rick & Morty.
O projeto Construindo um modelo classificador de roupas para comércio eletrônico com Keras foca na classificação de imagens no contexto do comércio eletrônico. Você vai usar o Keras pra criar um modelo de machine learning que automatiza a classificação de roupas com base em imagens. Isso é importante pra melhorar a experiência de compra, ajudando os clientes a encontrar produtos mais rápido e simplificando a gestão do estoque. Uma classificação precisa também ajuda nas recomendações personalizadas, aumentando o engajamento dos clientes e as vendas.
No projeto Detectar sinais de trânsito com aprendizado profundo, você vai usar o Keras para desenvolver um modelo de aprendizado profundo capaz de detectar sinais de trânsito, como sinais de parada e semáforos. Essa tecnologia é super importante para veículos autônomos, onde o reconhecimento rápido e preciso dos sinais de trânsito é essencial para uma navegação segura. Esse projeto cria as bases para desenvolver sistemas de veículos autônomos mais avançados, seguros e confiáveis.
No projeto Construindo um Modelo de Previsão de Demanda, você usa o PySpark para prever a demanda por produtos de comércio eletrônico em grande escala. Você vai carregar dados transacionais, criar recursos baseados no tempo, como atrasos e médias móveis, dividir por tempo para uma avaliação honesta e treinar uma linha de base junto com um modelo de aprendizado, como Gradient-Boosted Trees ou Random Forest, para capturar tendências e sazonalidade.
Depois, você avalia com MAE, RMSE e MAPE, compara com a linha de base e analisa os erros por SKU e janela de tempo para identificar viés e volatilidade.
No Projeto de previsão da temperatura em Londres, você faz um experimento de ML estruturado para prever a temperatura média diária a partir de dados meteorológicos históricos. Você vai carregar e limpar o conjunto de dados, criar divisões com base no tempo, criar recursos como médias móveis e valores defasados e treinar vários modelos candidatos usando o scikit-learn.
Depois, você organiza o fluxo de trabalho com funções reutilizáveis e programa tudo no MLflow, registrando parâmetros, métricas e artefatos para comparar as execuções.
Connect X é uma competição de simulação da Kaggle. Crie um agente RL (Reinforcement Learning) para competir com outros participantes da competição Kaggle.
Primeiro, você vai aprender como o jogo funciona e criar um agente funcional fictício para servir de base. Depois disso, você vai começar a experimentar vários algoritmos RL e arquiteturas de modelo. Você pode tentar criar um modelo com o algoritmo Deep Q-learning ou Proximal Policy Optimization.
O projeto do último ano exige que você dedique um certo tempo para criar uma solução única. Você vai pesquisar várias arquiteturas de modelos, usar várias estruturas de machine learning para normalizar e aumentar os conjuntos de dados, entender a matemática por trás do processo e escrever uma tese com base nos seus resultados.
No modelo ASR multilíngue, você vai ajustar o modelo Wave2Vec XLS-R usando áudio e transcrição em turco para criar um sistema de reconhecimento automático de fala.
Primeiro, você vai entender os arquivos de áudio e o conjunto de dados de texto, depois usar um tokenizador de texto, extrair recursos e processar os arquivos de áudio. Depois disso, você vai criar um treinador, a função WER, carregar modelos pré-treinados, ajustar hiperparâmetros e treinar e avaliar o modelo.
Você pode usar a plataforma Hugging Face para guardar os pesos do modelo e publicar aplicativos web para transcrever a fala em tempo real: Transmissão ao vivo em urdu Asr.
Imagem de huggingface.co
No projeto One Shot Face Stylization, você pode modificar o modelo para melhorar os resultados ou ajustar o JoJoGAN em um novo conjunto de dados para criar sua aplicação de estilização.
Ele vai usar a imagem original pra gerar uma nova imagem usando inversão GAN e ajustando um StyleGAN pré-treinado. Você vai entender várias arquiteturas de redes adversárias generativas. Depois disso, você vai começar a juntar um conjunto de dados emparelhados para criar um estilo da sua escolha.
Então, com a ajuda de uma solução de amostra da versão anterior do StyleGAN, você vai experimentar a nova arquitetura para criar arte realista.
A imagem foi criada usando o JoJoGAN.
No projeto Recomendações de Moda Personalizadas da H&M, você vai criar recomendações de produtos com base em transações anteriores, dados de clientes e metadados de produtos.
O projeto vai testar suas habilidades em PNL, CV (Visão Computacional) e aprendizado profundo. Nas primeiras semanas, você vai entender os dados e como usar vários recursos para criar uma linha de base.
Depois, crie um modelo simples que só use o texto e as características categóricas para prever recomendações. Depois disso, passe a combinar NLP e CV para melhorar sua pontuação no quadro de líderes. Você também pode entender melhor o problema conferindo as discussões da comunidade e o código.

Imagem da H&M EDA FIRST LOOK
No projeto Analisando Chamadas de Suporte ao Cliente, você cria um pipeline completo que transforma áudio bruto em insights. Você vai transcrever chamadas com um modelo de reconhecimento automático de voz, limpar e segmentar textos, fazer análises de sentimentos e extrair coisas como produtos, planos, lugares e nomes. Você também vai indexar transcrições com incorporações para permitir uma busca semântica rápida nas conversas.
Depois, você avalia a qualidade da transcrição e o desempenho do modelo, agrupa temas para descobrir os motivos comuns das chamadas e destaca pontos importantes, como picos de sentimento negativo ou palavras-chave de escalonamento.
No projeto Monitoramento de um Modelo de Detecção de Fraudes Financeiras, você atua como cientista de dados pós-implantação para um banco do Reino Unido, diagnosticando por que um modelo de fraude ativo está falhando. Você vai carregar previsões e resultados de produção, programar métricas importantes como precisão, recall, PR-AUC e calibração, além de visualizar o desempenho ao longo do tempo para detectar qualquer queda. Você também vai analisar por canal, região e segmento de clientes para descobrir onde estão os falsos positivos ou falsos negativos.
Depois, você testa a variação dos dados e conceitos usando verificações de distribuição e índices de estabilidade, dá uma olhada nas mudanças na importância dos recursos e usa ferramentas de explicabilidade para comparar o comportamento atual com o comportamento de referência.
No projeto MuZero para Atari 2600, você vai criar, treinar e validar o agente de aprendizagem por reforço usando o algoritmo MuZero para jogos Atari 2600. Dá uma olhada no tutorial pra entender melhor o algoritmo MuZero.
O objetivo é criar uma arquitetura nova ou modificar a que já existe para melhorar a pontuação no ranking global. Vai demorar mais de três meses para entender como o algoritmo funciona na aprendizagem por reforço.
Esse projeto envolve bastante matemática e precisa que você tenha experiência em Python. Você pode encontrar soluções sugeridas, mas pra chegar ao topo do ranking mundial, você precisa criar sua própria solução.
O projeto MLOps End-To-End machine learning é essencial pra você conseguir um emprego nas melhores empresas. Hoje em dia, os recrutadores estão procurando engenheiros de ML que possam criar sistemas completos usando ferramentas MLOps, orquestração de dados e computação em nuvem.
Neste projeto, você vai criar e implementar um classificador de imagens de localização usando TensorFlow, Streamlit, Docker, Kubernetes, cloudbuild, GitHub e Google Cloud. O principal objetivo é automatizar a criação e a implantação de modelos de machine learning na produção usando CI/CD. Para obter orientações, leia o tutorial sobre machine learning, pipelines, implantação e MLOps.
Imagem de Senthil E
Pra montar seu portfólio de machine learning, você precisa de projetos que se destaquem. Mostre ao gerente de contratação ou ao recrutador que você sabe programar em várias linguagens, entende várias estruturas de machine learning, resolve problemas únicos usando machine learning e entende o ecossistema completo do machine learning.
No projeto Fine-Tuning GPT-OSS , você vai instalar dependências, carregar o modelo e o tokenizador, definir um estilo de prompt claro com o pacote Harmony Python e executar uma inferência de linha de base rápida para confirmar que tudo funciona do início ao fim.
Depois, você prepara um conjunto de dados de perguntas e respostas médicas com a formatação Harmony, configura o treinamento e ajusta o modelo, seguido por uma avaliação pós-ajuste para medir as melhorias.
No projeto Fine-Tuning MedGemma on a Brain MRI Dataset, você adapta o modelo multimodal MedGemma 4B, o codificador de imagens SigLIP e um LLM ajustado para uso médico para classificar exames de ressonância magnética cerebral. Você vai configurar o ambiente no RunPod, instalar os pacotes Python necessários, carregar e limpar um conjunto de dados de ressonância magnética e preparar entradas com redimensionamento, normalização e mapeamento de rótulos consistentes antes de fazer uma inferência rápida de verificação de sanidade.
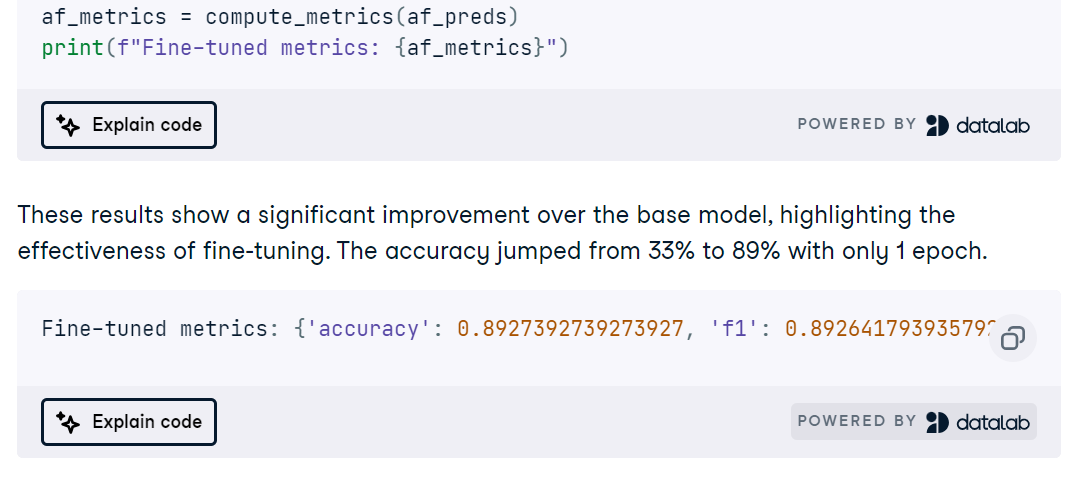
Em seguida, você ajusta o MedGemma na tarefa de ressonância magnética, programa as curvas de treinamento e avalia com precisão, ROC AUC, precisão, recall e matrizes de confusão para identificar modos de falha.
No projeto Fine-tuning Stable Diffusion XL com DreamBooth e LoRA, você configura o SDXL em Python com difusores, carrega o modelo base FP16 e VAE em uma GPU CUDA e gera imagens a partir de prompts curtos. Você vai ver como melhorar a qualidade rapidinho com o refinador SDXL, comparar resultados e usar uma ferramenta simples de grade pra conferir várias gerações lado a lado.
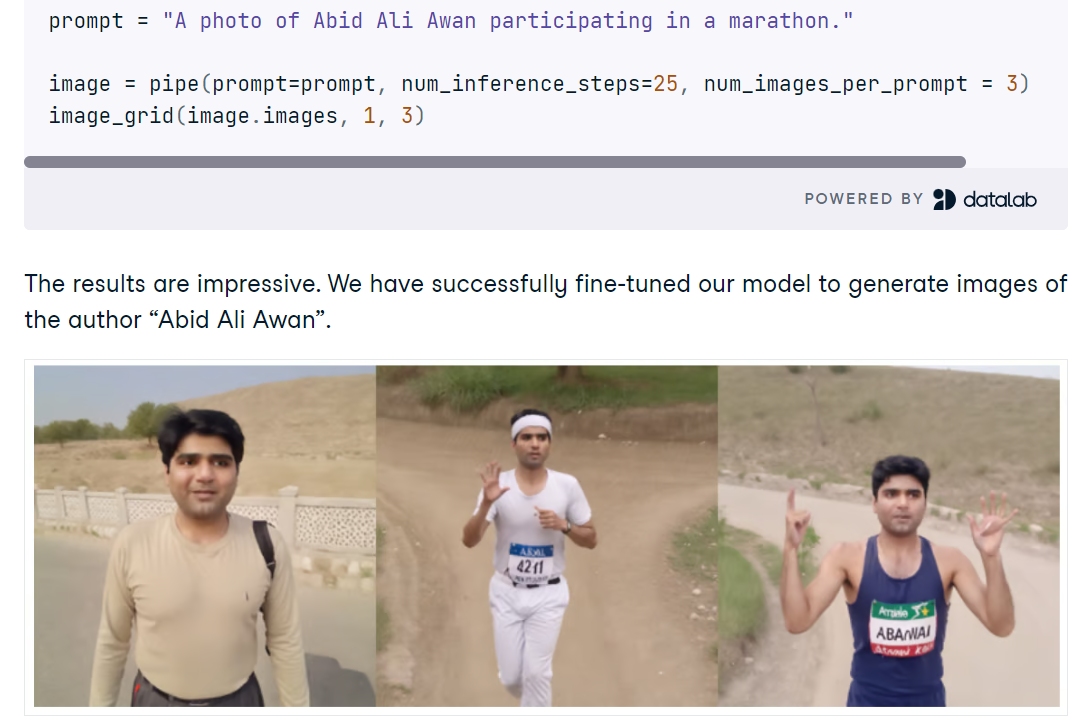
Em seguida, você ajusta o SDXL em um pequeno conjunto de fotos pessoais usando o AutoTrain Advanced com o DreamBooth, produzindo um adaptador LoRA compacto em vez de um ponto de verificação completo para uma inferência rápida e eficiente em termos de memória. Depois do treinamento, você coloca os pesos LoRA no pipeline base, testa novos prompts e vê se o refinador ajuda ou atrapalha a fidelidade da identidade.
Na projeto Song Generation with Latent Diffusion, você configura um modelo de música de difusão de código aberto para gerar músicas completas a partir de prompts de estilo de texto ou de um clipe de áudio de referência. Você vai instalar pelo Conda ou Docker, preparar o ambiente (espeak-ng, caminhos do phonemizer no Windows) e rodar os scripts de inferência fornecidos para criar programas com os pontos de verificação básicos ou completos, permitindo a decodificação em blocos quando a VRAM estiver apertada.
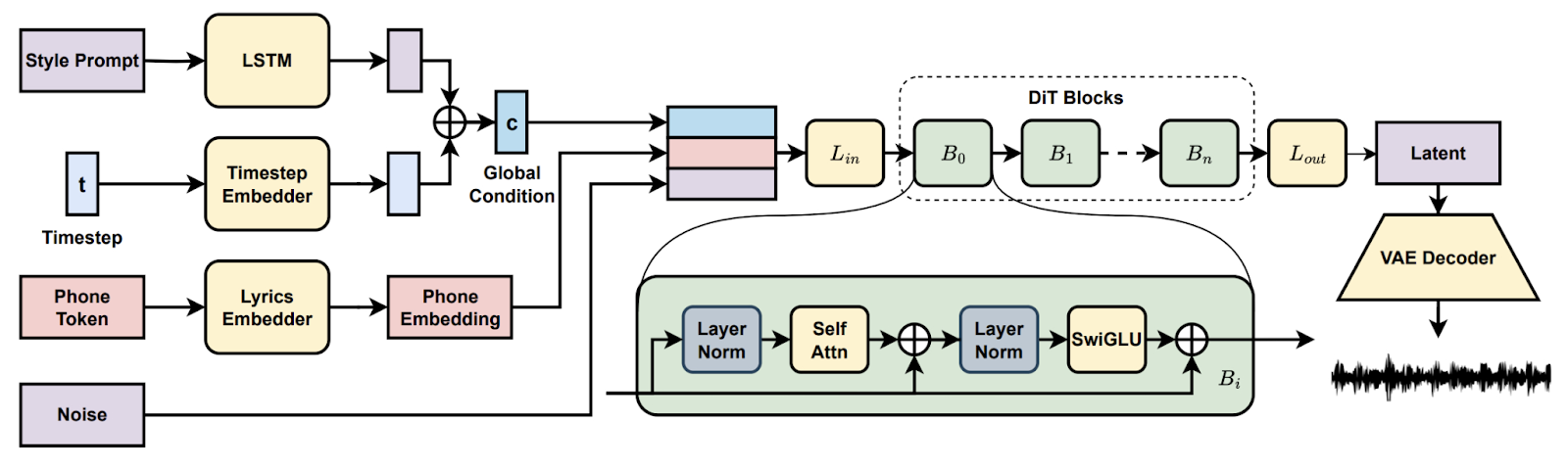
Depois, você pode ver recursos como continuação e edição de músicas, comparar arranjos entre prompts e documentar configurações para reproduzir. No final, você terá um pipeline prático para a criação musical de ponta a ponta.
No Implantação de um aplicativo de machine learning na produção, você cria um pipeline de ML totalmente automatizado com o GitHub Actions que treina, avalia, versiona e implanta um modelo simples de classificação de medicamentos. Você configura a estrutura do repositório e o Makefile, adiciona a configuração do ambiente, linting, testes de unidade e verificações de dados, depois cria scripts de treinamento e avaliação reproduzíveis que registram métricas e artefatos.
Depois, você conecta a integração contínua para disparar em pull requests e pushes principais, publica artefatos de modelo com CML e Hugging Face CLI e promove um modelo aprovado para implantação por meio de fluxos de trabalho de implantação contínua.
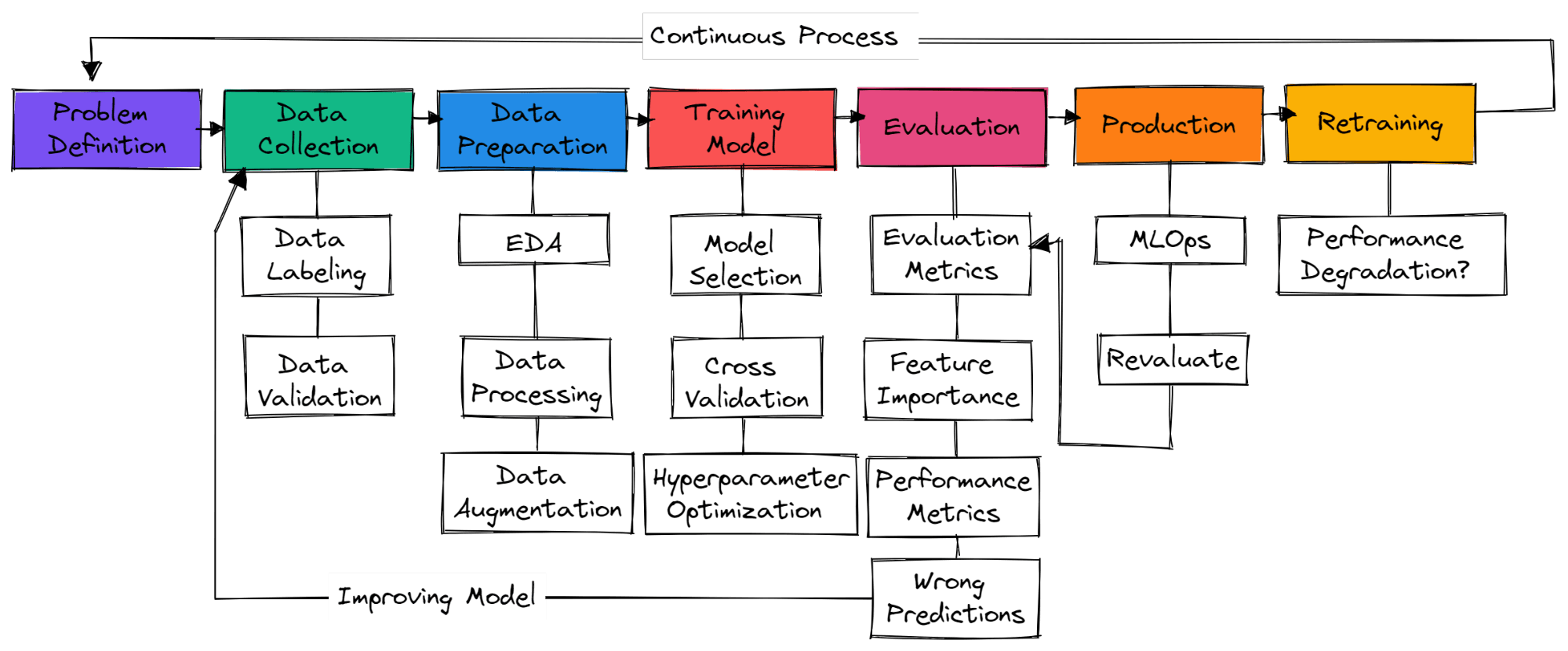
Imagem do autor
Não tem etapas padrão num projeto típico de machine learning. Então, pode ser só coleta de dados, preparação de dados e treinamento de modelos. Nesta seção, vamos aprender as etapas necessárias para criar um projeto de machine learning pronto para produção.
Você precisa entender o problema do negócio e ter uma ideia geral de como vai usar machine learning para resolver isso. Procure artigos de pesquisa, projetos de código aberto, tutoriais e aplicativos parecidos usados por outras empresas. Certifique-se de que sua solução seja realista e que os dados estejam facilmente disponíveis.
Você vai coletar dados de várias fontes, limpá-los e rotulá-los, além de criar scripts para validação de dados. Certifique-se de que seus dados não sejam tendenciosos nem contenham informações confidenciais.
Preencha os valores que faltam, limpe e processe os dados para análise. Use ferramentas de visualização para entender como os dados estão distribuídos e como você pode usar os recursos para melhorar o desempenho do modelo. O dimensionamento de recursos e o aumento de dados são usados para transformar dados para um modelo de machine learning.
escolhendo redes neurais ou algoritmos de machine learning que são normalmente usados para problemas específicos. Treinar o modelo usando validação cruzada e várias técnicas de otimização de hiperparâmetros para conseguir os melhores resultados.
Avaliando o modelo no conjunto de dados de teste. Certifique-se de que está usando a métrica de avaliação de modelo correta para problemas específicos. A precisão não é uma medida válida para todos os tipos de problemas. Dá uma olhada na pontuação F1 ou AUC para classificação ou RMSE para regressão. Visualize a importância dos recursos do modelo para descartar os que não são importantes. Avalie métricas de desempenho, como treinamento de modelos e tempo de inferência.
Certifique-se de que o modelo tenha superado a linha de base humana. Se não, volte a coletar mais dados de qualidade e comece o processo de novo. É um processo que vai se repetindo, onde você vai continuar treinando com várias técnicas de engenharia de recursos, arquitetos de modo e estruturas de machine learning para melhorar o desempenho.
Depois de conseguir resultados incríveis, é hora de colocar seu modelo de machine learning em produção/na nuvem usando as ferramentas MLOps. Fica de olho no modelo com dados em tempo real. A maioria dos modelos não dá certo na produção, então é uma boa ideia implementá-los para um pequeno grupo de usuários.
Se o modelo não der certo, você vai ter que voltar à prancheta e pensar em uma solução melhor. Mesmo que você consiga ótimos resultados, o modelo pode piorar com o tempo por causa do desvio de dados e do desvio de conceito. Treinar novamente os novos dados também faz com que seu modelo se adapte às mudanças em tempo real.
Cursos de machine learning
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Adel Nehme
15 min
blog
DataCamp Team
6 min
blog
Matt Crabtree
10 min
blog
Abid Ali Awan
15 min
blog
Natassha Selvaraj
15 min



