
Leerpad
Professionele data-engineer in Python
40 Hr
Dataworkflows en -pipelines vereisen vaak nauwkeurige coördinatie om te garanderen dat taken in de juiste volgorde worden uitgevoerd. De Directed Acyclic Graph (DAG) is een krachtig hulpmiddel om deze workflows efficiënt te beheren en fouten te voorkomen.
In dit artikel verkennen we DAG's en hun belang in data engineering, bekijken we enkele toepassingen en leren we hoe je ze gebruikt aan de hand van een praktisch voorbeeld met Airflow.
Om te begrijpen wat een DAG is, definiëren we eerst enkele kernbegrippen. In de informatica is een graaf een niet-lineaire datastructuur die bestaat uit knopen en randen. Knopen vertegenwoordigen afzonderlijke entiteiten of objecten, terwijl randen deze knopen verbinden en relaties of verbindingen ertussen voorstellen.
In een gerichte graaf hebben die randen een specifieke richting, wat een éénzijdige relatie tussen knopen aangeeft. Dit betekent dat als er een rand loopt van knoop A naar knoop B, dit een verbinding van A naar B impliceert, maar niet per se van B naar A.
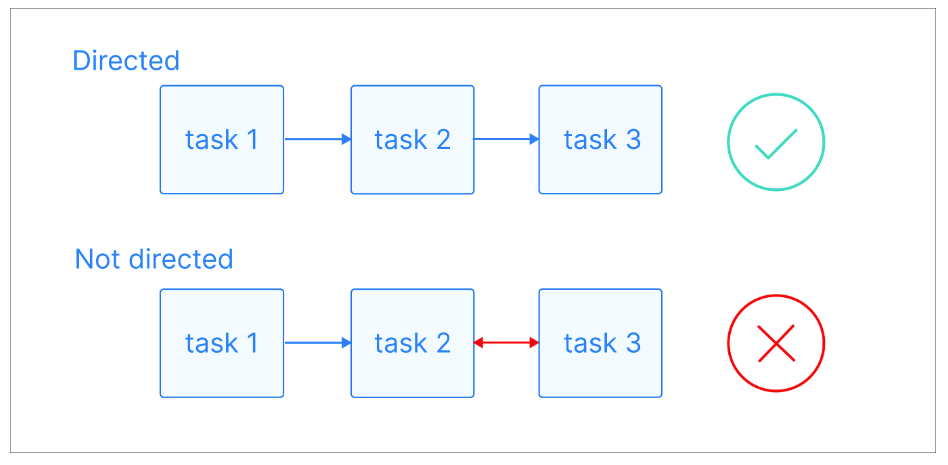
Visuele uitleg van gerichte grafen. Beeldbron: Astronomer
Een pad is een reeks knopen die verbonden zijn door gerichte randen. Het begint bij een specifieke knoop en volgt de richting van de randen om een andere knoop te bereiken. Een pad kan elke lengte hebben, van een enkele knoop tot een reeks van veel knopen, zolang de richting van de randen consequent wordt gevolgd.
Nu we de basisbegrippen hebben, bekijken we wat een DAG is: Een DAG is een gerichte graaf zonder gerichte cycli, waarbij elke knoop een specifieke taak vertegenwoordigt en elke rand de afhankelijkheid daartussen aangeeft.
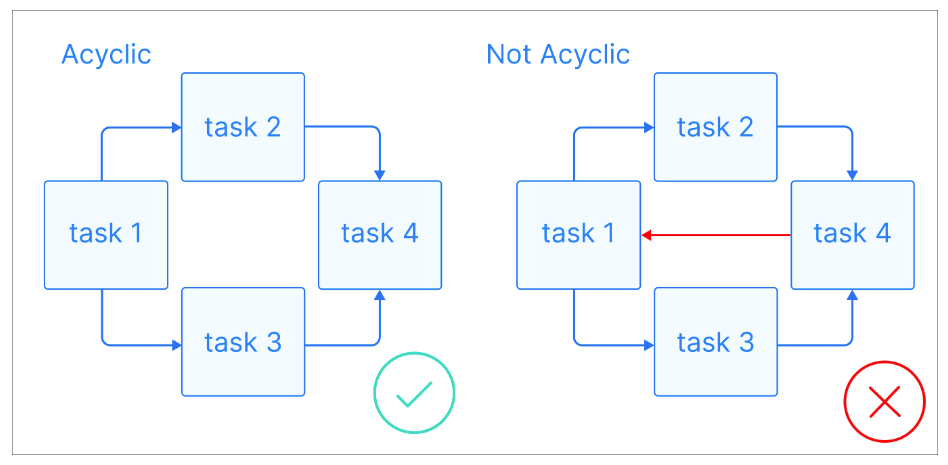 Visuele uitleg van acyclische grafen. Beeldbron: Astronomer
Visuele uitleg van acyclische grafen. Beeldbron: Astronomer
Het belangrijkste aan DAG's is dat ze acyclisch zijn: zodra je bij een knoop begint, kun je alleen vooruit bewegen en nooit terugkeren naar een vorige knoop. Dit zorgt ervoor dat taken in de juiste volgorde kunnen worden uitgevoerd zonder te leiden tot oneindige lussen. DAG's hebben vaak een hiërarchische structuur, waarbij taken zijn georganiseerd in niveaus of lagen. Taken op een hoger niveau zijn meestal afhankelijk van het afronden van taken op lagere niveaus.
Als data engineer, of wanneer je data-engineeringtaken uitvoert, sta je vaak voor de uitdaging om complexe datapipelines te bouwen waarbij elke stap afhankelijk is van de vorige. Dáár komen DAG's om de hoek kijken!
Omdat ze taken als knopen en afhankelijkheden als randen kunnen voorstellen, dwingen DAG's een logische uitvoeringsvolgorde af, zodat taken sequentieel worden uitgevoerd op basis van hun afhankelijkheden. Dit voorkomt fouten en inconsistenties door taken buiten volgorde te laten lopen. Bovendien kunnen DAG's, als één stap faalt, de getroffen taken identificeren en opnieuw uitvoeren, wat tijd en moeite bespaart.
Als je nieuw bent met het bouwen van datapipelines of je basis wilt versterken, biedt de cursus Understanding Data Engineering een uitstekend startpunt.
Het acyclische karakter van DAG's is een van de belangrijkste eigenschappen die ze ideaal maakt voor datapipelines. Ze zorgen ervoor dat taken kunnen worden uitgevoerd zonder oneindige lussen of recursieve afhankelijkheden die tot systeeminstabiliteit kunnen leiden.
Laten we een eenvoudig voorbeeld van een datapipeline bekijken:
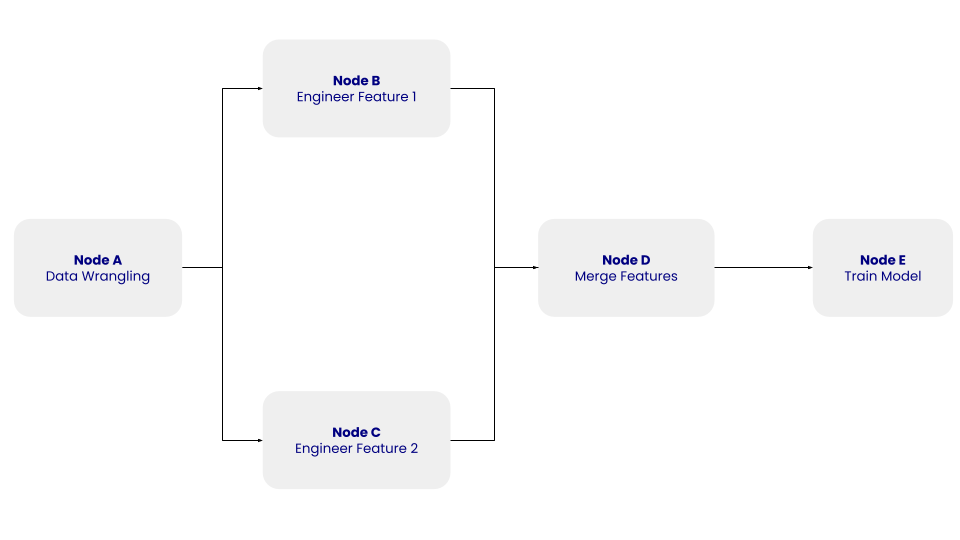 De structuur van deze eenvoudige DAG met de knopen A, B, C, D en E en hun afhankelijkheden. Afbeelding door de auteur.
De structuur van deze eenvoudige DAG met de knopen A, B, C, D en E en hun afhankelijkheden. Afbeelding door de auteur.
In de bovenstaande DAG vertegenwoordigt knoop A de stap data wrangling, die de datacleaningstap omvat, waarin de geëxtraheerde data wordt opgeschoond en voorbewerkt. De knopen B en C staan voor de stappen feature engineering, waarin de opgeschoonde data onafhankelijk wordt omgezet in twee features. Knoop D omvat het samenvoegen van de features. Tot slot vertegenwoordigt knoop E de modeltrainingsstap, waarin een machinelearningmodel wordt getraind op de getransformeerde data.
De DAG geeft niet om wat er binnen de taken gebeurt, maar om de volgorde waarin ze moeten worden uitgevoerd.
Bovendien stellen DAG's je in staat geautomatiseerde, schaalbare dataworkflows te creëren, vooral in gedistribueerde systemen en cloudomgevingen. Ze breken complexe dataverwerkingstaken op in kleinere, onafhankelijke, beheersbare subtaken, waardoor DAG's parallelle uitvoering en efficiënt gebruik van resources mogelijk maken. Deze schaalbaarheid is vooral belangrijk bij grote datasets en complexe datapipelines, omdat dit kosteneffectieve dataverwerking mogelijk maakt.
Tot slot kunnen DAG's een visuele weergave bieden van elke datapipeline, wat helpt bij het begrijpen en communiceren van de workflow. Die visuele helderheid is belangrijk bij samenwerking met andere teamleden of niet-technische stakeholders. Als je de datastroom en de afhankelijkheden tussen taken begrijpt, is het makkelijker om problemen te identificeren en op te lossen, het resourcegebruik te optimaliseren en weloverwogen beslissingen te nemen over verbeteringen aan de pipeline.
De cursus ETL and ELT in Python is een geweldige bron om praktisch te oefenen met het creëren en optimaliseren van datapipelines.
DAG's zijn breed omarmd en hebben verschillende toepassingen in data engineering. We noemden er al een paar in de vorige sectie. Laten we er nu een paar in meer detail bekijken.
Een van de meest voorkomende toepassingen van DAG's is het orkestreren van Extract, Transform, and Load (ETL)-processen. ETL-pipelines omvatten het extraheren van data uit diverse bronnen, het transformeren ervan naar een geschikt formaat en het laden in een doelsysteem.
Tools zoals Apache Airflow en Luigi gebruiken bijvoorbeeld DAG's om ETL-pipelines efficiënt te orkestreren. Een praktische usecase kan het integreren van data uit een CRM-systeem omvatten, het transformeren zodat het aansluit bij je bedrijfsbehoeften en het laden in een Snowflake-datawarehouse voor analytics.
Je kunt DAG's ook inzetten om runtimes van taken in je ETL-processen te monitoren en te loggen. Dit kan helpen bij het identificeren van knelpunten of taken die optimalisatie vereisen.
DAG's zijn ook uitstekend voor het beheren van complexe dataworkflows met meerdere taken en afhankelijkheden. Een machinelearningworkflow kan bijvoorbeeld taken omvatten zoals feature engineering, modeltraining en modeldeployment.
Een DAG in Apache Airflow kan bijvoorbeeld scripts voor featureselectie uitvoeren en pas daarna de modeltraining starten zodra de features zijn verwerkt, zodat afhankelijkheden worden beheerd en reproduceerbaarheid gewaarborgd is.
DAG's worden veel gebruikt in dataverwerkingspipelines om de datastroom uit meerdere bronnen te beheren en om te zetten in waardevolle inzichten. Een DAG in Apache Spark kan bijvoorbeeld clickstreamdata van een website verwerken, aggregaties uitvoeren om sessieduren te berekenen en de inzichten voeden aan een dashboard.
DAG's in Spark worden niet expliciet door gebruikers gedefinieerd, maar intern door het framework aangemaakt om de uitvoering van transformaties te optimaliseren.
Bij machine learning helpen DAG's bij het iteratieve en modulaire karakter van workflows. Ze stellen je in staat te experimenteren met verschillende preprocessingstappen, algoritmen en hyperparameters, terwijl je de pipeline georganiseerd houdt.
Tools zoals Kubeflow Pipelines en MLflow gebruiken DAG's om machinelearningworkflows te beheren, waardoor naadloos experimenteren en deployen mogelijk is. Je kunt bijvoorbeeld DAG's gebruiken om retraining-pipelines te activeren op basis van datadrift-detectie, zodat je modellen nauwkeurig en relevant blijven in de tijd.
Je hebt verschillende tools om DAG's effectief te beheren en te orkestreren. Laten we enkele van de populairste opties bekijken:
Apache Airflow is een veelgebruikt platform voor het creëren, plannen en monitoren van workflows. Het blinkt uit in het definiëren van complexe datapipelines als DAG's. Airflow biedt een gebruiksvriendelijke interface om deze DAG's te visualiseren en beheren, waardoor dataworkflows gemakkelijk te begrijpen en te troubleshooten zijn. De flexibiliteit en schaalbaarheid maken het een favoriet bij veel data-engineeringteams.
Prefect is een moderne orkestratietool die het maken en beheren van dataworkflows vereenvoudigt. Het biedt een Python-gebaseerde API om DAG's te definiëren, wat integratie met bestaande Python-code eenvoudig maakt. Prefect geeft prioriteit aan betrouwbaarheid en observability, met functies zoals automatische retries, backfills en robuuste monitoring.
Dask is een parallelle rekenbibliotheek voor Python die gedistribueerde dataworkflows beheert. Het kan berekeningen paralleliseren over meerdere cores of machines, waardoor het ideaal is voor grootschalige dataverwerkingstaken. Dask gebruikt een DAG-gebaseerd uitvoeringsmodel om taken te plannen en te coördineren, wat efficiënt resourcegebruik waarborgt.
Kubeflow Pipelines is een open-sourceplatform voor het bouwen en deployen van schaalbare machinelearningworkflows. Het gebruikt DAG's om end-to-end-workflows te definiëren, van datapreprocessing tot modeldeployment. Door de nauwe integratie met Kubernetes is het een sterke keuze voor het draaien van workflows in cloudomgevingen. Kubeflow biedt ook een visuele interface voor het beheren en monitoren van workflows, wat transparantie en controle geeft.
Dagster is een orkestratieplatform dat is ontworpen voor moderne dataworkflows. Het legt de nadruk op modulariteit en typeveiligheid, waardoor het testen en onderhouden van DAG's eenvoudiger wordt. Dagster integreert met populaire tools zoals Apache Spark, Snowflake en dbt, waardoor het een uitstekende keuze is voor data-engineeringteams met diverse technologieën.
Voordat je een DAG maakt, moet je Apache Airflow instellen. Je kunt het installeren met Docker of via een pakketbeheerder zoals pip:
pip install apache-airflowNa installatie moet je de Airflow-webserver en -scheduler configureren. Dit houdt in dat je databaseverbindingen instelt en initialiseert en de webserver start:
airflow db init
airflow webserver --port 8080Met Airflow ingesteld kun je je DAG maken. Je kunt Python gebruiken om de DAG en zijn taken als volgt te definiëren:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(
'simple_dag',
start_date=datetime(2023, 1, 1),
schedule_interval=None,
catchup=False
) as dag:
task1 = BashOperator(
task_id='task_1',
bash_command='echo "Hello, World!"'
)
task2 = BashOperator(
task_id='task_2',
bash_command='echo "This is task 2"'
)
task1 >> task2In dit voorbeeld bevat de eenvoudige DAG twee taken: task_1 en task_2. De operator >> stelt een afhankelijkheid tussen de taken in, waardoor task_2 pas wordt uitgevoerd nadat task_1 is voltooid.
Zodra je DAG is gedefinieerd en gedeployed naar Airflow, kun je ermee werken via de webinterface.
DAG's draaien op twee manieren:
schedule is heel gebruikelijk.Elke keer dat je een DAG draait, wordt er een nieuwe instantie van die DAG gemaakt, een zogeheten DAG run. DAG-runs kunnen parallel draaien voor dezelfde DAG en hebben elk een gedefinieerd datainterval, dat de periode aangeeft waarop de taken moeten opereren.
Na het triggeren kun je de voortgang monitoren in de DAG-weergave, die de workflow visueel weergeeft.
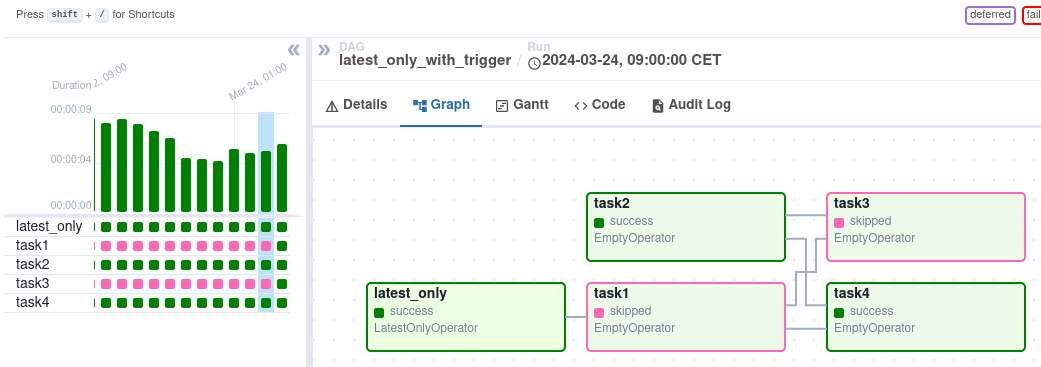 DAG-weergave in de Airflow-interface. Beeldbron: Airflow
DAG-weergave in de Airflow-interface. Beeldbron: Airflow
De Graph View biedt een gedetailleerde blik op een specifieke DAG-run, met inzicht in taakafhankelijkheden en uitvoeringstijden. De weergave Task Instances geeft gedetailleerde informatie over individuele taken, waaronder hun status, start- en eindtijden en logs. Je kunt taakelogs bekijken om fouten op te sporen en de hoofdoorzaak van storingen te begrijpen. De weergave Task Instances toont ook de duur van taken, wat helpt om potentiële prestatieproblemen te identificeren.
DAG's zijn een fundamenteel concept in data engineering en bieden een visuele en gestructureerde manier om complexe workflows weer te geven. Inzicht in knopen, randen en afhankelijkheden helpt je om datapipelines efficiënt te ontwerpen en beheren.
DAG's worden veel gebruikt om ETL-processen te orkestreren, dataverwerkingspipelines te beheren en machinelearningworkflows te automatiseren. Je kunt tools als Apache Airflow, Prefect en Dask gebruiken om DAG's effectief te creëren en beheren. Deze tools bieden gebruiksvriendelijke interfaces, planningsmogelijkheden en geavanceerde functies voor monitoring, foutafhandeling en schalen.
Wil je praktisch aan de slag, dan helpt deze introductiecursus over Airflow in Python je om DAG's effectief te maken en te beheren. Voor een bredere kijk op data-engineeringconcepten en -workflows biedt deze cursus over understanding data engineering een uitstekende basis!
Leer meer over data engineering met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
